Recognition: unknown
PERSA: Reinforcement Learning for Professor-Style Personalized Feedback with LLMs
Pith reviewed 2026-05-09 19:05 UTC · model grok-4.3
The pith
PERSA applies constrained reinforcement learning to personalize LLMs for matching individual professors' feedback styles on programming assignments while preserving diagnostic accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
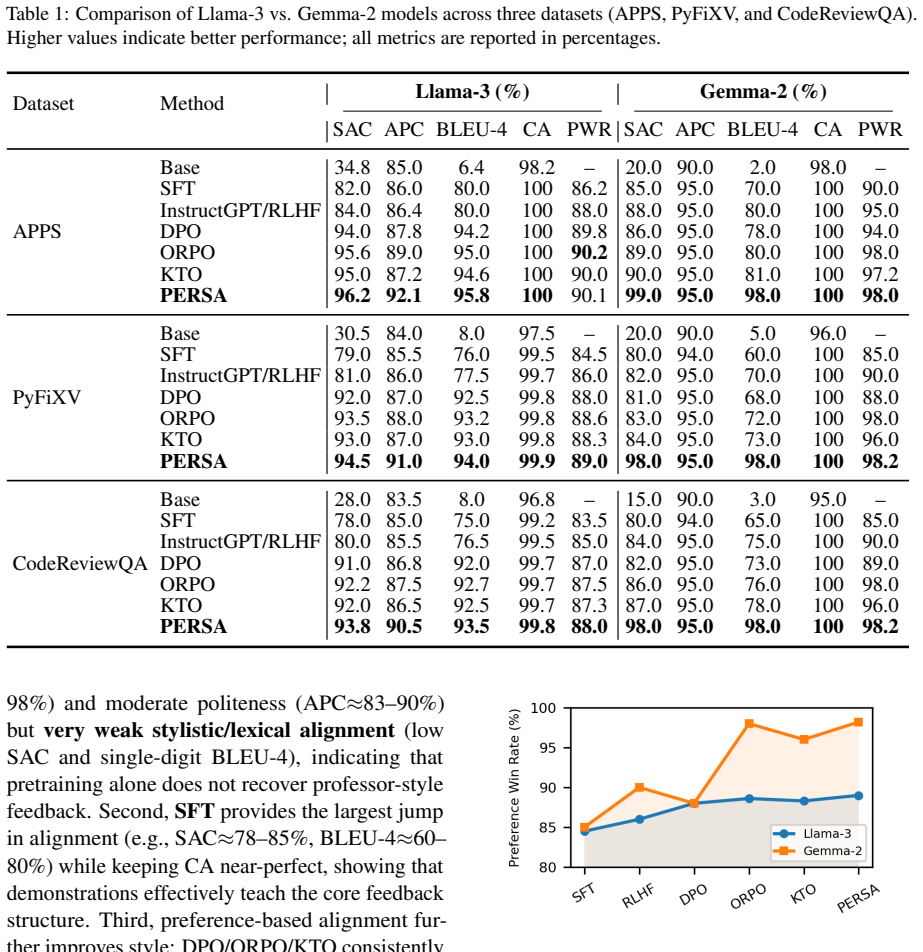
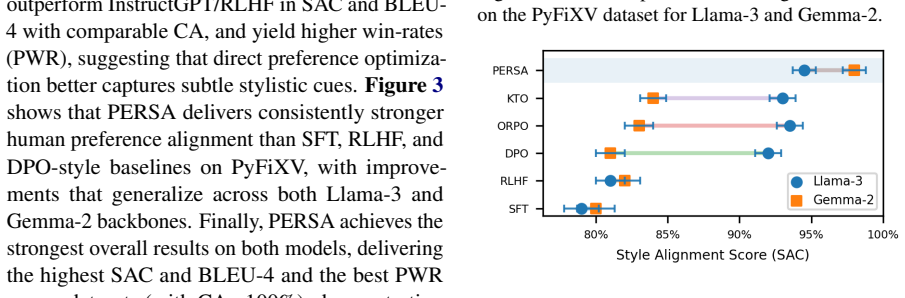
PERSA is an RLHF pipeline that first performs supervised fine-tuning on professor demonstrations, then trains a reward model on pairwise preferences, and finally applies PPO while limiting parameter changes to the uppermost transformer blocks and feed-forward networks. On the APPS benchmark this yields a Style Alignment Score of 96.2 percent compared with 34.8 percent for the unmodified base model, while Correctness Accuracy remains at 100 percent for both Llama-3 and Gemma-2. The same pattern holds on PyFiXV and CodeReviewQA, showing that style transfer and content fidelity can be achieved together through selective updating.
What carries the argument
Parameter-efficient fine-tuning restricted to the top transformer blocks and their feed-forward projections inside an RLHF pipeline that isolates style adaptation from core diagnostic knowledge.
If this is right
- Style alignment scores rise sharply on code-feedback tasks while correctness accuracy stays at ceiling levels.
- The same pipeline succeeds on both Llama-3 and Gemma-2 backbones without model-specific redesign.
- The method generalizes across the three evaluated benchmarks: APPS, PyFiXV, and CodeReviewQA.
- Feedback can be made to match both the factual diagnosis and the instructor's characteristic phrasing and structure.
Where Pith is reading between the lines
- Selective layer updating could reduce the cost of creating many instructor-specific tutor models for the same underlying LLM.
- The same style-isolation principle might transfer to feedback on math proofs or essay writing if those domains also localize tone in upper layers.
- Testing whether the unchanged lower layers retain performance on pure code-generation tasks would clarify how cleanly style and capability separate.
Load-bearing premise
That the professor-specific style lives mainly in the uppermost transformer blocks and feed-forward layers, so that updating only those components transfers the desired tone without disturbing the model's grasp of programming correctness.
What would settle it
If PERSA produces a measurable drop in correctness accuracy on APPS below 90 percent or fails to raise the style alignment score above the base model by a statistically clear margin, the claim that selective updates suffice would be refuted.
Figures




read the original abstract
Large language models (LLMs) can provide automated feedback in educational settings, but aligning an LLMs style with a specific instructors tone while maintaining diagnostic correctness remains challenging. We ask how can we update an LLM for automated feedback generation to align with a target instructors style without sacrificing core knowledge? We study how Reinforcement Learning from Human Feedback (RLHF) can adapt a transformer-based LLM to generate programming feedback that matches a professors grading voice. We introduce PERSA, an RLHF pipeline that combines supervised fine-tuning on professor demonstrations, reward modeling from pairwise preferences, and Proximal Policy Optimization (PPO), while deliberately constraining learning to style-bearing components. Motivated by analyses of transformer internals, PERSA applies parameter efficient fine-tuning. It updates only the top transformer blocks and their feed-forward projections, minimizing global parameter drift while increasing stylistic controllability. We evaluate our proposed approach on three code-feedback benchmarks (APPS, PyFiXV, and CodeReviewQA) using complementary metrics for style alignment and fidelity. Across both Llama-3 and Gemma-2 backbones, PERSA delivers the strongest professor-style transfer while retaining correctness, for example on APPS, it boosts Style Alignment Score (SAC) to 96.2% (from 34.8% for Base) with Correctness Accuracy (CA) up to 100% on Llama-3, and Gemma-2. Overall, PERSA offers a practical route to personalized educational feedback by aligning both what it says (content correctness) and, crucially, how it says it (instructor-like tone and structure).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PERSA, an RLHF pipeline for adapting LLMs (Llama-3, Gemma-2) to generate professor-style feedback on programming tasks. It combines SFT on professor demonstrations, reward modeling from pairwise preferences, and PPO, with updates deliberately restricted to the top transformer blocks and their feed-forward projections. Evaluations on APPS, PyFiXV, and CodeReviewQA report large gains in style alignment (e.g., SAC rising to 96.2% from 34.8% base on APPS) while preserving correctness accuracy up to 100%.
Significance. If the results hold under fuller verification, PERSA demonstrates a practical, parameter-efficient route to style personalization in educational LLMs without apparent loss of diagnostic capability. The selective-layer strategy, motivated by internal transformer analyses, could inform targeted adaptation techniques more broadly in controllable generation.
major comments (2)
- [Abstract and Experiments section] The central empirical claim (strong SAC gains with CA at 100%) is presented without reporting the volume of preference data, inter-rater agreement for style annotations, or statistical significance of the metric differences. These details are required to establish that the observed improvements are reliable and attributable to PERSA rather than data artifacts or baseline variance.
- [§3] §3 (method description): the design rests on the claim that style cues are sufficiently localized in the top blocks and FF projections so that constrained PPO can raise SAC while the frozen lower layers preserve diagnostic knowledge. No ablation is reported that varies the updated layers or compares against full-parameter fine-tuning; without this, the 100% CA cannot be distinguished from simple inheritance from the frozen components.
minor comments (2)
- [Abstract] Acronyms SAC and CA are used in the abstract without expansion on first occurrence; define them explicitly at first use.
- [Experiments section] Baseline descriptions (what exactly 'Base' and other comparators implement) should be stated more explicitly in the experimental setup for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of empirical rigor and methodological validation. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments section] The central empirical claim (strong SAC gains with CA at 100%) is presented without reporting the volume of preference data, inter-rater agreement for style annotations, or statistical significance of the metric differences. These details are required to establish that the observed improvements are reliable and attributable to PERSA rather than data artifacts or baseline variance.
Authors: We agree that these details are necessary to substantiate the reliability of the reported gains. In the revised manuscript, we will explicitly report the volume of preference data (number of pairs collected and number of annotators), inter-rater agreement for style annotations (e.g., Cohen's or Fleiss' kappa), and statistical significance of the SAC and CA differences (including p-values from appropriate tests and confidence intervals). These will be added to the Experiments section, Table 1, and associated text. revision: yes
-
Referee: [§3] §3 (method description): the design rests on the claim that style cues are sufficiently localized in the top blocks and FF projections so that constrained PPO can raise SAC while the frozen lower layers preserve diagnostic knowledge. No ablation is reported that varies the updated layers or compares against full-parameter fine-tuning; without this, the 100% CA cannot be distinguished from simple inheritance from the frozen components.
Authors: We acknowledge that ablations would more rigorously isolate the effect of our selective-layer strategy. Our layer selection is grounded in the transformer internal analyses presented in §3, but we will add a dedicated ablation subsection in the Experiments section. This will compare performance when updating different numbers of top blocks (e.g., top-2, top-4, top-8) as well as a full-parameter fine-tuning baseline (subject to compute constraints), reporting both SAC and CA for each. We will also discuss the trade-offs of full fine-tuning regarding efficiency and potential knowledge drift. revision: yes
Circularity Check
No circularity; results are independent empirical measurements on external benchmarks
full rationale
The paper describes an RLHF pipeline (SFT on professor demonstrations followed by pairwise reward modeling and PPO) with parameter-efficient updates restricted to top transformer blocks and feed-forward projections. All reported outcomes—Style Alignment Score (SAC) rising to 96.2% and Correctness Accuracy (CA) reaching 100% on APPS, PyFiXV, and CodeReviewQA—are framed as direct measurements on held-out evaluation sets using separate metrics for style and correctness. No equation, prediction, or central claim reduces by construction to a fitted parameter or self-citation; the performance numbers are obtained from external benchmarks rather than being algebraically entailed by the training procedure itself. The motivation from transformer-internal analyses is presented as background and does not create a self-referential loop in the derivation or results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
-
[2]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[3]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Style-specific neurons for steering LLMs in text style transfer , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[4]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[5]
arXiv preprint arXiv:2403.10704 , year=
Parameter efficient reinforcement learning from human feedback , author=. arXiv preprint arXiv:2403.10704 , year=
-
[6]
arXiv preprint arXiv:2404.11973 , year=
Exploring the landscape of large language models: Foundations, techniques, and challenges , author=. arXiv preprint arXiv:2404.11973 , year=
-
[7]
Large Language Models: A Deep Dive: Bridging Theory and Practice , pages=
Tuning for LLM alignment , author=. Large Language Models: A Deep Dive: Bridging Theory and Practice , pages=. 2024 , publisher=
2024
-
[8]
Assessing Writing , volume=
Fostering student engagement with feedback: An integrated approach , author=. Assessing Writing , volume=. 2022 , publisher=
2022
-
[9]
, author=
A meta-analysis of the effectiveness of intelligent tutoring systems on college students’ academic learning. , author=. Journal of educational psychology , volume=. 2014 , publisher=
2014
-
[10]
Feedback in higher and professional education , pages=
Trust and its role in facilitating dialogic feedback , author=. Feedback in higher and professional education , pages=. 2012 , publisher=
2012
-
[11]
arXiv preprint arXiv:2502.12842 , year=
Towards adaptive feedback with ai: Comparing the feedback quality of llms and teachers on experimentation protocols , author=. arXiv preprint arXiv:2502.12842 , year=
-
[12]
AI , volume=
The promises and pitfalls of large language models as feedback providers: A study of prompt engineering and the quality of AI-driven feedback , author=. AI , volume=. 2025 , publisher=
2025
-
[13]
Pedagogical alignment of large language models (
Razafinirina, Mahefa Abel and Dimbisoa, William Germain and Mahatody, Thomas , journal=. Pedagogical alignment of large language models (. 2024 , publisher=
2024
-
[14]
Educational Evaluation and Policy Analysis , volume=
Can automated feedback improve teachers’ uptake of student ideas? Evidence from a randomized controlled trial in a large-scale online course , author=. Educational Evaluation and Policy Analysis , volume=. 2024 , publisher=
2024
-
[15]
2002 , publisher=
Learning and teaching styles in engineering education , author=. 2002 , publisher=
2002
-
[16]
Teachers and Teaching , volume=
Pedagogical reasoning: The foundation of the professional knowledge of teaching , author=. Teachers and Teaching , volume=. 2019 , publisher=
2019
-
[18]
Advances in Neural Information Processing Systems , volume=
Openagi: When llm meets domain experts , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Zhao, J., Huang, J., Wu, Z., Bau, D., and Shi, W
Sorry-bench: Systematically evaluating large language model safety refusal , author=. arXiv preprint arXiv:2406.14598 , year=
-
[20]
ACM Computing Surveys , volume=
Rlhf deciphered: A critical analysis of reinforcement learning from human feedback for llms , author=. ACM Computing Surveys , volume=. 2025 , publisher=
2025
-
[21]
arXiv preprint arXiv:2404.09022 , year=
Navigating the landscape of large language models: A comprehensive review and analysis of paradigms and fine-tuning strategies , author=. arXiv preprint arXiv:2404.09022 , year=
-
[22]
Survey on factuality in large language models: Knowledge, retrieval and domain-specificity,
Survey on factuality in large language models: Knowledge, retrieval and domain-specificity , author=. arXiv preprint arXiv:2310.07521 , year=
-
[23]
arXiv preprint arXiv:2401.05778 , year=
Risk taxonomy, mitigation, and assessment benchmarks of large language model systems , author=. arXiv preprint arXiv:2401.05778 , year=
-
[24]
IEEE Access , volume=
Generation of asset administration shell with large language model agents: Toward semantic interoperability in digital twins in the context of industry 4.0 , author=. IEEE Access , volume=. 2024 , publisher=
2024
-
[25]
arXiv preprint arXiv:2408.13296 (2024)
The ultimate guide to fine-tuning llms from basics to breakthroughs: An exhaustive review of technologies, research, best practices, applied research challenges and opportunities , author=. arXiv preprint arXiv:2408.13296 , year=
-
[26]
2023 , publisher=
Quick start guide to large language models: strategies and best practices for using ChatGPT and other LLMs , author=. 2023 , publisher=
2023
-
[27]
arXiv preprint arXiv:2310.05191 , year=
Llm-as-a-tutor in efl writing education: Focusing on evaluation of student-llm interaction , author=. arXiv preprint arXiv:2310.05191 , year=
-
[28]
arXiv preprint arXiv:2407.10993 , year=
The effects of embodiment and personality expression on learning in llm-based educational agents , author=. arXiv preprint arXiv:2407.10993 , year=
-
[29]
Computers and Education: Artificial Intelligence , volume=
Analyzing K-12 AI education: A large language model study of classroom instruction on learning theories, pedagogy, tools, and AI literacy , author=. Computers and Education: Artificial Intelligence , volume=. 2024 , publisher=
2024
-
[30]
Natural Language Processing Journal , volume=
Towards effective teaching assistants: From intent-based chatbots to LLM-powered teaching assistants , author=. Natural Language Processing Journal , volume=. 2024 , publisher=
2024
-
[31]
Aligning large lan- guage models with human: A survey
Aligning large language models with human: A survey , author=. arXiv preprint arXiv:2307.12966 , year=
-
[32]
arXiv preprint arXiv:2501.04040 , year=
A survey on large language models with some insights on their capabilities and limitations , author=. arXiv preprint arXiv:2501.04040 , year=
-
[33]
Archives of Computational Methods in Engineering , volume=
Demystifying chatgpt: An in-depth survey of openai’s robust large language models , author=. Archives of Computational Methods in Engineering , volume=. 2024 , publisher=
2024
-
[34]
arXiv preprint arXiv:2310.05492 , year=
How abilities in large language models are affected by supervised fine-tuning data composition , author=. arXiv preprint arXiv:2310.05492 , year=
-
[35]
ESP International Journal of Advancements in Computational Technology (ESP-IJACT) , volume=
Reinforcement Learning: Advanced Techniques for LLM Behavior Optimization , author=. ESP International Journal of Advancements in Computational Technology (ESP-IJACT) , volume=
-
[36]
Proceedings of the AAAI Conference on Human Computation and Crowdsourcing , volume=
Investigating What Factors Influence Users’ Rating of Harmful Algorithmic Bias and Discrimination , author=. Proceedings of the AAAI Conference on Human Computation and Crowdsourcing , volume=
-
[37]
Style over substance: Evaluation biases for large language models.arXiv preprint arXiv:2307.03025,
Style over substance: Evaluation biases for large language models , author=. arXiv preprint arXiv:2307.03025 , year=
-
[38]
Mindstorms in natu- ral language-based societies of mind
Mindstorms in natural language-based societies of mind , author=. arXiv preprint arXiv:2305.17066 , year=
- [39]
-
[40]
Reward design with language models.arXiv preprint arXiv:2303.00001, 2023
Reward design with language models , author=. arXiv preprint arXiv:2303.00001 , year=
-
[41]
The Thirteenth International Conference on Learning Representations , year=
Rethinking reward modeling in preference-based large language model alignment , author=. The Thirteenth International Conference on Learning Representations , year=
-
[42]
Demystifying long chain-of- thought reasoning in llms.arXiv preprint arXiv:2502.03373, 2025
Demystifying long chain-of-thought reasoning in llms , author=. arXiv preprint arXiv:2502.03373 , year=
-
[43]
Understanding the effects of rlhf on llm generalisation and diversity , author=. arXiv preprint arXiv:2310.06452 , year=
-
[44]
2024 , school=
Automated Mechanistic Interpretability for Neural Networks , author=. 2024 , school=
2024
-
[45]
NEJM AI , volume=
Can large language models provide useful feedback on research papers? A large-scale empirical analysis , author=. NEJM AI , volume=. 2024 , publisher=
2024
-
[46]
Rlhf workflow: From reward modeling to online rlhf
Rlhf workflow: From reward modeling to online rlhf , author=. arXiv preprint arXiv:2405.07863 , year=
-
[47]
arXiv preprint arXiv:2409.15360 , year=
Reward-robust rlhf in llms , author=. arXiv preprint arXiv:2409.15360 , year=
-
[48]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[49]
Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
A computational approach to politeness with application to social factors , author=. Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
- [50]
-
[51]
Proceedings of the AAAI conference on artificial intelligence , volume=
Style transfer in text: Exploration and evaluation , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[52]
Jeuring and Bastiaan Heeren , title =
Hieke Keuning and Johan T. Jeuring and Bastiaan Heeren , title =. ACM Transactions on Computing Education , volume =. 2018 , doi =
2018
-
[53]
Assessing the proficiency of large language models in automatic feedback generation: An evaluation study , journal =
Wei Dai and Yi. Assessing the proficiency of large language models in automatic feedback generation: An evaluation study , journal =. 2024 , doi =
2024
-
[54]
2025 IEEE/ACM 37th International Conference on Software Engineering Education and Training (CSEE&T) , pages =
Dongwook Choi and Eunseok Lee , title =. 2025 IEEE/ACM 37th International Conference on Software Engineering Education and Training (CSEE&T) , pages =. 2025 , publisher =
2025
-
[55]
Proceedings of the 11th ACM Conference on Learning @ Scale (L@S 2024) , pages =
Hagit Gabbay and Anat Cohen , title =. Proceedings of the 11th ACM Conference on Learning @ Scale (L@S 2024) , pages =. 2024 , publisher =
2024
-
[56]
Evaluation of
Iria Est. Evaluation of. International Journal of Artificial Intelligence in Education , volume =. 2024 , doi =
2024
-
[57]
Proceedings of the 51st ACM Technical Symposium on Computer Science Education (SIGCSE '20) , year =
Luke Gusukuma and Austin Cory Bart and Dennis Kafura , title =. Proceedings of the 51st ACM Technical Symposium on Computer Science Education (SIGCSE '20) , year =
-
[58]
Meta-Learning the Difference: Preparing Large Language Models for Efficient Adaptation
Koto, Fajri and Lau, Jey Han and Baldwin, Timothy , title =. Transactions of the Association for Computational Linguistics , volume =. 2022 , pages =. doi:10.1162/tacl_a_00517 , note =
-
[59]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Geva, Mor and Schuster, Roei and Berant, Jonathan and Levy, Omer , title =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2021
-
[60]
2023 , howpublished =
McDougall, Callum , title =. 2023 , howpublished =
2023
-
[61]
ACM Transactions on Software Engineering and Methodology , year=
Ecosystem of large language models for code , author=. ACM Transactions on Software Engineering and Methodology , year=
-
[62]
arXiv preprint arXiv:2011.07537 , year=
Tonic: A deep reinforcement learning library for fast prototyping and benchmarking , author=. arXiv preprint arXiv:2011.07537 , year=
-
[63]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
arXiv preprint arXiv:2405.21046 , year=
Exploratory preference optimization: Harnessing implicit q*-approximation for sample-efficient rlhf , author=. arXiv preprint arXiv:2405.21046 , year=
-
[65]
Understanding layer significance in llm alignment, 2025
Understanding layer significance in llm alignment , author=. arXiv preprint arXiv:2410.17875 , year=
-
[66]
Engineering education , volume=
Learning and teaching styles in engineering education , author=. Engineering education , volume=. 1988 , publisher=
1988
-
[67]
An empirical study of catastrophic forgetting in large language models during continual fine-tuning , author =. arXiv preprint arXiv:2308.08747 , year =
-
[68]
arXiv preprint arXiv:2302.04662 , year=
Generating high-precision feedback for programming syntax errors using large language models , author=. arXiv preprint arXiv:2302.04662 , year=
-
[69]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Codereviewqa: The code review comprehension assessment for large language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[70]
Measuring Coding Challenge Competence With APPS
Measuring coding challenge competence with apps , author=. arXiv preprint arXiv:2105.09938 , year=
work page internal anchor Pith review arXiv
-
[71]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
work page internal anchor Pith review arXiv
-
[72]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[73]
Advances in Neural Information Processing Systems , volume=
DPO: Direct Preference Optimization with Dynamic , author=. Advances in Neural Information Processing Systems , volume=
-
[74]
arXiv preprint arXiv:2403.07691 , year=
Orpo: Monolithic preference optimization without reference model , author=. arXiv preprint arXiv:2403.07691 , year=
-
[75]
KTO: Model Alignment as Prospect Theoretic Optimization
Kto: Model alignment as prospect theoretic optimization , author=. arXiv preprint arXiv:2402.01306 , year=
work page internal anchor Pith review arXiv
-
[76]
2025 IEEE Global Engineering Education Conference (EDUCON) , pages=
The responsible development of automated student feedback with generative ai , author=. 2025 IEEE Global Engineering Education Conference (EDUCON) , pages=. 2025 , organization=
2025
-
[77]
arXiv preprint arXiv:2603.14819 , year=
RAZOR: Ratio-Aware Layer Editing for Targeted Unlearning in Vision Transformers and Diffusion Models , author=. arXiv preprint arXiv:2603.14819 , year=
-
[78]
arXiv preprint arXiv:2603.21524 , year=
CatRAG: Functor-Guided Structural Debiasing with Retrieval Augmentation for Fair LLMs , author=. arXiv preprint arXiv:2603.21524 , year=
-
[79]
arXiv preprint arXiv:2604.00419 , year=
G-Drift MIA: Membership Inference via Gradient-Induced Feature Drift in LLMs , author=. arXiv preprint arXiv:2604.00419 , year=
-
[80]
arXiv preprint arXiv:2603.07368 , year=
Position: Llms must use functor-based and rag-driven bias mitigation for fairness , author=. arXiv preprint arXiv:2603.07368 , year=
-
[81]
preprint , year=
Trustworthiness of llms in medical domain , author=. preprint , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.