Recognition: unknown
Position: Safety and Fairness in Agentic AI Depend on Interaction Topology, Not on Model Scale or Alignment
Pith reviewed 2026-05-09 18:49 UTC · model grok-4.3
The pith
Safety and fairness in multi-agent AI systems depend on how agents interact rather than on the scale or alignment of their models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
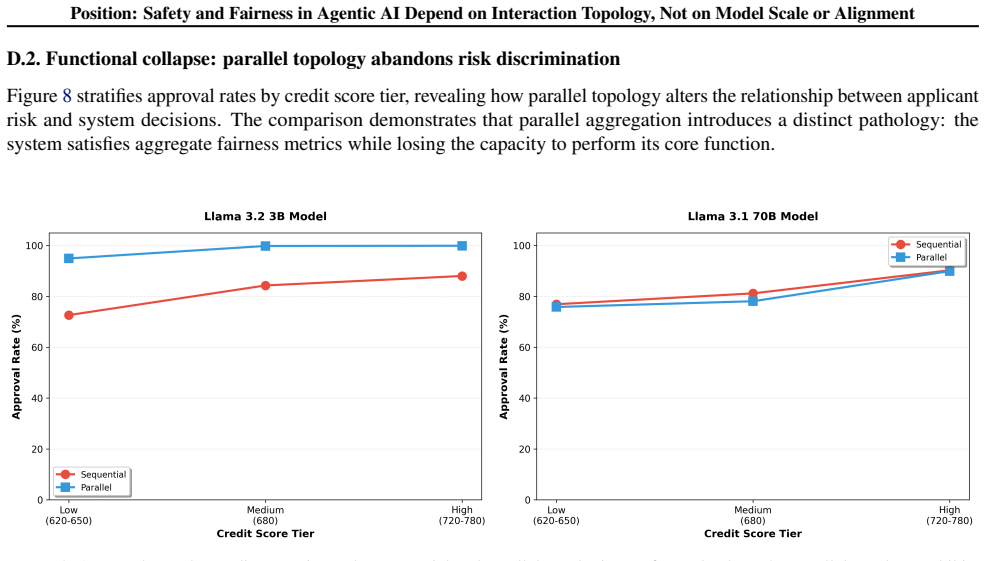
In agentic AI, safety is determined by interaction topology, not model weights. When agents deliberate sequentially or aggregate via parallel voting with a judge, the structure of information flow and decision coupling dominates outcomes. Evidence across model families and scales reveals three persistent topology-driven pathologies: ordering instability, where system behavior depends primarily on agent sequence; information cascades, where early judgments propagate regardless of correctness; and functional collapse, where systems satisfy fairness metrics while abandoning meaningful risk discrimination. Contrary to intuition, scaling to more capable models strengthens these effects by increas
What carries the argument
Interaction topology: the pattern of information flow and decision coupling among agents, which determines system-level safety and fairness independently of individual model scale or alignment.
If this is right
- Safety evaluations must test multi-agent systems under varied interaction architectures rather than isolated models.
- Regulatory requirements for high-stakes agentic AI should include demonstrated robustness to changes in agent ordering and coupling.
- Model scaling alone will not resolve these issues and may intensify consensus-driven failures.
- Design of agent systems must treat topology as a controllable variable subject to explicit safety testing.
Where Pith is reading between the lines
- Topologies with randomized ordering or explicit dissent mechanisms could be tested as practical mitigations.
- The same topology effects may appear in human-AI collaborative decision systems.
- Existing benchmarks for single-model alignment are structurally blind to these interaction failures.
Load-bearing premise
The three observed pathologies are general consequences of any sequential or voting-based interaction structure rather than artifacts of the particular agent implementations or evaluation tasks used.
What would settle it
An experiment showing that reordering agents or changing the aggregation rule eliminates ordering instability, information cascades, and functional collapse while holding model weights fixed, or conversely that the pathologies persist in non-agentic systems with the same models.
Figures






read the original abstract
As large language models are increasingly deployed as interacting agents in high-stakes decisions, the AI safety community assumes that safety properties of individual models will compose into safe multi-agent behavior. This position paper argues that this assumption is fundamentally mistaken. In agentic AI, safety is determined by interaction topology, not model weights. When agents deliberate sequentially or aggregate via parallel voting with a judge, the structure of information flow and decision coupling dominates outcomes. Evidence across model families and scales reveals three persistent topology-driven pathologies: ordering instability, where system behavior depends primarily on agent sequence; information cascades, where early judgments propagate regardless of correctness; and functional collapse, where systems satisfy fairness metrics while abandoning meaningful risk discrimination. Contrary to intuition, scaling to more capable models strengthens these effects by increasing consensus formation and reducing the challenge of initial decisions. These failure modes are invisible to model-centric evaluation and alignment procedures. We argue that agentic AI must be treated as a dynamical system rather than a collection of aligned components. Interaction topology must become a primary target of safety evaluation and regulation, with systems required to demonstrate robustness across architectural variations before deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a position paper arguing that safety and fairness properties in agentic AI systems are determined by interaction topology (e.g., sequential deliberation or parallel voting with a judge) rather than by model scale or alignment. It identifies three topology-driven pathologies—ordering instability, information cascades, and functional collapse—that dominate outcomes and are strengthened by scaling, rendering them invisible to model-centric evaluations. The paper concludes that agentic AI must be analyzed as dynamical systems, with interaction topology becoming a primary target for safety evaluation and regulation.
Significance. If the central claims hold and the pathologies prove robust across setups, the position would meaningfully reorient AI safety research away from individual model alignment toward system-level interaction design. This could affect evaluation protocols and regulatory requirements for deployed multi-agent systems in high-stakes domains.
major comments (2)
- [Abstract] Abstract: The claim that 'evidence across model families and scales reveals' the three pathologies (ordering instability, information cascades, functional collapse) is presented without any description of experimental protocols, agent definitions, deliberation prompts, voting rules, fairness metrics, model scales tested, or quantitative results. This absence prevents assessment of whether the effects are invariant properties of topology or artifacts of specific implementations and metric choices.
- [Abstract] Abstract: The assertion that 'scaling to more capable models strengthens these effects by increasing consensus formation' is stated without supporting analysis, data, or controls, yet this counterintuitive strengthening is load-bearing for the argument that model-centric approaches are insufficient.
minor comments (1)
- [Abstract] The abstract introduces the three pathologies without concise definitions or illustrative examples, which reduces clarity for readers new to the concepts.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our position paper. We address the two major comments on the abstract below. As a position paper, the abstract summarizes the core argument while the body provides the supporting experimental details; we will revise the abstract for greater self-containment without exceeding length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'evidence across model families and scales reveals' the three pathologies (ordering instability, information cascades, functional collapse) is presented without any description of experimental protocols, agent definitions, deliberation prompts, voting rules, fairness metrics, model scales tested, or quantitative results. This absence prevents assessment of whether the effects are invariant properties of topology or artifacts of specific implementations and metric choices.
Authors: We agree that the abstract, due to length limits, does not enumerate protocols. The full manuscript contains dedicated experimental sections that define the agent architectures, deliberation and voting procedures, fairness metrics (including risk discrimination and consensus measures), model families and scales tested, and quantitative results across configurations. These setups were chosen to isolate topology while varying scale and family, demonstrating the pathologies as topology-driven. To address the concern, we will revise the abstract to include a concise high-level description of the experimental approach and the key invariance findings. revision: partial
-
Referee: [Abstract] Abstract: The assertion that 'scaling to more capable models strengthens these effects by increasing consensus formation' is stated without supporting analysis, data, or controls, yet this counterintuitive strengthening is load-bearing for the argument that model-centric approaches are insufficient.
Authors: The claim is grounded in the manuscript's comparative experiments, which hold topology, prompts, and evaluation metrics fixed while varying model scale and capability. Larger models show measurably higher early consensus rates, which in turn amplify ordering instability and cascades while accelerating functional collapse. We will expand the revised manuscript with an explicit subsection on the scaling analysis, including controls, quantitative comparisons, and discussion of why this strengthening occurs, to make the supporting evidence more transparent. revision: yes
Circularity Check
No circularity; declarative position without self-referential derivations or equations
full rationale
The paper is a position statement asserting that safety and fairness in agentic AI are governed by interaction topology rather than model scale or alignment. It invokes three named pathologies (ordering instability, information cascades, functional collapse) as 'persistent topology-driven' effects 'revealed' by evidence across models, but supplies no equations, fitted parameters, predictions derived from inputs, or self-citations that function as load-bearing uniqueness theorems. No step reduces by construction to a prior definition or fit within the paper itself; the argument remains declarative and external to any closed loop of the form 'X is defined via Y which is measured from X'. Absence of empirical protocols is a supportability issue, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption safety properties of individual models will compose into safe multi-agent behavior
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[2]
On the Opportunities and Risks of Foundation Models
On the Opportunities and Risks of Foundation Models , author=. arXiv preprint arXiv:2108.07258 , year=
work page internal anchor Pith review arXiv
-
[3]
Advances in Neural Information Processing Systems , year=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[4]
2025 , note=
Multi-Agent Risks from Advanced AI , author=. 2025 , note=
2025
-
[5]
Review of Economic Studies , volume=
Bayesian Learning in Social Networks , author=. Review of Economic Studies , volume=
-
[6]
Advances in Complex Systems , volume=
Mixing Beliefs Among Interacting Agents , author=. Advances in Complex Systems , volume=
-
[7]
American Economic Journal: Microeconomics , volume=
Naive Learning in Social Networks and the Wisdom of Crowds , author=. American Economic Journal: Microeconomics , volume=
-
[8]
Journal of Artificial Societies and Social Simulation , volume=
Continuous Opinion Dynamics under Bounded Confidence: A Survey , author=. Journal of Artificial Societies and Social Simulation , volume=
-
[9]
arXiv preprint arXiv:2512.02682 , year=
Beyond Single-Agent Safety: A Taxonomy of Risks in LLM-to-LLM Interactions , author=. arXiv preprint arXiv:2512.02682 , year=
-
[10]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[11]
Advances in Neural Information Processing Systems , year=
Training Compute-Optimal Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[12]
arXiv preprint arXiv:2505.21503 , year=
Silence is Not Consensus: Disrupting Agreement Bias in Multi-Agent LLMs via Catfish Agent for Clinical Decision Making , author=. arXiv preprint arXiv:2505.21503 , year=
-
[13]
arXiv preprint arXiv:2406.15492 , year=
On the Principles behind Opinion Dynamics in Multi-Agent Systems of Large Language Models , author=. arXiv preprint arXiv:2406.15492 , year=
-
[14]
Journal of Political Economy , volume=
A Theory of Fads, Fashion, Custom, and Cultural Change as Informational Cascades , author=. Journal of Political Economy , volume=
-
[15]
Quarterly Journal of Economics , volume=
A Simple Model of Herd Behavior , author=. Quarterly Journal of Economics , volume=
-
[16]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. arXiv preprint arXiv:2306.05685 , year=
work page internal anchor Pith review arXiv
-
[17]
arXiv preprint arXiv:2403.02101 , year=
Can LLMs Critique and Iterate? Evaluation of LLM-as-a-Judge , author=. arXiv preprint arXiv:2403.02101 , year=
-
[18]
ACM UIST , year=
Generative Agents: Interactive Simulacra of Human Behavior , author=. ACM UIST , year=
-
[19]
arXiv preprint arXiv:2402.01234 , year=
A Survey on Multi-Agent LLM Systems , author=. arXiv preprint arXiv:2402.01234 , year=
-
[20]
Proceedings of the IEEE , volume=
Consensus and Cooperation in Networked Multi-Agent Systems , author=. Proceedings of the IEEE , volume=
-
[21]
Graph Theoretic Methods in Multiagent Networks , author=
-
[22]
Journal of the American Statistical Association , volume=
Reaching a Consensus , author=. Journal of the American Statistical Association , volume=
-
[23]
Distributed Consensus in Multi-vehicle Cooperative Control , author=
-
[24]
A Survey on LLM-as-a-Judge , author=. arXiv preprint arXiv:2411.15594 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Advances in Neural Information Processing Systems , year=
Training Language Models to Follow Instructions with Human Feedback , author=. Advances in Neural Information Processing Systems , year=
-
[26]
Constitutional AI: Harmlessness from AI Feedback
Constitutional AI: Harmlessness from AI Feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Transactions on Machine Learning Research , year=
Emergent Abilities of Large Language Models , author=. Transactions on Machine Learning Research , year=
-
[28]
Proceedings of the 2017 ACM Conference on Economics and Computation , pages=
Fair Public Decision Making , author=. Proceedings of the 2017 ACM Conference on Economics and Computation , pages=. 2017 , organization=
2017
-
[29]
Artificial Intelligence , volume=
Learning Fair Divisions in the Generalized Cake Cutting Model , author=. Artificial Intelligence , volume=. 2024 , note=
2024
-
[30]
Advances in Neural Information Processing Systems , year=
Deep Reinforcement Learning from Human Preferences , author=. Advances in Neural Information Processing Systems , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems , volume=. 2020 , note=
2020
-
[32]
arXiv preprint arXiv:2406.11776 , year=
Improving Multi-Agent Debate with Sparse Communication Topology , author=. arXiv preprint arXiv:2406.11776 , year=
-
[33]
Transactions on Machine Learning Research , year=
Holistic Evaluation of Language Models , author=. Transactions on Machine Learning Research , year=
-
[34]
Transactions on Machine Learning Research , year=
Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models , author=. Transactions on Machine Learning Research , year=
-
[35]
Proceedings of the Conference on Fairness, Accountability, and Transparency , pages=
Model Cards for Model Reporting , author=. Proceedings of the Conference on Fairness, Accountability, and Transparency , pages=. 2019 , organization=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.