Recognition: unknown
LangFlow: Continuous Diffusion Rivals Discrete in Language Modeling
Pith reviewed 2026-05-10 16:22 UTC · model grok-4.3
The pith
Continuous diffusion rivals discrete diffusion for language modeling
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LangFlow connects embedding-space diffusion language models to flow matching via Bregman divergence and adds three innovations—an ODE-based NLL bound for evaluation, an information-uniform Gumbel scheduler, and self-conditioning—to rival top discrete DLMs on both perplexity and generative perplexity while exceeding autoregressive baselines in zero-shot transfer on four of seven benchmarks.
What carries the argument
Embedding-space continuous flow matching connected to Bregman divergence, equipped with a learnable Gumbel noise scheduler for uniform information and self-conditioning during training.
If this is right
- Continuous diffusion becomes a competitive alternative to discrete methods for language tasks.
- The information-uniform principle offers a principled way to set noise schedules for sparse discrete data.
- Self-conditioning improves both likelihood and sample quality in embedding-space models in ways distinct from discrete diffusion.
- Such models can achieve zero-shot transfer that exceeds autoregressive baselines on multiple benchmarks.
Where Pith is reading between the lines
- Continuous diffusion could bring few-step controllable generation to language similar to its success in images.
- This opens a path toward unified continuous generative frameworks that treat text alongside other modalities without discrete tokenization.
- Researchers might test whether the approach reduces dependence on large token vocabularies or enables more flexible sampling strategies.
Load-bearing premise
That operating in embedding space together with the Gumbel scheduler and self-conditioning sufficiently overcomes the sparsity and discreteness of language data to enable stable continuous flow matching.
What would settle it
A direct head-to-head evaluation in which LangFlow shows higher perplexity or lower generative quality than leading discrete DLMs on LM1B or OpenWebText under matched conditions.
Figures

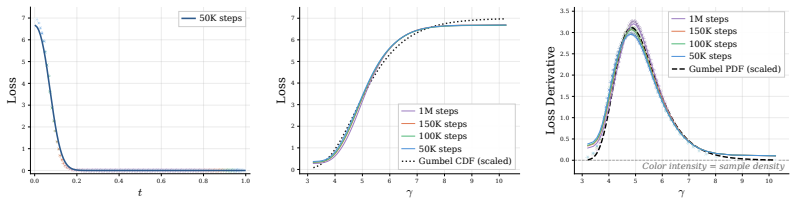

read the original abstract
Continuous diffusion has been the foundation of high-fidelity, controllable, and few-step generation of many data modalities such as images. However, in language modeling, prior continuous diffusion language models (DLMs) lag behind discrete counterparts due to the sparse data space and the underexplored design space. In this work, we close this gap with LangFlow, the first continuous DLM to rival discrete diffusion, by connecting embedding-space DLMs to Flow Matching via Bregman divergence, alongside three key innovations: (1) we derive a novel ODE-based NLL bound for principled evaluation of continuous flow-based language models; (2) we propose an information-uniform principle for setting the noise schedule, which motivates a learnable noise scheduler based on a Gumbel distribution; and (3) we revise prior training protocols by incorporating self-conditioning, as we find it improves both likelihood and sample quality of embedding-space DLMs with effects substantially different from discrete diffusion. Putting everything together, LangFlow rivals top discrete DLMs on both the perplexity (PPL) and the generative perplexity (Gen. PPL), reaching a PPL of 30.0 on LM1B and 24.6 on OpenWebText. It even exceeds autoregressive baselines in zero-shot transfer on 4 out of 7 benchmarks. LangFlow provides the first clear evidence that continuous diffusion is a promising paradigm for language modeling. Homepage: https://github.com/nealchen2003/LangFlow
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LangFlow, a continuous diffusion language model (DLM) that operates in embedding space using flow matching connected via Bregman divergence. It proposes three innovations: (1) a novel ODE-based negative log-likelihood (NLL) bound for evaluation, (2) an information-uniform Gumbel noise scheduler, and (3) self-conditioning during training. Empirically, LangFlow reports PPL of 30.0 on LM1B and 24.6 on OpenWebText, rivaling top discrete DLMs, along with competitive generative PPL and zero-shot transfer exceeding autoregressive baselines on 4 of 7 tasks.
Significance. If the ODE NLL bound is sufficiently tight and the comparisons hold, this would be the first demonstration that continuous diffusion can match discrete DLMs on language modeling benchmarks, potentially shifting focus toward continuous methods for their controllability and sampling efficiency advantages. The work provides concrete benchmark numbers and an open-source implementation, strengthening its contribution if the evaluation methodology is validated.
major comments (2)
- [§3.2] §3.2 (ODE-based NLL bound): The central PPL claims (30.0 on LM1B, 24.6 on OpenWebText) rely on this novel bound derived from the probability flow ODE and Bregman divergence. It is unclear whether the bound is tight, unbiased, or systematically over- or under-estimates the true likelihood relative to the exact NLLs reported by discrete DLMs; without tightness experiments (e.g., variance analysis or comparison to alternative continuous estimators), the rivalry conclusion risks being overstated.
- [§4.3] §4.3 (self-conditioning ablation): Self-conditioning is reported to improve both likelihood and sample quality, yet its interaction with the ODE NLL bound is not isolated. The paper should quantify how self-conditioning affects the bound tightness separately from its effect on training dynamics, as unisolated effects could confound attribution of the reported PPL gains.
minor comments (3)
- [Table 2] Table 2: The generative PPL numbers lack error bars or multiple random seeds; reporting standard deviations across runs would strengthen the comparison to discrete baselines.
- [§5.1] §5.1: The zero-shot transfer results on the 7 benchmarks would benefit from explicit listing of the exact tasks and whether the same prompt format was used across all models.
- [§3.1] Notation in §3.1: The definition of the information-uniform scheduler could be clarified with a short pseudocode snippet to distinguish it from standard Gumbel noise.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below with point-by-point responses and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (ODE-based NLL bound): The central PPL claims (30.0 on LM1B, 24.6 on OpenWebText) rely on this novel bound derived from the probability flow ODE and Bregman divergence. It is unclear whether the bound is tight, unbiased, or systematically over- or under-estimates the true likelihood relative to the exact NLLs reported by discrete DLMs; without tightness experiments (e.g., variance analysis or comparison to alternative continuous estimators), the rivalry conclusion risks being overstated.
Authors: We appreciate the referee's concern about the tightness and potential bias of the ODE-based NLL bound. The bound is derived directly from the probability flow ODE of the flow-matching process and the Bregman divergence between the embedding-space distributions, yielding a valid upper bound on the negative log-likelihood that is consistent with the training objective. While the manuscript presents the bound as a principled evaluation method, we acknowledge that explicit tightness validation would strengthen the claims. In the revised version, we will add variance analysis across multiple evaluation runs and comparisons against alternative continuous estimators (e.g., importance sampling variants) to quantify any systematic deviation and confirm that the reported PPL values remain competitive under these checks. revision: yes
-
Referee: [§4.3] §4.3 (self-conditioning ablation): Self-conditioning is reported to improve both likelihood and sample quality, yet its interaction with the ODE NLL bound is not isolated. The paper should quantify how self-conditioning affects the bound tightness separately from its effect on training dynamics, as unisolated effects could confound attribution of the reported PPL gains.
Authors: We thank the referee for this observation on isolating effects. Self-conditioning alters the training dynamics by feeding the model's intermediate predictions back as conditioning signals, which improves the learned data distribution in embedding space. The ODE NLL bound is an evaluation procedure applied after training and does not depend on the training procedure itself. To address the potential confounding, the revised manuscript will include an expanded ablation table that reports both the training objective values and the NLL bound tightness (measured via repeated forward passes and variance) for models trained with and without self-conditioning. This will allow readers to attribute the PPL improvements primarily to better modeling rather than evaluation artifacts. revision: yes
Circularity Check
No significant circularity; empirical benchmarks with derived evaluation bound
full rationale
The paper's primary claims rest on empirical benchmark results (PPL 30.0 on LM1B, 24.6 on OpenWebText, zero-shot transfer) rather than any derivation that reduces to its own inputs by construction. The ODE-based NLL bound is explicitly derived for evaluation purposes and does not define or tautologically reproduce the reported performance numbers. Design choices such as the Gumbel scheduler and self-conditioning are presented as innovations validated through experiments, with no evidence of self-citation load-bearing, fitted inputs renamed as predictions, or ansatzes smuggled via prior work. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Gumbel-based noise scheduler parameters
axioms (2)
- domain assumption Bregman divergence provides a valid bridge between embedding-space discrete language models and continuous flow matching
- standard math The derived ODE-based NLL bound is a principled and tight evaluator for continuous flow-based language models
Forward citations
Cited by 3 Pith papers
-
Sampling from Flow Language Models via Marginal-Conditioned Bridges
Marginal-conditioned bridges enable training-free sampling from Flow Language Models by drawing clean one-hot endpoints from factorized posteriors and using Ornstein-Uhlenbeck bridges, preserving token marginals and r...
-
StyleShield: Exposing the Fragility of AIGC Detectors through Continuous Controllable Style Transfer
StyleShield uses flow matching in continuous token embeddings with a DiT backbone to achieve 94.6% evasion on trained detectors and over 99% on unseen ones in Chinese benchmarks, with 0.928 semantic similarity, plus a...
-
ELF: Embedded Language Flows
ELF is a continuous embedding-space flow matching model for language that stays continuous until the last step and outperforms prior discrete and continuous diffusion language models with fewer sampling steps.
Reference graph
Works this paper leans on
-
[1]
Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Sub- ham Sekhar Sahoo, and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregres- sive and diffusion language models.arXiv preprint arXiv:2503.09573,
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127,
work page internal anchor Pith review arXiv
-
[3]
One billion word benchmark for measuring progress in statistical language modeling
Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. One billion word benchmark for measuring progress in statistical language modeling. arXiv preprint arXiv:1312.3005,
-
[4]
Ting Chen, Ruixiang Zhang, and Geoffrey Hinton. Analog bits: Generating discrete data using diffusion models with self-conditioning.arXiv preprint arXiv:2208.04202,
-
[5]
Chaoran Cheng, Jiahan Li, Jiajun Fan, and Ge Liu. α-flow: A unified framework for continuous-state discrete flow matching models.arXiv preprint arXiv:2504.10283, 2025a. Shuang Cheng, Yihan Bian, Dawei Liu, Linfeng Zhang, Qian Yao, Zhongbo Tian, Wenhai Wang, Qipeng Guo, Kai Chen, Biqing Qi, et al. Sdar: A synergistic diffusion-autoregression paradigm for s...
-
[6]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[7]
Continu- ous diffusion for categorical data.arXiv preprint arXiv:2211.15089, 2022
Sander Dieleman, Laurent Sartran, Arman Roshannai, Nikolay Savinov, Yaroslav Ganin, Pierre H Richemond, Arnaud Doucet, Robin Strudel, Chris Dyer, Conor Durkan, et al. Continuous diffusion for categorical data.arXiv preprint arXiv:2211.15089,
-
[8]
Shansan Gong, Mukai Li, Jiangtao Feng, Zhiyong Wu, and LingPeng Kong. Diffuseq: Sequence to sequence text generation with diffusion models.arXiv preprint arXiv:2210.08933,
-
[9]
12 Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, et al. Scaling diffusion language models via adaptation from autoregressive models.arXiv preprint arXiv:2410.17891,
-
[10]
Andrés Guzmán-Cordero, Floor Eijkelboom, and Jan-Willem Van De Meent. Exponential family variational flow matching for tabular data generation.arXiv preprint arXiv:2506.05940,
-
[11]
Continuous diffusion model for language modeling
Jaehyeong Jo and Sung Ju Hwang. Continuous diffusion model for language modeling.arXiv preprint arXiv:2502.11564,
-
[12]
Flow Map Language Models: One-step Language Modeling via Continuous Denoising
Chanhyuk Lee, Jaehoon Yoo, Manan Agarwal, Sheel Shah, Jerry Huang, Aditi Raghunathan, Se- unghoon Hong, Nicholas M Boffi, and Jinwoo Kim. One-step language modeling via continuous denoising.arXiv preprint arXiv:2602.16813,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
URLhttps://openreview.net/forum?id=PqvMRDCJT9t. Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834,
work page internal anchor Pith review arXiv
-
[14]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji- Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review arXiv
-
[15]
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data.arXiv preprint arXiv:2406.03736,
-
[16]
Kevin Rojas, Yuchen Zhu, Sichen Zhu, Felix X-F Ye, and Molei Tao. Diffuse everything: Multimodal diffusion models on arbitrary state spaces.arXiv preprint arXiv:2506.07903,
-
[17]
The diffusion duality.arXiv preprint arXiv:2506.10892, 2025
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin Chiu, and V olodymyr Kuleshov. The diffusion duality.arXiv preprint arXiv:2506.10892, 2025a. Subham Sekhar Sahoo, Zhihan Yang, Yash Akhauri, Johnna Liu, Deepansha Singh, Zhoujun Cheng, Zhengzhong Liu, Eric Xing, John Thickstun, and Arash Vahdat. Esoteric language models.arXiv pr...
-
[18]
Junzhe Shen, Jieru Zhao, Ziwei He, and Zhouhan Lin. Codar: Continuous diffusion language models are more powerful than you think.arXiv preprint arXiv:2603.02547,
-
[19]
Yuxuan Song, Zhe Zhang, Yu Pei, Jingjing Gong, Qiying Yu, Zheng Zhang, Mingxuan Wang, Hao Zhou, Jingjing Liu, and Wei-Ying Ma. Shortlisting model: A streamlined simplexdiffusion for discrete variable generation.arXiv preprint arXiv:2508.17345,
-
[20]
The Eleventh International Conference on Learning Representations , publisher =
Clement Vignac, Igor Krawczuk, Antoine Siraudin, Bohan Wang, V olkan Cevher, and Pascal Frossard. Digress: Discrete denoising diffusion for graph generation.arXiv preprint arXiv:2209.14734,
-
[21]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487,
work page internal anchor Pith review arXiv
-
[22]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Chunting Zhou, Lili Yu, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Levy. Transfusion: Predict the next token and diffuse images with one multi-modal model.arXiv preprint arXiv:2408.11039,
work page internal anchor Pith review arXiv
-
[23]
− ∥zb∥2 2σ2 b + Z b a ∇zγ ·v θ(zγ, γ) dγ+ log ˆp(x|z a) # + LD 2 log eσ2 a σ2 b (41) =E p(za|x)
14 Appendices A LangFlow A.1 Algorithms We summarize the complete training and sampling procedures of LangFlow in Algorithm 1 and Algorithm 2, respectively. Algorithm 1Training 1:repeat 2:x∼p data,z= (e x(1) , . . . ,ex(L) ) 3:q= clip(Uniform(0,1),10 −5,1−10 −5)using low-discrepancy sampler 4:γ= stopgrad(P µ −P β log(−logq)) 5:α γ = p sigmoid(−γ), σγ = p ...
2024
-
[24]
This strategy aligns the variance of our data to that of the noise, which follows the practice in latent diffusion (Rombach et al., 2022). Third, following Plaid (Gulrajani & Hashimoto, 2023), we add a tokenwise bias term rlogp(z (i) γ |x (i)) to the predicted logits log ˆx(i)(z(i) γ , γ), where logp(z (i) γ |x (i)) =− ∥z(i) γ −α γex(i) ∥2 2σ2γ = αγ σ2γ e...
2022
-
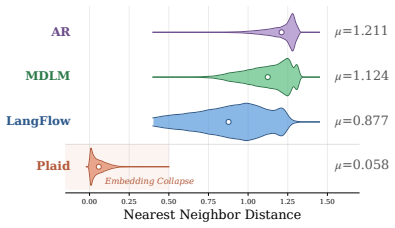
[25]
Table 4:Model and training setup. Feature Ours & Other Baselines Plaid # Parameters 130M 108M Backbone Transformer Transformer Embedding Dim 768 16 Layers / Hidden Dim 16 / 768 16 / 768 Time Conditioning AdaLN Addition Training Budget (GPU hours / GPU)∼292∼375 Optimizer AdamW AdamW Batch Size 512 512 Embedding Collapse under Mean Square Error .In Section ...
2024
-
[26]
run”to semantically related alternatives such as“go
and Plaid (Gulra- jani & Hashimoto, 2023). However, we empirically observe collapse in the token embedding layer when using this objective. Specifically, we visualize the distribution of the distance to the nearest neighbor (NND) of one token embedding for every token in the vocabulary, which describes how different token embeddings scatter in the whole s...
2023
-
[27]
heady and restrain
6 million in gross revenue for the three months that ended dec. [CLS] " heady and restrain " also contains a probaquiial reporting that touches [CLS] Sample 2 Generative Perplexity: 110.6519; Sample Entropy: 4.3081 [CLS] the science universe, where more than 1, 000 scientists around the world are searching for planets, the observations offer a better futu...
1999
-
[28]
grey’s anatomy
[CLS] kudos - - although " grey’s anatomy " may be as bad a money - making venture as that : the essential nervous breakdown : at the time of the source coronation for hbo ( no longer ). [CLS] in the 1990s the ranks were swelled with more than 4, 000 people needing kidney transplants only in hospitals and not seen by medics or local clinicians each year. ...
1936
-
[29]
could do nothing but drop her
We’ve probably heard a lot of discussions about privilege and how much distress it causes,’ said Wilson, who worked President Bush on state from 1991 to 2003 and is until recently a director of the American Center for the Study of Mental Health. ’It’s more of a taboo discussion.’ Not all Americans are concerned about mental health. The U.S. Census has est...
1991
-
[30]
But Gerrard was sort of annoying unseasonably and was the best NYCFC could reply to for a few decades, but then a strike and a similar mass casualty flood in the early 2000s
(use only IF YOU W ANT TO) which 05-16-2015 ’31:12 4,267 (CADES°.131-487, 23-7-2015, 96-67-16), 67-76 Publication(s): PERSONAL AGENDA ’ OPEN OBSESSION AND 28 Duo Sample Generative Perplexity: 68.9153; Sample Entropy: 5.4827 Power Premier League’s outfit and subsequently won the 2007 national team spot. But Gerrard was sort of annoying unseasonably and wa...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.