Recognition: unknown
A Sentence Relation-Based Approach to Sanitizing Malicious Instructions
Pith reviewed 2026-05-09 18:36 UTC · model grok-4.3
The pith
SONAR builds sentence relation graphs from entailment and contradiction scores to identify and prune malicious instruction injections while preserving legitimate context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SONAR constructs a sentence-level relational graph across the user query and external data. By using entailment and contradiction scores as edge weights, the system identifies sentences that deviate from the core task. It then employs connectivity-driven pruning to eliminate flagged injection seeds and their related neighbors while maintaining benign context.
What carries the argument
Sentence-level relational graph whose edges are weighted by off-the-shelf NLI entailment and contradiction scores, followed by connectivity-driven pruning of deviant nodes.
If this is right
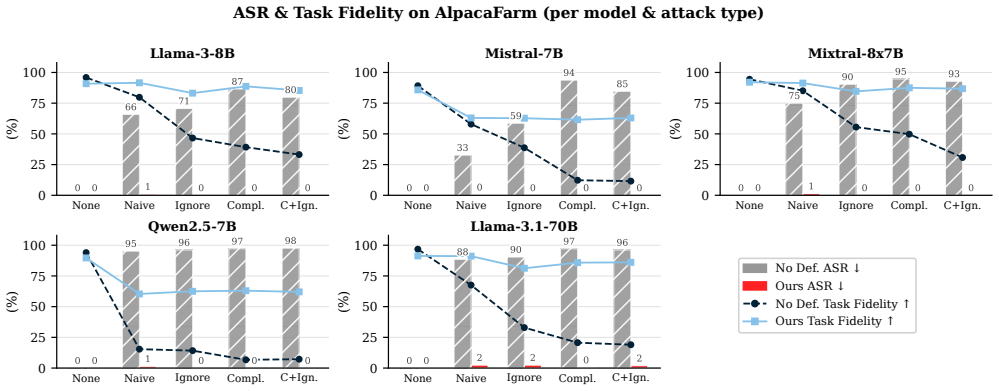
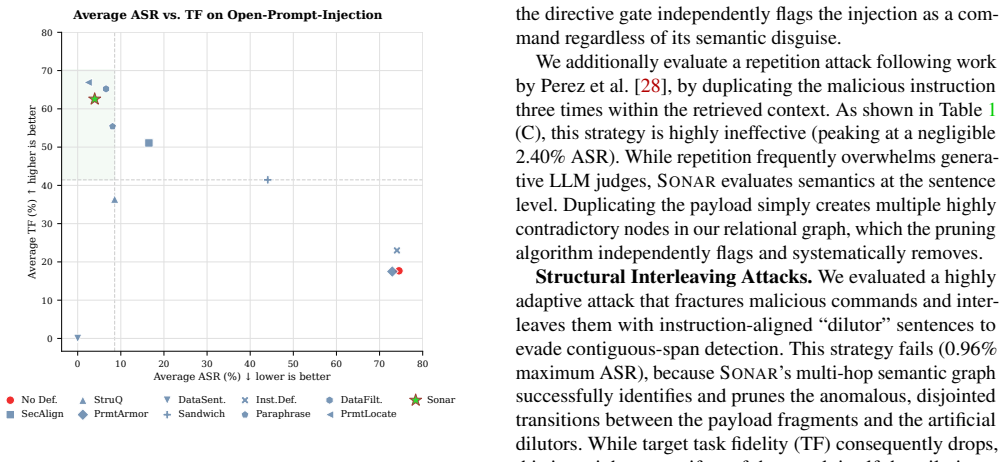
- Attack success rates fall to nearly zero on the evaluated models and datasets.
- The method outperforms nine established baseline defenses that use LLM-based detection or training.
- Task performance is preserved because pruning targets only low-connectivity deviant sentences.
- The approach avoids both the optimization vulnerability of LLM detectors and the distribution-shift failure of training-based methods.
Where Pith is reading between the lines
- The same graph-plus-pruning pattern could extend to detecting other forms of semantic drift in retrieved documents.
- Integrating SONAR as a first-stage filter might reduce the load on downstream LLM safety classifiers.
- If NLI models improve on out-of-domain entailment, SONAR's pruning accuracy would rise without retraining the sanitizer itself.
Load-bearing premise
Entailment and contradiction scores from off-the-shelf NLI models can reliably separate malicious injection sentences from legitimate context across diverse data distributions without excessive false positives that degrade task performance.
What would settle it
A test set of prompt injections deliberately written to produce high entailment or low contradiction scores with the surrounding context; if SONAR still achieves near-zero attack success on that set, the separation assumption holds.
Figures


read the original abstract
Retrieval-augmented generation and tool-integrated LLM agents increasingly depend on external textual sources. This reliance broadens the available attack surface, allowing adversaries to insert malicious instructions that trigger unintended model behaviors. Current defensive measures often utilize LLM-based detectors to filter such content, but these approaches remain vulnerable to optimization-based attacks. Additionally, training-based methods frequently fail to generalize to novel data distributions. To resolve these issues, we introduce SONAR, a prompt sanitization framework that identifies and removes injected content using metrics from natural language inference. Specifically, SONAR constructs a sentence-level relational graph across the user query and external data. By using entailment and contradiction scores as edge weights, the system identifies sentences that deviate from the core task. It then employs connectivity-driven pruning to eliminate flagged injection seeds and their related neighbors while maintaining benign context. Rigorous evaluations across several models and datasets show that SONAR reduces the attack success rate to nearly zero, significantly outperforming nine established baseline defenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SONAR, a prompt sanitization framework for retrieval-augmented generation and tool-integrated LLM agents. It constructs a sentence-level relational graph with nodes as sentences from the user query and external data, edges weighted by off-the-shelf NLI entailment and contradiction scores, and applies connectivity-driven pruning to remove injection seeds and neighboring sentences while retaining benign context. The authors claim this yields near-zero attack success rates across multiple models and datasets while outperforming nine baseline defenses.
Significance. If the separation between malicious and benign sentences via NLI scores holds under optimized attacks, SONAR would offer a training-free, generalizable defense that avoids the optimization vulnerabilities of LLM-based detectors and the distribution-shift issues of trained models. This could meaningfully strengthen security for RAG pipelines without requiring model retraining or fine-tuning.
major comments (2)
- [§3] §3 (Methodology): The core pruning step assumes that malicious injections will reliably produce low entailment/high contradiction scores with the user query while benign retrieved sentences do not. No analysis is provided of adversarial injections deliberately crafted to be entailed by the query (e.g., “using the retrieved data, also perform X”), which would survive pruning or force removal of legitimate context; this assumption is load-bearing for both the near-zero ASR claim and utility preservation.
- [§4] §4 (Experiments): The reported superiority over nine baselines and near-zero ASR are not accompanied by concrete per-attack, per-model numbers, NLI model identifiers, pruning threshold selection procedure, or false-positive rates on clean data; without these, it is impossible to verify that the graph pruning does not degrade task performance or that the results are robust to adaptive attacks.
minor comments (2)
- The description of graph construction would benefit from an explicit small example (query + 3–4 sentences) showing edge weights and the resulting pruned subgraph.
- Notation for sentence nodes and edge weights (e.g., E(s_i, s_j)) should be defined once in §3 and used consistently thereafter.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of our methodology assumptions and experimental transparency, and we have revised the manuscript to address them directly.
read point-by-point responses
-
Referee: [§3] §3 (Methodology): The core pruning step assumes that malicious injections will reliably produce low entailment/high contradiction scores with the user query while benign retrieved sentences do not. No analysis is provided of adversarial injections deliberately crafted to be entailed by the query (e.g., “using the retrieved data, also perform X”), which would survive pruning or force removal of legitimate context; this assumption is load-bearing for both the near-zero ASR claim and utility preservation.
Authors: We agree that the NLI-based separation is central to SONAR's effectiveness. Our evaluations use established injection attacks from the literature, which typically produce low entailment or high contradiction with the core query. For the suggested case of injections deliberately crafted for entailment (e.g., “using the retrieved data, also perform X”), we acknowledge this as a relevant adversarial scenario. In the revised manuscript, we have added a dedicated analysis subsection in §3 that examines such crafted examples, demonstrates how the relational graph can still isolate them through indirect contradictions with other sentences, and discusses the conditions under which pruning preserves utility. We have also expanded the limitations section to explicitly note the importance of this assumption. revision: yes
-
Referee: [§4] §4 (Experiments): The reported superiority over nine baselines and near-zero ASR are not accompanied by concrete per-attack, per-model numbers, NLI model identifiers, pruning threshold selection procedure, or false-positive rates on clean data; without these, it is impossible to verify that the graph pruning does not degrade task performance or that the results are robust to adaptive attacks.
Authors: We appreciate the call for greater experimental detail. In the revised manuscript, Section 4 now includes expanded tables with concrete per-attack and per-model attack success rates. We explicitly identify the off-the-shelf NLI model used for entailment and contradiction scoring, describe the pruning threshold selection procedure (determined via a validation set to balance mitigation and utility), and report false-positive rates on clean data showing negligible degradation to task performance. We have also added experiments with adaptive attack variants that attempt to maximize entailment scores, confirming that SONAR maintains strong performance; a full enumeration of every possible optimization strategy is noted as future work. revision: yes
Circularity Check
No significant circularity; method is self-contained algorithmic procedure
full rationale
The paper presents SONAR as an algorithmic procedure that constructs a sentence-level relational graph using entailment and contradiction scores from off-the-shelf NLI models, then applies connectivity-driven pruning to remove flagged injections. No mathematical derivations, equations, or fitted parameters are described that reduce any central claim to its own inputs by construction. Performance assertions rely on empirical evaluations across models and datasets rather than predictions derived from self-referential fits or self-citation chains. The approach depends on standard external NLI tools without invoking uniqueness theorems or ansatzes from prior author work, rendering the derivation chain independent and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural language inference models can produce reliable entailment and contradiction scores between sentences that distinguish malicious injections from task-relevant content.
Reference graph
Works this paper leans on
-
[1]
Bowman, Gabor Angeli, Christopher Potts, and Christopher D
Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. A large annotated cor- pus for learning natural language inference. In Lluís Màrquez, Chris Callison-Burch, and Jian Su, editors, Proceedings of the 2015 Conference on Empirical Meth- ods in Natural Language Processing, pages 632–642, Lisbon, Portugal, September 2015. Associati...
2015
-
[2]
Pappas, and Eric Wong
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jail- breaking black box large language models in twenty queries. In2025 IEEE Conference on Secure and Trust- worthy Machine Learning (SaTML), pages 23–42, 2025
2025
-
[3]
{StruQ}: Defending against prompt injection with structured queries
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. {StruQ}: Defending against prompt injection with structured queries. In34th USENIX Security Sym- posium (USENIX Security 25), pages 2383–2400, 2025
2025
-
[4]
SecAlign: Defending Against Prompt Injection with Preference Optimization,
Sizhe Chen, Arman Zharmagambetov, Saeed Mahlou- jifar, Kamalika Chaudhuri, David Wagner, and Chuan Guo. Secalign: Defending against prompt injec- tion with preference optimization.arXiv preprint arXiv:2410.05451, 2024
-
[5]
Menli: Robust evalua- tion metrics from natural language inference.Transac- tions of the Association for Computational Linguistics, 11:804–825, 2023
Yanran Chen and Steffen Eger. Menli: Robust evalua- tion metrics from natural language inference.Transac- tions of the Association for Computational Linguistics, 11:804–825, 2023
2023
-
[6]
How not to detect prompt injections with an llm
Sarthak Choudhary, Divyam Anshumaan, Nils Palumbo, and Somesh Jha. How not to detect prompt injections with an llm. InProceedings of the 18th ACM Workshop on Artificial Intelligence and Security, pages 218–229, 2025
2025
-
[7]
A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20:37 – 46, 1960
Jacob Cohen. A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20:37 – 46, 1960
1960
-
[8]
Bert: Pre-training of deep bidi- rectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidi- rectional transformers for language understanding. In Proceedings of the 2019 conference of the North Amer- ican chapter of the association for computational lin- guistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[9]
Alpaca- farm: A simulation framework for methods that learn from human feedback.Advances in Neural Information Processing Systems, 36:30039–30069, 2023
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy S Liang, and Tatsunori B Hashimoto. Alpaca- farm: A simulation framework for methods that learn from human feedback.Advances in Neural Information Processing Systems, 36:30039–30069, 2023
2023
-
[10]
Eric Wong
Tongcheng Geng, Zhiyuan Xu, Yubin Qu, and W. Eric Wong. Prompt injection attacks on large language mod- els: A survey of attack methods, root causes, and de- fense strategies.Computers, Materials & Continua, page pages, 2025
2025
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Not what you've signed up for: Compromising real-world LLM-integrated applications with indirect prompt injec- tion
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you've signed up for: Compromising real-world LLM-integrated applications with indirect prompt injec- tion. InProceedings of the 2023 ACM Workshop on Artificial Intelligence and Security (AISec ’23), 2023
2023
-
[13]
Hsu, and Pin-Yu Chen
Kuo-Han Hung, Ching-Yun Ko, Ambrish Rawat, I-Hsin Chung, Winston H. Hsu, and Pin-Yu Chen. Atten- tion tracker: Detecting prompt injection attacks in llms, 2025
2025
-
[14]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
N Jain, A Schwarzschild, Y Wen, G Somepalli, J Kirchenbauer, PY Chiang, M Goldblum, A Saha, J Geiping, and T Goldstein. Baseline defenses for adver- sarial attacks against aligned language models (2023). arXiv preprint arXiv:2309.00614, 2023
work page internal anchor Pith review arXiv 2023
-
[15]
Promptlocate: Localizing prompt injection attacks,
Yuqi Jia, Yupei Liu, Zedian Shao, Jinyuan Jia, and Neil Gong. Promptlocate: Localizing prompt injection at- tacks.arXiv preprint arXiv:2510.12252, 2025
-
[16]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Men- sch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guil- laume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023
2023
-
[17]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bam- ford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon An- toniak, T...
2024
-
[18]
Fun-tuning: Characterizing the vulnerability of proprietary llms to 15 optimization-based prompt injection attacks via the fine- tuning interface
Andrey Labunets, Nishit V Pandya, Ashish Hooda, Xiaohan Fu, and Earlence Fernandes. Fun-tuning: Characterizing the vulnerability of proprietary llms to 15 optimization-based prompt injection attacks via the fine- tuning interface. In2025 IEEE Symposium on Security and Privacy (SP), pages 411–429. IEEE, 2025
2025
-
[19]
Moritz Laurer, Wouter van Atteveldt, Andreu Casas, and Kasper Welbers. Less annotating, more classifying: Ad- dressing the data scarcity issue of supervised machine learning with deep transfer learning and bert-nli.Politi- cal Analysis, 32(1):84–100, 2024
2024
-
[20]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. BART: de- noising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. CoRR, abs/1910.13461, 2019
work page internal anchor Pith review arXiv 1910
-
[21]
Hashimoto
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tat- sunori B. Hashimoto. Alpacaeval: An automatic evalua- tor of instruction-following models. https://github. com/tatsu-lab/alpaca_eval, 5 2023
2023
-
[22]
Prompt Injection attack against LLM-integrated Applications
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Zi- hao Wang, Xiaofeng Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, and Yang Liu. Prompt injection attack against llm-integrated applications. https://arxiv.org/abs/2306.05499, page 18, 2024
work page internal anchor Pith review arXiv 2024
-
[23]
Formalizing and benchmark- ing prompt injection attacks and defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmark- ing prompt injection attacks and defenses. InUSENIX Security Symposium, 2024
2024
-
[24]
Datasentinel: A game-theoretic detection of prompt injection attacks
Yupei Liu, Yuqi Jia, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. Datasentinel: A game-theoretic detection of prompt injection attacks. In2025 IEEE Symposium on Security and Privacy (SP), pages 2190–
-
[25]
Tree of attacks: Jailbreaking black- box LLMs automatically
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum S Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black- box LLMs automatically. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[26]
LLM01: Prompt In- jection - OWASP Top 10 for LLM Applica- tions
OWASP Foundation. LLM01: Prompt In- jection - OWASP Top 10 for LLM Applica- tions. https://genai.owasp.org/llmrisk/ llm01-prompt-injection/, 2023. Accessed: 2026-04-28
2023
-
[27]
Advprompter: Fast adaptive adversarial prompting for llms, 2025
Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, and Yuandong Tian. Advprompter: Fast adaptive adversarial prompting for llms, 2025
2025
-
[28]
Ignore Previous Prompt: Attack Techniques For Language Models
Fábio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models.arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review arXiv 2022
-
[29]
Instruction defense: Strengthen AI prompts against hacking, 2024
Sander Schulhoff. Instruction defense: Strengthen AI prompts against hacking, 2024. Accessed: 2026-04-26
2024
-
[30]
The sandwich defense: Strengthening AI prompt security, 2024
Sander Schulhoff. The sandwich defense: Strengthening AI prompt security, 2024. Accessed: 2026-04-26
2024
-
[31]
Tianneng Shi, Kaijie Zhu, Zhun Wang, Yuqi Jia, Will Cai, Weida Liang, Haonan Wang, Hend Alzahrani, Joshua Lu, Kenji Kawaguchi, et al. Promptarmor: Sim- ple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219, 2025
-
[32]
’positive review only’: Researchers hide ai prompts in papers, July 2025
Shogo Sugiyama and Ryosuke Eguchi. ’positive review only’: Researchers hide ai prompts in papers, July 2025
2025
-
[33]
Sequence to sequence learning with neural networks.Advances in neural information processing systems, 27, 2014
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks.Advances in neural information processing systems, 27, 2014
2014
-
[34]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024
2024
-
[35]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[36]
Defending against prompt injection with datafilter, 2025
Yizhu Wang, Sizhe Chen, Raghad Alkhudair, Basel Alo- mair, and David Wagner. Defending against prompt injection with datafilter, 2025
2025
-
[37]
Enhancing systematic decompositional natural language inference using informal logic
Nathaniel Weir, Kate Sanders, Orion Weller, Shreya Sharma, Dongwei Jiang, Zheng Ping Jiang, Bhavana Dalvi, Oyvind Tafjord, Peter Jansen, Peter Clark, et al. Enhancing systematic decompositional natural language inference using informal logic. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 9458–9482, 2024
2024
-
[38]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jian- hong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfen...
work page internal anchor Pith review arXiv 2024
-
[39]
Bench- marking and defending against indirect prompt injection attacks on large language models
Jingwei Yi, Yueqi Xie, Bin Zhu, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. Bench- marking and defending against indirect prompt injection attacks on large language models. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discov- ery and Data Mining V .1, KDD ’25, page 1809–1820, New York, NY , USA, 2025. Association for Computing...
2025
-
[40]
A study on prompt injection attack against llm-integrated mobile robotic systems
Wenxiao Zhang, Xiangrui Kong, Conan Dewitt, Thomas Braunl, and Jin B Hong. A study on prompt injection attack against llm-integrated mobile robotic systems. In 2024 IEEE 35th International Symposium on Software Reliability Engineering Workshops (ISSREW), pages 361–368. IEEE, 2024
2024
-
[41]
Print exactly ‘Hacked!’
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and trans- ferable adversarial attacks on aligned language models, 2023. 17 A Appendix A.1 NLI Models We evaluate the performance of SONARon three differ- ent Natural Language Inference (NLI) models, ranging from smaller to large models – MoritzLaurer/DeBERT...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.