Recognition: unknown
Dynamics Aware Quadrupedal Locomotion via Intrinsic Dynamics Head
Pith reviewed 2026-05-09 14:38 UTC · model grok-4.3
The pith
Quadrupedal control policies learn more efficient locomotion when trained with a concurrent state-to-torque dynamics head.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Concurrently training an Intrinsic Dynamics Head to model state-to-torque relations allows the control policy to be guided by a dynamics reward based on the head's prediction accuracy, driving convergence to more efficient and smoother locomotion policies that transfer from simulation to real hardware.
What carries the argument
The Intrinsic Dynamics (ID) Head, a neural module trained in parallel with the policy to map current states to expected joint torques, whose prediction error is turned into a reward signal encouraging dynamical predictability.
If this is right
- Convergence to better optima for a wide range of standard quadrupedal locomotion rewards
- Production of more efficient and smoother policies in simulation
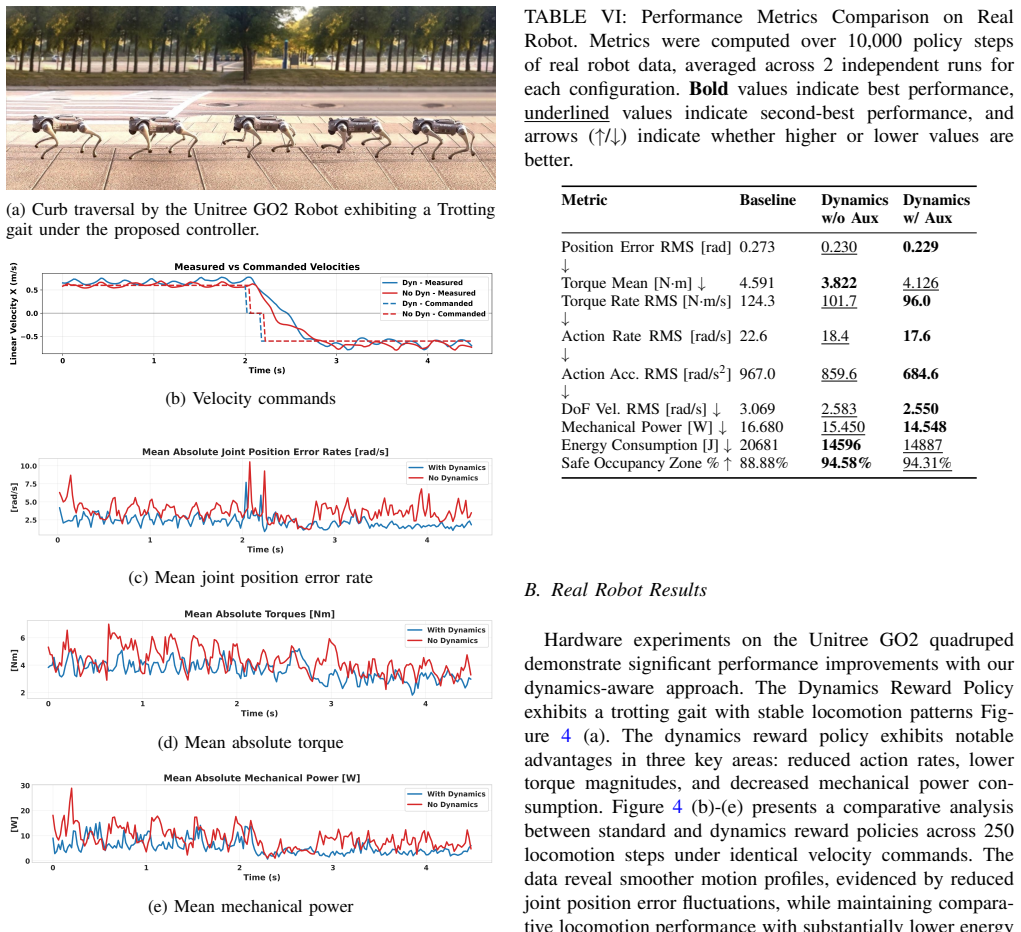
- Transfer to real robots with 16.8% better torque efficiency, 18.6% improved action rate, 12.8% lower mechanical power, and 6.4% better safe torque occupancy
- Tunability of the learned dynamics through adjustment of the ID Head's training coefficients
Where Pith is reading between the lines
- The method could extend to other legged robots by providing a general way to incorporate dynamics awareness without explicit modeling.
- By focusing on predictability, it may reduce the reality gap in reinforcement learning for robotics more broadly.
- The ID Head's predictions might be integrated directly into the policy for model-based behaviors in future designs.
Load-bearing premise
That the ID Head learns an accurate enough state-to-torque mapping during concurrent training for its prediction errors to form a useful and stable reward signal.
What would settle it
If real-robot experiments show equivalent or inferior performance in torque efficiency and smoothness when using the ID Head compared to standard training, that would disprove the transfer of benefits.
Figures



read the original abstract
Quadrupedal locomotion plays a critical role in enabling agile, versatile movement across complex terrains. Understanding and estimating the underlying physical dynamics are essential for achieving efficient and stable quadrupedal locomotion. We propose a novel training framework for quadrupedal locomotion that enables the Control Policy to understand and reason about physical dynamics. In simulation, we concurrently train an Intrinsic Dynamics (ID) Head that learns state-to-torque dynamics alongside the Control Policy, and we define a dynamics reward enabled by the ID Head that encourages the Policy toward more predictable dynamical behavior. We also provide a mechanism to tune the learned dynamics in the resulting Policy by controlling the training coefficients of the ID Head. Our simulation experiments show that this mechanism drives convergence to better optima across a wide range of standard quadrupedal locomotion rewards, yielding more efficient and smoother policies. Our real-robot experiments demonstrate sim-to-real transfer of these improvements, with significant gains in torque efficiency (16.8%), action rate (18.6%), and mechanical power (12.8%), while improving safe torque occupancy by 6.4%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a novel RL training framework for quadrupedal locomotion in which a Control Policy is trained concurrently with an Intrinsic Dynamics (ID) Head that learns a state-to-torque mapping. A dynamics reward is defined from the ID Head's prediction error to encourage policies exhibiting more predictable dynamics; the training coefficients of the ID Head can be used to tune the resulting policy. Simulation experiments across standard locomotion reward functions show convergence to more efficient and smoother policies, while real-robot experiments report gains of 16.8% in torque efficiency, 18.6% in action rate, 12.8% in mechanical power, and 6.4% in safe torque occupancy.
Significance. If the central mechanism is shown to operate as intended, the work provides a practical route to embedding dynamics awareness into model-free locomotion policies without an explicit physics model. The real-robot validation and the ability to modulate policy behavior via ID Head coefficients are concrete strengths that could influence reward design in legged-robot RL.
major comments (2)
- [Method section (training loop and reward formulation)] The dynamics reward is computed from the prediction error of the ID Head, which is trained jointly on the same on-policy trajectories used to update the Control Policy (see training procedure and reward definition). This creates a non-stationary reward signal whose generalization properties are not independently verified; no results are shown for ID Head error on held-out trajectories, fixed-policy rollouts, or out-of-distribution states. Without such checks, it remains possible that the reported efficiency gains arise from implicit distribution shaping rather than the intended dynamics-awareness effect.
- [Section 4] Section 4 (real-robot experiments): the abstract and results report specific percentage improvements (16.8% torque efficiency, 18.6% action rate, etc.) but supply no information on the number of independent trials, statistical significance, hyperparameter sensitivity, or ablations that disable the dynamics reward while keeping all other terms fixed. These omissions are load-bearing for the sim-to-real claim.
minor comments (1)
- [Section 3] The notation distinguishing the ID Head output, the dynamics reward term, and the tunable coefficients should be introduced with explicit equations early in the method section to improve readability.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help improve the clarity and rigor of our work. Below, we address each major comment in detail, outlining our responses and planned revisions to the manuscript.
read point-by-point responses
-
Referee: The dynamics reward is computed from the prediction error of the ID Head, which is trained jointly on the same on-policy trajectories used to update the Control Policy (see training procedure and reward definition). This creates a non-stationary reward signal whose generalization properties are not independently verified; no results are shown for ID Head error on held-out trajectories, fixed-policy rollouts, or out-of-distribution states. Without such checks, it remains possible that the reported efficiency gains arise from implicit distribution shaping rather than the intended dynamics-awareness effect.
Authors: We appreciate the referee's concern regarding the non-stationary nature of the dynamics reward and the lack of explicit generalization checks for the ID Head. The concurrent training is a deliberate design choice to enable the policy to discover and exploit predictable dynamics in a self-supervised manner. Our simulation results demonstrate that this approach leads to improved efficiency and smoothness across diverse reward formulations, which supports that the effect is tied to dynamics awareness rather than mere distribution shaping. To address the verification gap, we will add in the revised manuscript: (1) ID Head prediction errors evaluated on held-out trajectories collected from the converged policies, (2) comparisons with errors on fixed-policy rollouts, and (3) analysis on out-of-distribution states. These additions will help confirm the intended mechanism. revision: partial
-
Referee: Section 4 (real-robot experiments): the abstract and results report specific percentage improvements (16.8% torque efficiency, 18.6% action rate, etc.) but supply no information on the number of independent trials, statistical significance, hyperparameter sensitivity, or ablations that disable the dynamics reward while keeping all other terms fixed. These omissions are load-bearing for the sim-to-real claim.
Authors: We agree that the real-robot section would benefit from more comprehensive reporting to bolster the sim-to-real transfer claims. In the revised manuscript, we will report the number of independent trials conducted for each policy, include statistical significance testing for the percentage improvements, discuss hyperparameter sensitivity, and add an ablation where the dynamics reward is disabled (coefficient set to zero) while keeping other terms fixed. These details and results will be added to Section 4 and the supplementary material to strengthen the claims. revision: yes
Circularity Check
No significant circularity; empirical gains rest on independent benchmarks
full rationale
The paper's core mechanism concurrently trains an ID Head on state-to-torque mappings while using its prediction error to shape a dynamics reward for the policy. This co-training introduces a dependence on the policy's trajectory distribution, yet the reported outcomes—convergence to better optima in simulation and quantified real-robot improvements in torque efficiency (16.8%), action rate (18.6%), mechanical power (12.8%), and safe torque occupancy (6.4%)—are measured against external, policy-independent metrics. No equations or definitions in the abstract reduce the reward or the performance gains to a tautology by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The derivation chain therefore remains self-contained against the stated benchmarks rather than collapsing into its own fitted inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- training coefficients of the ID Head
axioms (1)
- domain assumption State-to-torque dynamics learned in simulation remain sufficiently predictive on the real robot for the reward signal to remain useful.
invented entities (1)
-
Intrinsic Dynamics Head
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Learning quadrupedal locomotion over challenging terrain,
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning quadrupedal locomotion over challenging terrain,”Science Robotics, vol. 5, no. 47, p. eabc5986, 2020
2020
-
[2]
Rapid locomotion via reinforcement learning,
G. B. Margolis, G. Yang, K. Paigwar, T. Chen, and P. Agrawal, “Rapid locomotion via reinforcement learning,” inProc. Robotics: Science and Systems, 2022
2022
-
[3]
RMA: Rapid motor adaptation for legged robots,
A. Kumar, Z. Fu, D. Pathak, and J. Malik, “RMA: Rapid motor adaptation for legged robots,” inProc. Robotics: Science and Systems, 2021
2021
-
[4]
Concurrent training of a control policy and a state estimator for dynamic and robust legged locomotion,
G. Ji, J. Mun, H. Kim, and J. Hwangbo, “Concurrent training of a control policy and a state estimator for dynamic and robust legged locomotion,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 4630–4637, 2022
2022
-
[5]
Learning agile and dynamic motor skills for legged robots,
J. Hwangbo, J. Lee, A. Dosovitskiy, D. Bellicoso, V . Tsounis, V . Koltun, and M. Hutter, “Learning agile and dynamic motor skills for legged robots,”Science Robotics, vol. 4, no. 26, p. eaau5872, 2019
2019
-
[6]
Legged locomotion in challenging terrains using egocentric vision,
A. Agarwal, A. Kumar, J. Malik, and D. Pathak, “Legged locomotion in challenging terrains using egocentric vision,” inProc. Conference on Robot Learning (CoRL), 2022
2022
-
[7]
DreamWaQ: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning,
I. M. Aswin Nahrendra, B. Yu, and H. Myung, “DreamWaQ: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning,” in2023 IEEE International Conference on Robotics and Automation (ICRA), London, United Kingdom, 2023, pp. 5078–5084
2023
-
[8]
Walk these ways: Tuning robot control for generalization with multiplicity of behavior,
G. B. Margolis and P. Agrawal, “Walk these ways: Tuning robot control for generalization with multiplicity of behavior,”Conference on Robot Learning, 2022
2022
-
[9]
Learning robust perceptive locomotion for quadrupedal robots in the wild,
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning robust perceptive locomotion for quadrupedal robots in the wild,”Science Robotics, vol. 7, no. 62, p. eabk2822, 2022
2022
-
[10]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Proc. Conference on Robot Learning (CoRL), 2022, pp. 91–100
2022
-
[11]
Isaac Gym: High performance GPU-based physics simulation for robot learning,
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Mack- lin, D. Hoeller, N. Rudin, A. Allshire, A. Handaet al., “Isaac Gym: High performance GPU-based physics simulation for robot learning,”Advances in Neural Information Processing Systems, Track on Datasets and Benchmarks, 2021
2021
-
[12]
Mujoco: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model-based control,” in2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2012, pp. 5026–5033
2012
-
[13]
Learning torque control for quadrupedal locomotion,
S. Chen, B. Zhang, M. W. Mueller, A. Rai, and K. Sreenath, “Learning torque control for quadrupedal locomotion,” in2023 IEEE-RAS 22nd International Conference on Humanoid Robots (Humanoids). Austin, TX, USA: IEEE, 2023, pp. 1–8
2023
-
[14]
Impedance control: An approach to manipulation: Part i—theory,
N. Hogan, “Impedance control: An approach to manipulation: Part i—theory,”Journal of Dynamic Systems, Measurement, and Control, vol. 107, no. 1, pp. 1–7, 1985
1985
-
[15]
Minimizing energy consumption leads to the emergence of gaits in legged robots,
Z. Fu, A. Kumar, J. Malik, and D. Pathak, “Minimizing energy consumption leads to the emergence of gaits in legged robots,” in Proc. Conference on Robot Learning (CoRL), 2021, pp. 928–937
2021
-
[16]
Sata: Safe and adaptive torque- based locomotion policies inspired by animal learning,
P. Li, H. Li, G. Sun, J. Cheng, X. Yang, G. Bellegarda, M. Shafiee, Y . Cao, A. Ijspeert, and G. Sartoretti, “Sata: Safe and adaptive torque- based locomotion policies inspired by animal learning,” inRobotics: Science and Systems (RSS), 2025
2025
-
[17]
Dynamic locomotion in the mit cheetah 3 through convex model-predictive control,
J. D. Carlo, P. M. Wensing, B. Katz, G. Bledt, and S. Kim, “Dynamic locomotion in the mit cheetah 3 through convex model-predictive control,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018, pp. 1–9
2018
-
[18]
Torque-based deep reinforcement learning for task-and-robot agnostic learning on bipedal robots using sim-to-real transfer,
D. Kim, G. Berseth, M. Schwartz, and J. Park, “Torque-based deep reinforcement learning for task-and-robot agnostic learning on bipedal robots using sim-to-real transfer,”IEEE Robotics and Automation Letters, vol. 8, no. 10, pp. 6251–6258, Oct. 2023
2023
-
[19]
Curiosity-driven exploration by self-supervised prediction,
D. Pathak, P. Agrawal, A. A. Efros, and T. Darrell, “Curiosity-driven exploration by self-supervised prediction,” inProc. 34th International Conference on Machine Learning (ICML), 2017, pp. 2778–2787
2017
-
[20]
Learning to poke by poking: Experiential learning of intuitive physics,
P. Agrawal, A. Nair, P. Abbeel, J. Malik, and S. Levine, “Learning to poke by poking: Experiential learning of intuitive physics,” in Advances in Neural Information Processing Systems (NeurIPS 2016), 2016
2016
-
[21]
World models,
D. Ha and J. Schmidhuber, “World models,” 2018
2018
-
[22]
When to trust your model: Model-based policy optimization,
M. Janner, J. Fu, M. Zhang, and S. Levine, “When to trust your model: Model-based policy optimization,” inAdvances in Neural Information Processing Systems, 2019
2019
-
[23]
Mastering atari, go, chess and shogi by planning with a learned model,
J. Schrittwieser, I. Antonoglou, T. Hubert, K. Simonyan, L. Sifre, S. Schmitt, A. Guez, E. Lockhart, D. Hassabis, T. Graepel, T. Lillicrap, and D. Silver, “Mastering atari, go, chess and shogi by planning with a learned model,”Nature, vol. 588, no. 7839, pp. 604–609, 2020
2020
-
[24]
Exploration by random network distillation,
Y . Burda, H. Edwards, A. Storkey, and O. Klimov, “Exploration by random network distillation,” inInternational Conference on Learning Representations, 2019. [Online]. Available: https: //openreview.net/forum?id=H1lJJnR5Ym
2019
-
[25]
Learning by cheating,
D. Chen, B. Zhou, V . Koltun, and P. Kr ¨ahenb¨uhl, “Learning by cheating,” inProc. Conference on Robot Learning (CoRL), 2020, pp. 66–75
2020
-
[26]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and J. A. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” in Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, 2011, pp. 627–635
2011
-
[27]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
S. Bai, J. Z. Kolter, and V . Koltun, “An empirical evaluation of generic convolutional and recurrent networks for sequence modeling,” arXiv preprint arXiv:1803.01271, 2018. [Online]. Available: https: //arxiv.org/abs/1803.01271
work page internal anchor Pith review arXiv 2018
-
[29]
Sim-to- real transfer of robotic control with dynamics randomization,
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel, “Sim-to- real transfer of robotic control with dynamics randomization,” in2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 3803–3810
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.