Recognition: unknown
Rethink MAE with Linear Time-Invariant Dynamics
Pith reviewed 2026-05-09 20:10 UTC · model grok-4.3
The pith
Frozen visual patch tokens hold order-dependent heterogeneity that linear time-invariant state space probes can exploit via learned permutations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
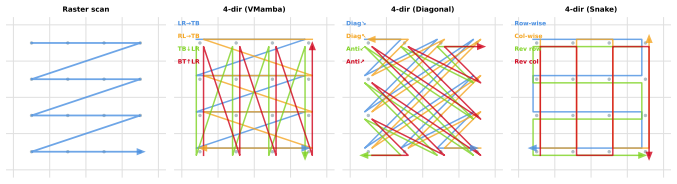
Token order is a critical, exploitable dimension in frozen visual representations. SSMProbe drives a state space model as a discrete LTI dynamical system so that sequence order strictly dictates the final hidden state through inherent memory decay. Formulating token ordering as an information scheduling problem, the method compares fixed scan heuristics against a differentiable soft permutation learned from supervision and shows that the learned ordering recovers strong performance on standard and fine-grained classification even when patches carry highly localized features.
What carries the argument
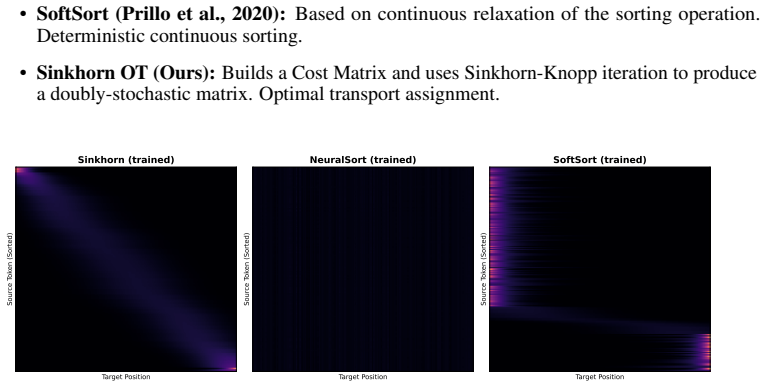
SSMProbe, a state space model operating as a discrete linear time-invariant dynamical system whose memory decay renders the final state strictly permutation-sensitive, paired with a Sinkhorn-based soft permutation that learns an optimal token schedule from downstream supervision.
If this is right
- Fixed scan orders fail on highly localized patch features while learned permutations recover competitive accuracy.
- Pre-training objectives shape token structure differently: DINOv2 concentrates semantics in CLS tokens leaving patches hyperspecialized, pure MAE preserves distributed heterogeneous patch informativeness, and BEiT lies in between.
- Heterogeneity is order-dependent, so SSM probe performance depends critically on which tokens occupy which temporal positions rather than on spatial grid topology alone.
- The approach supplies a new diagnostic lens for analyzing how visual representations encode information across token sequences.
Where Pith is reading between the lines
- The learned routing mechanism could be inspected to surface which specific patches carry task-relevant information in a given model.
- Order sensitivity may extend beyond probing to influence how spatial information is integrated during pre-training itself.
- If the heterogeneity proves robust, similar LTI scheduling could be tested on sequence models in other domains such as audio or video.
Load-bearing premise
Performance differences between fixed scans and the learned soft permutation arise from genuine exploitation of pre-existing token heterogeneity in the frozen representations rather than from the added capacity and optimization of the SSM probe itself.
What would settle it
An ablation in which the same SSM architecture with a fixed or random token order achieves the same accuracy as the learned soft permutation on the same frozen models would falsify the claim that order scheduling is required to exploit the heterogeneity.
Figures


read the original abstract
Standard representation probing for visual models relies on mathematically permutation-invariant operations like Global Average Pooling (GAP) or CLS tokens, treating patch representations as an unstructured bag-of-words. We challenge this paradigm by demonstrating that token order is a critical, exploitable dimension in frozen visual representations (e.g., MAE, BEiT, DINOv2, and ViT as CLS-ablation extreme). We propose SSMProbe, a probing framework driven by a State Space Model (SSM). Operating as discrete Linear Time-Invariant (LTI) dynamical systems, SSMs act as permutation-sensitive probes where sequence order strictly dictates the final state due to inherent memory decay. Formulating token ordering as an information scheduling problem, we compare fixed scan heuristics against a differentiable soft permutation (Sinkhorn-based) learned from downstream supervision. Evaluations on standard and fine-grained classification benchmarks reveal a striking order gap: while fixed scans fail dramatically on highly localized patch features, our learned soft permutation successfully extracts highly competitive performance from otherwise heavily localized patch sequences. We find that pre-training objectives fundamentally shape token structure: DINOv2 concentrates global semantics in optimized CLS tokens leaving patches hyperspecialized, pure MAE preserves distributed representations with heterogeneous patch informativeness, and ViT represents a supervised CLS-dominated extreme. BEiT occupies middle ground. This heterogeneity is order-dependent -- meaning the SSM probe's performance depends critically on which tokens are placed at which temporal positions -- and is not merely a topological property of the spatial grid. SSMProbe's learned routing effectively discovers and exploits this heterogeneity, offering a powerful new diagnostic lens for visual representation analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SSMProbe, a probing framework based on State Space Models (SSMs) formulated as discrete Linear Time-Invariant (LTI) dynamical systems, to show that token order is a critical exploitable dimension in frozen visual representations from MAE, BEiT, DINOv2, and ViT. It compares fixed scan heuristics against a differentiable soft permutation learned via Sinkhorn normalization on downstream classification tasks, claiming that pre-training objectives shape order-dependent patch token heterogeneity (e.g., distributed in MAE vs. hyperspecialized in DINOv2) that fixed permutation-invariant probes like GAP or CLS tokens overlook.
Significance. If the central empirical claims hold after addressing capacity controls, this offers a new diagnostic approach for analyzing visual representations by exploiting the inherent permutation sensitivity of LTI dynamics, potentially improving understanding of how self-supervised objectives distribute information across patches and providing an alternative to standard invariant probing methods.
major comments (1)
- [§4 (Experiments)] §4 (Experiments): The performance gap between fixed scan orders and the learned soft permutation (Sinkhorn) is load-bearing for the claim that SSMProbe exploits pre-existing order-dependent token heterogeneity via LTI memory decay. However, the learned permutation introduces additional trainable parameters and task-specific optimization absent from the fixed-scan baselines, raising the possibility that gains reflect greater expressive power of the routing mechanism rather than genuine exploitation of frozen feature structure. A capacity-matched control (e.g., a non-learned but optimized ordering or permutation-agnostic probe with equivalent parameters) is required to isolate the effect.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback and for identifying a key experimental control needed to strengthen our claims. We agree that the performance advantage of the learned soft permutation must be isolated from capacity differences, and we will incorporate the suggested controls in the revised manuscript.
read point-by-point responses
-
Referee: The performance gap between fixed scan orders and the learned soft permutation (Sinkhorn) is load-bearing for the claim that SSMProbe exploits pre-existing order-dependent token heterogeneity via LTI memory decay. However, the learned permutation introduces additional trainable parameters and task-specific optimization absent from the fixed-scan baselines, raising the possibility that gains reflect greater expressive power of the routing mechanism rather than genuine exploitation of frozen feature structure. A capacity-matched control (e.g., a non-learned but optimized ordering or permutation-agnostic probe with equivalent parameters) is required to isolate the effect.
Authors: We agree that this is a substantive concern and that the current comparison leaves open the possibility that gains are partly due to the added capacity of the Sinkhorn layer. The learned permutation introduces a modest number of parameters (the cost matrix for the soft assignment) that are optimized end-to-end. In the revised §4 we will add two capacity-matched controls: (1) a non-learned but optimized fixed ordering found by searching over permutations on a held-out validation set without joint optimization, and (2) a permutation-agnostic probe (e.g., a small MLP or linear layer on the flattened token sequence) whose parameter count is matched to the full SSMProbe + Sinkhorn model. These additions will allow us to attribute performance differences more cleanly to the exploitation of order-dependent heterogeneity in the frozen representations. We view this as a necessary strengthening of the experimental design. revision: yes
Circularity Check
No circularity; empirical probe comparisons are independent of inputs
full rationale
The paper introduces SSMProbe as an LTI state-space model to test order sensitivity in frozen patch tokens from MAE/BEiT/DINOv2/ViT. It reports empirical gaps between fixed scan orders and a Sinkhorn-optimized soft permutation trained on downstream labels. No derivation equates a claimed result to its own fitted parameters or prior self-citations by construction; the LTI memory decay is a standard property of the SSM, not redefined from the target heterogeneity. The central demonstration rests on benchmark performance differences rather than any tautological reduction. This is the normal self-contained empirical case.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption State space models operating as discrete LTI dynamical systems act as permutation-sensitive probes where sequence order strictly dictates the final state due to inherent memory decay.
Reference graph
Works this paper leans on
-
[1]
BEiT: BERT Pre-Training of Image Transformers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254,
work page internal anchor Pith review arXiv
-
[2]
arXiv:2405.21060. Alexey Dosovitskiy and et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR),
work page internal anchor Pith review arXiv
-
[3]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
arXiv:2010.11929. Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[4]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review arXiv
-
[5]
Li, Berlin Chen, Caitlin Wang, Aviv Bick, J
Albert Gu and Tri Dao. Mamba-3: Improved sequence modeling using state space principles.arXiv preprint arXiv:2603.15569,
-
[6]
Efficiently Modeling Long Sequences with Structured State Spaces
URL https://arxiv.org/abs/2111.00396. NeurIPS 2021, arXiv:2111.00396. Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
work page internal anchor Pith review arXiv 2021
-
[7]
DINOv2: Learning Robust Visual Features without Supervision
arXiv:2304.07193. Catherine Wah, Grant Van Horn, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[8]
Xinjian Wu, Fanhu Zeng, Xiudong Wang, and Xinghao Chen
Technical Report CNS-TR-2010-001, Caltech. Xinjian Wu, Fanhu Zeng, Xiudong Wang, and Xinghao Chen. Ppt: Token pruning and pooling for efficient vision transformers
2010
-
[9]
arXiv:2310.01812. Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Ruslan Salakhutdinov, and Alexander J. Smola. Deep sets. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[10]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xin Wang, Wenjun Wu, and Jae-Joon Kim. Vision mamba: Efficient visual representation learning with bidirectional state space model.arXiv preprint arXiv:2401.09417,
work page internal anchor Pith review arXiv
-
[11]
forgotten
By unrolling the recurrence relation from k= 1 to the final sequence length L (where L≤N depending on optional dropping), the final state vectorz L =h L can be written as a convolution: zL = NX k=1 ¯AN−k ¯B˜tk Here, the term ¯AN−k acts as an attenuation factor. Under appropriate discretization schemes and given these spectral properties of the transition ...
2011
-
[12]
Table 5: Sinkhorn hyperparameter grid search on CUB-200-2011 (5-seed average, frozen MAE)
0.97 0.77 Sinkhorn (S4 + scorer) 0.97 103.99 Transformer 3.43 120.15 DeepSets 1.07 118.35 Random-Fixed Perm + S4 0.97 0.77 Random-Dynamic Perm + S4 0.97 0.77 Sinkhorn + 1D-Conv 0.93 289.70 Bi-GRU 0.95 271.56 hyperparameters (K= 20 , τ= 0.1 ) used in the main experiments are near-optimal, and Sinkhorn is robust across a wide range of hyperparameter setting...
2011
-
[13]
These claims are supported by experimental results in Section 6 showing the order gap between learned permutations (69.39%) and fixed scans ( 64.2%)
GAP 19.57 – CLS 29.01 – 16 NeurIPS Paper Checklist 1.Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Yes] Justification: The abstract and introduction clearly state that (1) SSMProbe is the first SSM- based probing framework, and (2) token order is an important fact...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.