Recognition: unknown
Forager: a lightweight testbed for continual learning with partial observability in RL
Pith reviewed 2026-05-09 19:12 UTC · model grok-4.3
The pith
A lightweight testbed called Forager shows that constructing internal states helps continual RL agents retain learning ability in partially observable worlds more than standard plasticity fixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
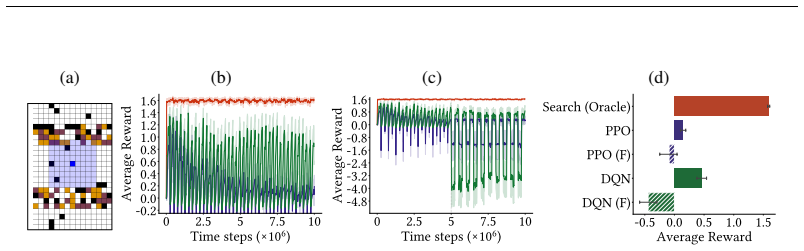
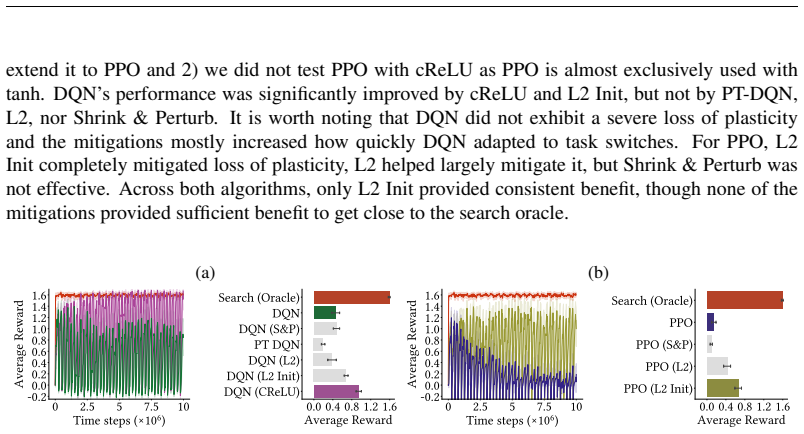
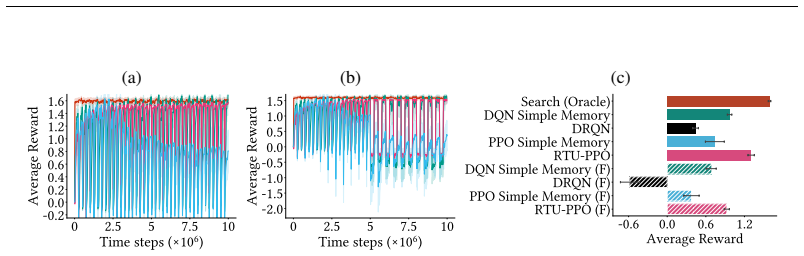
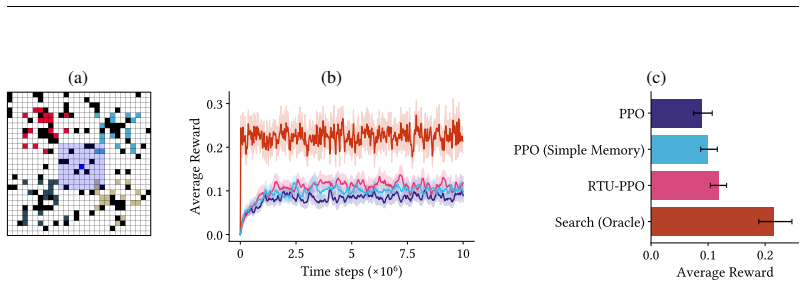
Forager is a partially observable continual RL environment with fixed memory footprint in which agents must act, explore, and learn indefinitely; experiments establish that loss of plasticity appears, proposed mitigations help modestly, state construction helps most, and an infinite-task variant exposes clear limits of current agents.
What carries the argument
State construction, the process by which agents build and maintain internal representations of the partially observed world to support ongoing learning and adaptation.
If this is right
- CRL agents that incorporate recurrence or memory mechanisms will maintain performance longer than memory-less agents in long-horizon partially observable settings.
- Fixes focused only on plasticity loss, such as weight resetting or regularization, will remain insufficient without accompanying improvements in state representation.
- Researchers can now run controlled, low-cost experiments that isolate the interaction between partial observability and continual learning.
- Environments that generate new tasks on the fly will serve as stronger benchmarks for evaluating whether agents can truly learn indefinitely.
Where Pith is reading between the lines
- Future work should treat representation learning as a primary lever for continual RL rather than a secondary concern after plasticity fixes.
- The same lightweight testbed approach could be adapted to study continual learning in other domains that combine partial observability with non-stationarity, such as dialogue or recommendation systems.
- An open question left by the work is how state construction scales when the underlying world grows in size or complexity beyond the Forager tasks.
Load-bearing premise
The specific tasks and partial-observability structure chosen for Forager are representative enough of real-world continual learning problems to support general statements about agent limitations.
What would settle it
Apply the same set of agents and mitigations to a different partially observable continual task with richer dynamics, such as a simulated robotics navigation problem with moving obstacles, and check whether state construction still outperforms the other methods by a wide margin.
Figures






read the original abstract
In continual reinforcement learning (CRL), good performance requires never-ending learning, acting, and exploration in a big, partially observable world. Most CRL experiments have focused on loss of plasticity -- the inability to keep learning -- in one-off experiments where some unobservable non-stationarity is added to classic fully observable MDPs. Further, these experiments rarely consider the role of partial observability and the importance of CRL agents that use memory or recurrence. One potential reason for this focus on mitigating loss of plasticity without considering partial observability is that many partially-observable CRL environments are prohibitively expensive. In this paper, we introduce Forager, a light-weight partially-observable CRL environment with a constant memory footprint. We provide a set of experiments and sample tasks demonstrating that Forager is challenging for current CRL agents and yet also allows for in-depth study of those agents. We demonstrate that agents exhibit loss of plasticity, proposed mitigations can help, but that most useful is to leverage state construction. We conclude with a variant of Forager that generates an unending stream of new tasks to learn that clearly highlights the limitations of current CRL agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Forager, a lightweight partially-observable continual reinforcement learning (CRL) testbed featuring constant memory footprint and procedurally generated tasks. It reports experiments demonstrating that agents exhibit loss of plasticity, that proposed mitigations offer partial relief, but that state construction is the most effective approach; a final variant with an unending stream of new tasks is used to illustrate fundamental limitations of current CRL agents.
Significance. If the empirical findings hold, Forager supplies a computationally efficient and reproducible benchmark for studying CRL under partial observability, an area where many existing environments are prohibitively expensive. The constant memory footprint and procedural task generation are clear strengths for scalability and reproducibility. The relative emphasis on state construction over other plasticity mitigations offers a concrete direction for agent design that could influence future work in memory-augmented RL.
major comments (2)
- [Abstract] Abstract: the central claims that 'most useful is to leverage state construction' and that the unending-task variant 'clearly highlights the limitations of current CRL agents' rest on Forager's specific PO structure and task-generation mechanism being representative of broader CRL challenges. No explicit mapping is provided to real-world properties such as long-term dependencies, non-stationary hidden dynamics, or scaling with observation dimensionality, so the diagnostic value for 'current CRL agents' in general is not yet substantiated.
- [unending-task variant section] Section describing the unending-task variant: while the variant is presented as exposing fundamental limits, the procedural generation rules themselves could be the dominant source of difficulty rather than intrinsic CRL issues; a direct comparison against established PO CRL benchmarks (e.g., with controlled long-horizon dependencies) is needed to separate environment-specific effects from general claims.
minor comments (2)
- [Experiments section] All experimental results should include error bars, number of seeds, and statistical tests; the abstract's lack of any quantitative data makes it impossible to evaluate the magnitude of the reported effects.
- Clarify notation for state-construction modules versus standard recurrent baselines so readers can immediately distinguish the proposed approach from prior work.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, indicating where revisions have been or will be made to strengthen the manuscript while preserving its core contributions as a lightweight testbed.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that 'most useful is to leverage state construction' and that the unending-task variant 'clearly highlights the limitations of current CRL agents' rest on Forager's specific PO structure and task-generation mechanism being representative of broader CRL challenges. No explicit mapping is provided to real-world properties such as long-term dependencies, non-stationary hidden dynamics, or scaling with observation dimensionality, so the diagnostic value for 'current CRL agents' in general is not yet substantiated.
Authors: We agree that an explicit mapping to broader CRL challenges would improve the substantiation of our claims. In the revised manuscript, we have added a dedicated paragraph in the introduction (immediately following the problem statement) that provides this mapping: Forager's partial observability and memory requirements are linked to long-term dependencies in real-world POMDPs; its procedural task switches model non-stationary hidden dynamics; and the constant memory footprint is discussed in relation to scaling with observation dimensionality. We have also lightly revised the abstract to frame the claims as diagnostic insights obtained within this controlled testbed rather than universal statements about all CRL settings. revision: yes
-
Referee: [unending-task variant section] Section describing the unending-task variant: while the variant is presented as exposing fundamental limits, the procedural generation rules themselves could be the dominant source of difficulty rather than intrinsic CRL issues; a direct comparison against established PO CRL benchmarks (e.g., with controlled long-horizon dependencies) is needed to separate environment-specific effects from general claims.
Authors: We acknowledge the validity of this concern regarding potential confounding from the procedural rules. In the revised section, we have expanded the description of the generation mechanism to emphasize its controllable parameters (e.g., explicit variation of task complexity and dependency length independent of the continual aspect) and clarified that single-task performance remains high, isolating the difficulty to the unending CRL setting. We have also softened the language from 'clearly highlights the limitations of current CRL agents' to 'illustrates key limitations of current CRL agents within this scalable PO setting.' A full direct comparison to other established benchmarks would require additional experiments outside the current scope; we instead position Forager as a complementary lightweight tool and note this as an avenue for future work. revision: partial
Circularity Check
Empirical testbed introduction with no derivations or self-referential reductions
full rationale
The paper introduces the Forager environment and reports experimental results on loss of plasticity, mitigations, state construction benefits, and an unending-task variant. No equations, parameter fits, or derivation chains exist that could reduce to inputs by construction. Claims rest on direct empirical evaluation within the new testbed rather than self-citation load-bearing, uniqueness theorems, or renamed known results. Representativeness of the tasks is an external-validity question, not a circularity issue in any claimed derivation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Forager environment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Charnov, Eric , year =
Pyke, Graham and Pulliam, H. and Charnov, Eric , year =. Optimal Foraging: A Selective Review of Theory and Tests , journal =
-
[2]
Charnov , journal =
Eric L. Charnov , journal =. Optimal foraging, the marginal value theorem , year =
-
[3]
International Conference on Machine Learning , year=
On the role of tracking in stationary environments , author=. International Conference on Machine Learning , year=
-
[4]
International Conference on Machine Learning , year=
Craftax: A Lightning-Fast Benchmark for Open-Ended Reinforcement Learning , author=. International Conference on Machine Learning , year=
-
[5]
Advances in Neural Information Processing Systems , year=
Discovered policy optimisation , author=. Advances in Neural Information Processing Systems , year=
-
[6]
arXiv preprint arXiv:2208.11173 , year=
The Alberta plan for AI research , author=. arXiv preprint arXiv:2208.11173 , year=
-
[7]
international conference on intelligent robots and systems , year=
Mujoco: A physics engine for model-based control , author=. international conference on intelligent robots and systems , year=
-
[8]
Trends in cognitive sciences , year=
Catastrophic forgetting in connectionist networks , author=. Trends in cognitive sciences , year=
-
[9]
International Conference on Learning Representations , year=
Jelly Bean World: A Testbed for Never-Ending Learning , author=. International Conference on Learning Representations , year=
-
[10]
Deepmind lab , author=. arXiv preprint arXiv:1612.03801 , year=
-
[11]
Advances in Neural Information Processing Systems , year=
Non-stationary learning of neural networks with automatic soft parameter reset , author=. Advances in Neural Information Processing Systems , year=
-
[12]
Advances in Neural Information Processing Systems , year=
Real-time recurrent learning using trace units in reinforcement learning , author=. Advances in Neural Information Processing Systems , year=
-
[13]
Adaptive Behavior , year=
From eye-blinks to state construction: Diagnostic benchmarks for online representation learning , author=. Adaptive Behavior , year=
-
[14]
International Conference on Learning Representations , year=
Learning Continually by Spectral Regularization , author=. International Conference on Learning Representations , year=
-
[15]
Journal of Artificial Intelligence Research , year=
Revisiting the arcade learning environment: Evaluation protocols and open problems for general agents , author=. Journal of Artificial Intelligence Research , year=
-
[16]
AAAI Conference on Artificial Intelligence , year=
Rainbow: Combining improvements in deep reinforcement learning , author=. AAAI Conference on Artificial Intelligence , year=
-
[17]
Real-Time Recurrent Learning using Trace Units in Reinforcement Learning , year =
Elelimy, Esraa and White, Adam and Bowling, Michael and White, Martha , booktitle =. Real-Time Recurrent Learning using Trace Units in Reinforcement Learning , year =
-
[18]
Finding the Frame: An RLC Workshop for Examining Conceptual Frameworks , year=
The big world hypothesis and its ramifications for artificial intelligence , author=. Finding the Frame: An RLC Workshop for Examining Conceptual Frameworks , year=
-
[19]
Steven Morad and Ryan Kortvelesy and Matteo Bettini and Stephan Liwicki and Amanda Prorok , booktitle=
-
[20]
Journal of Artificial Intelligence Research , year=
The arcade learning environment: An evaluation platform for general agents , author=. Journal of Artificial Intelligence Research , year=
-
[21]
AAAI Conference on Artificial Intelligence , year=
Toward an architecture for never-ending language learning , author=. AAAI Conference on Artificial Intelligence , year=
-
[22]
On the Properties of Neural Machine Translation: Encoder -- Decoder Approaches
Cho, Kyunghyun and van Merri. On the Properties of Neural Machine Translation: Encoder -- Decoder Approaches. Workshop on Syntax, Semantics and Structure in Statistical Translation. 2014
2014
-
[23]
Learning phrase representations using RNN encoder-decoder for statistical machine translation,
Cho, Kyunghyun and van Merri. Learning Phrase Representations using RNN Encoder -- Decoder for Statistical Machine Translation. Conference on Empirical Methods in Natural Language Processing. 2014. doi:10.3115/v1/D14-1179
-
[24]
International Conference on Learning Representations , year=
Autonomous Reinforcement Learning: Formalism and Benchmarking , author=. International Conference on Learning Representations , year=
-
[26]
International Conference on Machine Learning Position Paper Track , year=
Position: Lifetime tuning is incompatible with continual reinforcement learning , author=. International Conference on Machine Learning Position Paper Track , year=
-
[27]
AAAI Conference on Artificial Intelligence , volume=
A deep hierarchical approach to lifelong learning in minecraft , author=. AAAI Conference on Artificial Intelligence , volume=
-
[28]
The eleventh international conference on learning representations , year=
Memory gym: Partially observable challenges to memory-based agents , author=. The eleventh international conference on learning representations , year=
-
[29]
Conference on Lifelong Learning Agents , year=
Cora: Benchmarks, baselines, and metrics as a platform for continual reinforcement learning agents , author=. Conference on Lifelong Learning Agents , year=
-
[30]
Advances in Neural Information Processing Systems , year=
Coom: A game benchmark for continual reinforcement learning , author=. Advances in Neural Information Processing Systems , year=
-
[31]
Mastering diverse control tasks through world models , journal =
Hafner, Danijar and Pasukonis, Jurgis and Ba, Jimmy and Lillicrap, Timothy , year =. Mastering diverse control tasks through world models , journal =
-
[32]
Advances in Neural Information Processing Systems , year=
The nethack learning environment , author=. Advances in Neural Information Processing Systems , year=
-
[33]
International Conference on Learning Representations , year=
Benchmarking the Spectrum of Agent Capabilities , author=. International Conference on Learning Representations , year=
-
[34]
arXiv preprint arXiv:2101.11071 , year=
The minerl 2020 competition on sample efficient reinforcement learning using human priors , author=. arXiv preprint arXiv:2101.11071 , year=
-
[35]
Advances in Neural Information Processing Systems , year=
Continual world: A robotic benchmark for continual reinforcement learning , author=. Advances in Neural Information Processing Systems , year=
-
[36]
International conference on machine learning , year=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , year=
-
[37]
AAAI Conference on Artificial Intelligence , year=
Deep reinforcement learning with double q-learning , author=. AAAI Conference on Artificial Intelligence , year=
-
[38]
Journal of Machine Learning Research , year=
End-to-end training of deep visuomotor policies , author=. Journal of Machine Learning Research , year=
-
[39]
International Conference on Learning Representations , year=
Implicit Under-Parameterization Inhibits Data-Efficient Deep Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[40]
Conference on Lifelong Learning Agents , year =
Disentangling the causes of plasticity loss in neural networks , author=. Conference on Lifelong Learning Agents , year =
-
[41]
2024 , articleno =
Lee, Hojoon and Cho, Hyeonseo and Kim, Hyunseung and Kim, Donghu and Min, Dugki and Choo, Jaegul and Lyle, Clare , title =. 2024 , articleno =
2024
-
[42]
International Conference on Learning Representations , year=
Addressing Loss of Plasticity and Catastrophic Forgetting in Continual Learning , author=. International Conference on Learning Representations , year=
-
[43]
Proceedings of the National Academy of Sciences , year=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the National Academy of Sciences , year=
-
[44]
Advances in Neural Information Processing Systems , year=
On warm-starting neural network training , author=. Advances in Neural Information Processing Systems , year=
-
[45]
Advances in Neural Information Processing Systems , year=
Normalization and effective learning rates in reinforcement learning , author=. Advances in Neural Information Processing Systems , year=
-
[46]
arXiv preprint arXiv:2506.06981 , year=
Deep rl needs deep behavior analysis: Exploring implicit planning by model-free agents in open-ended environments , author=. arXiv preprint arXiv:2506.06981 , year=
-
[47]
International Conference on Machine Learning , year=
The Impact of On-Policy Parallelized Data Collection on Deep Reinforcement Learning Networks , author=. International Conference on Machine Learning , year=
-
[48]
, author=
Deep Recurrent Q-Learning for Partially Observable MDPs. , author=. AAAI Fall Symposia , volume=
-
[49]
Advances in Neural Information Processing Systems , year=
A definition of continual reinforcement learning , author=. Advances in Neural Information Processing Systems , year=
-
[50]
Conference on Lifelong Learning Agents , year =
Maintaining Plasticity in Continual Learning via Regenerative Regularization , author =. Conference on Lifelong Learning Agents , year =
-
[51]
Advances in Neural Information Processing Systems , year=
Prediction and control in continual reinforcement learning , author=. Advances in Neural Information Processing Systems , year=
-
[52]
arXiv preprint arXiv:2403.00514 , year=
Overestimation, overfitting, and plasticity in actor-critic: the bitter lesson of reinforcement learning , author=. arXiv preprint arXiv:2403.00514 , year=
-
[53]
Advances in Neural Information Processing Systems , year=
Plastic: Improving input and label plasticity for sample efficient reinforcement learning , author=. Advances in Neural Information Processing Systems , year=
-
[54]
Advances in Neural Information Processing Systems , year=
Deep reinforcement learning with plasticity injection , author=. Advances in Neural Information Processing Systems , year=
-
[55]
Conference on Lifelong Learning Agents , year=
Loss of plasticity in continual deep reinforcement learning , author=. Conference on Lifelong Learning Agents , year=
-
[56]
Sixteenth European Workshop on Reinforcement Learning , year=
Overcoming Policy Collapse in Deep Reinforcement Learning , author=. Sixteenth European Workshop on Reinforcement Learning , year=
-
[57]
Machine Learning , year=
GVFs in the real world: making predictions online for water treatment , author=. Machine Learning , year=
-
[58]
Journal of Machine Learning Research , year=
Empirical Design in Reinforcement Learning , author=. Journal of Machine Learning Research , year=
-
[59]
3rd International Conference on Learning Representations , year =
Dzmitry Bahdanau and Kyunghyun Cho and Yoshua Bengio , title =. 3rd International Conference on Learning Representations , year =
-
[60]
International Conference on Learning Representations , year=
Recurrent Experience Replay in Distributed Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[61]
Proximal Policy Optimization Algorithms
John Schulman and Filip Wolski and Prafulla Dhariwal and Alec Radford and Oleg Klimov , title =. arXiv preprint arxiv:1707.06347 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
and Zipser, David , journal=
Williams, Ronald J. and Zipser, David , journal=. A Learning Algorithm for Continually Running Fully Recurrent Neural Networks , year=
-
[63]
International Conference on Learning Representations , year=
Understanding and Preventing Capacity Loss in Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[64]
Fernando and Lan, Qingfeng and Rahman, Parash and Mahmood, A
Dohare, Shibhansh and Hernandez-Garcia, J. Fernando and Lan, Qingfeng and Rahman, Parash and Mahmood, A. Rupam and Sutton, Richard S , year =. Loss of plasticity in deep continual learning , journal =
-
[65]
Remove Symmetries to Control Model Expressivity and Improve Optimization , author=
-
[66]
International Conference on Machine Learning , year=
Understanding plasticity in neural networks , author=. International Conference on Machine Learning , year=
-
[67]
International Conference on Machine Learning , year=
The dormant neuron phenomenon in deep reinforcement learning , author=. International Conference on Machine Learning , year=
-
[68]
International Conference on Learning Representations , year=
CausalWorld: A Robotic Manipulation Benchmark for Causal Structure and Transfer Learning , author=. International Conference on Learning Representations , year=
-
[69]
Journal of Artificial Intelligence Research , year=
Towards continual reinforcement learning: A review and perspectives , author=. Journal of Artificial Intelligence Research , year=
-
[70]
Klein Tank, A. M. G. and Wijngaard, J. B. and Können, G. P. and Böhm, R. and Demarée, G. and Gocheva, A. and Mileta, M. and Pashiardis, S. and Hejkrlik, L. and Kern-Hansen, C. and Heino, R. and Bessemoulin, P. and Müller-Westermeier, G. and Tzanakou, M. and Szalai, S. and Pálsdóttir, T. and Fitzgerald, D. and Rubin, S. and Capaldo, M. and Maugeri, M. and ...
-
[71]
and Veness, Joel and Bellemare, Marc G
Mnih, Volodymyr and Kavukcuoglu, Koray and Silver, David and Rusu, Andrei A. and Veness, Joel and Bellemare, Marc G. and Graves, Alex and Riedmiller, Martin and Fidjeland, Andreas K. and Ostrovski, Georg and Petersen, Stig and Beattie, Charles and Sadik, Amir and Antonoglou, Ioannis and King, Helen and Kumaran, Dharshan and Wierstra, Daan and Legg, Shane ...
-
[72]
arXiv preprint arXiv:2410.07994 , year=
Neuroplastic expansion in deep reinforcement learning , author=. arXiv preprint arXiv:2410.07994 , year=
-
[73]
arXiv preprint arXiv:2505.18347 , year =
The Cell Must Go On: Agar.io for Continual Reinforcement Learning , author =. arXiv preprint arXiv:2505.18347 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.