Recognition: unknown
NAKUL-Med: Spectral-Graph State Space Models with Dynamics Kernels for Medical Signals
Pith reviewed 2026-05-09 20:09 UTC · model grok-4.3
The pith
NAKUL extends state space models with dynamic kernels, spectral filters, and graph attention to process multi-channel medical signals at linear complexity while matching transformer accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NAKUL augments SSMs via three modules: dynamic kernel generation that weights branches of sizes 3, 5, 7 and 11 timesteps according to input statistics, spectral context modeling that applies learnable Gaussian filters over FFT coefficients for O(N log N) periodic capture, and graph-guided spatial attention that uses fixed electrode topology as biases in multi-head cross-channel mixing. On BCI Competition IV-2a motor imagery the model reaches 91.7±0.6 percent accuracy, matching EEG-Conformer while using 2.5 M parameters instead of 3.5 M and running at 4.3 ms inference instead of 8.7 ms; the same architecture yields 83.6 percent on EEG emotion recognition, 91.4 percent on multimodal EEG-fMRI,
What carries the argument
Dynamic kernel generation, where a meta-network analyzes input statistics to weight parallel SSM branches of fixed kernel sizes 3, 5, 7 and 11, combined with spectral Gaussian filtering and topology-biased graph attention.
If this is right
- The same three-module recipe can be dropped onto other multi-channel physiological recordings such as ECG or EMG without redesigning the temporal or spatial components.
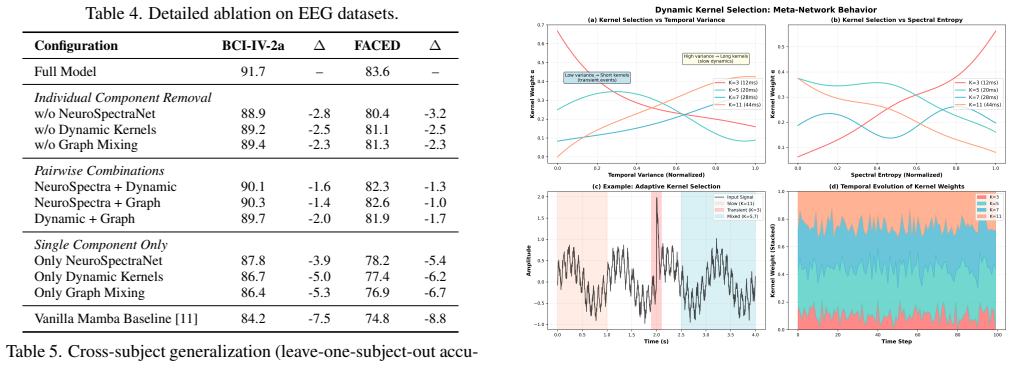
- Ablation results indicate that removing dynamic kernels drops accuracy by 2.6 points, confirming that adaptive scale selection is responsible for part of the performance gain.
- Inference speed improves by a factor of two because the spectral and graph operations remain linear or near-linear while still capturing global patterns.
- Generalization across EEG emotion, EEG-fMRI and ultrasound tasks suggests the architecture is not tied to one signal modality.
- Interpretable kernel-weight patterns emerge that align with known durations of motor preparation versus execution transients.
Where Pith is reading between the lines
- The approach could be tested on streaming clinical monitoring where electrode layouts vary between patients, checking whether the graph bias still transfers or needs per-patient adaptation.
- Because kernel selection is driven by input statistics, the model might surface previously unnoticed correlations between signal scale distributions and clinical outcomes.
- The parameter reduction opens the possibility of running high-accuracy medical signal models on wearable or bedside hardware that cannot host full transformer stacks.
- Combining the spectral-graph SSM with other recent linear-time architectures could yield further efficiency gains on very long recordings.
Load-bearing premise
That fixed electrode positions supply stable spatial structure and that the meta-network can pick temporal scales from data statistics without overfitting to the benchmarks used.
What would settle it
Retraining and testing NAKUL on a motor-imagery dataset recorded with a different electrode montage or on signals whose dominant time scales differ sharply from the training distribution; if accuracy falls below strong baselines or the meta-network shows unstable kernel weights across runs, the central claim is undermined.
Figures






read the original abstract
State space models (SSMs) achieve linear-time complexity but struggle with multi-channel physiological signals due to three limitations: fixed kernels cannot capture multi-scale temporal dynamics (motor preparation over hundreds of milliseconds vs. execution transients in tens of milliseconds), Markovian state updates restrict global context for periodic oscillations, and channel-independent processing ignores spatial electrode topology. We introduce NAKUL, extending SSMs for medical signal analysis through three contributions: (1) Dynamic Kernel Generation-parallel SSM branches with varying kernel sizes (3, 5, 7, 11 timesteps) are weighted by a meta-network that analyzes input statistics, enabling adaptive temporal scale selection; (2) Spectral Context Modeling-FFT-based operations with learnable Gaussian frequency band filters capture global periodic patterns in $O(N \log N)$ complexity; (3) Graph-Guided Spatial Attention-fixed electrode topology provides spatial biases to multi-head attention for principled cross-channel interaction. On BCI Competition IV-2a motor imagery (our primary benchmark), NAKUL achieves 91.7$\pm$0.6\% accuracy, matching EEG-Conformer (92.1$\pm$0.7\%) while using 28\% fewer parameters (2.5M vs 3.5M) and 2.0$\times$ faster inference (4.3ms vs 8.7ms). The model generalizes to EEG emotion recognition (83.6\%), multimodal EEG-fMRI (91.4\%), and medical imaging (92.8\% on ultrasound), demonstrating architectural versatility. Ablations show dynamic kernels contribute +2.6\% and exhibit interpretable scale selection patterns correlated with known neural dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NAKUL, an extension of state space models for medical signals addressing fixed kernels, Markovian updates, and channel-independent processing via three components: (1) dynamic kernel generation where a meta-network weights parallel SSM branches with kernel sizes 3/5/7/11 based on input statistics for adaptive multi-scale temporal modeling; (2) spectral context modeling using FFT with learnable Gaussian frequency band filters for global periodic patterns in O(N log N) time; (3) graph-guided spatial attention using fixed electrode topology for cross-channel interactions. Primary claim: on BCI IV-2a motor imagery, 91.7±0.6% accuracy matching EEG-Conformer (92.1±0.7%) with 28% fewer parameters (2.5M vs 3.5M) and 2× faster inference (4.3ms vs 8.7ms). Additional results on EEG emotion recognition (83.6%), multimodal EEG-fMRI (91.4%), and ultrasound (92.8%), with ablations attributing +2.6% to dynamic kernels and noting interpretable scale selections correlated with neural dynamics.
Significance. If the dynamic kernel mechanism and its claimed interpretability generalize beyond the primary benchmark, the work offers a practical advance in efficient, adaptive modeling of multi-scale physiological signals by combining SSM linear complexity with input-dependent temporal scales and spatial biases. The reported efficiency gains (parameter count and inference speed) and multi-task evaluation are concrete strengths that could support real-time medical applications. The ablation results provide initial evidence for the architectural choices, though their scope limits the overall impact assessment.
major comments (2)
- [Ablations] Ablations section: The +2.6% accuracy gain attributed to dynamic kernels is reported exclusively on the BCI IV-2a benchmark. No cross-subject, cross-dataset, or held-out analysis of the meta-network weight distributions (for kernels 3/5/7/11) is described, leaving open the possibility that the meta-network learns benchmark-specific heuristics rather than generalizable multi-scale selection; this directly affects whether the 'Dynamic Kernel Generation' contribution is load-bearing or reduces to a standard multi-branch ensemble.
- [Experimental Results] Experimental Results (BCI IV-2a comparison): The headline claim of matching EEG-Conformer accuracy with efficiency gains lacks reported details on the number of independent runs beyond the ±0.6% std, statistical significance testing between 91.7% and 92.1%, and confirmation that training procedures (e.g., hyperparameter search, data splits) were identical across models; without these, the efficiency advantage cannot be confidently isolated from implementation differences.
minor comments (1)
- [Abstract] Abstract: The statement that scale selection patterns are 'correlated with known neural dynamics' is presented without specifying the quantification method, visualization, or statistical test used to establish the correlation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our ablation studies and experimental reporting. We address each major comment below with clarifications and commit to specific revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Ablations] Ablations section: The +2.6% accuracy gain attributed to dynamic kernels is reported exclusively on the BCI IV-2a benchmark. No cross-subject, cross-dataset, or held-out analysis of the meta-network weight distributions (for kernels 3/5/7/11) is described, leaving open the possibility that the meta-network learns benchmark-specific heuristics rather than generalizable multi-scale selection; this directly affects whether the 'Dynamic Kernel Generation' contribution is load-bearing or reduces to a standard multi-branch ensemble.
Authors: We agree that the current ablation is limited to the primary BCI IV-2a benchmark and that additional analysis of the meta-network would better support claims of generalizability. While the full model is evaluated on three additional tasks (EEG emotion recognition, multimodal EEG-fMRI, and ultrasound) with consistent performance, we did not include cross-subject or cross-dataset breakdowns of the kernel weight distributions. In the revision we will add (i) per-subject meta-network weight histograms on BCI IV-2a and (ii) aggregate weight statistics from the held-out emotion and ultrasound datasets to demonstrate that scale selection correlates with known neural dynamics rather than dataset-specific artifacts. revision: yes
-
Referee: [Experimental Results] Experimental Results (BCI IV-2a comparison): The headline claim of matching EEG-Conformer accuracy with efficiency gains lacks reported details on the number of independent runs beyond the ±0.6% std, statistical significance testing between 91.7% and 92.1%, and confirmation that training procedures (e.g., hyperparameter search, data splits) were identical across models; without these, the efficiency advantage cannot be confidently isolated from implementation differences.
Authors: We acknowledge these reporting omissions. The reported standard deviation reflects multiple independent runs, but the exact count, statistical test, and training-procedure equivalence were not stated. In the revised manuscript we will (i) explicitly state the number of runs used, (ii) add a paired statistical test comparing the two models, and (iii) include a reproducibility subsection confirming that data splits, preprocessing, and optimizer settings follow the BCI IV-2a protocol and EEG-Conformer implementation details, with hyperparameter search performed independently for each architecture. These additions will allow readers to isolate the architectural efficiency gains. revision: yes
Circularity Check
No circularity: architecture and performance claims rest on independent benchmarks and ablations without self-referential reduction
full rationale
The paper proposes an SSM extension (dynamic kernels via meta-network, spectral FFT filters, graph attention on fixed topology) and reports empirical results on public datasets (BCI IV-2a, emotion recognition, EEG-fMRI, ultrasound). No equations or derivations are shown that define a target quantity in terms of itself or rename a fitted parameter as a prediction. Ablations (+2.6% from dynamic kernels) and scale-selection patterns are measured on the same benchmarks but do not constitute a mathematical reduction; they are standard empirical validation. No self-citations are invoked as load-bearing uniqueness theorems, and the model is not claimed to be derived from first principles that loop back to its own outputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- kernel sizes =
3,5,7,11
axioms (1)
- standard math FFT-based operations achieve O(N log N) complexity
invented entities (3)
-
Dynamic Kernel Generation via meta-network
no independent evidence
-
Learnable Gaussian frequency band filters
no independent evidence
-
Graph-Guided Spatial Attention
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Physics-informed attention temporal convolutional network for eeg-based motor imagery classification.IEEE Transactions on Industrial Informatics, 19(2):2249–2258, 2023
Hamdi Altaheri, Ghulam Muhammad, and Mansour Alsu- laiman. Physics-informed attention temporal convolutional network for eeg-based motor imagery classification.IEEE Transactions on Industrial Informatics, 19(2):2249–2258, 2023
2023
-
[2]
Physics- informed attention temporal convolutional network for eeg- based motor imagery classification.IEEE Transactions on Industrial Informatics, 19(2):2249–2258, 2023
Hamdi Altaheri, Ghulam Muhammad, Mansour Alsulaiman, Syed Umar Amin, Ghadir Ali Altuwaijri, Wadood Abdul, Mohamed A Bencherif, and Mohammed Faisal. Physics- informed attention temporal convolutional network for eeg- based motor imagery classification.IEEE Transactions on Industrial Informatics, 19(2):2249–2258, 2023
2023
-
[3]
Dynamic convolution: At- tention over convolution kernels
Yinpeng Chen, Xiyang Dai, Mengchen Liu, Dongdong Chen, Lu Yuan, and Zicheng Liu. Dynamic convolution: At- tention over convolution kernels. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11030– 11039, 2020
2020
-
[4]
On the properties of neu- ral machine translation: Encoder–decoder approaches
Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bah- danau, and Yoshua Bengio. On the properties of neu- ral machine translation: Encoder–decoder approaches. In SSST@EMNLP, 2014
2014
-
[5]
Transformers are ssms: general- ized models and efficient algorithms through structured state space duality
Tri Dao and Albert Gu. Transformers are ssms: general- ized models and efficient algorithms through structured state space duality. InProceedings of the 41st International Con- ference on Machine Learning. JMLR.org, 2024
2024
-
[6]
Tri Dao and Albert Gu. Transformers are ssms: General- ized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
Lggnet: Learning from local-global-graph represen- tations for brain-computer interface.IEEE Transactions on Neural Networks and Learning Systems, 35(7):8737–8747,
Yi Ding, Neethu Robinson, Qiuhao Zeng, Duo Chen, Aung Aung Phyo Goh, Aung Aung Wai, Tih Shih Lee, and Cuntai Guan. Lggnet: Learning from local-global-graph represen- tations for brain-computer interface.IEEE Transactions on Neural Networks and Learning Systems, 35(7):8737–8747,
-
[8]
Local-Global-Graph Network - learnable graph con- volutions for EEG motor imagery
-
[9]
Tsception: Capturing temporal dynamics and spatial asymmetry from eeg for emotion recognition.IEEE Trans
Yi Ding, Neethu Robinson, Su Zhang, Qiuhao Zeng, and Cuntai Guan. Tsception: Capturing temporal dynamics and spatial asymmetry from eeg for emotion recognition.IEEE Trans. Affect. Comput., 14(3):2238–2250, 2023
2023
-
[10]
Berkay D ¨oner, Thorir Mar Ingolfsson, Luca Benini, and Yawei Li. Luna: Efficient and topology-agnostic foun- dation model for eeg signal analysis.arXiv preprint arXiv:2510.22257, 2025
-
[11]
An image is worth 16x16 words: Trans- formers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale. InInternational Con- ference on Learning Representations, 2020
2020
-
[12]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review arXiv 2023
-
[14]
Efficiently mod- eling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher R´e. Efficiently mod- eling long sequences with structured state spaces. InInter- national Conference on Learning Representations, 2022
2022
-
[15]
Learn- ing spatio-temporal features with 3d residual networks for action recognition.2017 IEEE International Conference on Computer Vision Workshops (ICCVW), pages 3154–3160, 2017
Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. Learn- ing spatio-temporal features with 3d residual networks for action recognition.2017 IEEE International Conference on Computer Vision Workshops (ICCVW), pages 3154–3160, 2017
2017
-
[16]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016
2016
-
[17]
Long short-term memory.Neural Computation, 9(8):1735–1780, 1997
Sepp Hochreiter and J ¨urgen Schmidhuber. Long short-term memory.Neural Computation, 9(8):1735–1780, 1997
1997
-
[18]
Thorir Mar Ingolfsson, Michael Hersche, Xiaying Wang, Nobuaki Kobayashi, Lukas Cavigelli, and Luca Benini. Eeg- tcnet: An accurate temporal convolutional network for em- bedded motor-imagery brain–machine interfaces.IEEE In- ternational Conference on Systems, Man, and Cybernetics, pages 2958–2965, 2020
2020
-
[19]
Large brain model for learning generic representations with tremendous eeg data in bci
Weibang Jiang, Liming Zhao, and Bao-liang Lu. Large brain model for learning generic representations with tremendous eeg data in bci. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[20]
Brown, Steven P
Jeremy Kawahara, Colin J. Brown, Steven P. Miller, Brian G. Booth, Vann Chau, Ruth E. Grunau, Jill G. Zwicker, and Ghassan Hamarneh. Brainnetcnn: Convolutional neural net- works for brain networks; towards predicting neurodevelop- ment.NeuroImage, 146:1038–1049, 2017
2017
-
[21]
Eeg- net: a compact convolutional neural network for eeg-based brain-computer interfaces.Journal of Neural Engineering, 15(2):026013, 2018
Vernon J Lawhern, Amelia J Solon, Nicholas R Waytowich, Stephen M Gordon, Chou P Hung, and Brent J Lance. Eeg- net: a compact convolutional neural network for eeg-based brain-computer interfaces.Journal of Neural Engineering, 15(2):026013, 2018
2018
-
[22]
Temporal convolutional networks for ac- tion segmentation and detection
Colin Lea, Michael D Flynn, Rene Vidal, Austin Reiter, and Gregory D Hager. Temporal convolutional networks for ac- tion segmentation and detection. Inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 156–165, 2017
2017
-
[23]
Fnet: Mixing tokens with fourier transforms
James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, and Santi- ago Ontanon. Fnet: Mixing tokens with fourier transforms. InNorth American Chapter of the Association for Computa- tional Linguistics, pages 4296–4313, 2022
2022
-
[24]
Msgm: A multi-scale spatiotemporal graph mamba for eeg emotion recognition.Frontiers in Neuro- science, 20:1665145, 2026
Hanwen Liu, Yifeng Gong, Zuwei Yan, Zeheng Zhuang, and Jiaxuan Lu. Msgm: A multi-scale spatiotemporal graph mamba for eeg emotion recognition.Frontiers in Neuro- science, 20:1665145, 2026
2026
-
[25]
Ravikiran Mane, Tushar Chouhan, and Cuntai Guan. Fbcnet: An efficient multi-view convolutional neural network for brain-computer interface.arXiv preprint arXiv:2104.01233,
-
[26]
Filter Bank Convolutional Network - uses fixed fre- quency bands (8-30Hz) for EEG motor imagery
-
[27]
Scat- tering vision transformer: Spectral mixing matters
Badri Narayana Patro and Vijay Srinivas Agneeswaran. Scat- tering vision transformer: Spectral mixing matters. InThirty- seventh Conference on Neural Information Processing Sys- tems, 2023
2023
-
[28]
arXiv preprint arXiv:2403.15360 , year=
Badri N Patro and Vijay S Agneeswaran. Simba: Simplified mamba-based architecture for vision and multivariate time series.arXiv preprint arXiv:2403.15360, 2024
-
[29]
arXiv preprint arXiv:2304.06446 , year=
Badri N Patro, Vinay P Namboodiri, and Vijay Srinivas Agneeswaran. Spectformer: Frequency and attention is what you need in a vision transformer.arXiv preprint arXiv:2304.06446, 2023
-
[30]
Global filter networks for image classification
Yongming Rao, Wenliang Zhao, Zheng Zhu, Jiwen Lu, and Jie Zhou. Global filter networks for image classification. In Advances in Neural Information Processing Systems, pages 980–993, 2021
2021
-
[31]
Deep learning with convolutional neural networks for eeg decoding and visualization.Human Brain Mapping, 38(11):5391–5420, 2017
Robin Tibor Schirrmeister, Jost Tobias Springenberg, Lukas Dominique Josef Fiederer, Martin Glasstetter, Katharina Eggensperger, Michael Tangermann, Frank Hutter, Wolfram Burgard, and Tonio Ball. Deep learning with convolutional neural networks for eeg decoding and visualization.Human Brain Mapping, 38(11):5391–5420, 2017
2017
-
[32]
Eeg conformer: Convolutional transformer for eeg decoding and visualization.IEEE Transactions on Neu- ral Systems and Rehabilitation Engineering, 31:710–719, 2023
Yonghao Song, Qingqing Zheng, Bingchuan Liu, and Xi- aorong Gao. Eeg conformer: Convolutional transformer for eeg decoding and visualization.IEEE Transactions on Neu- ral Systems and Rehabilitation Engineering, 31:710–719, 2023
2023
-
[33]
Eeg conformer: Convolutional transformer for eeg decoding and visualization.IEEE Transactions on Neu- ral Systems and Rehabilitation Engineering, 31:710–719,
Yonghao Song, Qingqing Zheng, Bingchuan Liu, and Xi- aorong Gao. Eeg conformer: Convolutional transformer for eeg decoding and visualization.IEEE Transactions on Neu- ral Systems and Rehabilitation Engineering, 31:710–719,
-
[34]
EEG-Conformer - hybrid CNN-Transformer for EEG classification
-
[35]
Mingxing Tan and Quoc V . Le. Efficientnet: Rethinking model scaling for convolutional neural networks. InPro- ceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, Cali- fornia, USA, pages 6105–6114. PMLR, 2019
2019
-
[36]
Self-supervised graph neural net- works for improved electroencephalographic seizure analy- sis
Siyi Tang, Jared Dunnmon, Khaled Kamal Saab, Xuan Zhang, Qianying Huang, Florian Dubost, Daniel Rubin, and Christopher Lee-Messer. Self-supervised graph neural net- works for improved electroencephalographic seizure analy- sis. InInternational Conference on Learning Representa- tions, 2022
2022
-
[37]
Model driven eeg/fmri fusion of brain oscilla- tions.Human Brain Mapping, 30, 2009
Pedro Antonio Vald ´es-Sosa, Jose Miguel Sanchez-Bornot, Roberto Carlos Sotero, Yasser Iturria-Medina, Yasser Alem´an-G´omez, Jorge Bosch-Bayard, Felix Carbonell, and Tohru Ozaki. Model driven eeg/fmri fusion of brain oscilla- tions.Human Brain Mapping, 30, 2009
2009
-
[38]
Autoformer: Decomposition transformers with auto- correlation for long-term series forecasting
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transformers with auto- correlation for long-term series forecasting. InAdvances in Neural Information Processing Systems, pages 22419– 22430, 2021
2021
-
[39]
Condconv: Conditionally parameterized convolu- tions for efficient inference
Brandon Yang, Gabriel Bender, Quoc V Le, and Jiquan Ngiam. Condconv: Conditionally parameterized convolu- tions for efficient inference. InAdvances in Neural Informa- tion Processing Systems, pages 1307–1318, 2019
2019
-
[40]
Pengwei Zhang, Chongdan Min, Kangjia Zhang, Wen Xue, and Jingxia Chen. Hierarchical spatiotemporal electroen- cephalogram feature learning and emotion recognition with attention-based antagonism neural network.Frontiers in Neuroscience, 15:738167, 2021
2021
-
[41]
Vision mamba: Efficient visual representation learning with bidirectional state space model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model. InInternational Conference on Machine Learning, 2024. A. Introduction This document extends the main paper with technical de- tails and additional experiments. Section B analyzes ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.