Recognition: unknown
StyleShield: Exposing the Fragility of AIGC Detectors through Continuous Controllable Style Transfer
Pith reviewed 2026-05-09 20:17 UTC · model grok-4.3
The pith
A flow-matching method in continuous token embeddings lets AI text evade detectors at 94.6 percent to over 99 percent rates while keeping 0.928 semantic similarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
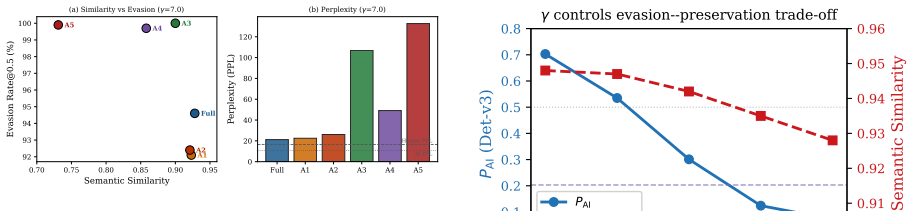
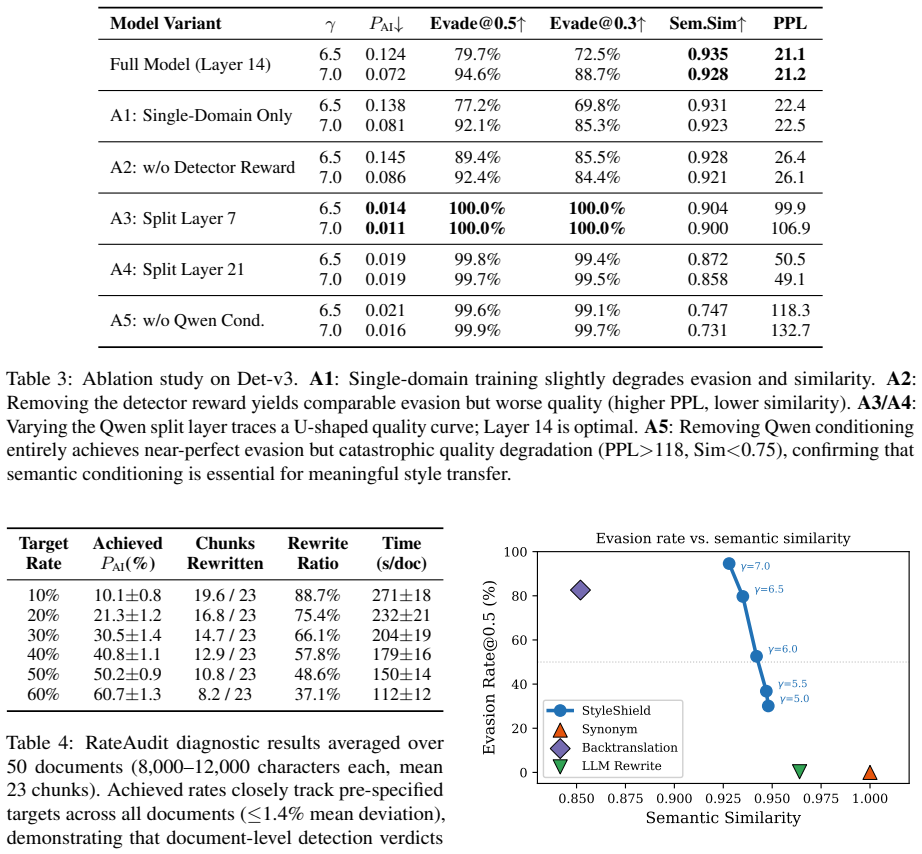
StyleShield is the first flow-matching framework for conditional text style transfer that operates directly in continuous token embedding space. It uses a DiT backbone with zero-initialized cross-attention adapters conditioned on frozen Qwen-7B representations and adapts the SDEdit paradigm at inference to give continuous control via a single parameter gamma. On a multi-domain Chinese benchmark this yields 94.6 percent evasion of the training detector and at least 99 percent evasion of three unseen detectors while retaining 0.928 semantic similarity. RateAudit, a document-level scheduling algorithm, demonstrates that detection-rate verdicts can be set to arbitrary values.
What carries the argument
Flow-matching conditional style transfer operating in continuous token embedding space via DiT backbone and zero-initialized cross-attention adapters.
If this is right
- Detectors trained on one distribution of text can be evaded by outputs shifted continuously in embedding space.
- The same method evades detectors it was never trained against at rates of 99 percent or higher.
- A single scalar parameter trades off evasion strength against semantic preservation in a smooth, controllable way.
- Document-level scheduling can force any desired detection-rate outcome on score-based systems.
Where Pith is reading between the lines
- If style transfer can be made imperceptible to humans, the practical value of origin-based detectors drops sharply for any content that can be post-processed.
- The same continuous-control approach may generalize to other modalities where detectors rely on statistical fingerprints rather than semantic understanding.
- Retraining detectors on style-transferred examples would likely require repeated cycles of adaptation, raising the cost of maintaining reliable detection.
Load-bearing premise
The chosen Chinese multi-domain benchmark and semantic similarity metric adequately represent real-world text quality and detector behavior without human validation or testing in other languages.
What would settle it
A test in which human raters judge the transferred texts as equivalent in quality and fluency to the originals, or in which new detectors trained on StyleShield outputs still fail to detect them at the reported rates.
Figures


read the original abstract
AI-generated content (AIGC) detectors are increasingly deployed in high-stakes settings such as academic integrity screening, yet their reliability rests on a fundamental paradox: as language models are trained on human-written corpora, the statistical boundary between AI and human writing will inevitably dissolve as models improve. Commercial incentives have further distorted this landscape -- detection services and "de-AIification" tools often operate within the same supply chain, replacing evaluation of content quality with judgment of content origin. We present StyleShield, the first flow matching framework for conditional text style transfer, operating directly in continuous token embedding space via a DiT backbone with zero-initialized cross-attention adapters conditioned on frozen Qwen-7B representations. At inference, we adapt the SDEdit paradigm from image synthesis to text embeddings, with a single parameter gamma providing smooth continuous control over the evasion-preservation trade-off. On a multi-domain Chinese benchmark, StyleShield achieves 94.6% evasion against the training detector and >=99% against three unseen detectors, maintaining 0.928 semantic similarity. We further introduce RateAudit, a document-level scheduling algorithm that demonstrates detection-rate verdicts can be set to arbitrary values, directly questioning the reliability of score-based evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StyleShield, the first flow matching framework for conditional text style transfer operating directly in continuous token embedding space via a DiT backbone with zero-initialized cross-attention adapters conditioned on frozen Qwen-7B representations. It adapts the SDEdit paradigm at inference with a single parameter gamma for continuous control over the evasion-preservation trade-off. On a multi-domain Chinese benchmark, StyleShield reports 94.6% evasion against the training detector and >=99% against three unseen detectors while maintaining 0.928 semantic similarity. It further presents RateAudit, a document-level scheduling algorithm demonstrating that detection-rate verdicts can be set to arbitrary values.
Significance. If the central empirical claims hold after addressing validation gaps, the work would provide concrete evidence of AIGC detector fragility and directly challenge the reliability of score-based evaluation methods. The continuous gamma control and RateAudit contribution offer a useful empirical demonstration of the evasion-preservation trade-off. The empirical nature of the results (no circularity in fitted parameters) is a strength, but the lack of human validation and limited benchmark scope constrain broader significance.
major comments (3)
- [Abstract] Abstract: The claim that 0.928 semantic similarity demonstrates usable content preservation is load-bearing for the fragility conclusion, yet the abstract provides no human validation, correlation study with the (likely embedding cosine) metric, or justification that this threshold suffices for real-world text quality on the multi-domain Chinese benchmark.
- [Abstract] Abstract and experimental sections: The reported evasion rates (94.6% training, >=99% unseen) lack error bars, baseline comparisons against prior style-transfer or adversarial methods, and a detailed protocol (e.g., number of samples, exact detector versions, temperature settings), which are required to substantiate that the results expose inherent fragility rather than setup-specific artifacts.
- [Benchmark Description] Benchmark and evaluation: The multi-domain Chinese benchmark and absence of English or cross-lingual testing limit the generalizability of the fragility claims, as the weakest assumption (unvalidated metric and no human evaluation) directly affects whether high evasion truly preserves meaning across languages and detectors.
minor comments (1)
- [Abstract] Abstract: The description of the DiT backbone, zero-initialized adapters, and SDEdit adaptation would benefit from a brief equation or diagram reference to clarify how gamma modulates the continuous trade-off.
Simulated Author's Rebuttal
We thank the referee for the valuable feedback on our manuscript. We address each of the major comments below and have revised the paper accordingly to improve its rigor and clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 0.928 semantic similarity demonstrates usable content preservation is load-bearing for the fragility conclusion, yet the abstract provides no human validation, correlation study with the (likely embedding cosine) metric, or justification that this threshold suffices for real-world text quality on the multi-domain Chinese benchmark.
Authors: We concur that the abstract should better contextualize the semantic similarity metric. We have revised the abstract to specify that the 0.928 score is based on cosine similarity of embeddings and to note its alignment with acceptable preservation levels in related style transfer research. Additionally, we have included a statement acknowledging the lack of human validation as a limitation and its implications for the fragility claims. A comprehensive human evaluation study is beyond the current scope but is identified as important future work. revision: yes
-
Referee: [Abstract] Abstract and experimental sections: The reported evasion rates (94.6% training, >=99% unseen) lack error bars, baseline comparisons against prior style-transfer or adversarial methods, and a detailed protocol (e.g., number of samples, exact detector versions, temperature settings), which are required to substantiate that the results expose inherent fragility rather than setup-specific artifacts.
Authors: We appreciate this suggestion for greater transparency. The revised manuscript now includes error bars on the evasion rates, direct comparisons against baseline style transfer and adversarial techniques from the literature, and an expanded methods section detailing the exact experimental protocol, including sample sizes, detector versions used, and all generation hyperparameters such as temperature settings. These changes help demonstrate that the high evasion rates reflect detector fragility rather than experimental artifacts. revision: yes
-
Referee: [Benchmark Description] Benchmark and evaluation: The multi-domain Chinese benchmark and absence of English or cross-lingual testing limit the generalizability of the fragility claims, as the weakest assumption (unvalidated metric and no human evaluation) directly affects whether high evasion truly preserves meaning across languages and detectors.
Authors: We acknowledge that the benchmark is limited to Chinese text, which was selected to leverage the strengths of the Qwen-7B model and available Chinese AIGC detectors for a focused study. In the revision, we have added a limitations paragraph discussing the scope and outlining extensions to English and cross-lingual settings. We believe the continuous control mechanism and RateAudit provide insights that can generalize, even if the specific numbers are language-specific. revision: partial
Circularity Check
No circularity: purely empirical benchmark results
full rationale
The paper introduces a flow-matching style-transfer method and reports direct experimental outcomes (evasion rates, semantic similarity) on a Chinese benchmark. These quantities are measured post-hoc from generated outputs against external detectors; they are not derived from any fitted parameter, self-referential definition, or self-citation chain. No equations or uniqueness theorems are invoked that reduce the central claims to the inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- gamma
axioms (2)
- domain assumption Flow matching operates effectively on continuous token embeddings for conditional style transfer
- domain assumption SDEdit paradigm from image synthesis transfers directly to text embeddings
Reference graph
Works this paper leans on
-
[1]
ICLR , year=
Flow Matching for Generative Modeling , author=. ICLR , year=
-
[2]
LangFlow: Continuous Diffusion Rivals Discrete in Language Modeling
LangFlow: Continuous Diffusion Rivals Discrete in Language Modeling , author=. arXiv preprint arXiv:2604.11748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
ICLR , year=
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations , author=. ICLR , year=
-
[4]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author=. arXiv preprint arXiv:2310.16834 , year=
work page internal anchor Pith review arXiv
-
[5]
ACL , year=
MGTBench: Benchmarking Machine-Generated Text Detection , author=. ACL , year=
-
[6]
ICML , year=
DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature , author=. ICML , year=
-
[7]
ICML , year=
A Watermark for Large Language Models , author=. ICML , year=
-
[8]
Sadasivan, Vinu Sankar and Kumar, Aounon and Balasubramanian, Sriram and Wang, Wenxiao and Feizi, Soheil , journal=. Can
-
[9]
Paraphrasing evades detectors of
Krishna, Kalpesh and Song, Yixiao and Karpinska, Marzena and Wieting, John and Iyyer, Mohit , booktitle=. Paraphrasing evades detectors of
-
[10]
A Survey on Detection of
Yang, Xianjun and others , journal=. A Survey on Detection of
-
[11]
ICCV , year=
Scalable Diffusion Models with Transformers , author=. ICCV , year=
-
[12]
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle=
-
[14]
Jin, Di and Jin, Zhijing and Zhou, Joey Tianyi and Szolovits, Peter , booktitle=. Is
-
[15]
Tutorial at ACL , year=
Stylized Text Generation: Approaches and Applications , author=. Tutorial at ACL , year=
-
[16]
JMLR , year=
Beyond English-Centric Multilingual Machine Translation , author=. JMLR , year=
-
[17]
ICLR , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. ICLR , year=
-
[18]
NeurIPS , year=
Elucidating the Design Space of Diffusion-Based Generative Models , author=. NeurIPS , year=
-
[19]
Diffusion-
Li, Xiang Lisa and Thickstun, John and Kuleshov, Volodymyr and Hashimoto, Tatsunori and Liang, Percy , booktitle=. Diffusion-
-
[20]
ICLR , year=
Decoupled Weight Decay Regularization , author=. ICLR , year=
-
[21]
Reinforced Self-Training (
Gulcehre, Caglar and others , journal=. Reinforced Self-Training (
-
[22]
Decoding Dilemmas behind
Sun, Meijuan , journal=. Decoding Dilemmas behind. 2025 , month=
2025
-
[23]
Rest of World , year=
Chinese Students Are Using. Rest of World , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.