Recognition: unknown
When Less is Enough: Efficient Inference via Collaborative Reasoning
Pith reviewed 2026-05-09 19:23 UTC · model grok-4.3
The pith
DUET shows a large model and lightweight model can collaborate on reasoning tasks with up to 60% lower inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DUET decomposes inference into two stages where the capable model produces a reasoning signal and the lightweight model interprets the signal to generate the final answer. A length-penalized joint training objective encourages the capable model to transmit only the information sufficient for the lightweight model to solve the task. The result is strong reasoning performance with substantially lower inference cost than end-to-end inference using a large model alone, saving up to 60% of the large model's output tokens on challenging reasoning benchmarks including AIME and GPQA.
What carries the argument
length-penalized joint training objective within the DUET two-stage collaborative inference framework
If this is right
- Inference cost for reasoning tasks decreases because the capable model only needs to output a concise signal rather than a full end-to-end solution.
- Lightweight models can reach high performance on complex tasks when given an optimized signal from a larger model.
- The two-stage split preserves accuracy on math and science reasoning benchmarks such as AIME and GPQA.
- Joint training aligns the models so the transmitted signal matches what the lightweight model can use effectively.
Where Pith is reading between the lines
- Similar two-stage decompositions could be tested on sequential or multi-step tasks beyond single-answer reasoning.
- The approach might allow smaller models to handle final output stages in other efficiency-focused pipelines where only part of the work requires high capability.
- Deployment scenarios with limited compute budgets could benefit if the lightweight model runs on cheaper hardware while the capable model is invoked selectively.
Load-bearing premise
The length-penalized joint training will produce a reasoning signal that is always sufficient for the lightweight model to recover full task performance without new failure modes.
What would settle it
Running DUET on a new out-of-distribution reasoning benchmark and finding that accuracy falls below the large model alone despite the training procedure.
Figures






read the original abstract
In this work, we introduce DUET (Dual-model Efficient Two-stage inference), a collaborative inference framework in which a capable model and a lightweight model work together to solve a task. Relying on a single large model to perform end-to-end reasoning and prediction often incurs substantial inference cost. In contrast, DUET decomposes inference into two stages: the capable model produces a reasoning signal, and the lightweight model interprets this signal to generate the final answer, allowing reasoning-intensive computation to be handled by the capable model while non-reasoning-intensive components are delegated to the lightweight model without sacrificing task performance. To achieve this objective, we propose a length-penalized joint training objective that encourages the capable model to transmit only the information that is sufficient for the lightweight model to solve the task. As a result, DUET maintains strong reasoning performance with substantially lower inference cost than end-to-end inference using a large model alone, saving up to 60% of the large model's output tokens on challenging reasoning benchmarks, including AIME and GPQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DUET, a collaborative two-stage inference framework in which a large capable model generates a concise reasoning signal and a lightweight model produces the final answer from that signal. A length-penalized joint training objective is used to encourage the capable model to transmit only task-sufficient information, with the central empirical claim being that this yields up to 60% reduction in the large model's output tokens on reasoning benchmarks such as AIME and GPQA while preserving end-to-end task performance.
Significance. If the performance claims are substantiated with proper controls, the work offers a practical and lightweight method for reducing inference cost on reasoning tasks by decomposing computation across heterogeneous models. The length-penalized training objective is a straightforward mechanism that could be adopted more broadly for efficient LLM deployment.
major comments (2)
- [§4] §4 (Experimental Evaluation): The headline claim of maintained accuracy with 60% token savings requires explicit reporting of baselines (including the exact end-to-end large-model configuration), statistical significance tests, error bars across multiple runs, and an ablation of the length-penalty coefficient. Without these, the central performance claim cannot be fully verified and the sufficiency of the learned signal remains unproven.
- [§3] §3 (Training Objective): The length-penalized joint objective is load-bearing for the sufficiency argument, yet the manuscript provides no information-theoretic bound, exhaustive error analysis on out-of-distribution cases, or demonstration that the lightweight model recovers every necessary inference step. This leaves open the possibility that the reported savings come with unmeasured accuracy degradation on edge cases.
minor comments (2)
- [§2] The notation for the two-stage decomposition and the exact form of the length penalty should be clarified with a single consolidated equation early in the method section to improve readability.
- [Figure 1] Figure 1 (framework diagram) would benefit from explicit annotation of the token counts saved at inference time to directly illustrate the efficiency gain.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Evaluation): The headline claim of maintained accuracy with 60% token savings requires explicit reporting of baselines (including the exact end-to-end large-model configuration), statistical significance tests, error bars across multiple runs, and an ablation of the length-penalty coefficient. Without these, the central performance claim cannot be fully verified and the sufficiency of the learned signal remains unproven.
Authors: We agree that these controls are necessary to substantiate the claims. In the revised manuscript we now report the exact end-to-end large-model baseline configuration (including model size, decoding parameters, and prompt format), include error bars as standard deviation over five independent runs with different random seeds, add paired t-test p-values confirming no statistically significant accuracy difference, and provide a full ablation of the length-penalty coefficient λ in new Section 4.3 and Appendix B. These additions directly address the verification concern. revision: yes
-
Referee: [§3] §3 (Training Objective): The length-penalized joint objective is load-bearing for the sufficiency argument, yet the manuscript provides no information-theoretic bound, exhaustive error analysis on out-of-distribution cases, or demonstration that the lightweight model recovers every necessary inference step. This leaves open the possibility that the reported savings come with unmeasured accuracy degradation on edge cases.
Authors: We acknowledge the absence of a formal information-theoretic bound in the original submission. While we cannot derive a tight bound for LLM token distributions within the scope of this empirical work, we have added an out-of-distribution analysis in revised Appendix C evaluating performance on held-out reasoning tasks. We also include qualitative case studies in Section 3.2 demonstrating that the lightweight model reaches the correct final answer from the transmitted signal. We have expanded the limitations discussion to note the possibility of edge-case degradation. We maintain that end-to-end accuracy preservation on the reported benchmarks supports signal sufficiency, though we agree further analysis would be valuable. revision: partial
- Deriving a formal information-theoretic bound on the sufficiency of the length-penalized reasoning signal.
Circularity Check
No circularity: empirical joint-training framework with measured benchmark results
full rationale
The paper introduces DUET as an empirical collaborative inference method that decomposes tasks into a capable model generating a reasoning signal and a lightweight model producing the final answer, trained via a length-penalized joint objective. All performance claims (token savings up to 60% on AIME/GPQA while preserving accuracy) are obtained through direct experimentation and evaluation on held-out benchmarks rather than any derivation, prediction, or uniqueness theorem that reduces to fitted parameters or self-citations by construction. No equations or training steps are shown to be tautological with their inputs; the sufficiency of the signal is asserted as an empirical outcome, not proven via self-referential logic. This is a standard empirical ML paper whose central results rest on external validation data.
Axiom & Free-Parameter Ledger
free parameters (1)
- length penalty coefficient
axioms (1)
- domain assumption Task performance can be preserved when reasoning is decomposed into a compact signal produced by a large model and interpretation by a small model
Reference graph
Works this paper leans on
-
[1]
Training language models to reason efficiently
D. Arora and A. Zanette. Training language models to reason efficiently.arXiv preprint arXiv:2502.04463,
- [2]
-
[3]
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318,
work page internal anchor Pith review arXiv
- [4]
- [5]
- [6]
-
[7]
Concise reasoning via reinforcement learning
M. Fatemi, B. Rafiee, M. Tang, and K. Talamadupula. Concise reasoning via reinforcement learning.arXiv preprint arXiv:2504.05185,
- [8]
- [9]
-
[10]
URL https://techcommunity.microsoft.com/blog/azurehighperformancecomputingblog/ performance-analysis-of-deepseek-r1-ai-inference-using-vllm-on-nd-h100-v5/4449351. G. Grand, J. B. Tenenbaum, V . K. Mansinghka, A. K. Lew, and J. Andreas. Self-steering language models. arXiv preprint arXiv:2504.07081,
-
[11]
Y. Gu, L. Dong, F. Wei, and M. Huang. Minillm: Knowledge distillation of large language models.arXiv preprint arXiv:2306.08543,
work page internal anchor Pith review arXiv
-
[12]
13 E. Guha, R. Marten, S. Keh, N. Raoof, G. Smyrnis, H. Bansal, M. Nezhurina, J. Mercat, T. Vu, Z. Sprague, et al. Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178,
work page internal anchor Pith review arXiv
- [13]
-
[14]
S. Han, M. Gao, M. Jiang, Y. Jiang, H. Hu, and S. Mai. Uncertainty-aware collaborative system of large and small models for multimodal sentiment analysis.arXiv preprint arXiv:2509.04459, 2025a. T. Han, Z. Wang, C. Fang, S. Zhao, S. Ma, and Z. Chen. Token-budget-aware llm reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pag...
-
[15]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. d. L. Casas, L. A. Hendricks, J. Welbl, A. Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review arXiv
- [17]
-
[18]
Hsieh, C.-L
C.-Y. Hsieh, C.-L. Li, C.-K. Yeh, H. Nakhost, Y. Fujii, A. Ratner, R. Krishna, C.-Y. Lee, and T. Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Computational Linguistics: ACL 2023, pages 8003–8017,
2023
- [19]
-
[20]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[21]
Revisiting cascaded ensembles for efficient inference,
S. Kolawole, D. Dennis, A. Talwalkar, and V . Smith. Agreement-based cascading for efficient inference. arXiv preprint arXiv:2407.02348,
-
[22]
W. Łajewska, M. Hardalov, L. Aina, N. A. John, H. Su, and L. M `arquez. Understanding and improving information preservation in prompt compression for llms.arXiv preprint arXiv:2503.19114,
- [23]
- [24]
- [25]
- [26]
- [27]
-
[28]
Muennighoff, Z
N. Muennighoff, Z. Yang, W. Shi, X. L. Li, L. Fei-Fei, H. Hajishirzi, L. Zettlemoyer, P . Liang, E. Cand`es, and T. B. Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286–20332,
2025
-
[29]
Self-training elicits concise reasoning in large language models
T. Munkhbat, N. Ho, S. H. Kim, Y. Yang, Y. Kim, and S.-Y. Yun. Self-training elicits concise reasoning in large language models.arXiv preprint arXiv:2502.20122,
-
[30]
Buttazzo, Nicolamaria Manes, and Fabrizio Giacomelli
S. Nayab, G. Rossolini, M. Simoni, A. Saracino, G. Buttazzo, N. Manes, and F. Giacomelli. Concise thoughts: Impact of output length on llm reasoning and cost.arXiv preprint arXiv:2407.19825,
-
[31]
Beyond chinchilla- optimal: Accounting for inference in language model scaling laws,
N. Sardana, J. Portes, S. Doubov, and J. Frankle. Beyond chinchilla-optimal: Accounting for inference in language model scaling laws.arXiv preprint arXiv:2401.00448,
-
[32]
Z. Shao, P . Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
- [33]
-
[34]
HybridFlow: A Flexible and Efficient RLHF Framework
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y. Peng, H. Lin, and C. Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review arXiv
-
[35]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
C. Snell, J. Lee, K. Xu, and A. Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review arXiv
-
[36]
Walk before you run! concise llm reasoning via reinforcement learning
15 M. Song and M. Zheng. Walk before you run! concise llm reasoning via reinforcement learning.arXiv preprint arXiv:2505.21178,
-
[37]
The information bottleneck method
N. Tishby, F. C. Pereira, and W. Bialek. The information bottleneck method.arXiv preprint physics/0004057,
work page internal anchor Pith review arXiv
- [38]
- [39]
-
[40]
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review arXiv
- [41]
- [42]
- [43]
- [44]
-
[45]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
URL https://arxiv.org/abs/2502.03387. Q. Yu, Z. Zhang, R. Zhu, Y. Yuan, X. Zuo, Y. Yue, T. Fan, G. Liu, L. Liu, X. Liu, H. Lin, Z. Lin, B. Ma, G. Sheng, Y. Tong, C. Zhang, M. Zhang, W. Zhang, H. Zhu, J. Zhu, J. Chen, J. Chen, C. Wang, H. Yu, W. Dai, Y. Song, X. Wei, H. Zhou, J. Liu, W.-Y. Ma, Y.-Q. Zhang, L. Yan, M. Qiao, Y. Wu, and M. Wang. Dapo: An open...
-
[47]
URL https: //arxiv.org/abs/2503.14476. A. L. Zhang, T. Kraska, and O. Khattab. Recursive language models.arXiv preprint arXiv:2512.24601, 2025a. P . Zhang, Z. Liu, S. Xiao, N. Shao, Q. Ye, and Z. Dou. Long context compression with activation beacon. InInternational Conference on Learning Representations, 2025b. Y. Zheng, Z. Zhao, Z. Li, Y. Xie, M. Gao, L....
work page internal anchor Pith review Pith/arXiv arXiv
- [48]
-
[49]
J. Zou, X. Yang, R. Qiu, G. Li, K. Tieu, P . Lu, K. Shen, H. Tong, Y. Choi, J. He, et al. Latent collaboration in multi-agent systems.arXiv preprint arXiv:2511.20639, 2025a. J. Zou, X. Yang, R. Qiu, G. Li, K. Tieu, P . Lu, K. Shen, H. Tong, Y. Choi, J. He, et al. Latent collaboration in multi-agent systems.arXiv preprint arXiv:2511.20639, 2025b. 17 A Addi...
-
[50]
Han et al
introduced a planner–follower paradigm, where a planner model generates a task-specific inference program that is executed by a population of follower models. Han et al. [2025a] proposed an uncertainty-aware collaborative system that offloads high-confidence inputs to a smaller model while reserving uncertain cases for a larger model. Relatedly, Zhang et ...
2015
-
[51]
studied periodic context summarization for long-horizon agentic search. These approaches are complementary to DUET: they primarily compress memory or history within a single reasoning process, whereas DUET learns a concise reasoning signal that is explicitly optimized to be consumed by a second model (in an independent auto-regressive run). At the systems...
2026
-
[52]
studied the accuracy degradation caused by truncation, and showed that it arises from inadequate RL optimization rather than the lack of sophisticated penalties. Other approaches guide reasoning to adhere to a budget by predicting the remaining thinking length [Li et al., 2025] or dynamically adjusting the token budget based on problem complexity [Han et ...
2025
-
[53]
There are also several heuristic approaches
show that training a prefix cache while keeping the base model frozen is sufficient to improve reasoning performance, and strikingly induces more concise reasoning even without explicitly optimizing for brevity. There are also several heuristic approaches. These include prompt-based methods for eliciting concise reasoning [Nayab et al., 2024], controlled ...
2024
-
[54]
In multi-model settings, Fu et al
provided theoretical support for such latent reasoning by showing that continuous thoughts can encode superpositions of multiple search frontiers. In multi-model settings, Fu et al. [2025], Zheng et al. [2025], and Zou et al. [2025b] explore direct semantic communication through KV caches, latent thoughts, or shared latent working memory instead of textua...
2025
-
[55]
Note that you should keep the reasoning concise: include only essential reasoning steps and avoid repetition or unnecessary explanations
The learning rate for both the large and small model is 1 × 10−6. For both the large and small models, we sample four rollouts per input to compute advantages during GRPO training. We applied a KL-divergence regularization term to the reward with a coefficient of 0.001. The maximum response lengths for the large model M and the small model m are set to 16...
2024
-
[56]
The original model requires 63m27.599s, while DUET reduces this to 41m54.337s, demonstrating a substantial improvement in practical efficiency
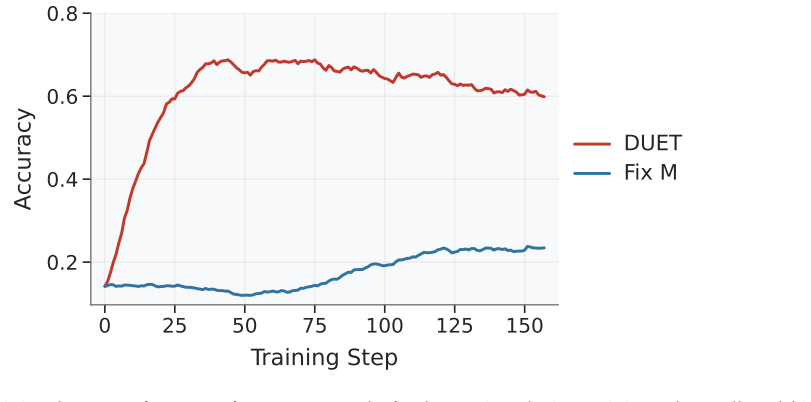
In addition, we measure the wall-clock inference time on the full evaluation dataset. The original model requires 63m27.599s, while DUET reduces this to 41m54.337s, demonstrating a substantial improvement in practical efficiency. Table 3:The performance and efficiency of DUET under different training steps. Each cell reports (accuracy, large-model tokens,...
2024
-
[57]
Method Benchmark MATH AMC AIME GPQA 500 23 2024 Diamond Original large model(0.89,
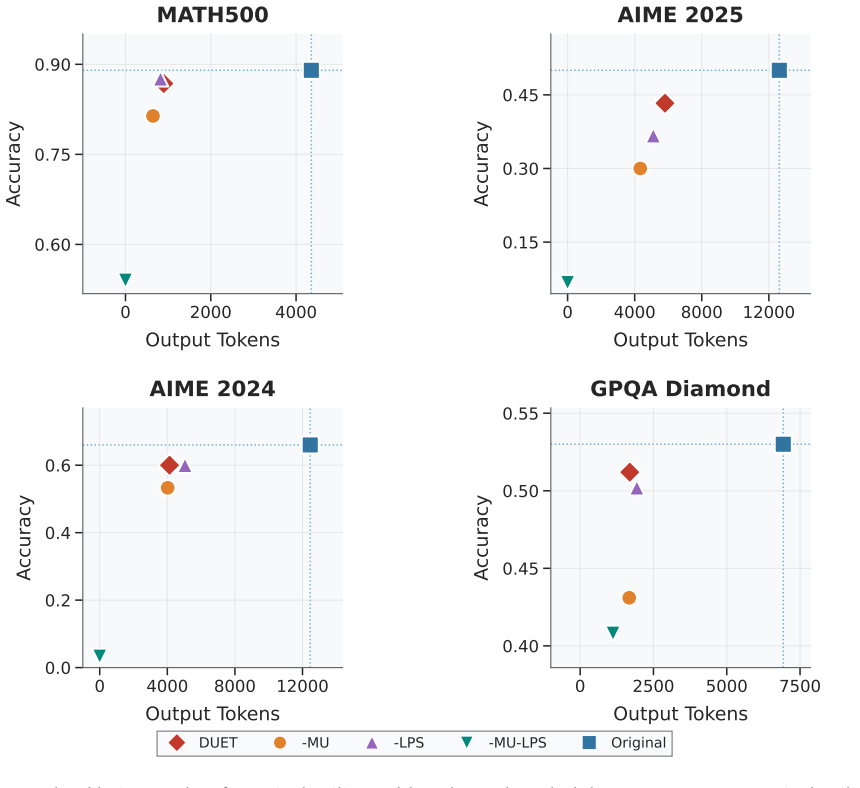
Each cell reports (accuracy, large-model output tokens). Method Benchmark MATH AMC AIME GPQA 500 23 2024 Diamond Original large model(0.89,
2024
-
[58]
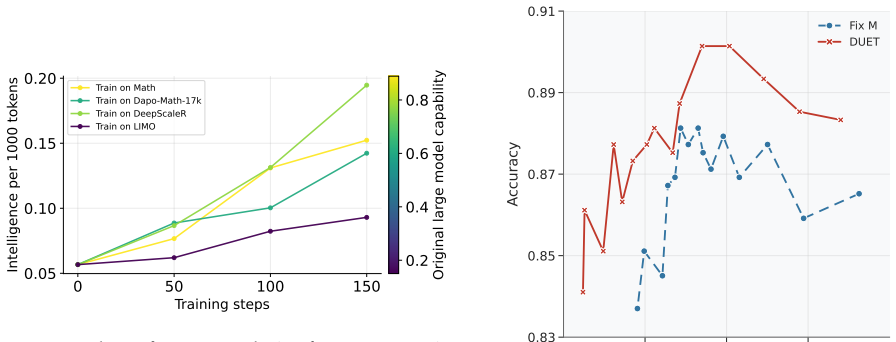
Each cell reports the intelligence-per-1000-tokens metric evaluated at 50, 100, and 150 training steps, respectively. Training dataset Benchmark AIME AIME GPQA 2024 2025 Diamond MATH-LightEval(0.075, 0.126, 0.121) (0.045, 0.073, 0.075) (0.113, 0.162, 0.230) DeepScaleR(0.089, 0.119, 0.109) (0.042, 0.079, 0.106) (0.129, 0.196, 0.369) DAPO-MATH-17k(0.085, 0....
2024
-
[59]
E.6 Ablation on Hyperparameters We conduct ablation studies on the hyperparameters in the length penalty, including B and λ (with constant schedule)
Training only the large model with a standard RL algorithm fails to produce concise reasoning, demonstrating that the ability to generate concise reasoning stems from the DUET framework and length-penalized joint training, rather than from the training dataset itself. E.6 Ablation on Hyperparameters We conduct ablation studies on the hyperparameters in th...
2000
-
[60]
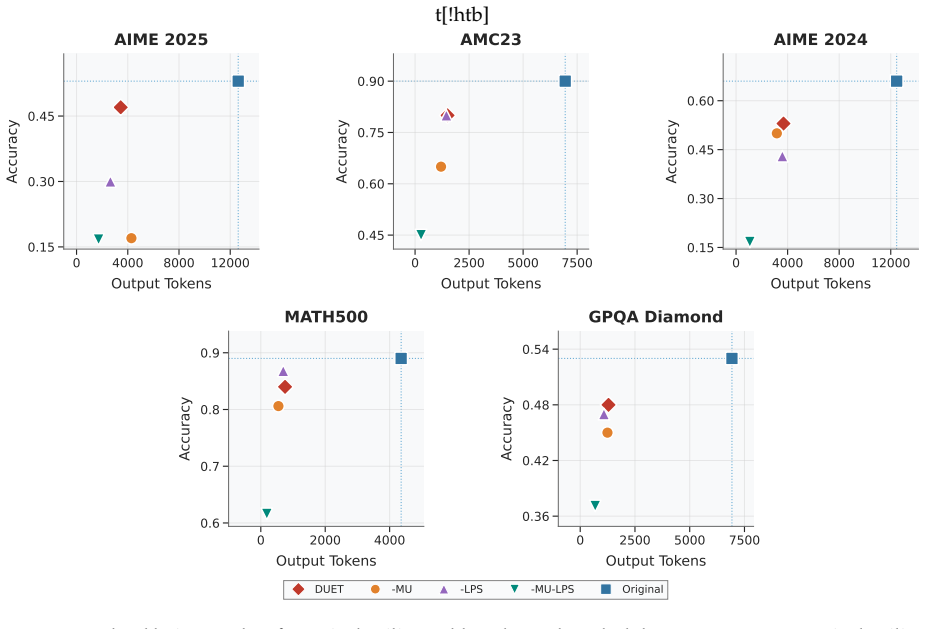
Larger values of λ apply stronger length penalties, achieving more compressed reasoning. As shown in the ablations on marginal utility and length penalty schedule (Section E.4), the constant schedule achieves similar 25 t[!htb] 0 4000 8000 12000 Output T okens 0.15 0.30 0.45 Accuracy AIME 2025 0 2500 5000 7500 Output T okens 0.45 0.60 0.75 0.90 Accuracy A...
2025
-
[61]
Models are trained on theDeepScaleRdataset and evaluated at 100 training steps across multiple benchmarks
We find that including the KL penalty achieves better performance and training stability 26 Table 8:Ablation study of hyperparameter B. Models are trained on theDeepScaleRdataset and evaluated at 100 training steps across multiple benchmarks. Acc. denotes accuracy (%) and Tokens denotes average output tokens per sample. Value of B MATH500 AMC23 AIME24 AIM...
2054
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.