Recognition: unknown
Divergence is Uncertainty: A Closed-Form Posterior Covariance for Flow Matching
Pith reviewed 2026-05-09 20:30 UTC · model grok-4.3
The pith
For any pre-trained flow matching velocity field the trace of the posterior covariance equals the divergence of that field up to a time-dependent factor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We prove that for any pre-trained flow matching velocity field the trace of the posterior covariance over the clean data given the current state equals the divergence of the velocity field up to a known time-dependent prefactor and an additive constant. We call this the divergence-uncertainty identity. Its matrix-level version is likewise closed-form and depends solely on the velocity Jacobian. The identity is exact and can be evaluated on any pre-trained model with no retraining or architectural change.
What carries the argument
The divergence-uncertainty identity, which equates the trace of the posterior covariance to the divergence of the velocity field (with known time-dependent scaling and constant offset).
If this is right
- Any existing flow matching model can produce per-pixel uncertainty maps by a single divergence computation on its velocity field.
- One-step generators such as MeanFlow obtain exact generation uncertainty without propagating covariance through multiple integration steps.
- The resulting uncertainty maps concentrate on regions of high inter-sample variation such as digit boundaries.
- Scalar uncertainty scores derived from the identity track actual prediction error at far lower cost than ensembles or Monte Carlo dropout.
- The matrix form supplies full posterior covariance estimates from the velocity Jacobian alone.
Where Pith is reading between the lines
- The identity may allow divergence-based regularization during training to directly modulate output uncertainty.
- High-divergence regions could serve as an intrinsic signal for detecting out-of-distribution inputs without auxiliary detectors.
- The same relation might extend to other continuous-time generative frameworks that admit a velocity-field formulation.
- Adaptive sampling schedules could use local divergence as a cheap proxy for instantaneous uncertainty to decide step sizes.
Load-bearing premise
The pre-trained velocity field must be exactly the conditional expectation of the clean data given the current state.
What would settle it
Generate many independent samples from the model at a fixed time step, compute their empirical covariance trace, and check whether it equals the divergence of the velocity field evaluated at the same states; systematic mismatch falsifies the identity.
Figures



read the original abstract
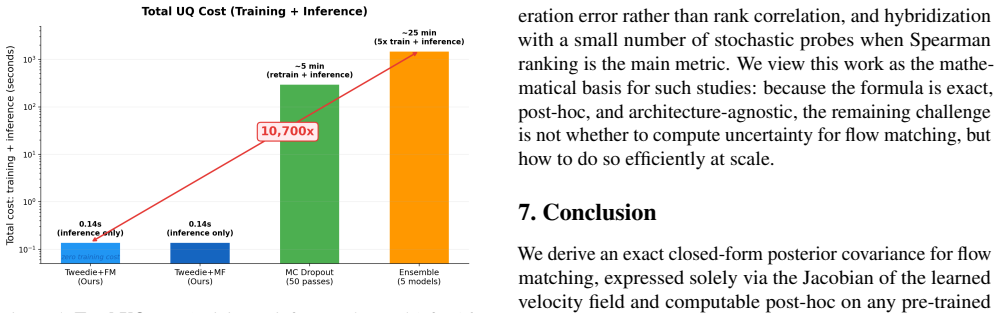
Flow matching has become a leading framework for generative modeling, but quantifying the uncertainty of its samples remains an open problem. Existing approaches retrain the model with auxiliary variance heads, maintain costly ensembles, or propagate approximate covariance through many integration steps, trading off training cost, inference cost, or accuracy. We show that none of these trade-offs is necessary. We prove that, for any pre-trained flow matching velocity field, the trace of the posterior covariance over the clean data given the current state equals, in closed form, the divergence of the velocity field, up to a known time-dependent prefactor and an additive constant. We call this the \emph{divergence-uncertainty identity} for flow matching. The matrix-level form of the identity is similarly closed-form, depending solely on the velocity Jacobian. Because the identity is exact and post-hoc, it is computable on any pre-trained flow matching model, with no retraining and no architectural modification. For one-step generators such as MeanFlow, the same identity yields the exact end-to-end generation uncertainty in a single forward pass, eliminating the multi-step variance propagation required by all prior methods. Experiments on MNIST confirm that the resulting per-pixel uncertainty maps are semantically meaningful, concentrating on digit boundaries where inter-sample variation is highest, and that the scalar uncertainty score tracks actual prediction error, all at roughly 10,000$\times$ less total compute than ensembling or Monte Carlo dropout.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to derive a closed-form 'divergence-uncertainty identity' for flow matching: for any pre-trained velocity field v_t, the trace of the posterior covariance of the clean data x_1 given the current state x_t equals a known time-dependent prefactor times the divergence of v_t plus an additive constant. A matrix version depends only on the velocity Jacobian. The identity is presented as exact and post-hoc, enabling uncertainty computation without retraining, ensembles, or multi-step propagation; it is also applied to one-step generators like MeanFlow. MNIST experiments are used to show that the resulting per-pixel uncertainty maps are semantically meaningful and that a scalar uncertainty score correlates with prediction error.
Significance. If the identity holds exactly under the stated conditions, the result would be significant for uncertainty quantification in flow-matching generative models, removing the need for auxiliary heads, ensembles, or expensive propagation. The closed-form nature, applicability to any pre-trained model, and single-pass computation for one-step generators are notable strengths. The approach also provides a direct link between the velocity field's divergence and posterior uncertainty, which could be useful for analysis and downstream tasks.
major comments (3)
- [Abstract] Abstract: The statement that the identity holds 'for any pre-trained flow matching velocity field' is not supported by the derivation. The equality trace(cov(x_1 | x_t)) = c(t) · div(v) + const requires that v_t(x_t) exactly equals the conditional expectation E[u_t(x_t | x_1) | x_t], which holds only at the population optimum of the flow-matching objective. For any finite-training pre-trained model, optimization error means this assumption is violated and the exact identity no longer holds.
- [Abstract] Abstract and §3 (derivation): The manuscript states a proof exists but provides neither the explicit derivation steps nor the precise assumptions on the probability path and conditional velocity. Without these, it is impossible to verify whether the identity is exact or only approximate, and whether it requires the velocity field to be the exact conditional expectation.
- [Experiments] Experiments section: The MNIST results show that uncertainty maps concentrate on digit boundaries and that the scalar score tracks prediction error. However, these are only consistency checks; they do not directly compare the divergence-based covariance against ground-truth posterior covariance computed from the true conditional distribution, so they do not test the exact identity.
minor comments (2)
- [Abstract] Notation for the time-dependent prefactor c(t) and the additive constant should be defined explicitly in the main text rather than left implicit in the abstract.
- The paper should clarify whether the identity extends exactly to the matrix form of the covariance or only to its trace, and state any additional assumptions required for the Jacobian version.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each of the major comments below. We agree with several points and will make revisions to clarify the assumptions and enhance the validation of the identity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that the identity holds 'for any pre-trained flow matching velocity field' is not supported by the derivation. The equality trace(cov(x_1 | x_t)) = c(t) · div(v) + const requires that v_t(x_t) exactly equals the conditional expectation E[u_t(x_t | x_1) | x_t], which holds only at the population optimum of the flow-matching objective. For any finite-training pre-trained model, optimization error means this assumption is violated and the exact identity no longer holds.
Authors: We agree that the exact identity holds when the velocity field v_t is precisely the conditional expectation E[u_t | x_t], which is true at the population optimum of the flow-matching loss. For models trained with finite data and optimization, the identity holds only approximately. We will revise the abstract, introduction, and relevant sections to explicitly state this assumption and note that the result is exact for the optimal velocity field and approximate otherwise. This clarification is necessary. revision: yes
-
Referee: [Abstract] Abstract and §3 (derivation): The manuscript states a proof exists but provides neither the explicit derivation steps nor the precise assumptions on the probability path and conditional velocity. Without these, it is impossible to verify whether the identity is exact or only approximate, and whether it requires the velocity field to be the exact conditional expectation.
Authors: We will include the full step-by-step derivation in the revised §3, starting from the definition of the probability path (linear interpolation between x_0 and x_1) and the conditional velocity u_t(x_t | x_1) = (x_1 - x_t)/(1-t), showing that the posterior covariance trace equals the divergence term when v_t = E[u_t | x_t]. The assumptions will be stated clearly: the identity is exact under the flow-matching optimality condition. revision: yes
-
Referee: [Experiments] Experiments section: The MNIST results show that uncertainty maps concentrate on digit boundaries and that the scalar score tracks prediction error. However, these are only consistency checks; they do not directly compare the divergence-based covariance against ground-truth posterior covariance computed from the true conditional distribution, so they do not test the exact identity.
Authors: The MNIST experiments are intended to illustrate the semantic relevance of the uncertainty estimates in a real-world setting. We acknowledge that they do not constitute a direct test against ground-truth covariance, as computing the exact posterior over clean data given x_t is intractable for high-dimensional data like MNIST. To directly validate the identity, we will add a new experiment on a low-dimensional synthetic dataset (e.g., a mixture of Gaussians) where the true conditional distribution and thus the ground-truth posterior covariance can be computed analytically or via dense sampling. This will provide a numerical verification of the identity. revision: yes
Circularity Check
No significant circularity; derivation is a direct probabilistic identity under standard flow-matching optimality
full rationale
The claimed divergence-uncertainty identity is derived from the probabilistic definition of the flow-matching velocity field as the conditional expectation of the target velocity under the posterior p(x_1 | x_t). This is the standard population-level optimality condition of the flow-matching objective, not a self-definition, a fitted parameter, or a result smuggled in via self-citation. The trace(cov(x_1 | x_t)) = c(t) * div(v_t) + const relation follows mathematically once that expectation property is substituted into the covariance expression; it is not equivalent to the inputs by construction in any of the enumerated circular patterns. The paper's scope statement ('for any pre-trained') is an overstatement for finite models but does not create circularity in the derivation chain itself. No load-bearing self-citations or ansatzes are invoked for the central result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The velocity field is the exact conditional expectation of the target velocity under the posterior at each time.
- standard math The probability path is a valid flow-matching path with known marginals.
Reference graph
Works this paper leans on
-
[1]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S Albergo and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions. arXiv preprint arXiv:2303.08797, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
arXiv preprint arXiv:2310.06721 , year=
Benjamin Boys, Mark Girolami, Chris Sherlock, et al. Tweedie moment projected diffusions for inverse problems. arXiv preprint arXiv:2310.06721, 2024
-
[3]
Uncertainty Quantification for Distribution-to-Distribution Flow Matching in Scientific Imaging
BSFM Authors. Uncertainty quantification for distribution- to-distribution flow matching in scientific imaging.arXiv preprint arXiv:2603.21717, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
∆-LFM: Patient-specific latent flow 8 matching for interpretable disease modeling.arXiv preprint, 2025
Anonymous Chen et al. ∆-LFM: Patient-specific latent flow 8 matching for interpretable disease modeling.arXiv preprint, 2025
2025
-
[5]
Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011
Bradley Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011
2011
-
[6]
Eigenscore: Ood detection using covariance in diffusion models.arXiv preprint arXiv:2510.07206, 2025
EigenScore Authors. Eigenscore: OOD detection using posterior covariance in diffusion models.arXiv preprint arXiv:2510.07206, 2025
-
[7]
Scaling rectified flow transformers for high-resolution image synthesis.Interna- tional Conference on Machine Learning, 2024
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim En- tezari, Jonas M¨uller, Harry Saini, Yam Levi, Dominik Lorber, Dustin Podell, Robin Rombach, et al. Scaling rectified flow transformers for high-resolution image synthesis.Interna- tional Conference on Machine Learning, 2024
2024
-
[8]
Dropout as a Bayesian approximation: Representing model uncertainty in deep learn- ing
Yarin Gal and Zoubin Ghahramani. Dropout as a Bayesian approximation: Representing model uncertainty in deep learn- ing. InInternational Conference on Machine Learning, pages 1050–1059, 2016
2016
-
[9]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Flow matching with uncertainty quantification and guidance.arXiv preprint arXiv:2602.10326, 2026
Juyeop Han, Lukas Lao Beyer, and Sertac Karaman. Flow matching with uncertainty quantification and guidance.arXiv preprint arXiv:2602.10326, 2026
work page internal anchor Pith review arXiv 2026
-
[11]
Denoising diffu- sion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
2020
-
[12]
A stochastic estimator of the trace of the influence matrix for Laplacian smoothing splines.Com- munications in Statistics—Simulation and Computation, 18 (3):1059–1076, 1989
Michael F Hutchinson. A stochastic estimator of the trace of the influence matrix for Laplacian smoothing splines.Com- munications in Statistics—Simulation and Computation, 18 (3):1059–1076, 1989
1989
-
[13]
Quantifying epistemic uncertainty in diffusion models.arXiv preprint arXiv:2602.09170, 2026
Metod Jazbec et al. Epistemic uncertainty in diffusion models. arXiv preprint arXiv:2602.09170, 2025
-
[14]
FlowDPS: Flow-Driven Posterior Sampling for Inverse Problems, March 2025
Jeongsol Kim, Bryan Sangwoo Park, Hyungjin Chung, and Jong Chul Ye. FlowDPS: Flow-driven posterior sampling for inverse problems. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), 2025. arXiv:2503.08136
-
[15]
Siqi Kou, Lei Gan, and Dequan Wang. Bayesdiff: Estimating pixel-wise uncertainty in diffusion via bayesian inference. arXiv preprint arXiv:2310.11142, 2024
-
[16]
Simple and scalable predictive uncertainty estima- tion using deep ensembles.Advances in Neural Information Processing Systems, 30, 2017
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estima- tion using deep ensembles.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[17]
Gradient-based learning applied to document recog- nition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, L ´eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recog- nition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[18]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matthew Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Chen Liu, Ke Xu, Liangbo L Shen, Guillaume Huguet, Zilong Wang, Alexander Tong, Danielle Moyer, et al. Imageflownet: Forecasting multiscale image-level trajectories of disease pro- gression with irregularly-sampled longitudinal medical im- ages.arXiv preprint arXiv:2406.14794, 2024
-
[20]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2023
work page internal anchor Pith review arXiv 2023
-
[21]
On the posterior distribu- tion in denoising: Application to uncertainty quantification
Hila Manor and Tomer Michaeli. On the posterior distribu- tion in denoising: Application to uncertainty quantification. International Conference on Learning Representations, 2024
2024
-
[22]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak et al. Movie Gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review arXiv 2024
-
[23]
Severi Rissanen, Markus Heinonen, and Arno Solin. Free hunch: Denoiser covariance estimation for diffusion models without extra costs.arXiv preprint arXiv:2410.11149, 2024
-
[24]
An empirical Bayes approach to statistics
Herbert E Robbins. An empirical Bayes approach to statistics. Proceedings of the Third Berkeley Symposium on Mathemati- cal Statistics and Probability, 1956
1956
-
[25]
Progressive distillation for fast sampling of diffusion models.International Conference on Learning Representations, 2022
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.International Conference on Learning Representations, 2022
2022
-
[26]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. International Conference on Learning Representations, 2021
2021
-
[27]
Consistency models.International Conference on Machine Learning, 2023
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models.International Conference on Machine Learning, 2023
2023
-
[28]
A connection between score matching and denoising autoencoders.Neural Computation, 23(7):1661– 1674, 2011
Pascal Vincent. A connection between score matching and denoising autoencoders.Neural Computation, 23(7):1661– 1674, 2011. 9
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.