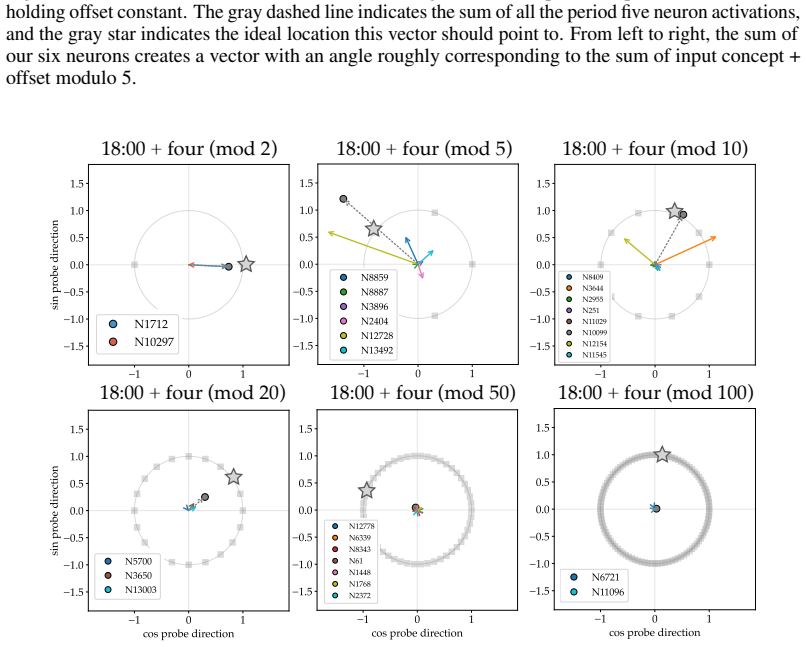
Recognition: unknown
Arithmetic in the Wild: Llama uses Base-10 Addition to Reason About Cyclic Concepts
Pith reviewed 2026-05-09 18:42 UTC · model grok-4.3
The pith
Llama-3.1-8B uses base-10 addition to reason about cyclic concepts like months.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
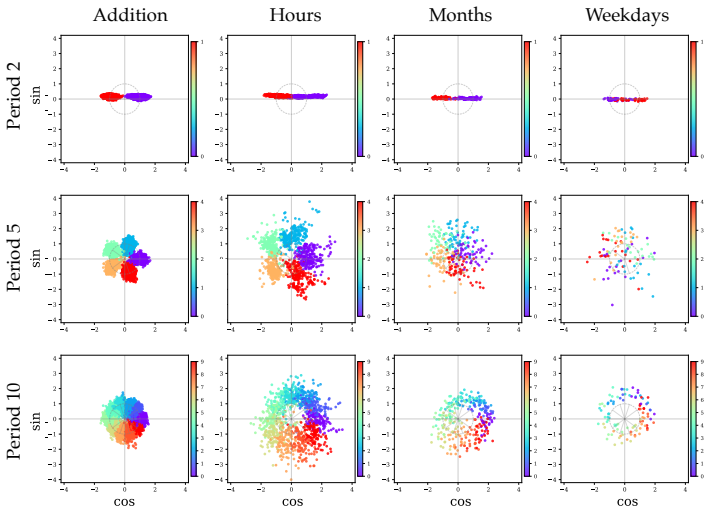
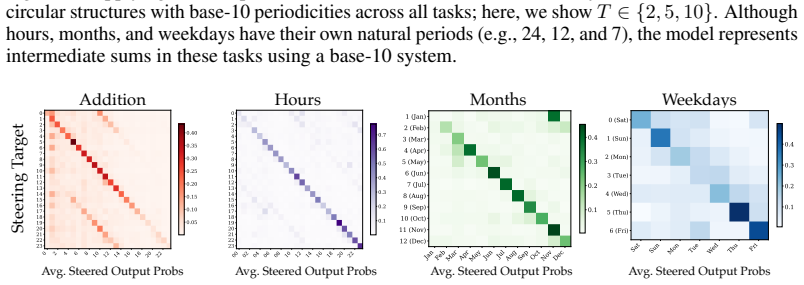
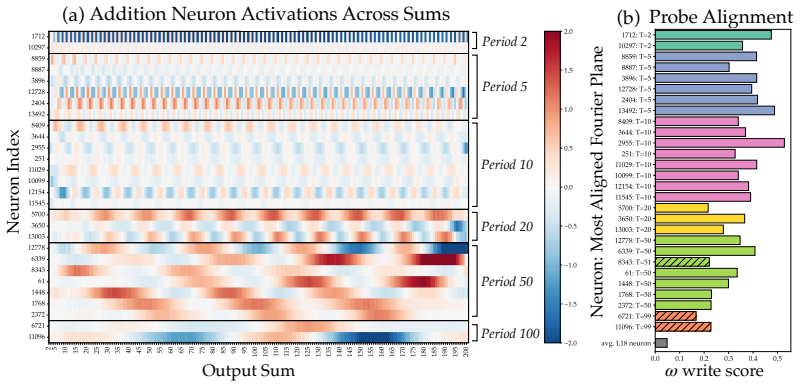
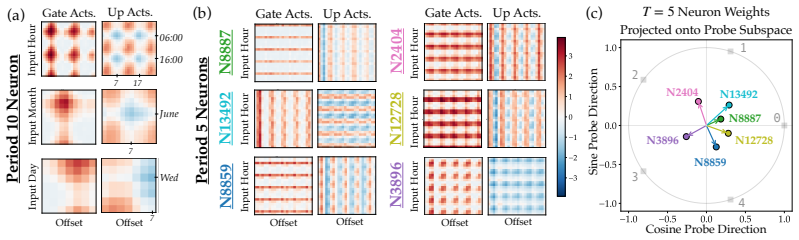
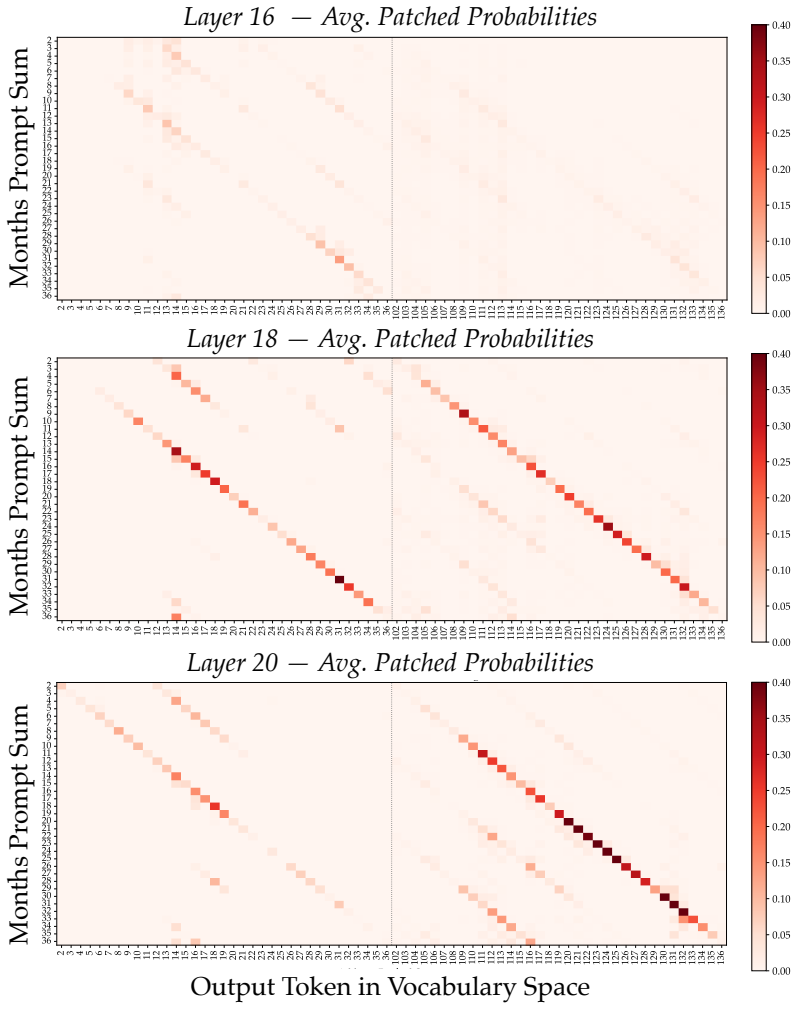
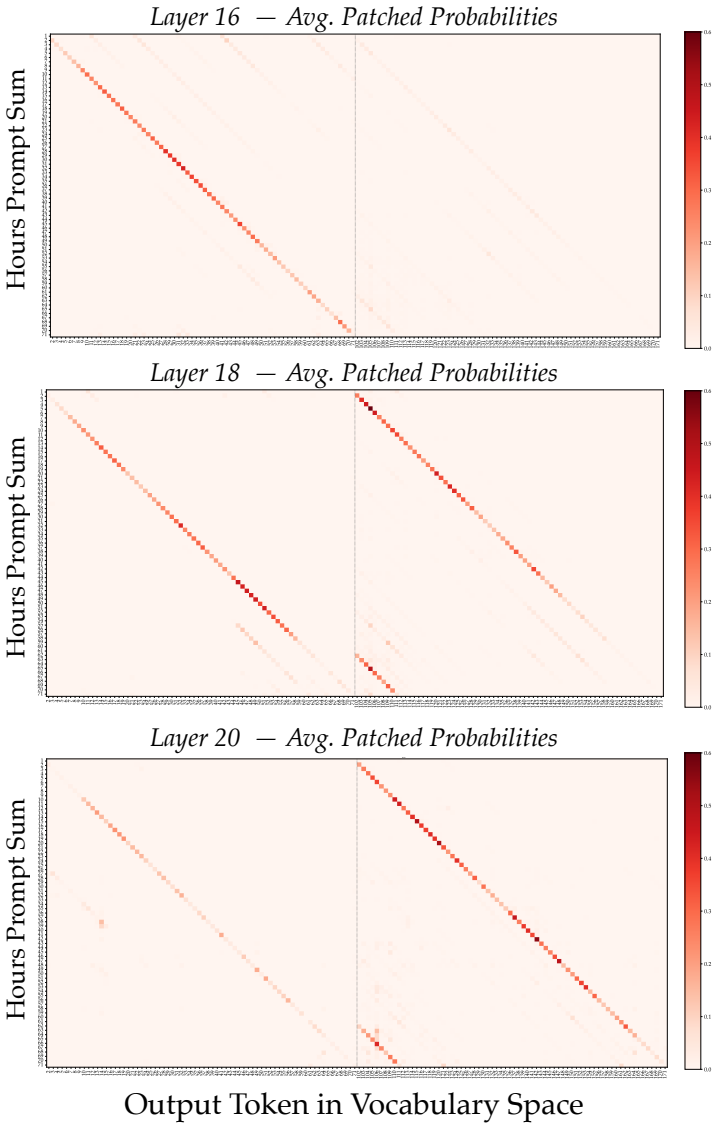
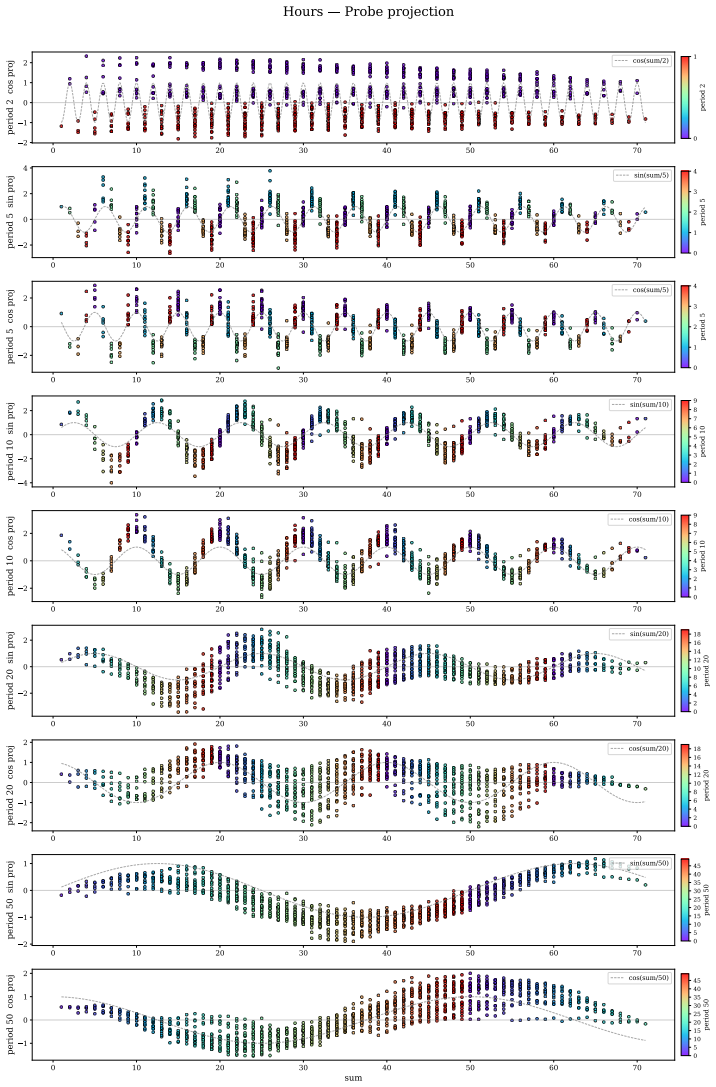
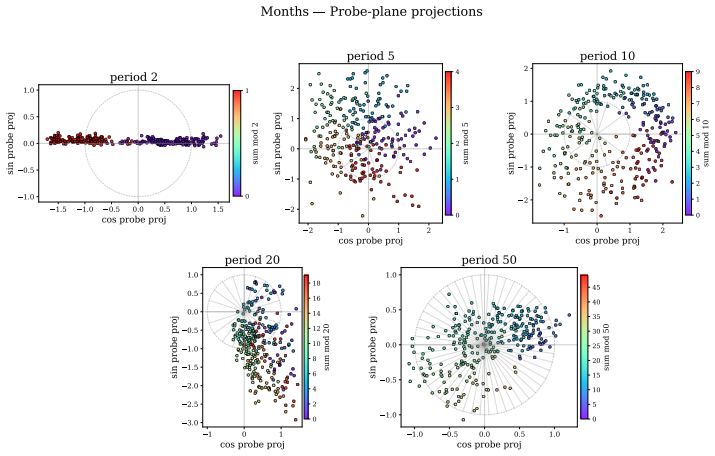
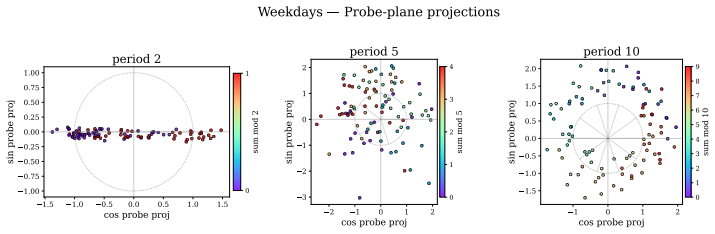
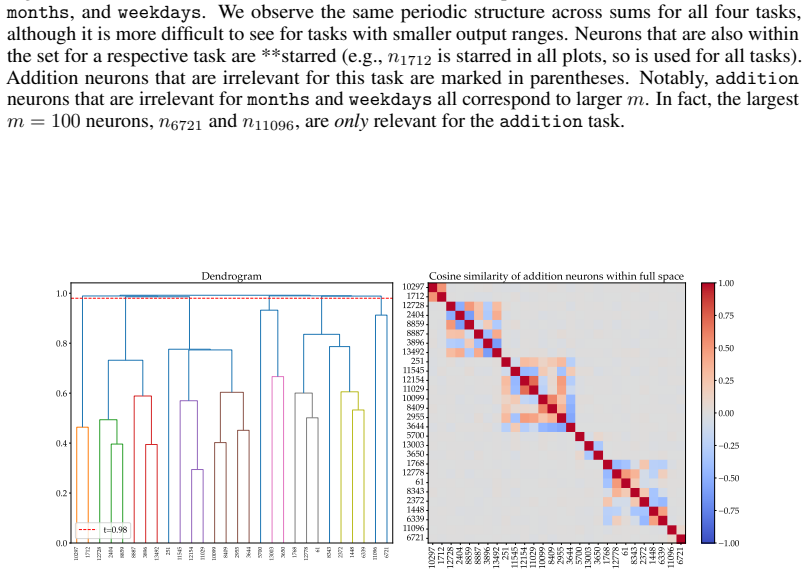
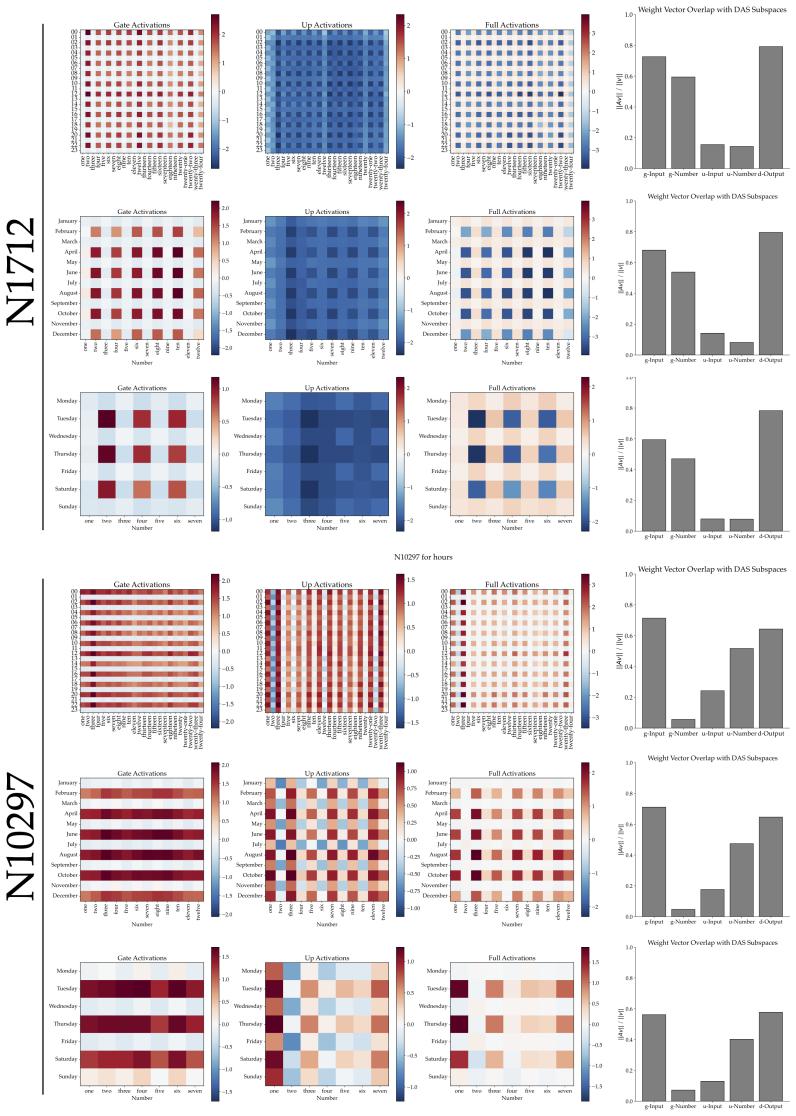
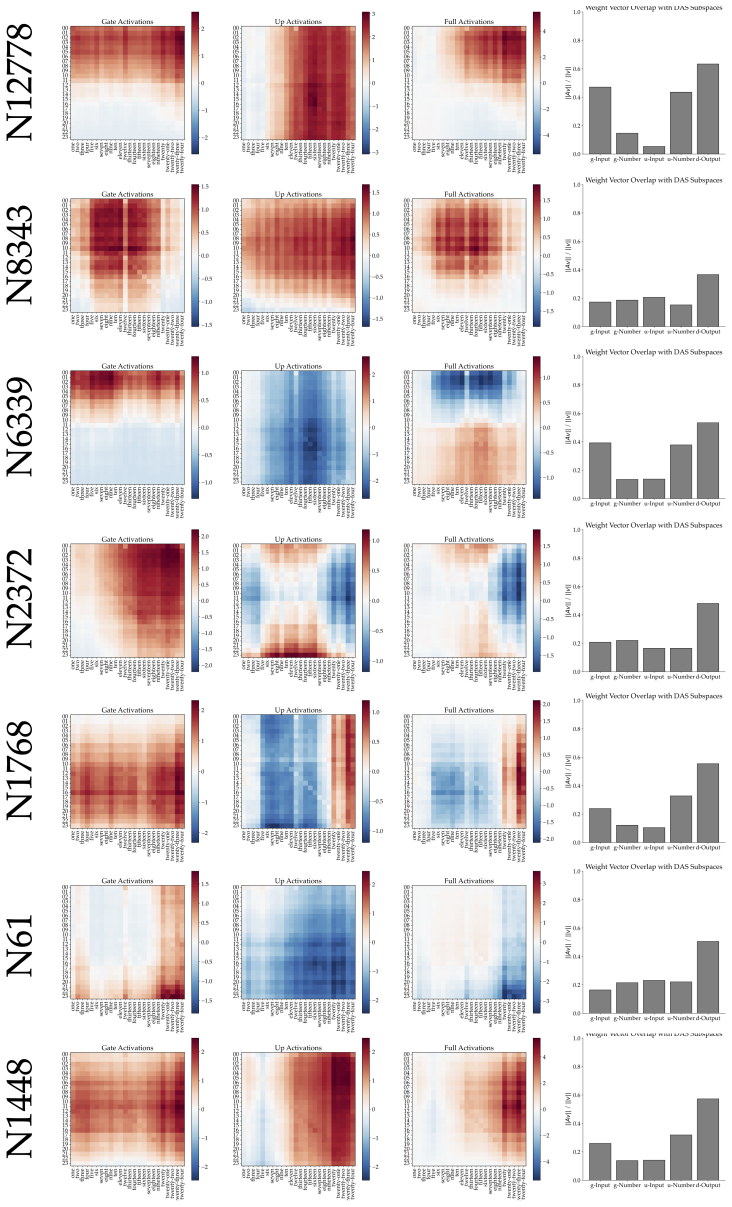
Llama-3.1-8B reasons over cyclic concepts by computing the sum of its two inputs using base-10 addition and then mapping this sum back to cyclic concept space. It achieves the addition using task-agnostic Fourier features that have periods respecting base-10, like 2, 5, and 10, rather than the cyclic period like 12. The model re-uses a generic addition mechanism across tasks that operates independently of concept-specific geometry. A sparse set of 28 MLP neurons, roughly 0.2 percent at layer 18, can be partitioned into disjoint clusters each computing the sum for a Fourier feature with a different period.
What carries the argument
Task-agnostic Fourier features with base-10 periods, implemented by a sparse set of 28 reusable MLP neurons, that perform the addition step before mapping to cyclic space.
Load-bearing premise
The identified sparse set of 28 MLP neurons and the Fourier features are causally responsible for the base-10 addition rather than correlated side effects of the analysis.
What would settle it
Ablating the 28 neurons or disrupting the identified Fourier features would not impair the model's ability to correctly answer cyclic addition questions, or the features would not show periods matching base-10 in causal tests.
Figures








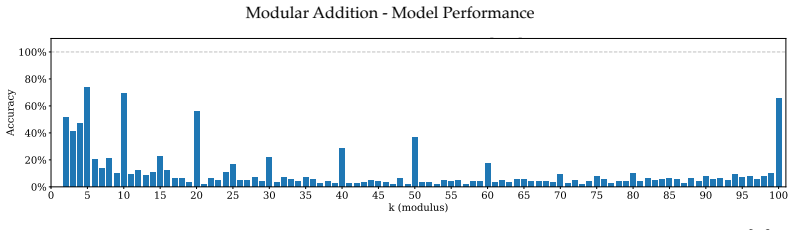
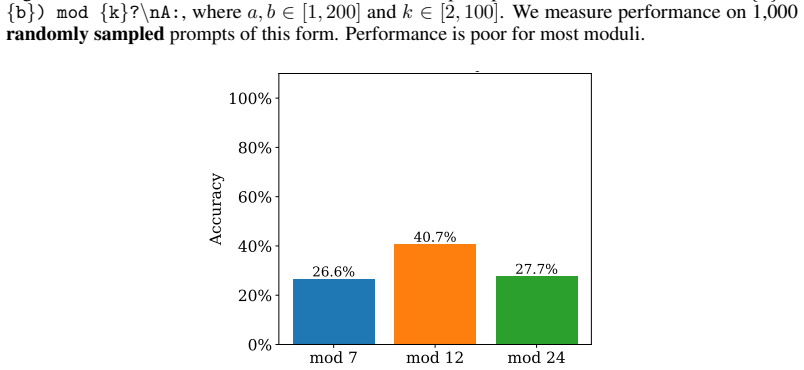



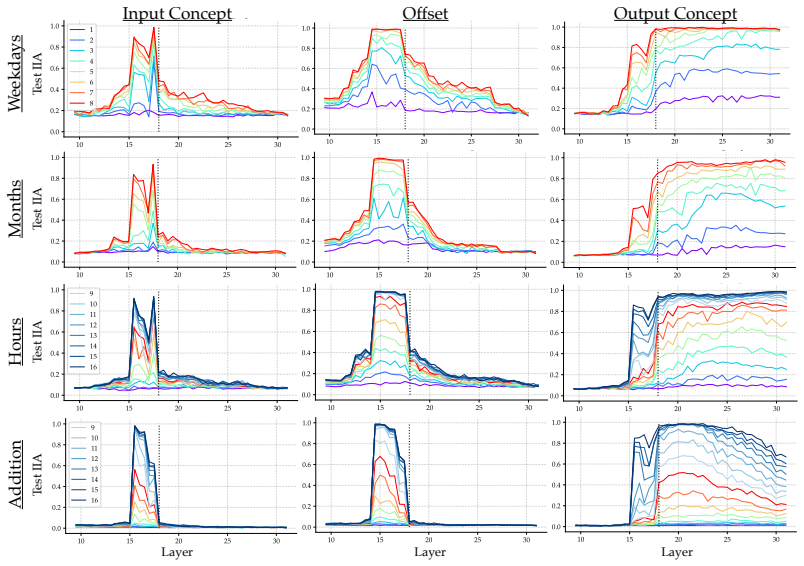
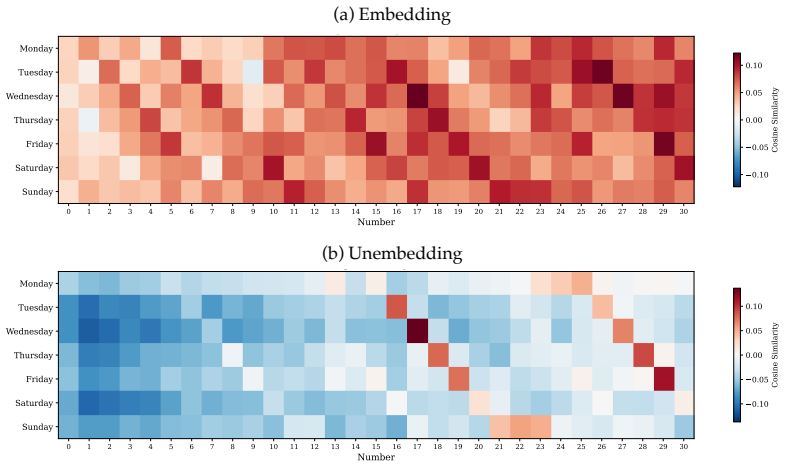




























read the original abstract
Does structure in representations imply structure in computation? We study how Llama-3.1-8B reasons over cyclic concepts (e.g., "what month is six months after August?"). Even though Llama-3.1-8B's representations for these concepts are circularly structured, we find that instead of directly computing modular addition in the period of the cyclic concept (e.g., 12 for months), the model re-uses a generic addition mechanism across tasks that operates independently of concept-specific geometry. First, it computes the sum of its two inputs using base-10 addition (six + August=14). Then, it maps this sum back to cyclic concept space (14->February). We show that Llama-3.1-8B uses task-agnostic Fourier features to compute these sums--in fact, these features have periods that respect standard base-10 addition, e.g., 2, 5, and 10, rather than the cyclic concept period (e.g., 12 for months). Furthermore, we identify a sparse set of 28 MLP neurons re-used across all tasks (approximately 0.2% of the MLP at layer 18) that can be partitioned into disjoint clusters, each computing the sum for a Fourier feature with a different period. Our work highlights how an interplay between causal abstraction and feature geometry can deepen our mechanistic understanding of LMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Llama-3.1-8B reasons over cyclic concepts (e.g., months) by first computing the sum of inputs via a generic base-10 addition mechanism implemented with task-agnostic Fourier features whose periods are 2, 5, and 10 (rather than the cyclic period such as 12), followed by a remapping step back into cyclic space. It further identifies a sparse set of 28 MLP neurons (0.2% of the layer-18 MLP) that are reused across tasks and can be partitioned into disjoint clusters each responsible for one Fourier component of the sum.
Significance. If the causal responsibility of the identified neurons and Fourier features is established, the work would demonstrate reuse of general arithmetic circuits for domain-specific cyclic reasoning in LLMs, providing a concrete case study of how feature geometry (Fourier periods) interacts with computational mechanisms identified via causal abstraction. This advances mechanistic interpretability by showing that representation structure need not dictate the underlying algorithm.
major comments (3)
- [§4.3] §4.3 (Neuron Identification): The 28 MLP neurons are identified via activation clustering and correlation with Fourier components, but the manuscript reports no causal interventions such as selective ablation, activation patching, or counterfactual editing that would show these neurons are necessary and sufficient for the base-10 addition step (e.g., producing base-10 carry errors like 6+8=13 while preserving the subsequent cyclic mapping). Without such tests the features could be downstream correlates of numeric training data rather than the operative circuit.
- [§3.2] §3.2 (Fourier Feature Extraction): The claim that the extracted features have periods strictly respecting base-10 addition (2, 5, 10) rather than cyclic periods is supported only by correlational analysis of representations; no quantitative model comparison (e.g., R² or reconstruction error for base-10 vs. modular-12 bases) or control for embedding geometry confounds is provided to establish that the periods are computed by the model rather than induced by the analysis pipeline.
- [Methods] Methods section: The abstract references experiments using causal abstraction and neuron identification, yet the manuscript lacks full details on sample sizes, statistical thresholds, exact clustering procedure, and controls for multiple comparisons. This prevents evaluation of whether the reported sparsity (28 neurons) and period selectivity are robust or sensitive to analysis choices.
minor comments (2)
- [Figure 4] Figure 4 (neuron clusters): axis labels and color legends are insufficiently described, making it difficult to verify the claimed disjoint partitioning into period-specific clusters.
- [§3.1] The notation for Fourier periods (e.g., “period 2 feature”) is introduced without an explicit equation linking it to the standard Fourier basis used in the analysis.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which identifies key opportunities to strengthen the causal claims and methodological transparency of our work. We address each major comment below and will revise the manuscript accordingly to incorporate additional experiments and details.
read point-by-point responses
-
Referee: [§4.3] §4.3 (Neuron Identification): The 28 MLP neurons are identified via activation clustering and correlation with Fourier components, but the manuscript reports no causal interventions such as selective ablation, activation patching, or counterfactual editing that would show these neurons are necessary and sufficient for the base-10 addition step (e.g., producing base-10 carry errors like 6+8=13 while preserving the subsequent cyclic mapping). Without such tests the features could be downstream correlates of numeric training data rather than the operative circuit.
Authors: We appreciate the referee's observation that our neuron identification in §4.3 relies on activation clustering and correlation with Fourier components. While these methods reveal a sparse, task-agnostic set of neurons reused across cyclic tasks, we agree that explicit causal interventions would provide stronger evidence of necessity and sufficiency for the base-10 addition mechanism. In the revised manuscript, we will add selective ablation results demonstrating that removing these 28 neurons increases base-10 carry errors (e.g., 6+8 producing 13) while leaving the subsequent cyclic remapping intact. We will also include activation patching experiments to establish sufficiency. These will be reported with quantitative metrics in an expanded §4.3. revision: yes
-
Referee: [§3.2] §3.2 (Fourier Feature Extraction): The claim that the extracted features have periods strictly respecting base-10 addition (2, 5, 10) rather than cyclic periods is supported only by correlational analysis of representations; no quantitative model comparison (e.g., R² or reconstruction error for base-10 vs. modular-12 bases) or control for embedding geometry confounds is provided to establish that the periods are computed by the model rather than induced by the analysis pipeline.
Authors: We acknowledge that the evidence for base-10 period selectivity in §3.2 is currently correlational. To address this, the revised version will include quantitative model comparisons, reporting R² values and reconstruction errors when fitting base-10 Fourier bases (periods 2, 5, 10) versus modular bases matched to each cyclic concept period (e.g., 12 for months). We will also add controls for embedding geometry confounds by repeating the Fourier analysis on permuted or randomly projected embeddings. These comparisons will be added to §3.2 to demonstrate that the observed periods reflect the model's internal computation. revision: yes
-
Referee: [Methods] Methods section: The abstract references experiments using causal abstraction and neuron identification, yet the manuscript lacks full details on sample sizes, statistical thresholds, exact clustering procedure, and controls for multiple comparisons. This prevents evaluation of whether the reported sparsity (28 neurons) and period selectivity are robust or sensitive to analysis choices.
Authors: We agree that the Methods section requires greater detail to support evaluation of the reported findings. In the revision, we will expand the Methods to specify all sample sizes used in the experiments, the exact statistical thresholds (including correlation cutoffs and any significance criteria), the precise clustering procedure (algorithm, parameters such as number of clusters, and initialization method), and the approach to multiple-comparison correction. These additions will allow readers to assess the robustness of the 28-neuron sparsity and the selectivity to periods 2, 5, and 10. revision: yes
Circularity Check
No circularity: empirical analysis of representations and interventions
full rationale
The paper's central claims rest on direct empirical inspection of Llama-3.1-8B activations, identification of Fourier features with periods 2/5/10, and clustering of 28 MLP neurons across tasks. These are observational and interventional findings (representation geometry, neuron reuse) rather than any derivation, prediction, or first-principles result that reduces to fitted parameters or self-referential definitions by construction. No equations, ansatzes, or uniqueness theorems are invoked; no self-citations appear as load-bearing premises. The analysis pipeline produces new observations about the model's computation without tautological renaming or statistical forcing of the reported patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2602.03655 , year =
Sequential Group Composition: A Window into the Mechanics of Deep Learning , author=. arXiv preprint arXiv:2602.03655 , year=
-
[2]
arXiv preprint arXiv:2601.05328 , year =
Bi-Orthogonal Factor Decomposition for Vision Transformers , author=. arXiv preprint arXiv:2601.05328 , year=
-
[3]
Advances in Neural Information Processing Systems , volume=
Pareto frontiers in deep feature learning: Data, compute, width, and luck , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
The Thirty Sixth Annual Conference on Learning Theory , pages=
Sgd learning on neural networks: leap complexity and saddle-to-saddle dynamics , author=. The Thirty Sixth Annual Conference on Learning Theory , pages=. 2023 , organization=
2023
-
[5]
arXiv preprint arXiv:2506.06489 , year =
Alternating gradient flows: A theory of feature learning in two-layer neural networks , author=. arXiv preprint arXiv:2506.06489 , year=
-
[6]
What happens during the loss plateau? understanding abrupt learning in transformers
What Happens During the Loss Plateau? Understanding Abrupt Learning in Transformers , author=. arXiv preprint arXiv:2506.13688 , year=
-
[7]
Representation shattering in transformers: A synthetic study with knowledge editing , author=. arXiv preprint arXiv:2410.17194 , year=
-
[8]
arXiv preprint arXiv:2505.18651 , year =
On the emergence of linear analogies in word embeddings , author=. arXiv preprint arXiv:2505.18651 , year=
-
[9]
Goodfire , year =
Pearce, Michael and Simon, Elana and Byun, Michael and Balsam, Daniel , title =. Goodfire , year =
-
[10]
Transformer Circuits Thread , year=
Gurnee, Wes and Ameisen, Emmanuel and Kauvar, Isaac and Tarng ,Julius and Pearce, Adam and Olah, Chris and Batson, Joshua , title=. Transformer Circuits Thread , year=
-
[11]
NeurIPS Workshop on Symmetry and Geometry in Neural Representations (NeurReps) , year =
Neural Manifold Geometry Encodes Feature Fields , author =. NeurIPS Workshop on Symmetry and Geometry in Neural Representations (NeurReps) , year =
-
[12]
arXiv preprint arXiv:2603.16689 , year =
Grid-World Representations in Transformers Reflect Predictive Geometry , author=. arXiv preprint arXiv:2603.16689 , year=
-
[13]
Uncovering hidden geometry in transformers via disentangling position and context , author=. arXiv preprint arXiv:2310.04861 , year=
-
[14]
NeurIPS 2024 Workshop on Symmetry and Geometry in Neural Representations , year=
Constrained Belief Updating and Geometric Structures in Transformer Representations , author=. NeurIPS 2024 Workshop on Symmetry and Geometry in Neural Representations , year=
2024
-
[15]
Advances in Neural Information Processing Systems , volume=
Transformers represent belief state geometry in their residual stream , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Advances in Neural Information Processing Systems , volume=
Abrupt learning in transformers: A case study on matrix completion , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
2023 , eprint=
Kernelized Concept Erasure , author=. 2023 , eprint=
2023
-
[18]
2022 , eprint=
Linear Adversarial Concept Erasure , author=. 2022 , eprint=
2022
-
[20]
Nora Belrose and David Schneider. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , year =
2023
-
[21]
Shauli Ravfogel and Yoav Goldberg and Ryan Cotterell , editor =. Log-Linear Guardedness and its Implications , booktitle =. 2023 , url =. doi:10.18653/V1/2023.ACL-LONG.523 , timestamp =
-
[22]
2017 , eprint=
Understanding Neural Networks through Representation Erasure , author=. 2017 , eprint=
2017
-
[23]
Distill , year =
Cammarata, Nick and Carter, Shan and Goh, Gabriel and Olah, Chris and Petrov, Michael and Schubert, Ludwig and Voss, Chelsea and Egan, Ben and Lim, Swee Kiat , title =. Distill , year =
-
[24]
2023 , eprint=
Dissecting Recall of Factual Associations in Auto-Regressive Language Models , author=. 2023 , eprint=
2023
-
[25]
Advances in neural information processing systems , volume=
Universality and individuality in neural dynamics across large populations of recurrent networks , author=. Advances in neural information processing systems , volume=
-
[26]
Proceedings of the National Academy of Sciences , volume=
Neural representational geometry underlies few-shot concept learning , author=. Proceedings of the National Academy of Sciences , volume=. 2022 , publisher=
2022
-
[27]
Proceedings of the National Academy of Sciences , volume=
A mathematical theory of semantic development in deep neural networks , author=. Proceedings of the National Academy of Sciences , volume=. 2019 , publisher=
2019
-
[28]
Computational Linguistics , volume=
Probing classifiers: Promises, shortcomings, and advances , author=. Computational Linguistics , volume=
-
[29]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[30]
Alessandro Stolfo and Yonatan Belinkov and Mrinmaya Sachan , editor =. A Mechanistic Interpretation of Arithmetic Reasoning in Language Models using Causal Mediation Analysis , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.435 , timestamp =
-
[31]
ArXiv , year=
Finding Alignments Between Interpretable Causal Variables and Distributed Neural Representations , author=. ArXiv , year=
-
[32]
Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
Vig, Jesse and Gehrmann, Sebastian and Belinkov, Yonatan and Qian, Sharon and Nevo, Daniel and Singer, Yaron and Shieber, Stuart , booktitle =. Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
-
[33]
Computational Linguistics , pages =
Mueller, Aaron and Brinkmann, Jannik and Li, Millicent and Marks, Samuel and Pal, Koyena and Prakash, Nikhil and Rager, Can and Sankaranarayanan, Aruna and Sharma, Arnab Sen and Sun, Jiuding and Todd, Eric and Bau, David and Belinkov, Yonatan , title =. Computational Linguistics , pages =. 2026 , month =. doi:10.1162/COLI.a.572 , url =
-
[34]
Journal of Machine Learning Research , year =
Atticus Geiger and Duligur Ibeling and Amir Zur and Maheep Chaudhary and Sonakshi Chauhan and Jing Huang and Aryaman Arora and Zhengxuan Wu and Noah Goodman and Christopher Potts and Thomas Icard , title =. Journal of Machine Learning Research , year =
-
[35]
2026 , eprint=
The Shape of Beliefs: Geometry, Dynamics, and Interventions along Representation Manifolds of Language Models' Posteriors , author=. 2026 , eprint=
2026
-
[36]
2025 , eprint=
Not All Language Model Features Are One-Dimensionally Linear , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
The Origins of Representation Manifolds in Large Language Models , author=. 2025 , eprint=
2025
-
[38]
2024 , eprint=
Pre-trained Large Language Models Use Fourier Features to Compute Addition , author=. 2024 , eprint=
2024
-
[39]
2025 , eprint=
Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics , author=. 2025 , eprint=
2025
-
[40]
2025 , eprint=
Language Models Use Trigonometry to Do Addition , author=. 2025 , eprint=
2025
-
[41]
2023 , eprint=
Progress measures for grokking via mechanistic interpretability , author=. 2023 , eprint=
2023
-
[42]
2023 , eprint=
The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks , author=. 2023 , eprint=
2023
-
[43]
Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =
Geiger, Atticus and Lu, Hanson and Icard, Thomas and Potts, Christopher , title =. Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =. 2021 , isbn =
2021
-
[44]
2025 , booktitle =
AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders , author =. 2025 , booktitle =
2025
-
[45]
2025 , journal =
Causal Abstraction: A Theoretical Foundation for Mechanistic Interpretability , author =. 2025 , journal =
2025
-
[46]
2025 , booktitle =
Combining Causal Models for More Accurate Abstractions of Neural Networks , author =. 2025 , booktitle =
2025
-
[47]
The Fourteenth International Conference on Learning Representations , year=
Correlations in the Data Lead to Semantically Rich Feature Geometry Under Superposition , author=. The Fourteenth International Conference on Learning Representations , year=
-
[48]
2025 , booktitle =
Decomposing MLP Activations into Interpretable Features via Semi-Nonnegative Matrix Factorization , author =. 2025 , booktitle =
2025
-
[49]
2025 , booktitle =
Enhancing Automated Interpretability with Output-Centric Feature Descriptions , author =. 2025 , booktitle =
2025
-
[50]
2025 , booktitle =
How Causal Abstraction Underpins Computational Explanation , author =. 2025 , booktitle =
2025
-
[51]
2025 , booktitle =
How Do Transformers Learn Variable Binding in Symbolic Programs? , author =. 2025 , booktitle =
2025
-
[52]
2025 , booktitle =
HyperDAS: Towards Automating Mechanistic Interpretability with Hypernetworks , author =. 2025 , booktitle =
2025
-
[53]
2025 , booktitle =
HyperSteer: Activation Steering at Scale with Hypernetworks , author =. 2025 , booktitle =
2025
-
[54]
2025 , booktitle =
MIB: A Mechanistic Interpretability Benchmark , author =. 2025 , booktitle =
2025
-
[55]
Xiaoyan Bai and Itamar Pres and Yuntian Deng and Chenhao Tan and Stuart M. Shieber and Fernanda B. Vi. Why Can't Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls , journal =. 2025 , url =. doi:10.48550/ARXIV.2510.00184 , eprinttype =. 2510.00184 , timestamp =
-
[56]
2025 , booktitle =
Mixing Mechanisms: How Language Models Retrieve Bound Entities In-Context , author =. 2025 , booktitle =
2025
-
[57]
2025 , journal =
Open Problems in Mechanistic Interpretability , author =. 2025 , journal =
2025
-
[58]
(2023)'s Interpretability Illusions Arguments , author =
A Reply to Makelov et al. (2023)'s Interpretability Illusions Arguments , author =. 2024 , booktitle =
2023
-
[59]
2024 , booktitle =
Evaluating Open-Source Sparse Autoencoders on Disentangling Factual Knowledge in GPT-2 Small , author =. 2024 , booktitle =
2024
-
[60]
2024 , booktitle =
Finding Alignments Between Interpretable Causal Variables and Distributed Neural Representations , author =. 2024 , booktitle =
2024
-
[61]
2024 , booktitle =
Is This the Subspace You Are Looking for? An Interpretability Illusion for Subspace Activation Patching , author =. 2024 , booktitle =
2024
-
[62]
2024 , booktitle =
Language Models Linearly Represent Sentiment , author =. 2024 , booktitle =
2024
-
[63]
2024 , booktitle =
pyvene: A Library for Understanding and Improving PyTorch Models via Interventions , author =. 2024 , booktitle =
2024
-
[64]
2024 , booktitle =
RAVEL: Evaluating Interpretability Methods on Disentangling Language Model Representations , author =. 2024 , booktitle =
2024
-
[65]
2024 , booktitle =
Recurrent Neural Networks Learn to Store and Generate Sequences using Non-Linear Representations , author =. 2024 , booktitle =
2024
-
[66]
2024 , booktitle =
ReFT: Representation Finetuning for Language Models , author =. 2024 , booktitle =
2024
-
[67]
2024 , booktitle =
Updating CLIP to Prefer Descriptions Over Captions , author =. 2024 , booktitle =
2024
-
[68]
2023 , booktitle =
A Semantics for Causing, Enabling, and Preventing Verbs Using Structural Causal Models , author =. 2023 , booktitle =
2023
-
[69]
2023 , booktitle =
Causal Abstraction with Soft Interventions , author =. 2023 , booktitle =
2023
-
[70]
Language Models Encode Numbers Using Digit Representations in Base 10 , booktitle =
Amit Arnold Levy and Mor Geva , editor =. Language Models Encode Numbers Using Digit Representations in Base 10 , booktitle =. 2025 , url =. doi:10.18653/V1/2025.NAACL-SHORT.33 , timestamp =
-
[71]
2025 , eprint=
Priors in Time: Missing Inductive Biases for Language Model Interpretability , author=. 2025 , eprint=
2025
-
[72]
2025 , eprint=
From Flat to Hierarchical: Extracting Sparse Representations with Matching Pursuit , author=. 2025 , eprint=
2025
-
[73]
2025 , eprint=
MIB: A Mechanistic Interpretability Benchmark , author=. 2025 , eprint=
2025
-
[74]
The Fourteenth International Conference on Learning Representations (ICLR 2026) , year =
LLMs Process Lists With General Filter Heads , author=. The Fourteenth International Conference on Learning Representations (ICLR 2026) , year=. 2510.26784 , archivePrefix=
-
[75]
2026 , eprint=
From Directions to Regions: Decomposing Activations in Language Models via Local Geometry , author=. 2026 , eprint=
2026
-
[76]
FoNE: Precise Single-Token Number Embeddings via Fourier Features
FoNE: Precise Single-Token Number Embeddings via Fourier Features , author=. arXiv preprint arXiv:2502.09741 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
Saxe , editor =
Lukas Braun and Erin Grant and Andrew M. Saxe , editor =. Not all solutions are created equal: An analytical dissociation of functional and representational similarity in deep linear neural networks , booktitle =. 2025 , url =
2025
-
[78]
Second Mechanistic Interpretability Workshop at NeurIPS , year=
Vector Arithmetic in Concept and Token Subspaces , author=. Second Mechanistic Interpretability Workshop at NeurIPS , year=
-
[79]
Feature Learning beyond the Lazy-Rich Dichotomy: Insights from Representational Geometry , booktitle =
Chi. Feature Learning beyond the Lazy-Rich Dichotomy: Insights from Representational Geometry , booktitle =. 2025 , url =
2025
-
[80]
Hyunmo Kang and Abdulkadir Canatar and SueYeon Chung , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.19648 , eprinttype =. 2502.19648 , timestamp =
-
[81]
2025 , eprint=
Language Models use Lookbacks to Track Beliefs , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.