Recognition: unknown
VLA-ATTC: Adaptive Test-Time Compute for VLA Models with Relative Action Critic Model
Pith reviewed 2026-05-09 15:06 UTC · model grok-4.3
The pith
Vision-language-action models can switch into deliberate test-time computation when uncertain, using pairwise action comparisons to reduce failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
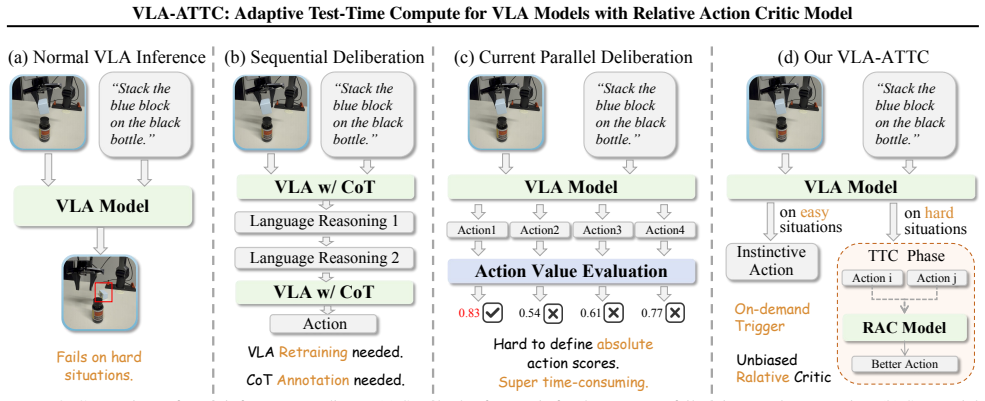
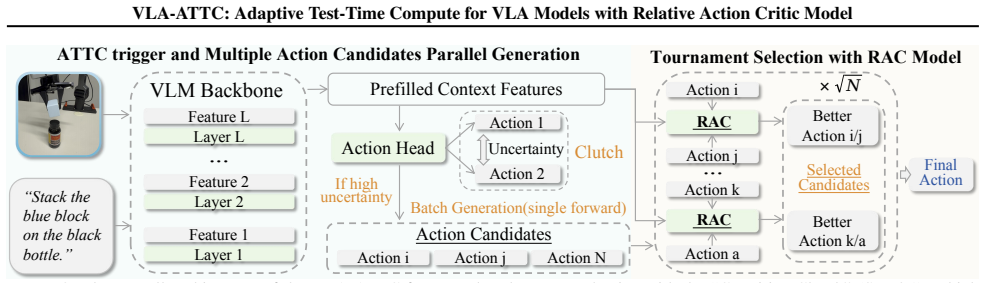
VLA-ATTC adds adaptive test-time compute to VLA models via an uncertainty-based cognitive clutch that shifts from reflexive action to a deliberation phase, where the Relative Action Critic selects the best action from candidates through pairwise comparisons, replacing unstable absolute scoring, supported by efficient sampling and an automated preference data pipeline, yielding over 50% failure rate reduction for the PI0.5 model on the LIBERO-LONG benchmark.
What carries the argument
The Relative Action Critic model, which identifies the optimal action among generated candidates by performing pairwise comparisons instead of direct value estimation.
If this is right
- VLA models achieve substantially lower failure rates on long-horizon manipulation benchmarks.
- The critic training objective becomes simpler and more stable than absolute value methods.
- An automated pipeline can generate preference pairs for training without manual labeling.
- Efficient sampling amortizes the added compute cost during the deliberation phase.
- Existing state-of-the-art VLA models can be enhanced by this plug-in adaptive mechanism.
Where Pith is reading between the lines
- The pairwise comparison idea could transfer to other generative decision systems that currently rely on scalar rewards.
- Real-world robot deployments might see fewer catastrophic errors in ambiguous scenes if uncertainty triggers are tuned appropriately.
- Scaling the approach to longer horizons or multi-agent settings would test whether the clutch and critic remain effective.
- Combining this with other test-time methods like search or planning could compound reliability gains.
Load-bearing premise
Uncertainty estimates can reliably detect when extra deliberation is required and pairwise comparisons can stably identify superior actions without training collapse.
What would settle it
Running the full VLA-ATTC pipeline on the LIBERO-LONG benchmark and measuring whether the failure rate for PI0.5 drops by more than half; if the reduction is substantially smaller or the critic exhibits unstable training, the central claim would not hold.
Figures




read the original abstract
Vision-Language-Action (VLA) models have demonstrated remarkable capabilities and generalization in embodied manipulation. However, their decision-making relies on a fast, instinctive process that lacks deliberation. This strategy often leads to suboptimal or catastrophic actions when facing complex or ambiguous scenarios that require greater consideration. In this paper, we introduce \textbf{VLA-ATTC}, a framework that endows VLA models with adaptive test-time compute (TTC). VLA-ATTC employs an uncertainty-based ``cognitive clutch'' to dynamically transition from reflexive execution to a TTC deliberation phase when necessary. During TTC phase, a novel \textbf{Relative Action Critic} (RAC) model identifies the optimal action from generated candidates via pairwise comparisons. This relative mechanism replaces unstable absolute value estimation, significantly simplifying the learning objective. Furthermore, we introduce an efficient sampling strategy to amortize computational costs and an automated data pipeline that curates preference pairs without manual annotation. On the LIBERO-LONG benchmark, VLA-ATTC reduces the failure rate of the SOTA model PI0.5 by over 50\%. We will open-source all the code and weights.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VLA-ATTC, a framework for endowing Vision-Language-Action (VLA) models with adaptive test-time compute. It uses an uncertainty-based 'cognitive clutch' to dynamically switch from reflexive action execution to a deliberation phase when facing complex or ambiguous states. In the deliberation phase, a novel Relative Action Critic (RAC) model selects the optimal action from candidate actions via pairwise comparisons, replacing absolute value estimation. The approach includes an efficient sampling strategy to amortize costs and an automated pipeline for generating preference pairs without manual annotation. The central empirical claim is that VLA-ATTC reduces the failure rate of the SOTA PI0.5 model by over 50% on the LIBERO-LONG benchmark.
Significance. If the reported results hold under rigorous validation, the work could meaningfully advance reliable deployment of VLA models in embodied manipulation by enabling selective deliberation without constant high compute overhead. The relative pairwise formulation of the critic simplifies the learning objective relative to absolute critics and the automated preference data pipeline removes a common annotation bottleneck. The commitment to open-sourcing code and weights would support reproducibility and follow-on work.
major comments (3)
- [Abstract] Abstract: The headline claim of >50% failure-rate reduction on LIBERO-LONG is load-bearing for the paper's contribution, yet the abstract (and by extension the presented description) provides no quantitative validation that the uncertainty-based clutch reliably identifies only the states where extra compute improves outcomes (e.g., no precision/recall or failure-case analysis of clutch triggers).
- [Abstract] Abstract: The RAC is asserted to 'significantly simplify the learning objective' and avoid instability of absolute critics, but no analysis, ablation, or metric (such as transitivity error rate or ranking consistency across pairwise comparisons) is supplied to confirm that the pairwise preference model converges to stable, transitive orderings on the generated candidates.
- [Abstract] Abstract: The automated data pipeline for curating preference pairs is presented as a key enabler, yet no details are given on how negative or ambiguous pairs are filtered, how label noise is controlled, or whether the resulting training distribution matches the distribution of states encountered at test time under the clutch.
minor comments (2)
- [Abstract] Abstract: The phrase 'cognitive clutch' is evocative but should be accompanied by a concise technical definition of the uncertainty signal (e.g., entropy, variance, or model disagreement) in the main text.
- [Abstract] Abstract: Reporting only the aggregate failure-rate reduction leaves open whether gains are uniform across task categories or driven by a few long-horizon episodes; per-task breakdowns or confidence intervals would strengthen the result.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of >50% failure-rate reduction on LIBERO-LONG is load-bearing for the paper's contribution, yet the abstract (and by extension the presented description) provides no quantitative validation that the uncertainty-based clutch reliably identifies only the states where extra compute improves outcomes (e.g., no precision/recall or failure-case analysis of clutch triggers).
Authors: We agree that the abstract would benefit from additional context on the clutch. The full manuscript (Section 4.2) includes quantitative analysis and failure-case studies showing that the uncertainty clutch triggers deliberation primarily on states where the base VLA model fails, directly contributing to the reported performance gains. We will revise the abstract to include a brief statement summarizing the clutch's empirical reliability and its selective activation. revision: yes
-
Referee: [Abstract] Abstract: The RAC is asserted to 'significantly simplify the learning objective' and avoid instability of absolute critics, but no analysis, ablation, or metric (such as transitivity error rate or ranking consistency across pairwise comparisons) is supplied to confirm that the pairwise preference model converges to stable, transitive orderings on the generated candidates.
Authors: The manuscript motivates the relative formulation as a simplification that avoids the calibration challenges of absolute critics. We acknowledge that explicit supporting metrics would strengthen this claim. We will add an ablation study and analysis of transitivity error and ranking consistency to the revised manuscript to empirically validate the stability of the RAC model on generated candidates. revision: yes
-
Referee: [Abstract] Abstract: The automated data pipeline for curating preference pairs is presented as a key enabler, yet no details are given on how negative or ambiguous pairs are filtered, how label noise is controlled, or whether the resulting training distribution matches the distribution of states encountered at test time under the clutch.
Authors: The automated pipeline is detailed in Section 3.4 of the manuscript, where pairs are derived from base-model rollouts. To directly address the concern, we will expand both the relevant section and the abstract to specify the filtering criteria for negative/ambiguous pairs, noise-control measures, and evidence of distribution alignment between training pairs and clutch-triggered test-time states. revision: yes
Circularity Check
No circularity: new algorithmic components with empirical validation
full rationale
The paper introduces an uncertainty-based cognitive clutch and a Relative Action Critic (RAC) that uses pairwise comparisons instead of absolute value estimation. These are presented as novel engineering choices with an automated data pipeline for preference pairs. No equations, derivations, or central claims reduce by construction to the inputs (e.g., no fitted parameter renamed as a prediction, no self-citation chain invoked as a uniqueness theorem, no ansatz smuggled via prior work). Performance gains on LIBERO-LONG are reported as empirical results, not tautological consequences of the method definition. The derivation chain is self-contained and externally falsifiable via benchmark evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLA models can benefit from additional compute in uncertain scenarios
invented entities (1)
-
Relative Action Critic model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al. pi0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review arXiv
-
[2]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Galliker, M. Y ., et al. pi0.5: a vision-language-action model with open- world generalization.arXiv preprint arXiv:2504.16054,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
Chen, Q., Qin, L., Liu, J., Peng, D., Guan, J., Wang, P., Hu, M., Zhou, Y ., Gao, T., and Che, W. Towards reasoning era: A survey of long chain-of-thought for reasoning large language models.arXiv preprint arXiv:2503.09567,
work page internal anchor Pith review arXiv
-
[4]
Multi-agent embodied ai: Advances and future directions.arXiv preprint arXiv:2505.05108,
Feng, Z., Xue, R., Yuan, L., Yu, Y ., Ding, N., Liu, M., Gao, B., Sun, J., Zheng, X., and Wang, G. Multi-agent embodied ai: Advances and future directions.arXiv preprint arXiv:2505.05108,
-
[5]
arXiv preprint arXiv:2506.22355 (2025) 5
Fung, P., Bachrach, Y ., Celikyilmaz, A., Chaudhuri, K., Chen, D., Chung, W., Dupoux, E., Gong, H., J´egou, H., Lazaric, A., et al. Embodied ai agents: Modeling the world.arXiv preprint arXiv:2506.22355,
-
[6]
Guo, W., Lu, G., Deng, H., Wu, Z., Tang, Y ., and Wang, Z. Vla-reasoner: Empowering vision-language-action models with reasoning via online monte carlo tree search. arXiv preprint arXiv:2509.22643,
-
[7]
Efficient test-time scaling via self-calibration
Huang, C., Huang, L., Leng, J., Liu, J., and Huang, J. Effi- cient test-time scaling via self-calibration.arXiv preprint arXiv:2503.00031,
-
[8]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M. J., Pertsch, K., Karamcheti, S., Xiao, T., Balakr- ishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., San- keti, P., et al. Openvla: An open-source vision-language- action model.arXiv preprint arXiv:2406.09246,
work page internal anchor Pith review arXiv
-
[9]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Kim, M. J., Finn, C., and Liang, P. Fine-tuning vision- language-action models: Optimizing speed and success. arXiv preprint arXiv:2502.19645,
work page internal anchor Pith review arXiv
-
[10]
Kwok, J., Agia, C., Sinha, R., Foutter, M., Li, S., Stoica, I., Mirhoseini, A., and Pavone, M. Robomonkey: Scaling test-time sampling and verification for vision-language- action models.arXiv preprint arXiv:2506.17811,
-
[11]
Li, D., Cao, S., Cao, C., Li, X., Tan, S., Keutzer, K., Xing, J., Gonzalez, J. E., and Stoica, I. S*: Test time scaling for code generation.arXiv preprint arXiv:2502.14382,
-
[12]
Li, Q., Liang, Y ., Wang, Z., Luo, L., Chen, X., Liao, M., Wei, F., Deng, Y ., Xu, S., Zhang, Y ., et al. Cogact: A foundational vision-language-action model for synergiz- ing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650,
-
[13]
Onetwovla: A unified vision-language-action model with adaptive reasoning
Lin, F., Nai, R., Hu, Y ., You, J., Zhao, J., and Gao, Y . Onetwovla: A unified vision-language-action model with adaptive reasoning.arXiv preprint arXiv:2505.11917,
-
[14]
Muennighoff, N., Yang, Z., Shi, W., Li, X. L., Fei-Fei, L., Hajishirzi, H., Zettlemoyer, L., Liang, P., Cand `es, E., and Hashimoto, T. s1: Simple test-time scaling.arXiv preprint arXiv:2501.19393,
-
[15]
Nakamoto, M., Mees, O., Kumar, A., and Levine, S. Steer- ing your generalists: Improving robotic foundation mod- els via value guidance.arXiv preprint arXiv:2410.13816,
-
[16]
Nguyen, H. T., Nguyen, B., and Nguyen, V . A. Struc- tured pruning for diverse best-of-n reasoning optimiza- tion.arXiv preprint arXiv:2506.03978,
-
[17]
Y ., Xu, J., Fazel-Zarandi, M., Bansal, M., Sukhbaatar, S., Weston, J., and Yu, J
Prasad, A., Yuan, W., Pang, R. Y ., Xu, J., Fazel-Zarandi, M., Bansal, M., Sukhbaatar, S., Weston, J., and Yu, J. Self-consistency preference optimization.arXiv preprint arXiv:2411.04109,
-
[18]
Sessa, P. G., Dadashi, R., Hussenot, L., Ferret, J., Vieil- lard, N., Ram ´e, A., Shariari, B., Perrin, S., Friesen, A., Cideron, G., et al. Bond: Aligning llms with best-of-n distillation.arXiv preprint arXiv:2407.14622,
-
[19]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Shukor, M., Aubakirova, D., Capuano, F., Kooijmans, P., Palma, S., Zouitine, A., Aractingi, M., Pascal, C., Russi, M., Marafioti, A., et al. Smolvla: A vision-language- action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844,
work page internal anchor Pith review arXiv
-
[20]
Song, H., Qu, D., Yao, Y ., Chen, Q., Lv, Q., Tang, Y ., Shi, M., Ren, G., Yao, M., Zhao, B., et al. Hume: Introducing system-2 thinking in visual-language-action model.arXiv preprint arXiv:2505.21432,
-
[21]
Octo: An Open-Source Generalist Robot Policy
Team, O. M., Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Kreiman, T., Xu, C., et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213,
work page internal anchor Pith review arXiv
-
[22]
Genselect: A generative approach to best-of-n
Toshniwal, S., Sorokin, I., Ficek, A., Moshkov, I., and Gitman, I. Genselect: A generative approach to best-of-n. arXiv preprint arXiv:2507.17797,
-
[23]
M., Oesterling, A., Lakkaraju, H., and Calmon, F
Verdun, C. M., Oesterling, A., Lakkaraju, H., and Calmon, F. P. Soft best-of-n sampling for model alignment.arXiv preprint arXiv:2505.03156,
-
[24]
Soft self-consistency improves language model agents
Wang, H., Prasad, A., Stengel-Eskin, E., and Bansal, M. Soft self-consistency improves language model agents. arXiv preprint arXiv:2402.13212, 2024a. Wang, X. and Zhou, D. Chain-of-thought reasoning without prompting.Advances in Neural Information Processing Systems, 37:66383–66409,
-
[25]
Make every penny count: Difficulty-adaptive self-consistency for cost-efficient reasoning
Wang, X., Feng, S., Li, Y ., Yuan, P., Zhang, Y ., Tan, C., Pan, B., Hu, Y ., and Li, K. Make every penny count: Difficulty-adaptive self-consistency for cost-efficient rea- soning.arXiv preprint arXiv:2408.13457, 2024b. Wang, X., Feng, S., Li, Y ., Yuan, P., Zhang, Y ., Tan, C., Pan, B., Hu, Y ., and Li, K. Make every penny count: Difficulty-adaptive sel...
-
[26]
Xu, S., Wang, Y ., Xia, C., Zhu, D., Huang, T., and Xu, C. Vla-cache: Towards efficient vision-language-action model via adaptive token caching in robotic manipulation. arXiv preprint arXiv:2502.02175,
-
[27]
Demystifying long chain-of-thought reasoning in llms, 2025
Yeo, E., Tong, Y ., Niu, M., Neubig, G., and Yue, X. Demys- tifying long chain-of-thought reasoning in llms.arXiv preprint arXiv:2502.03373,
-
[28]
Robotic Control via Embodied Chain-of-Thought Reasoning
Zawalski, M., Chen, W., Pertsch, K., Mees, O., Finn, C., and Levine, S. Robotic control via embodied chain-of-thought reasoning.arXiv preprint arXiv:2407.08693,
work page internal anchor Pith review arXiv
-
[29]
Zeng, Z., Cheng, Q., Yin, Z., Zhou, Y ., and Qiu, X. Revisit- ing the test-time scaling of o1-like models: Do they truly possess test-time scaling capabilities?arXiv preprint arXiv:2502.12215,
-
[30]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Zhang, Q., Lyu, F., Sun, Z., Wang, L., Zhang, W., Hua, W., Wu, H., Guo, Z., Wang, Y ., Muennighoff, N., et al. A survey on test-time scaling in large language mod- els: What, how, where, and how well?arXiv preprint arXiv:2503.24235,
work page internal anchor Pith review arXiv
-
[31]
Accelerating best-of-n via specula- tive rejection
Zhang, R., Haider, M., Yin, M., Qiu, J., Wang, M., Bartlett, P., and Zanette, A. Accelerating best-of-n via specula- tive rejection. InICML 2024 Workshop on Structured Probabilistic Inference Generative Modeling,
2024
-
[32]
Vision-language-action model with open- world embodied reasoning from pretrained knowledge
Zhou, Z., Zhu, Y ., Wen, J., Shen, C., and Xu, Y . Chatvla-2: Vision-language-action model with open-world embodied reasoning from pretrained knowledge.arXiv preprint arXiv:2505.21906, 2025a. Zhou, Z., Zhu, Y ., Zhu, M., Wen, J., Liu, N., Xu, Z., Meng, W., Cheng, R., Peng, Y ., Shen, C., et al. Chatvla: Unified 10 VLA-ATTC: Adaptive Test-Time Compute for ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.