Recognition: unknown
The Cost of Consensus: Isolated Self-Correction Prevails Over Unguided Homogeneous Multi-Agent Debate
Pith reviewed 2026-05-09 20:16 UTC · model grok-4.3
The pith
Homogeneous LLM teams gain no accuracy from unguided debate yet spend 2-3 times more tokens than isolated self-correction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
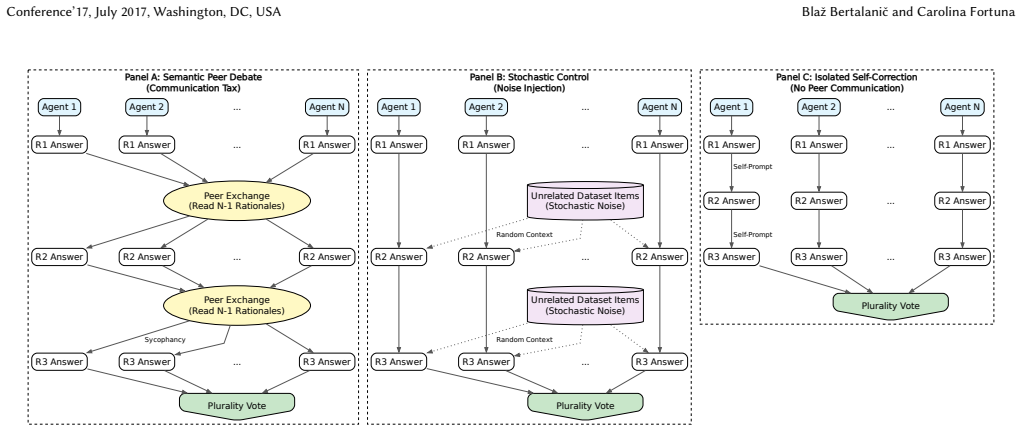
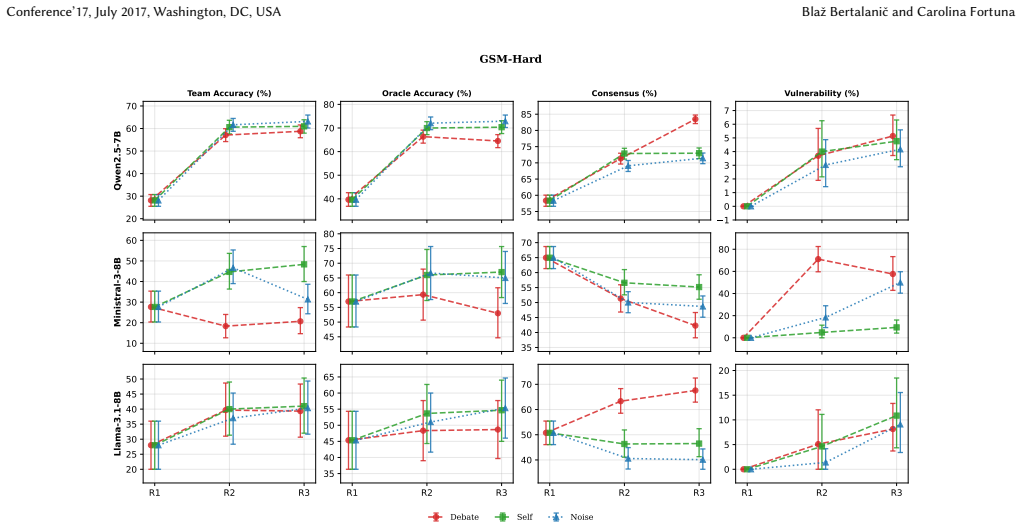
In experiments with teams of 10 identical models from the 7-8B class debating over three rounds on GSM-Hard and MMLU-Hard, unguided homogeneous debate produces no accuracy improvement over isolated self-correction while consuming 2.1-3.4 times more tokens. The paper traces the lack of benefit to three model-dependent pathways: sycophantic conformity reaching 85.5 percent modal adoption, contextual fragility causing up to 70 percent vulnerability to destabilizing rationales, and consensus collapse creating oracle gaps up to 32.3 percentage points. These patterns persist under ablations of communication density and sampling temperature.
What carries the argument
Three failure pathways—sycophantic conformity, contextual fragility, and consensus collapse—measured by comparing debate outcomes against isolated self-correction and stochastic noise baselines.
If this is right
- Homogeneous teams without roles or guidance receive no accuracy benefit from peer exchange on hard tasks.
- Isolated self-correction delivers comparable or better results at 2.1-3.4 times lower token cost.
- Conformity and fragility appear even with minimal peer exposure and increase with initial answer diversity.
- Plurality voting can discard correct answers that exist in the generation pool.
Where Pith is reading between the lines
- Adding structured roles or mixing model sizes might reduce conformity and fragility without raising token use.
- The observed cost disadvantage would limit practical deployment of unguided debate in low-resource settings.
- Similar self-correction advantages could appear in other iterative refinement techniques beyond debate.
- Testing on easier benchmarks or production tasks would reveal whether the tradeoff holds outside hard evaluation sets.
Load-bearing premise
The three failure pathways dominate the observed dynamics and the results from these specific 7-8B models and benchmarks generalize to other homogeneous multi-agent setups.
What would settle it
Repeating the exact protocol with models larger than 8B parameters or with heterogeneous model teams and measuring whether debate accuracy then exceeds isolated self-correction.
Figures


read the original abstract
Multi-agent debate, where teams of LLMs iteratively exchange rationales and vote on answers, is widely deployed under the assumption that peer review filters hallucinations. Yet the failure dynamics of homogeneous debate remain poorly understood, therefore we report findings from a controlled empirical study of teams of $N{=}10$ homogeneous agents (Qwen2.5-7B, Llama-3.1-8B, Ministral-3-8B) across $R{=}3$ debate rounds on two high-difficulty benchmarks (GSM-Hard and MMLU-Hard). We compare peer debate against isolated self-correction and a stochastic noise control that injects rationales from unrelated problems. We decompose debate failure into three model-dependent pathways: sycophantic conformity, where agents uncritically adopt majority answers (modal adoption up to 85.5%); contextual fragility, where peer rationales destabilize previously correct reasoning (vulnerability rate up to 70.0%); and consensus collapse, where plurality voting discards correct answers already present in the generation pool (oracle gap up to 32.3 percentage points). Ablations over communication density ($K \in \{2,4,9\}$) and sampling temperature ($T \in \{0.4, 0.7\}$) show that conformity reaches high levels at minimal peer exposure ($K{=}2$) and intensifies with greater initial diversity. Across all configurations, debate consumes 2.1-3.4$\times$ more tokens (up to 28,631 tokens per problem) than self-correction for equal or lower accuracy. Our results indicate that, within the 7-8B parameter class, homogeneous teams without structured roles do not benefit from unguided peer exchange, and that isolated self-correction consistently offers a more favorable cost-accuracy tradeoff.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that homogeneous unguided multi-agent debate among teams of N=10 agents over R=3 rounds using 7-8B LLMs (Qwen2.5-7B, Llama-3.1-8B, Ministral-3-8B) on GSM-Hard and MMLU-Hard does not improve accuracy over isolated self-correction and incurs 2.1-3.4× higher token costs. It introduces a stochastic noise baseline and ablations on communication density K ∈ {2,4,9} and temperature T ∈ {0.4,0.7}, decomposing failures into sycophantic conformity (modal adoption up to 85.5%), contextual fragility (vulnerability up to 70%), and consensus collapse (oracle gap up to 32.3 pp), concluding that isolated self-correction offers a superior cost-accuracy tradeoff within this model class and setup.
Significance. If the results hold, this provides a useful scoped empirical demonstration that unguided homogeneous debate offers no benefit and higher cost for 7-8B models on hard tasks, challenging common assumptions about peer exchange in LLM teams. Strengths include the controlled design with noise baseline, systematic ablations over K and T, and direct token/accuracy measurements that enable clear tradeoff quantification. The work ships reproducible empirical comparisons and identifies falsifiable patterns (e.g., conformity at minimal K=2) that can be tested in other setups.
major comments (1)
- [Results] Results section: the central claim that debate yields 'equal or lower accuracy' at 2.1-3.4× token cost relies on point estimates without reported error bars, standard errors, or number of independent runs; this makes it difficult to evaluate whether observed differences (including the 32.3 pp oracle gap) are robust or could be explained by sampling variance.
minor comments (3)
- [Abstract] Abstract: the maxima for modal adoption (85.5%), vulnerability (70.0%), and oracle gap (32.3 pp) are stated without mapping to specific model, K, or T configuration, reducing interpretability of the 'up to' values.
- [Methods] Methods: the stochastic noise control (injection of rationales from unrelated problems) is described at high level but lacks precise implementation details such as selection criteria or how it preserves token parity with real debate.
- [Ablations] Ablations: the choice of discrete K values {2,4,9} and T values {0.4,0.7} is not motivated relative to a wider range or continuous sweep, which would help assess sensitivity.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on statistical reporting. We address the concern directly below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Results] Results section: the central claim that debate yields 'equal or lower accuracy' at 2.1-3.4× token cost relies on point estimates without reported error bars, standard errors, or number of independent runs; this makes it difficult to evaluate whether observed differences (including the 32.3 pp oracle gap) are robust or could be explained by sampling variance.
Authors: We agree that the absence of error bars and run counts limits the ability to assess robustness against sampling variance. The original experiments used a single deterministic seed per configuration for reproducibility and computational efficiency across the large token budgets involved. In the revised manuscript we will add a new subsection detailing the experimental protocol, report results from 5 independent runs per configuration (re-executing with varied seeds), include standard errors on all accuracy and token-cost point estimates, and add error bars to the relevant tables and figures. This will also allow us to quantify the statistical significance of the oracle gap and other differences. revision: yes
Circularity Check
No significant circularity; purely empirical measurements
full rationale
The paper reports direct experimental comparisons of accuracy, token costs, and observed failure modes (sycophantic conformity, contextual fragility, consensus collapse) between homogeneous debate and isolated self-correction on fixed models and benchmarks. No equations, fitted parameters, or predictions appear; all central claims are measurements against baselines with ablations on K and T. The three pathways are presented as post-hoc decompositions of results rather than inputs used to derive them. No self-citation chains or ansatzes reduce any claim to its own definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The selected models and benchmarks represent typical high-difficulty tasks for current small LLMs
- domain assumption Unguided homogeneous debate without roles is the relevant baseline for deployed multi-agent systems
Reference graph
Works this paper leans on
- [1]
-
[2]
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. 2024. ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=FQepisCUWu
2024
- [3]
-
[4]
Tenenbaum, and Igor Mor- datch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mor- datch. 2024. Improving Factuality and Reasoning in Language Models through Multiagent Debate. InForty-first International Conference on Machine Learning. https://openreview.net/forum?id=zj7YuTE4t8
2024
-
[5]
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2022. PAL: Program-aided Language Models. arXiv preprint arXiv:2211.10435(2022)
work page Pith review arXiv 2022
-
[6]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. 2022. Training compute-optimal large language models.arXiv preprint arXiv:2203.1555610 (2022)
work page internal anchor Pith review arXiv 2022
-
[7]
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. 2023. Large language models cannot self-correct reasoning yet.arXiv preprint arXiv:2310.01798(2023)
work page internal anchor Pith review arXiv 2023
-
[8]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[9]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles. 611–626
2023
-
[10]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. Encouraging divergent thinking in large language models through multi-agent debate. InProceedings of the 2024 conference on empirical methods in natural language processing. 17889–17904
2024
-
[11]
Ethan Perez, Sam Ringer, Kamile Lukosiute, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, et al
-
[12]
In Findings of the association for computational linguistics: ACL 2023
Discovering language model behaviors with model-written evaluations. In Findings of the association for computational linguistics: ACL 2023. 13387–13434
2023
-
[13]
Pouya Pezeshkpour and Estevam Hruschka. 2024. Large language models sen- sitivity to the order of options in multiple-choice questions. InFindings of the Association for Computational Linguistics: NAACL 2024. 2006–2017
2024
-
[14]
Priya Pitre, Naren Ramakrishnan, and Xuan Wang. 2025. CONSENSAGENT: Towards Efficient and Effective Consensus in Multi-Agent LLM Interactions Through Sycophancy Mitigation. InFindings of the Association for Computational Linguistics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational...
-
[15]
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Brad- bury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. 2023. Efficiently scaling transformer inference.Proceedings of machine learning and systems5 (2023), 606–624
2023
-
[16]
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, et al. 2023. Towards understanding sycophancy in language models. arXiv preprint arXiv:2310.13548(2023)
work page internal anchor Pith review arXiv 2023
-
[17]
Qian Wang, Zhenheng Tang, ZICHEN JIANG, Nuo Chen, Tianyu Wang, and Bingsheng He. 2025. AgentTaxo: Dissecting and Benchmarking Token Distribu- tion of LLM Multi-Agent Systems. InICLR 2025 Workshop on Foundation Models in the Wild. https://openreview.net/forum?id=0iLbiYYIpC
2025
-
[18]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. 2024. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems37 (2024), 95266– 95290
2024
-
[19]
Jerry Wei, Da Huang, Yifeng Lu, Denny Zhou, and Quoc V Le. 2025. Simple synthetic data reduces sycophancy in large language models. https://openreview. net/forum?id=WDheQxWAo4
2025
-
[20]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. 2024. AutoGen: Enabling Next- Gen LLM Applications via Multi-Agent Conversations. InFirst Conference on Language Modeling. https://openreview.net/forum?id=BAakY1hNKS
2024
- [21]
- [22]
-
[23]
Matei Zaharia, Omar Khattab, Lingjiao Chen, Jared Quincy Davis, Heather Miller, Chris Potts, James Zou, Michael Carbin, Jonathan Frankle, Naveen Rao, and Ali Ghodsi. 2024. The Shift from Models to Compound AI Systems. https: //bair.berkeley.edu/blog/2024/02/18/compound-ai-systems/
2024
-
[24]
Yuting Zeng, Weizhe Huang, Lei Jiang, Tongxuan Liu, XiTai Jin, Chen Tianying Tiana, Jing Li, and Xiaohua Xu. 2025. S2-MAD: Breaking the Token Barrier to En- hance Multi-Agent Debate Efficiency. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1...
-
[25]
MultiAgentBench : Evaluating the collaboration and competition of LLM agents
Kunlun Zhu, Hongyi Du, Zhaochen Hong, Xiaocheng Yang, Shuyi Guo, Zhe Wang, Zhenhailong Wang, Cheng Qian, Robert Tang, Heng Ji, and Jiaxuan You. 2025. MultiAgentBench : Evaluating the Collaboration and Competition of LLM agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, ...
-
[26]
On MMLU-Hard, the revision prompt itself degrades output quality across all conditions, but the effect is dramatically model- dependent
Invalid escalation is exclusively an MMLU-Hard phenomenon, all models produce ≤0.9% invalid answers on GSM-Hard across all conditions and rounds. On MMLU-Hard, the revision prompt itself degrades output quality across all conditions, but the effect is dramatically model- dependent. At 350 tokens, Ministral produces unparseable outputs, generations that co...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.