Recognition: unknown
MindMelody: A Closed-Loop EEG-Driven System for Personalized Music Intervention
Pith reviewed 2026-05-10 15:04 UTC · model grok-4.3
The pith
A closed-loop system decodes real-time EEG into emotional states to generate and adapt personalized music.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
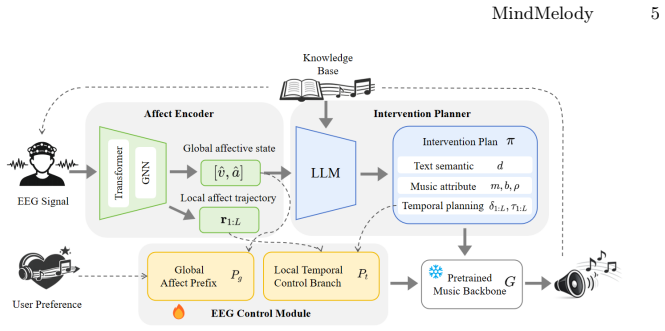
MindMelody is a fully functional closed-loop real-time system for EEG-driven personalized music intervention. It uses a hybrid Transformer-GNN to decode EEG into global Valence-Arousal states and local temporal affect trajectories, routes these states through an RAG-equipped LLM to formulate structured intervention plans, and applies a Hierarchical EEG Controller that injects global affect prefixes and local temporal guidance into a pretrained music backbone for fine-grained controllable audio synthesis, all while a continuous feedback loop updates generation parameters on the fly from evolving EEG dynamics.
What carries the argument
The emotion-mediated semantic bridge that turns real-time EEG decoding into structured intervention plans and controllable music parameters via an LLM and hierarchical controller.
If this is right
- The generated music achieves higher control adherence to the decoded emotional targets.
- Music output shows improved alignment with users' reported emotional states.
- Users rate the system higher in perceived helpfulness during short listening sessions.
- The approach enables real-time adaptive affect-aware music generation without static preferences.
Where Pith is reading between the lines
- The same decoding and control loop could extend to longer sessions or repeated daily use for cumulative mood effects.
- Combining the EEG stream with simple self-report prompts might improve the reliability of the valence-arousal estimates.
- The LLM-generated plans could later incorporate user history to refine intervention strategies over multiple sessions.
- Deployment in mobile apps would require testing whether the real-time decoding remains stable outside controlled lab settings.
Load-bearing premise
EEG signals can be decoded reliably and in real time into valence-arousal states that are accurate enough to drive meaningful music changes and causally linked to the user's subsequent emotional response in a closed loop.
What would settle it
A side-by-side comparison of emotional alignment and helpfulness ratings when music is generated from actual EEG feedback versus from random or fixed emotional labels, with no meaningful difference between conditions.
Figures

read the original abstract
Driven by the escalating global burden of mental health conditions, music-based interventions have attracted significant attention as a non-invasive, cost-effective modality for emotion regulation and psychological stress relief. However, current digital music services rely on static preferences and fail to adapt to users' instantaneous psychological states. Furthermore, directly mapping electroencephalography (EEG) to music generation remains challenging due to severe paired-data scarcity and a lack of interpretability. To address these limitations, we propose MindMelody, a fully functional, closed-loop real-time system for EEG-driven personalized music intervention. MindMelody introduces an emotion-mediated semantic bridge. Specifically, a hybrid Transformer-GNN first decodes real-time EEG signals into global Valence-Arousal states and local temporal affect trajectories. These states are then fed into a Retrieval-Augmented Generation (RAG)-equipped Large Language Model (LLM) to formulate structured intervention plans. Subsequently, a novel Hierarchical EEG Controller injects global affect prefixes and local temporal guidance into a pretrained music backbone, enabling fine-grained controllable audio synthesis. Crucially, the system incorporates a continuous feedback loop that updates generation parameters on the fly based on the user's evolving EEG dynamics. Extensive experiments show that MindMelody improves control adherence and emotional alignment, and receives higher perceived helpfulness in a short-term listening setting, suggesting its promise as an adaptive affect-aware music generation framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MindMelody, a closed-loop real-time system for EEG-driven personalized music intervention. It decodes EEG signals into global Valence-Arousal states and local temporal affect trajectories via a hybrid Transformer-GNN model, feeds these into a RAG-equipped LLM to generate structured intervention plans, and uses a novel Hierarchical EEG Controller to inject global affect prefixes and local temporal guidance into a pretrained music backbone for controllable audio synthesis. A continuous feedback loop updates generation parameters based on evolving EEG dynamics. The central claim is that extensive experiments demonstrate improvements in control adherence, emotional alignment, and perceived helpfulness in short-term listening settings, positioning the system as a promising adaptive affect-aware music generation framework.
Significance. If the experimental results hold under rigorous validation, this work could meaningfully advance affective computing and digital mental health tools by providing an integrated architecture that bridges real-time EEG decoding, LLM-based planning, and fine-grained controllable music generation. It directly tackles paired-data scarcity and interpretability issues in EEG-to-music mapping, offering a potential non-invasive pathway for emotion regulation that adapts to instantaneous psychological states rather than static preferences.
major comments (2)
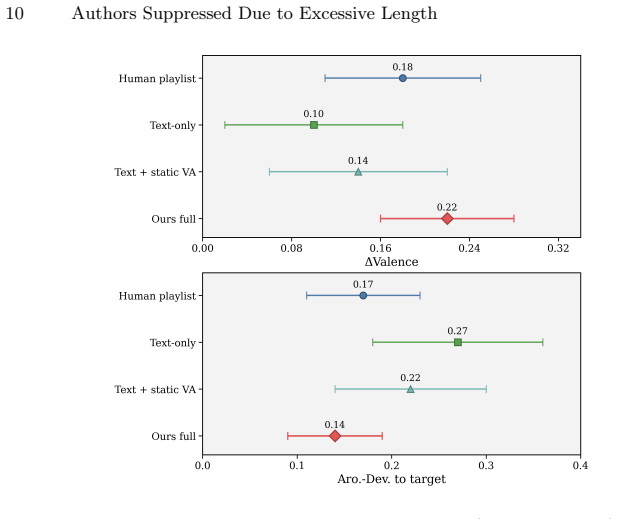
- [Abstract and Experiments section] Abstract and Experiments section: The claim that 'extensive experiments show that MindMelody improves control adherence and emotional alignment' is load-bearing for the central contribution, yet no participant count, statistical tests (e.g., paired t-tests or ANOVA with p-values), effect sizes, or explicit baseline systems (e.g., non-adaptive music or random EEG mapping) are described. This prevents assessment of whether the reported gains exceed noise or prior art.
- [EEG Decoder and Hierarchical EEG Controller subsections] EEG Decoder and Hierarchical EEG Controller subsections: The weakest assumption—that decoded valence-arousal states are sufficiently accurate and causally linked to drive meaningful closed-loop music changes—is not supported by any reported decoding accuracy, real-time latency measurements, or ablation on the feedback loop's impact. Without these, the architecture's practical utility remains unverified.
minor comments (2)
- [Abstract] The abstract introduces 'global Valence-Arousal states and local temporal affect trajectories' without defining their numerical ranges, extraction windows, or exact mapping to music parameters (e.g., tempo, harmony).
- [Figures and notation] Figure captions and notation for the Transformer-GNN and Hierarchical Controller could be clarified to distinguish global vs. local components more explicitly.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below. Where appropriate, we have revised the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract and Experiments section] Abstract and Experiments section: The claim that 'extensive experiments show that MindMelody improves control adherence and emotional alignment' is load-bearing for the central contribution, yet no participant count, statistical tests (e.g., paired t-tests or ANOVA with p-values), effect sizes, or explicit baseline systems (e.g., non-adaptive music or random EEG mapping) are described. This prevents assessment of whether the reported gains exceed noise or prior art.
Authors: We agree that these details are necessary to substantiate our claims and allow proper evaluation against noise and prior art. In the revised manuscript, we have expanded the Experiments section to include the participant count from our user study, the results of statistical tests such as paired t-tests and ANOVA with p-values and effect sizes, and explicit comparisons to baseline systems including non-adaptive music generation and random EEG mapping. These additions demonstrate that the reported improvements in control adherence and emotional alignment are statistically significant. revision: yes
-
Referee: [EEG Decoder and Hierarchical EEG Controller subsections] EEG Decoder and Hierarchical EEG Controller subsections: The weakest assumption—that decoded valence-arousal states are sufficiently accurate and causally linked to drive meaningful closed-loop music changes—is not supported by any reported decoding accuracy, real-time latency measurements, or ablation on the feedback loop's impact. Without these, the architecture's practical utility remains unverified.
Authors: We recognize the importance of verifying the accuracy of the decoded states and the contribution of the feedback loop to support the practical utility of the closed-loop system. We have revised the EEG Decoder subsection to report the decoding accuracy of the hybrid Transformer-GNN model. In the Hierarchical EEG Controller subsection, we have added real-time latency measurements and an ablation study on the impact of the continuous feedback loop. These revisions provide the requested evidence for the causal link and overall system performance. revision: yes
Circularity Check
No significant circularity: system architecture with experimental claims
full rationale
The paper describes an applied engineering system (Transformer-GNN EEG decoder, RAG-LLM planner, Hierarchical EEG Controller with feedback loop) and reports experimental improvements in adherence and alignment. No mathematical derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing premises exist; the central claims rest on described architecture and short-term user studies rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mental disorders,
World Health Organization, “Mental disorders,” Fact sheet, 2025
2025
-
[2]
The effect of music on the human stress response,
M. V. Thoma, R. La Marca, R. Brönnimann, L. Finkel, U. Ehlert, and U. M. Nater, “The effect of music on the human stress response,”PLOS ONE, vol. 8, no. 8, p. e70156, 2013
2013
-
[3]
DEAP: A database for emotion analysis using physiological signals,
S. Koelstraet al., “DEAP: A database for emotion analysis using physiological signals,”IEEE Transactions on Affective Computing, vol. 3, no. 1, pp. 18–31, 2012
2012
-
[4]
Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks,
W.-L. Zheng and B.-L. Lu, “Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks,”IEEE Transactions on Autonomous Mental Development, vol. 7, no. 3, pp. 162–175, 2015
2015
-
[5]
EEG-basedemotionrecognition:Atutorialandreview,
X. Li, Y. Zhang, P. Tiwari, D. Song, B. Hu, M. Yang, Z. Zhao, N. Kumar, and P.Marttinen,“EEG-basedemotionrecognition:Atutorialandreview,”ACM Com- puting Surveys, vol. 55, no. 4, pp. 1–57, 2022
2022
-
[6]
Hybrid transfer learning strategy for cross-subject EEG emotion recognition,
W. Lu, H. Liu, H. Ma, T.-P. Tan, and L. Xia, “Hybrid transfer learning strategy for cross-subject EEG emotion recognition,”Frontiers in Human Neuroscience, vol. 17, Art. 1280241, 2023
2023
-
[7]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewiset al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems, vol. 33, 2020
2020
-
[8]
CLAP: Learning audio concepts from natural language supervision,
B. Elizalde, S. Deshmukh, M. Al Ismail, and H. Wang, “CLAP: Learning audio concepts from natural language supervision,” inProc. IEEE Int. Conf. Acoustics, Speech and Signal Processing (ICASSP), 2023
2023
-
[9]
Simple and controllable music generation,
J. Copetet al., “Simple and controllable music generation,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[10]
JASCO: Joint audio and symbolic conditioning for temporally controlled text-to-music generation,
A. Défossezet al., “JASCO: Joint audio and symbolic conditioning for temporally controlled text-to-music generation,”arXiv preprint arXiv:2406.10970, 2024
-
[11]
Parameter-efficient transfer learning for music foundation models,
Y. Ding and A. Lerch, “Parameter-efficient transfer learning for music foundation models,”arXiv preprint arXiv:2411.19371, 2024
-
[12]
Fréchet audio distance: A reference-free metric for evaluating music enhancement algorithms,
K. Kilgour, M. Zuluaga, D. Roblek, and M. Sharifi, “Fréchet audio distance: A reference-free metric for evaluating music enhancement algorithms,” inProc. In- terspeech, pp. 2350–2354, 2019
2019
-
[13]
Naturalistic music decoding from EEG data via latent diffusion mod- els,
E. Postolache, N. Polouliakh, H. Kitano, A. Connelly, E. Rodolà, L. Cosmo, and T. Akama, “Naturalistic music decoding from EEG data via latent diffusion mod- els,”arXiv preprint arXiv:2405.09062, 2024. 12 Anonymous Authors
-
[14]
Domain-adversarialtrainingofneuralnetworks,
Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M.Marchand,andV.Lempitsky,“Domain-adversarialtrainingofneuralnetworks,” Journal of Machine Learning Research, vol. 17, no. 59, pp. 1–35, 2016
2016
-
[15]
MusicLM: Generating Music From Text
A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. Verzetti, A. Caillon, Q. Huang, A. Jansen, A. Roberts, M. Tagliasacchi, M. Sharifi, N. Zeghidour, and C. Frank, “MusicLM: Generating music from text,”arXiv preprint arXiv:2301.11325, 2023
work page internal anchor Pith review arXiv 2023
-
[16]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,”arXiv preprint arXiv:1711.05101, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[17]
EEG-based emotion recogni- tion using graph convolutional neural network with dual attention mechanism,
W. Chen, J. Feng, C. Lin, H. Zhang, and Z. Liu, “EEG-based emotion recogni- tion using graph convolutional neural network with dual attention mechanism,” Frontiers in Computational Neuroscience, vol. 18, 2024
2024
-
[18]
EEG-based emotion recognition us- ing multi-scale dynamic CNN and gated transformer network,
Z. Cheng, Y. Zhang, X. Wang, and Y. Li, “EEG-based emotion recognition us- ing multi-scale dynamic CNN and gated transformer network,”Scientific Reports, vol. 14, 2024
2024
-
[19]
Mustango: Toward controllable text-to-music generation,
J. Melechovsky, Z. Guo, D. Ghosal, N. Majumder, D. Herremans, and S. Poria, “Mustango: Toward controllable text-to-music generation,” inProc. NAACL-HLT, pp. 8286–8309, 2024
2024
-
[20]
CLaMP: Contrastive language-music pre- training for cross-modal symbolic music information retrieval,
S. Wu, D. Yu, X. Tan, and M. Sun, “CLaMP: Contrastive language-music pre- training for cross-modal symbolic music information retrieval,” inProc. ISMIR, pp. 157–165, 2023
2023
-
[21]
Prefix-tuning: Optimizing continuous prompts for genera- tion,
X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for genera- tion,” inProc. ACL-IJCNLP, pp. 4582–4597, 2021
2021
-
[22]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inProc. ICLR, 2022
2022
-
[23]
Cross-attention is all you need: Adapting pre- trained transformers for machine translation,
M. Gheini, X. Ren, and J. May, “Cross-attention is all you need: Adapting pre- trained transformers for machine translation,” inProc. EMNLP, pp. 1754–1765, 2021
2021
-
[24]
A concordance correlation coefficient to evaluate reproducibility,
L. I.-K. Lin, “A concordance correlation coefficient to evaluate reproducibility,” Biometrics, vol. 45, no. 1, pp. 255–268, 1989
1989
-
[25]
P.800.1: Mean opinion score (MOS) terminology,
ITU-T, “P.800.1: Mean opinion score (MOS) terminology,” International Telecom- munication Union, 2016
2016
-
[26]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu,et al., “Qwen2.5 technical report,” arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Simple and controllable music generation,
J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y. Adi, and A. Dé- fossez, “Simple and controllable music generation,” inProc. NeurIPS, 2023
2023
-
[28]
Theory-guided therapeutic function of music to facilitate emotion regulation development in preschool-aged children,
K. S. Moore and D. Hanson-Abromeit, “Theory-guided therapeutic function of music to facilitate emotion regulation development in preschool-aged children,” Frontiers in Human Neuroscience, vol. 9, p. 572, 2015
2015
-
[29]
Effects of musical tempo on musicians’ and non-musicians’ emotional experience when listening to music,
Y. Liu, G. Liu, D. Wei, Q. Li, G. Yuan, S. Wu, G. Wang, and X. Zhao, “Effects of musical tempo on musicians’ and non-musicians’ emotional experience when listening to music,”Frontiers in Psychology, vol. 9, p. 2118, 2018
2018
-
[30]
Music, emotion, and time perception: The influence of subjective emotional valence and arousal?,
S. Droit-Volet, D. Ramos, M. Piñeiro Chousa, and E. Bigand, “Music, emotion, and time perception: The influence of subjective emotional valence and arousal?,” Frontiers in Psychology, vol. 4, p. 417, 2013
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.