Recognition: unknown
Are we Doomed to an AI Race? Why Self-Interest Could Drive Countries Towards a Moratorium on Superintelligence
Pith reviewed 2026-05-09 18:27 UTC · model grok-4.3
The pith
Sufficiently high perceived costs of losing control can make a superintelligence moratorium the rational self-interest of competing states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By formalizing the trade-off between technological supremacy and catastrophic risks in a game-theoretic setting, the authors establish that as the perceived cost of loss of control increases sufficiently relative to other parameters, it becomes in each state's self-interest to impose a moratorium on superintelligence development.
What carries the argument
A game-theoretic model of state interactions that weighs benefits of AI leadership against risks of uncontrolled superintelligence and identifies the parameter threshold at which moratorium becomes the dominant strategy.
If this is right
- Each state prefers mutual moratorium once perceived risk costs cross a critical threshold.
- The resulting equilibrium is stable because no party gains by unilaterally resuming development.
- Empirical increases in risk awareness make a self-enforcing pause more attainable without coercion.
- The model isolates exact conditions under which pure self-interest produces restraint rather than escalation.
Where Pith is reading between the lines
- Efforts that raise public and elite awareness of ASI dangers could move states closer to the self-interest threshold for a moratorium.
- The same payoff logic might apply to other dual-use technologies carrying high loss-of-control risks.
- Domestic political divisions within states could prevent the coherent risk valuation the model requires.
- Tracking whether policy statements shift in tandem with changes in risk-perception surveys would test the mechanism.
Load-bearing premise
States act as unitary rational actors whose perceived costs of losing control over ASI can be treated as adjustable parameters free of internal political or organizational frictions.
What would settle it
Continued acceleration of superintelligence programs by major powers even as independent surveys document sharply rising global perceptions of loss-of-control risk would show that the predicted shift in self-interest does not occur.
Figures

read the original abstract
This paper uses game theory to argue that, contrary to the prevailing view, a moratorium on Artificial Superintelligence (ASI) can be in a state's self-interest. By formalizing trategic interactions between geopolitical superpowers, we model the trade-off between the benefits of technological supremacy and the catastrophic risks of uncontrolled ASI. The analysis reveals that as the perceived cost of loss of control increases sufficiently relative to other parameters, it becomes in each state's self-interest to impose a moratorium. We further provide empirical evidence suggesting that the global perception of ASI risk is rising, making a stable, rational moratorium increasingly plausible in the current geopolitical landscape.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper uses game theory to model strategic interactions between geopolitical superpowers on Artificial Superintelligence (ASI) development. It claims that, contrary to the prevailing view of an inevitable AI race driven by self-interest, a moratorium on ASI can become the equilibrium outcome when the perceived cost of loss of control exceeds a sufficient threshold relative to other parameters. It further asserts that empirical trends show rising global perception of ASI risks, making such a rational moratorium increasingly plausible.
Significance. If the game-theoretic derivation is made rigorous and the empirical component substantiated, the paper could offer a useful formalization of conditions under which self-interest favors restraint in high-stakes technology competitions. This would provide a counterpoint to standard AI arms-race narratives in policy literature and could inform discussions of international AI governance. The explicit modeling of the supremacy-benefit versus catastrophic-risk trade-off is a constructive step, though its value hinges on resolving the parameter and evidence issues.
major comments (3)
- [Abstract] Abstract: The claim that 'as the perceived cost of loss of control increases sufficiently relative to other parameters, it becomes in each state's self-interest to impose a moratorium' is asserted without any derivation of the payoff functions, equilibrium conditions, or demonstration that the threshold is reached for non-arbitrary parameter values. This is load-bearing for the central result.
- [Modeling section] Modeling section: The 'perceived cost of loss of control' is treated as an exogenous free parameter that is adjusted until the moratorium equilibrium appears, rather than being derived from observable capabilities, domestic institutions, or belief-updating processes. This makes the strongest claim dependent on the modeling choice itself.
- [Empirical evidence] Empirical evidence: The assertion that 'the global perception of ASI risk is rising' is presented without any data sources, survey instruments, statistical methods, or analysis, rendering it impossible to evaluate whether the trend actually supports the policy conclusion.
minor comments (1)
- [Abstract] Abstract: 'trategic interactions' is a typographical error and should read 'strategic interactions'.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which help clarify how to strengthen the rigor of the game-theoretic claims and the supporting evidence. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'as the perceived cost of loss of control increases sufficiently relative to other parameters, it becomes in each state's self-interest to impose a moratorium' is asserted without any derivation of the payoff functions, equilibrium conditions, or demonstration that the threshold is reached for non-arbitrary parameter values. This is load-bearing for the central result.
Authors: The abstract summarizes the central result derived in the modeling section. We will revise the abstract to include a brief reference to the equilibrium condition (moratorium as dominant strategy when perceived loss-of-control cost exceeds a threshold determined by the ratio of supremacy benefits to baseline parameters) and direct readers to the modeling section for the full payoff derivation and Nash analysis. We will also incorporate a short discussion of plausible parameter ranges based on expert estimates of ASI risk probabilities to illustrate that the threshold is reachable for non-arbitrary values. revision: yes
-
Referee: [Modeling section] Modeling section: The 'perceived cost of loss of control' is treated as an exogenous free parameter that is adjusted until the moratorium equilibrium appears, rather than being derived from observable capabilities, domestic institutions, or belief-updating processes. This makes the strongest claim dependent on the modeling choice itself.
Authors: Treating the perceived cost as a parameter is intentional to derive the analytical threshold condition under which self-interest favors a moratorium, consistent with standard game-theoretic approaches to policy analysis. This isolates the role of risk perception in shifting equilibria. In revision, we will add a dedicated subsection linking the parameter to observable proxies (e.g., public opinion data and official statements) and outline how it could be endogenized in extensions via belief-updating processes, while retaining the core parametric analysis. revision: partial
-
Referee: [Empirical evidence] Empirical evidence: The assertion that 'the global perception of ASI risk is rising' is presented without any data sources, survey instruments, statistical methods, or analysis, rendering it impossible to evaluate whether the trend actually supports the policy conclusion.
Authors: We agree that the empirical claim requires explicit substantiation. The revised manuscript will incorporate specific data sources (e.g., references to repeated international surveys on AI risk perceptions), describe the survey instruments and trend analysis methods employed, and present the observed upward trend with appropriate caveats. This will allow readers to assess whether the evidence supports the policy implications. revision: yes
Circularity Check
No significant circularity in the game-theoretic derivation
full rationale
The paper presents a standard game-theoretic analysis in which a moratorium equilibrium emerges conditionally when an exogenous parameter (perceived cost of loss of control) exceeds a threshold relative to benefits of racing. This is a direct mathematical consequence of the payoff structure rather than a reduction by construction, self-definition, or fitted input. The authors separately cite empirical trends in rising ASI risk perception to argue the threshold may become relevant, but this does not make the model output tautological. No load-bearing step equates the claimed result to its inputs via renaming, self-citation chains, or ansatz smuggling. The derivation remains self-contained within its stated assumptions of unitary rational actors.
Axiom & Free-Parameter Ledger
free parameters (1)
- perceived cost of loss of control
axioms (1)
- domain assumption States behave as unitary rational actors maximizing expected self-interest in a simultaneous-move game
Reference graph
Works this paper leans on
-
[1]
A Prisoner’s Dilemma in the Race to Artificial General Intelligence
Lisa Abraham, Joshua Kavner, and Alvin Moon. A Prisoner’s Dilemma in the Race to Artificial General Intelligence. Technical report, RAND Corporation, Santa Monica, CA, 2026
2026
-
[2]
Racing to the Precipice: a Model of Artificial Intelligence Development.AI & SOCI- ETY, 31(2):201–206, May 2016
Stuart Armstrong, Nick Bostrom, and Carl Shulman. Racing to the Precipice: a Model of Artificial Intelligence Development.AI & SOCI- ETY, 31(2):201–206, May 2016
2016
-
[3]
Leopold Aschenbrenner.Situational Awareness. 2024
2024
-
[4]
Oxford University Press, Oxford, New York, July 2014
Nick Bostrom.Superintelligence: Paths, Dangers, Strategies. Oxford University Press, Oxford, New York, July 2014
2014
-
[5]
Statement on AI Risk, 2023
Center for AI Safety. Statement on AI Risk, 2023
2023
-
[6]
World Leaders Agree to Launch Network of AI Safety Institutes, May 2024
Anna Desmarais. World Leaders Agree to Launch Network of AI Safety Institutes, May 2024. Section: next tech-news
2024
-
[7]
Against racing to AGI: Cooperation, deterrence, and catastrophic risks, July 2025
Leonard Dung and Max Hellrigel-Holderbaum. Against racing to AGI: Cooperation, deterrence, and catastrophic risks, July 2025. arXiv:2507.21839 [cs]. 15
-
[8]
Uncertainty, Information, and Risk in International Technology Races.Journal of Conflict Resolution, 68(10):2019–2047, November 2024
Nicholas Emery-Xu, Andrew Park, and Robert Trager. Uncertainty, Information, and Risk in International Technology Races.Journal of Conflict Resolution, 68(10):2019–2047, November 2024
2019
-
[9]
Pause Giant AI Experiments: An Open Letter, 2023
Future of Life Institute. Pause Giant AI Experiments: An Open Letter, 2023
2023
-
[10]
Statement on Superintelligence, 2025
Future of Life Institute. Statement on Superintelligence, 2025
2025
-
[11]
Future of Life Institute. The U.S. Public Wants Regulation (or Prohi- bition) of Expert-Level and Superhuman AI, October 2025
2025
-
[12]
Goldstein and Jon C
Joshua S. Goldstein and Jon C. Pevehouse.International Relations. Pearson, Harlow, UK, twelfth edition, 2020
2020
-
[13]
Korzekwa
Katja Grace, Julia Fabienne Sandk¨ uhler, Harlan Stewart, Benjamin Weinstein-Raun, Stephen Thomas, Zach Stein-Perlman, John Salvatier, Jan Brauner, and Richard C. Korzekwa. Thousands of AI Authors on the Future of AI.Journal of Artificial Intelligence Research, 84, October 2025
2025
-
[14]
What are the odds? Risk and uncertainty about AI existential risk, October 2025
Marco Grossi. What are the odds? Risk and uncertainty about AI existential risk, October 2025
2025
-
[15]
Bridging the Artificial Intelligence Gov- ernance Gap: The United States’ and China’s Divergent Approaches to Governing General-Purpose Artificial Intelligence
Oliver Guest and Kevin Wei. Bridging the Artificial Intelligence Gov- ernance Gap: The United States’ and China’s Divergent Approaches to Governing General-Purpose Artificial Intelligence. Technical report, RAND Corporation, 2024
2024
-
[16]
Trager, Anka Reuel, David Manheim, Miles Brundage, Onni Aarne, Aaron Scher, Yanliang Pan, Jenny Xiao, and Kristy Loke
Ben Harack, Robert F. Trager, Anka Reuel, David Manheim, Miles Brundage, Onni Aarne, Aaron Scher, Yanliang Pan, Jenny Xiao, and Kristy Loke. Verification for International AI Governance.AI Gover- nance Initiative, Oxford Martin School, 2025
2025
-
[17]
Action Plan to Increase the Safety and Security of Advanced AI
Jeremy Harris, Edouard Harris, and Mark Beall. Action Plan to Increase the Safety and Security of Advanced AI. Technical report, Gladstone AI, 2023
2023
-
[18]
Superintelligence strategy: Expert version
Dan Hendrycks, Eric Schmidt, and Alexandr Wang. Superintelligence Strategy: Expert Version, April 2025. arXiv:2503.05628 [cs]. 16
-
[19]
Conflict and rent-seeking success functions: Ratio vs
Jack Hirshleifer. Conflict and rent-seeking success functions: Ratio vs. difference models of relative success.Public Choice, 63(2):101–112, November 1989
1989
-
[20]
Cooperation Under the Security Dilemma.World Poli- tics, 30(2):167–214, 1978
Robert Jervis. Cooperation Under the Security Dilemma.World Poli- tics, 30(2):167–214, 1978
1978
-
[21]
Contest functions: Theoretical foundations and issues in estimation.International Journal of Industrial Organization, 31(3):211–222, May 2013
Hao Jia, Stergios Skaperdas, and Samarth Vaidya. Contest functions: Theoretical foundations and issues in estimation.International Journal of Industrial Organization, 31(3):211–222, May 2013
2013
-
[22]
The Manhattan Trap: Why a Race to Artificial Superintelligence is Self-Defeating, 2025
Corin Katzke and Gideon Futerman. The Manhattan Trap: Why a Race to Artificial Superintelligence is Self-Defeating, 2025
2025
-
[23]
Kydd.Trust and Mistrust in International Relations
Andrew H. Kydd.Trust and Mistrust in International Relations. Prince- ton University Press, Princeton, NJ Oxford, 2007
2007
-
[24]
Lippman and Kevin F
Steven A. Lippman and Kevin F. McCardle. Preemption in R&D races. European Economic Review, 32(8):1661–1669, October 1988
1988
-
[25]
M¨ uller and Nick Bostrom
Vincent C. M¨ uller and Nick Bostrom. Future Progress in Artificial In- telligence: A Survey of Expert Opinion. In Vincent C. M¨ uller, editor, Fundamental Issues of Artificial Intelligence, pages 555–572. Springer International Publishing, Cham, 2016
2016
-
[26]
Bloomsbury Academic, London, 2021
Toby Ord.The Precipice: Existential Risk and the Future of Humanity. Bloomsbury Academic, London, 2021
2021
-
[27]
AI Doomsday Worries many Americans
Taylor Orth and Carl Bialik. AI Doomsday Worries many Americans. So does Apocalypse from Climate Change, Nukes, War, and More, April 2023
2023
-
[28]
Springer Berlin Heidelberg, Berlin, Heidelberg, 2015
Hans Peters.Game Theory: A Multi-Leveled Approach, volume Second Edition. Springer Berlin Heidelberg, Berlin, Heidelberg, 2015
2015
-
[29]
AI Ban Backers Risk Freezing Progress, October 2025
James Pethokoukis. AI Ban Backers Risk Freezing Progress, October 2025
2025
-
[30]
Why the U.S
Tharin Pillay. Why the U.S. Launched an International Network of AI Safety Institutes, November 2024. 17
2024
-
[31]
Benchmarking as a Path to International AI Governance
Ian Reynolds. Benchmarking as a Path to International AI Governance. 2025
2025
-
[32]
Penguin UK, 2019
Stuart Russell.Human Compatible: AI and the Problem of Control. Penguin UK, 2019
2019
-
[33]
Schelling.The strategy of conflict.Harvard university, Cam- bridge (Mass.), 2nd pr
Thomas C. Schelling.The strategy of conflict.Harvard university, Cam- bridge (Mass.), 2nd pr. edition, 1963
1963
-
[34]
Prisoner’s Dilemma
Glenn H. Snyder. “Prisoner’s Dilemma” and “Chicken” Models in Inter- national Politics.International Studies Quarterly, 15(1):66–103, March 1971
1971
-
[35]
Existential Risk and Global Catas- trophic Risk: A Review
Lalitha Sundaram and Lara Mani. Existential Risk and Global Catas- trophic Risk: A Review. May 2025
2025
-
[36]
AI Threatens Humanity’s Future, 61% of Americans say: Reuters/Ipsos poll.Reuters, May 2023
Anna Tong. AI Threatens Humanity’s Future, 61% of Americans say: Reuters/Ipsos poll.Reuters, May 2023
2023
-
[37]
The Bletchley Declaration by Countries Attending the AI Safety Summit, 1-2 November 2023, February 2025
UK Government. The Bletchley Declaration by Countries Attending the AI Safety Summit, 1-2 November 2023, February 2025
2023
-
[38]
A Taxonomy of Systemic Risks from General-Purpose AI, November
Risto Uuk, Carlos Ignacio Gutierrez, Daniel Guppy, Lode Lauwaert, Atoosa Kasirzadeh, Lucia Velasco, Peter Slattery, and Carina Prunkl. A Taxonomy of Systemic Risks from General-Purpose AI, November
- [39]
-
[40]
Who’s Driving? Game Theoretic Path Risk of AGI De- velopment, January 2025
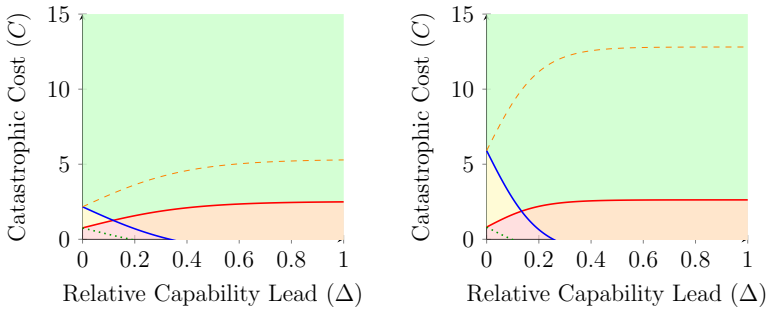
Robin Young. Who’s Driving? Game Theoretic Path Risk of AGI De- velopment, January 2025. arXiv:2501.15280 [cs]. Appendix The Model We formalize the strategic model described in Section 2 above as a two player game, with playersi∈ {1,2}. Let ∆ denote the Frontrunner’s relative capa- bility advantage. Lets i ∈[0,1] be the safety policy taken by playeri, whe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.