Recognition: 2 theorem links
· Lean TheoremFrom Flat Facts to Sharp Hallucinations: Detecting Stubborn Errors via Gradient Sensitivity
Pith reviewed 2026-05-13 07:51 UTC · model grok-4.3
The pith
Perturbing input embeddings with noise detects stubborn hallucinations by exposing sharp minima in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EPGS identifies stubborn hallucinations by perturbing embeddings and tracking gradient spikes, which signal sharp minima tied to brittle memorization instead of the flat regions holding robust facts.
What carries the argument
Embedding-Perturbed Gradient Sensitivity (EPGS), a technique that adds Gaussian noise to input embeddings and measures the resulting rise in gradient magnitude to approximate sharpness in the loss surface.
Load-bearing premise
Stubborn hallucinations occupy sharp minima due to brittle memorization while robust facts occupy flat minima.
What would settle it
Finding a case where EPGS scores low on a known high-confidence hallucination or high on a verified fact, or where noise perturbation does not correlate with error confidence.
Figures




read the original abstract
Traditional hallucination detection fails on "Stubborn Hallucinations" - errors where LLMs are confidently wrong. We propose a geometric solution: Embedding-Perturbed Gradient Sensitivity (EPGS). We hypothesize that while robust facts reside in flat minima, stubborn hallucinations sit in sharp minima, supported by brittle memorization. EPGS detects this sharpness by perturbing input embeddings with Gaussian noise and measuring the resulting spike in gradient magnitude. This acts as an efficient proxy for the Hessian spectrum, differentiating stable knowledge from unstable memorization. Our experiments show that EPGS significantly outperforms entropy-based and representation-based baselines, providing a robust signal for detecting high-confidence factual errors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Embedding-Perturbed Gradient Sensitivity (EPGS) to detect stubborn hallucinations in LLMs. It hypothesizes that robust facts occupy flat minima while hallucinations occupy sharp minima supported by brittle memorization, and claims that perturbing input embeddings with Gaussian noise and measuring the resulting spike in gradient magnitude serves as an efficient proxy for the Hessian spectrum, outperforming entropy-based and representation-based baselines on high-confidence factual errors.
Significance. If the proxy relation between input-embedding perturbations and parameter-space curvature holds and the reported outperformance is reproducible with proper controls, the work would supply a geometrically motivated, low-overhead signal for hallucination detection that complements existing uncertainty measures. The absence of any derivation or validation for the geometric claim, however, leaves the central hypothesis unanchored.
major comments (3)
- [Abstract / Method] Abstract and Method section: the assertion that EPGS 'acts as an efficient proxy for the Hessian spectrum' is unsupported. Input-embedding perturbation followed by ||∇_θ L|| measurement captures local input-to-loss sensitivity (potentially dominated by embedding-layer Lipschitz constants or token noise), not the curvature of the loss with respect to model parameters θ that defines flat/sharp minima. No derivation equates the two quantities, and no comparison is made to standard sharpness diagnostics such as loss change under θ-perturbations or stochastic Hessian-trace estimators.
- [Experiments] Experiments section: the claim that 'EPGS significantly outperforms entropy-based and representation-based baselines' is presented without dataset descriptions, implementation hyperparameters, error bars, ablation studies, or statistical significance tests. This renders the central empirical claim unverifiable and prevents assessment of whether the reported signal is robust or merely an artifact of the chosen evaluation protocol.
- [Introduction / Hypothesis] Hypothesis paragraph: the geometric premise that 'stubborn hallucinations sit in sharp minima, supported by brittle memorization' is treated as given, yet the manuscript supplies neither a formal link between memorization and Hessian eigenvalues nor any diagnostic (e.g., loss landscape visualization or parameter-perturbation experiments) that would confirm the flat/sharp distinction for the factual versus hallucinated cases.
minor comments (3)
- [Method] Notation for the EPGS statistic (Gaussian noise variance, gradient-norm aggregation, etc.) should be defined explicitly with an equation rather than left implicit.
- [Related Work] Add citations to prior literature on flat/sharp minima (e.g., Hochreiter & Schmidhuber 1997, Keskar et al. 2017) and to existing gradient-based hallucination detectors to clarify novelty.
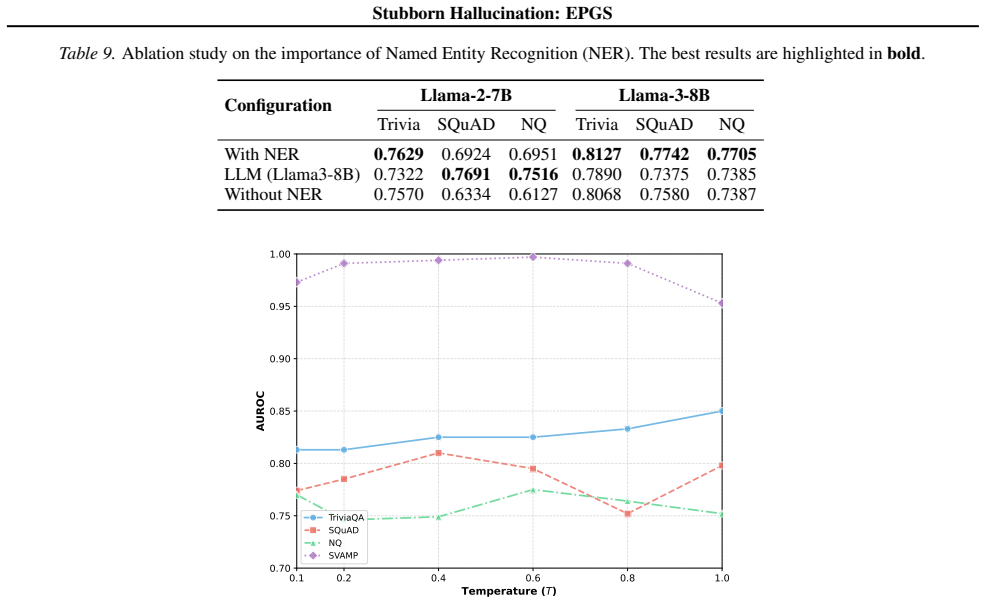
- [Figures] Figure captions should state the exact number of runs, seeds, and confidence intervals shown.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments highlight important areas for clarification and strengthening, particularly regarding theoretical grounding and experimental rigor. We address each major comment below and describe the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and Method section: the assertion that EPGS 'acts as an efficient proxy for the Hessian spectrum' is unsupported. Input-embedding perturbation followed by ||∇_θ L|| measurement captures local input-to-loss sensitivity (potentially dominated by embedding-layer Lipschitz constants or token noise), not the curvature of the loss with respect to model parameters θ that defines flat/sharp minima. No derivation equates the two quantities, and no comparison is made to standard sharpness diagnostics such as loss change under θ-perturbations or stochastic Hessian-trace estimators.
Authors: We acknowledge that the manuscript currently lacks a formal derivation linking input-embedding perturbations to the Hessian spectrum of the loss with respect to parameters. The proxy is motivated by the chain-rule relationship between input sensitivity and parameter curvature, but we agree this requires explicit justification and comparison to standard diagnostics. In revision we will add a dedicated subsection in Methods deriving the connection under simplifying assumptions (e.g., locally linear embeddings) and include direct comparisons to parameter-perturbation sharpness measures and stochastic Hessian-trace estimators on a subset of models where computation is tractable. We will also state the limitations of the proxy explicitly. revision: partial
-
Referee: [Experiments] Experiments section: the claim that 'EPGS significantly outperforms entropy-based and representation-based baselines' is presented without dataset descriptions, implementation hyperparameters, error bars, ablation studies, or statistical significance tests. This renders the central empirical claim unverifiable and prevents assessment of whether the reported signal is robust or merely an artifact of the chosen evaluation protocol.
Authors: We agree that the current presentation of results omits necessary experimental details. The full manuscript contains the underlying datasets, code, and runs, but these were not reported with sufficient granularity. In the revised version we will expand the Experiments section to include: (i) complete dataset descriptions and splits, (ii) all hyperparameters and perturbation variances, (iii) error bars from at least five independent runs, (iv) ablation studies on noise scale and number of perturbations, and (v) statistical significance tests (paired t-tests with p-values) against each baseline. These additions will make the performance claims fully verifiable. revision: yes
-
Referee: [Introduction / Hypothesis] Hypothesis paragraph: the geometric premise that 'stubborn hallucinations sit in sharp minima, supported by brittle memorization' is treated as given, yet the manuscript supplies neither a formal link between memorization and Hessian eigenvalues nor any diagnostic (e.g., loss landscape visualization or parameter-perturbation experiments) that would confirm the flat/sharp distinction for the factual versus hallucinated cases.
Authors: The flat-versus-sharp hypothesis is presented as the motivating premise rather than a proven theorem. While a closed-form link between memorization and Hessian eigenvalues is not supplied, we will strengthen the claim empirically. The revision will add a new subsection containing (a) loss-landscape visualizations obtained by perturbing parameters along random directions for factual versus hallucinated examples and (b) quantitative parameter-perturbation experiments measuring loss increase under small θ-perturbations. These diagnostics will provide direct evidence supporting the geometric distinction. revision: yes
Circularity Check
No significant circularity; EPGS defined independently of target labels
full rationale
The paper states a hypothesis that facts occupy flat minima and hallucinations occupy sharp minima, then defines EPGS explicitly as input-embedding perturbation followed by gradient-magnitude measurement. No equation or section equates EPGS to the target sharpness quantity by construction, nor does any self-citation supply the missing equivalence. The method is presented as an independent proxy rather than a quantity fitted or renamed from the labels it is meant to detect. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Robust facts reside in flat minima while stubborn hallucinations sit in sharp minima supported by brittle memorization
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe hypothesize that while robust facts reside in flat minima, stubborn hallucinations sit in sharp minima... EPGS detects this sharpness by perturbing input embeddings with Gaussian noise and measuring the resulting spike in gradient magnitude. This acts as an efficient proxy for the Hessian spectrum
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearTheorem 3.4 (Gradient Sensitivity Bounds Hessian Curvature)... ∥∇θL(θ∗;x+ϵ,ŷ)∥² ≲ λ_max(H)·∥ν_ϵ∥²
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima , author=. International Conference on Learning Representations , year=
-
[2]
Hochreiter, Sepp and Schmidhuber, J\". Flat minima , year =. doi:10.1162/neco.1997.9.1.1 , journal =
-
[3]
Proceedings of the 52nd annual ACM SIGACT symposium on theory of computing , pages=
Does learning require memorization? a short tale about a long tail , author=. Proceedings of the 52nd annual ACM SIGACT symposium on theory of computing , pages=
-
[4]
International conference on machine learning , pages=
A closer look at memorization in deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[5]
Are NLP Models really able to Solve Simple Math Word Problems?
Patel, Arkil and Bhattamishra, Satwik and Goyal, Navin. Are NLP Models really able to Solve Simple Math Word Problems?. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.168
-
[6]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[7]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy. SQ u AD : 100,000+ Questions for Machine Comprehension of Text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1264. 1606.05250 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/d16-1264 2016
-
[8]
Transactions of the Association for Computational Linguistics , author =
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav. Natura...
-
[9]
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
work page 2023
- [10]
- [11]
-
[12]
International Conference on Learning Representations , year=
Uncertainty Estimation in Autoregressive Structured Prediction , author=. International Conference on Learning Representations , year=
-
[13]
Language Models (Mostly) Know What They Know , author=. 2022 , eprint=
work page 2022
-
[14]
Detecting hallucinations in large language models using semantic entropy , author=. Nature , volume=. 2024 , doi=
work page 2024
-
[15]
Chao Chen and Kai Liu and Ze Chen and Yi Gu and Yue Wu and Mingyuan Tao and Zhihang Fu and Jieping Ye , booktitle=. 2024 , url=
work page 2024
-
[16]
Revisiting Hallucination Detection with Effective Rank-based Uncertainty , author=. 2025 , eprint=
work page 2025
-
[17]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[18]
International Conference on Learning Representations , year=
FreeLB: Enhanced Adversarial Training for Natural Language Understanding , author=. International Conference on Learning Representations , year=
-
[19]
B ayesian Prompt Ensembles: Model Uncertainty Estimation for Black-Box Large Language Models
Tonolini, Francesco and Aletras, Nikolaos and Massiah, Jordan and Kazai, Gabriella. B ayesian Prompt Ensembles: Model Uncertainty Estimation for Black-Box Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.728
- [20]
-
[21]
Survey of hallucination in natural language generation,
Ji, Ziwei and Lee, Nayeon and Frieske, Rita and Yu, Tiezheng and Su, Dan and Xu, Yan and Ishii, Etsuko and Bang, Ye Jin and Madotto, Andrea and Fung, Pascale , year=. Survey of Hallucination in Natural Language Generation , volume=. ACM Computing Surveys , publisher=. doi:10.1145/3571730 , number=
-
[22]
S iren ' s Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Zhang, Yue and Li, Yafu and Cui, Leyang and Cai, Deng and Liu, Lemao and Fu, Tingchen and Huang, Xinting and Zhao, Enbo and Zhang, Yu and Chen, Yulong and Wang, Longyue and Luu, Anh Tuan and Bi, Wei and Shi, Freda and Shi, Shuming. S iren ' s Song in the AI Ocean: A Survey on Hallucination in Large Language Models. Computational Linguistics. 2025. doi:10....
-
[23]
Huang, Lei and Yu, Weijiang and Ma, Weitao and Zhong, Weihong and Feng, Zhangyin and Wang, Haotian and Chen, Qianglong and Peng, Weihua and Feng, Xiaocheng and Qin, Bing and Liu, Ting , year=. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions , volume=. ACM Transactions on Information Systems , publis...
-
[24]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00638
-
[25]
Transactions on Machine Learning Research , issn=
Teaching Models to Express Their Uncertainty in Words , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
work page 2022
-
[26]
Andrew P. Bradley , keywords =. The use of the area under the ROC curve in the evaluation of machine learning algorithms , journal =. 1997 , issn =. doi:https://doi.org/10.1016/S0031-3203(96)00142-2 , url =
-
[27]
Proceedings of the 34th International Conference on Machine Learning , pages =
Sharp Minima Can Generalize For Deep Nets , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
work page 2017
-
[28]
International Conference on Learning Representations , year=
Fantastic Generalization Measures and Where to Find Them , author=. International Conference on Learning Representations , year=
- [29]
- [30]
-
[31]
Bradley Efron and Robert J Tibshirani.An introduction to the bootstrap, volume
Lin, Stephanie and Hilton, Jacob and Evans, Owain. T ruthful QA : Measuring How Models Mimic Human Falsehoods. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.229
-
[32]
H alu E val: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models
Li, Junyi and Cheng, Xiaoxue and Zhao, Xin and Nie, Jian-Yun and Wen, Ji-Rong. H alu E val: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.397
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.