Recognition: unknown
Checkerboard: A Simple, Effective, Efficient and Learning-free Clean Label Backdoor Attack with Low Poisoning Budget
Pith reviewed 2026-05-09 14:28 UTC · model grok-4.3
The pith
A checkerboard trigger derived in closed form from linear separability creates an effective clean-label backdoor attack without any surrogate training or optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
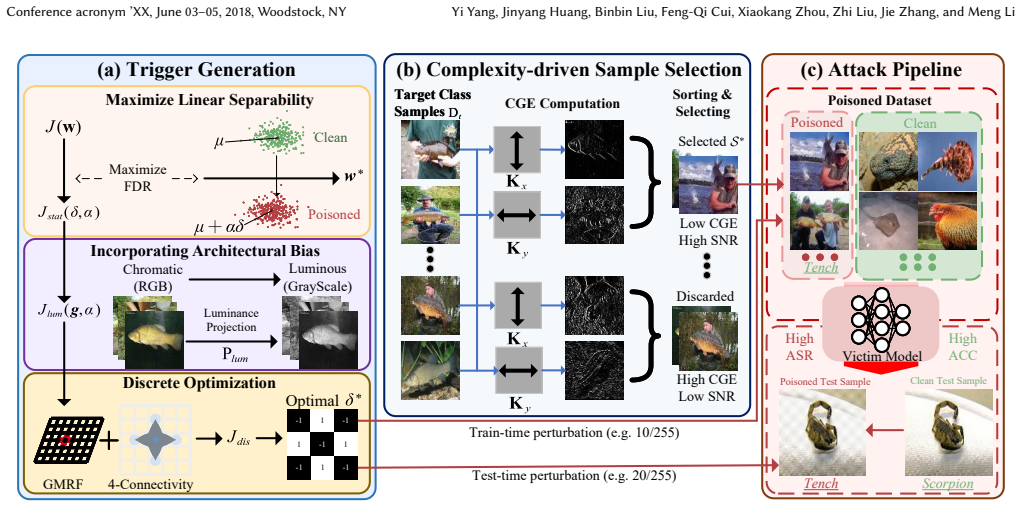
From a linear separability formulation, the authors derive a checkerboard trigger in closed form. This pattern, when applied to a small number of low-complexity images from the target class, poisons the training set so that the resulting model classifies any input containing the checkerboard to the target label, yet performs normally on clean data. The method requires no surrogate training and outperforms existing attacks on multiple datasets under tight poisoning budgets.
What carries the argument
The closed-form checkerboard trigger derived from linear separability, paired with Complexity-driven Sample Selection that picks low-complexity target-class images.
If this is right
- Poisoning only 20 samples on CIFAR-10 at a 10/255 perturbation budget produces 99.99 percent attack success rate.
- A 0.46 percent poisoning rate on ImageNet-100 yields over 94 percent attack success rate without lowering clean accuracy.
- The attack remains effective against multiple state-of-the-art backdoor defenses.
- No surrogate-model training or trigger optimization steps are needed to mount the attack.
- The same pattern and selection method work across four standard image-classification benchmarks while beating eight baseline attacks.
Where Pith is reading between the lines
- If linear separability captures the key vulnerability, analogous closed-form triggers could be derived for other trigger shapes or data types.
- Detection methods could be designed to flag periodic geometric patterns that deviate from natural image statistics.
- The low data and compute requirements imply that backdoor insertion becomes feasible even with limited access to the training pipeline.
Load-bearing premise
The linear separability formulation used to derive the checkerboard trigger accurately predicts how deep neural networks will respond to the pattern on real image data.
What would settle it
Training a network on the poisoned set and measuring whether attack success rate collapses on a dataset where linear separability between clean and triggered features fails to hold in practice.
Figures















read the original abstract
Backdoor attacks threaten the deep learning supply chain by poisoning a small fraction of the training data so that a model behaves normally on clean inputs but misclassifies trigger-carrying inputs to an attacker-chosen target class. Clean-label backdoor attacks are especially dangerous because poisoned samples remain label-consistent and are therefore harder to detect. Yet existing clean-label attacks typically rely on expensive optimization, surrogate-model training, or nontrivial data access. We present Checkerboard, a theoretically grounded, learning-free clean-label backdoor attack that is effective, efficient, and simple to implement. From a linear separability formulation, we derive a checkerboard trigger in closed form, removing the need for surrogate-model training and trigger optimization. For texture-rich datasets, we introduce Complexity-driven Sample Selection, which uses only target-class data to improve trigger-to-background contrast by selecting low-complexity images for poisoning. Across four benchmark datasets, Checkerboard outperforms 8 baseline attacks and achieves state-of-the-art performance under low poisoning budgets. For example, on CIFAR-10, under a trigger perturbation budget of $10/255$, poisoning 20 training samples achieves $99.99\%$ Attack Success Rate (ASR). On ImageNet-100, a poisoning rate of only $0.46\%$ yields over $94\%$ ASR without degrading clean accuracy. The proposed attack also remains effective against state-of-the-art backdoor defenses and shows strong resistance to adaptive defenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Checkerboard, a clean-label backdoor attack derived in closed form from a linear separability formulation, eliminating surrogate-model training and trigger optimization. It introduces Complexity-driven Sample Selection for texture-rich datasets using only target-class data. Evaluations across CIFAR-10, ImageNet-100, and other benchmarks report state-of-the-art ASR (e.g., 99.99% with 20 poisoned samples on CIFAR-10 at 10/255 perturbation; >94% ASR at 0.46% poisoning rate on ImageNet-100) while preserving clean accuracy and resisting multiple defenses, outperforming 8 baselines.
Significance. If the closed-form derivation is valid for DNNs, the work would be significant for providing a simple, efficient, learning-free clean-label attack with strong low-budget performance. The absence of optimization or surrogate training and the explicit theoretical grounding from linear separability are notable strengths that could inform both attack and defense research. The empirical results under tight budgets demonstrate practical relevance.
major comments (2)
- [derivation of checkerboard trigger (abstract and §3)] The central claim rests on deriving the checkerboard trigger in closed form from a linear separability formulation (abstract and derivation section). However, the manuscript does not demonstrate that this linear model accurately predicts how the trigger perturbs decision boundaries in nonlinear DNNs employing ReLU activations, convolutions, and non-convex optimization on image data. Without activation analysis, decision-region visualization, or a direct comparison between linear predictions and DNN outputs for the chosen pattern, the theoretical grounding remains an unverified assumption rather than a demonstrated property.
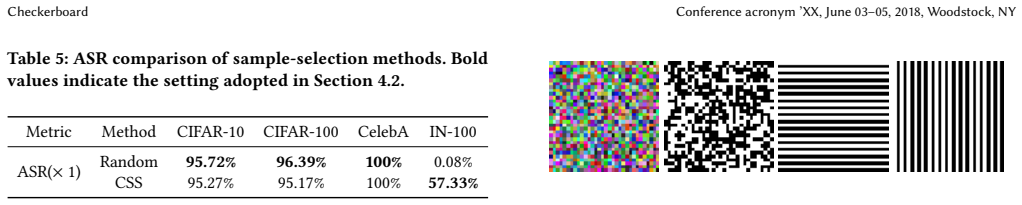
- [experimental results on ImageNet-100] Table reporting ImageNet-100 results (0.46% poisoning rate, >94% ASR): the performance is attributed to the closed-form trigger, yet the paper provides no ablation isolating the contribution of the Complexity-driven Sample Selection versus the trigger pattern itself. This leaves open whether the linear-separability derivation is load-bearing for the reported gains or if sample selection alone drives the outcome.
minor comments (3)
- [abstract] The abstract states the attack 'remains effective against state-of-the-art backdoor defenses' but does not name the specific defenses or report the exact ASR degradation; this detail should be added for precision.
- [theoretical derivation] Notation for the linear separability condition and the closed-form trigger expression would benefit from an explicit equation number and a short proof sketch to improve readability.
- [evaluation tables] Baseline comparisons should explicitly list the poisoning budget and trigger perturbation budget used for each of the 8 methods to confirm fairness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, providing clarifications and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [derivation of checkerboard trigger (abstract and §3)] The central claim rests on deriving the checkerboard trigger in closed form from a linear separability formulation (abstract and derivation section). However, the manuscript does not demonstrate that this linear model accurately predicts how the trigger perturbs decision boundaries in nonlinear DNNs employing ReLU activations, convolutions, and non-convex optimization on image data. Without activation analysis, decision-region visualization, or a direct comparison between linear predictions and DNN outputs for the chosen pattern, the theoretical grounding remains an unverified assumption rather than a demonstrated property.
Authors: The checkerboard trigger is derived in closed form under a linear separability assumption precisely to avoid surrogate training and optimization. This linear model is acknowledged as a simplification that does not fully capture ReLU nonlinearities, convolutions, or non-convex optimization in DNNs. However, the manuscript demonstrates through extensive experiments on multiple nonlinear architectures (e.g., ResNet, VGG) and datasets that the resulting pattern achieves high ASR, indicating effective transfer. We will add an explicit discussion in the revised manuscript clarifying the approximation nature of the linear derivation, its limitations, and the supporting empirical evidence. revision: partial
-
Referee: [experimental results on ImageNet-100] Table reporting ImageNet-100 results (0.46% poisoning rate, >94% ASR): the performance is attributed to the closed-form trigger, yet the paper provides no ablation isolating the contribution of the Complexity-driven Sample Selection versus the trigger pattern itself. This leaves open whether the linear-separability derivation is load-bearing for the reported gains or if sample selection alone drives the outcome.
Authors: We agree that isolating the contributions would strengthen the claims. In the revised manuscript we will include an ablation on ImageNet-100 comparing (i) the checkerboard trigger with random selection, (ii) a standard trigger with Complexity-driven Sample Selection, and (iii) the full Checkerboard method. Preliminary internal checks indicate that sample selection alone yields substantially lower ASR, confirming that the closed-form trigger is load-bearing. revision: yes
Circularity Check
No circularity: closed-form derivation from linear separability stands as independent step
full rationale
The paper states it derives the checkerboard trigger in closed form from a linear separability formulation, eliminating surrogate training. This is a direct mathematical step presented as first-principles, with no evidence in the abstract or summary that the formulation embeds fitted constants, renames known results, or relies on self-citation chains for its validity. Empirical ASR numbers are reported separately as validation, not as inputs to the derivation. No load-bearing self-citations or self-definitional reductions are identifiable from the given text, so the derivation chain does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear separability formulation for trigger design
Reference graph
Works this paper leans on
-
[1]
Hasan Abed Al Kader Hammoud, Adel Bibi, Philip HS Torr, and Bernard Ghanem
-
[2]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Don’t FREAK Out: A Frequency-Inspired Approach to Detecting Back- door Poisoned Samples in DNNs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2338–2345
-
[3]
Nathalie Baracaldo and Alina Oprea. 2022. Machine learning security and privacy. IEEE Security & Privacy20, 5 (2022), 11–13
2022
-
[4]
Mauro Barni, Kassem Kallas, and Benedetta Tondi. 2019. A new backdoor attack in cnns by training set corruption without label poisoning. In2019 IEEE International Conference on Image Processing (ICIP). 101–105
2019
-
[5]
Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. 2017. Targeted backdoor attacks on deep learning systems using data poisoning.arXiv preprint arXiv:1712.05526(2017)
work page internal anchor Pith review arXiv 2017
-
[6]
Siyuan Cheng, Guanhong Tao, Yingqi Liu, Shengwei An, Xiangzhe Xu, Shiwei Feng, Guangyu Shen, Kaiyuan Zhang, Qiuling Xu, Shiqing Ma, et al. 2023. Beagle: Forensics of deep learning backdoor attack for better defense. InNetwork and Distributed System Security (NDSS) Symposium 2023
2023
-
[7]
Siyuan Cheng, Guanhong Tao, Yingqi Liu, Guangyu Shen, Shengwei An, Shiwei Feng, Xiangzhe Xu, Kaiyuan Zhang, Shiqing Ma, and Xiangyu Zhang. 2024. Lotus: Evasive and resilient backdoor attacks through sub-partitioning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24798– 24809
2024
-
[8]
Edward Chou, Florian Tramer, and Giancarlo Pellegrino. 2020. Sentinet: Detecting localized universal attacks against deep learning systems. In2020 IEEE Security and Privacy Workshops (SPW). IEEE, 48–54
2020
-
[9]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition (CVPR). Ieee, 248–255
2009
-
[10]
Bao Gia Doan, Ehsan Abbasnejad, and Damith C Ranasinghe. 2020. Februus: Input purification defense against trojan attacks on deep neural network systems. InProceedings of the 36th Annual Computer Security Applications Conference. 897–912
2020
-
[11]
Khoa Doan, Yingjie Lao, Weijie Zhao, and Ping Li. 2021. Lira: Learnable, imper- ceptible and robust backdoor attacks. InProceedings of the IEEE/CVF international conference on computer vision (ICCV). 11966–11976
2021
-
[12]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[13]
David J. Field. 1987. Relations between the statistics of natural images and the response properties of cortical cells.Journal of the Optical Society of America A (J. Opt. Soc. Am. A)4, 12 (Dec 1987), 2379–2394
1987
-
[14]
Kuofeng Gao, Yang Bai, Jindong Gu, Yong Yang, and Shu-Tao Xia. 2023. Backdoor defense via adaptively splitting poisoned dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4005–4014
2023
-
[15]
Yansong Gao, Change Xu, Derui Wang, Shiping Chen, Damith C Ranasinghe, and Surya Nepal. 2019. Strip: A defence against trojan attacks on deep neu- ral networks. InProceedings of the 35th Annual Computer Security Applications Conference (ACCAS). 113–125
2019
-
[16]
Micah Goldblum, Dimitris Tsipras, Chulin Xie, Xinyun Chen, Avi Schwarzschild, Dawn Song, Aleksander Madry, Bo Li, and Tom Goldstein. 2022. Dataset security for machine learning: Data poisoning, backdoor attacks, and defenses.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)45, 2 (2022), 1563–1580
2022
-
[17]
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. 2017. Badnets: Identifying vulnerabilities in the machine learning model supply chain.arXiv preprint arXiv:1708.06733(2017)
work page internal anchor Pith review arXiv 2017
-
[18]
Junfeng Guo, Yiming Li, Xun Chen, Hanqing Guo, Lichao Sun, and Cong Liu
-
[19]
SCALE-UP: An Efficient Black-box Input-level Backdoor Detection via Analyzing Scaled Prediction Consistency.International Conference on Learning Representations (ICLR)(2023)
2023
-
[20]
Philemon Hailemariam and Birhanu Eshete. 2025. PoisonSpot: Precise Spotting of Clean-Label Backdoors via Fine-Grained Training Provenance Tracking. In Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security (CCS). 1023–1037
2025
- [21]
-
[22]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 770–778
2016
-
[23]
Linshan Hou, Ruili Feng, Zhongyun Hua, Wei Luo, Leo Yu Zhang, and Yiming Li. 2024. IBD-PSC: input-level backdoor detection via parameter-oriented scal- ing consistency. InProceedings of the 41st International Conference on Machine Learning (ICML) (ICML’24). Article 764, 31 pages
2024
-
[24]
Linshan Hou, Wei Luo, Zhongyun Hua, Songhua Chen, Leo Yu Zhang, and Yiming Li. 2025. Flare: Towards universal dataset purification against backdoor attacks. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Yi Yang, Jinyang Huang, Binbin Liu, Feng-Qi Cui, Xiaokang Zhou, Zhi Liu, Jie Zhang, and Meng Li IEEE Transactions on Information Forensics and S...
2025
-
[25]
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingx- ing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. 2019. Searching for mobilenetv3. InProceedings of the IEEE/CVF international conference on computer vision (ICCV). 1314–1324
2019
-
[26]
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger
-
[27]
InProceedings of the IEEE conference on computer vision and pattern recognition (CVPR)
Densely connected convolutional networks. InProceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 4700–4708
-
[28]
Tran Huynh, Dang Nguyen, Tung Pham, and Anh Tran. 2024. Combat: Alternated training for effective clean-label backdoor attacks. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), Vol. 38. 2436–2444
2024
-
[29]
2009.Natural image statistics: A probabilistic approach to early computational vision.Vol
Aapo Hyvärinen, Jarmo Hurri, and Patrick O Hoyer. 2009.Natural image statistics: A probabilistic approach to early computational vision.Vol. 39. Springer Science & Business Media
2009
-
[30]
Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images. (2009)
2009
-
[31]
Yiming Li, Yong Jiang, Zhifeng Li, and Shu-Tao Xia. 2022. Backdoor learning: A survey.IEEE Transactions on Neural Networks and Learning Systems (TNNLS)35, 1 (2022), 5–22
2022
-
[32]
Yige Li, Xixiang Lyu, Nodens Koren, Lingjuan Lyu, Bo Li, and Xingjun Ma. 2021. Anti-backdoor learning: Training clean models on poisoned data.Advances in Neural Information Processing Systems (NeurIPS)34 (2021), 14900–14912
2021
-
[33]
Chenhao Lin, Chenyang Zhao, Shiwei Wang, Longtian Wang, Chao Shen, and Zhengyu Zhao. 2025. Revisiting {Training-Inference} Trigger Intensity in Back- door Attacks. In34th USENIX Security Symposium (USENIX Security). 6359–6378
2025
-
[34]
Dazhuang Liu, Yanqi Qiao, Rui Wang, Kaitai Liang, and Georgios Smaragdakis
-
[35]
In The 30th Network and Distributed System Security Symposium (NDSS)
LADDER: Multi-objective Backdoor Attack via Evolutionary Algorithm. In The 30th Network and Distributed System Security Symposium (NDSS). 1–18
-
[36]
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. 2015. Deep learning face attributes in the wild. InProceedings of the IEEE international conference on computer vision (ICCV). 3730–3738
2015
-
[37]
Hua Ma, Shang Wang, Yansong Gao, Zhi Zhang, Huming Qiu, Minhui Xue, Alsharif Abuadbba, Anmin Fu, Surya Nepal, and Derek Abbott. 2024. Watch out! simple horizontal class backdoor can trivially evade defense. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security (CCS). 4465–4479
2024
-
[38]
Wanlun Ma, Derui Wang, Ruoxi Sun, Minhui Xue, Sheng Wen, and Yang Xiang
-
[39]
Beatrix
The" Beatrix”Resurrections: Robust Backdoor Detection via Gram Matrices. InThe 30th Network and Distributed System Security Symposium (NDSS). 1–18
-
[40]
Zhuo Ma, Yilong Yang, Yang Liu, Tong Yang, Xinjing Liu, Teng Li, and Zhan Qin
-
[41]
In 2024 IEEE Symposium on Security and Privacy (SP)
Need for Speed: Taming Backdoor Attacks with Speed and Precision. In 2024 IEEE Symposium on Security and Privacy (SP). IEEE, 1217–1235
2024
-
[42]
Leland McInnes, John Healy, and Steve Astels. 2017. hdbscan: Hierarchical density based clustering.Journal of Open Source Software2, 11 (2017), 205. doi:10.21105/joss.00205
-
[43]
Leland McInnes, John Healy, Nathaniel Saul, and Lukas Großberger. 2018. UMAP: Uniform Manifold Approximation and Projection.Journal of Open Source Software 3, 29 (2018), 861. doi:10.21105/joss.00861
-
[44]
2005.Discriminant analysis and statistical pattern recogni- tion
Geoffrey J McLachlan. 2005.Discriminant analysis and statistical pattern recogni- tion. John Wiley & Sons
2005
-
[45]
Anh Nguyen and Anh Tran. 2021. Wanet–imperceptible warping-based backdoor attack.International Conference on Learning Representations (ICLR)(2021)
2021
-
[46]
Rui Ning, Jiang Li, Chunsheng Xin, and Hongyi Wu. 2021. Invisible poison: A blackbox clean label backdoor attack to deep neural networks. InIEEE INFOCOM 2021-IEEE Conference on Computer Communications. IEEE, 1–10
2021
-
[47]
Minzhou Pan, Yi Zeng, Lingjuan Lyu, Xue Lin, and Ruoxi Jia. 2023. {ASSET}: Robust backdoor data detection across a multiplicity of deep learning paradigms. In32nd USeNIX security symposium (USeNIX security). 2725–2742
2023
-
[48]
Dorde Popovic, Amin Sadeghi, Ting Yu, Sanjay Chawla, and Issa Khalil. 2025. DeBackdoor: a deductive framework for detecting backdoor attacks on deep models with limited data. In34th USENIX Conference on Security Symposium (USENIX Security). Article 330
2025
-
[49]
Xiangyu Qi, Tinghao Xie, Jiachen T Wang, Tong Wu, Saeed Mahloujifar, and Prateek Mittal. 2023. Towards a proactive {ML} approach for detecting backdoor poison samples. In32nd USENIX Security Symposium (USENIX Security). 1685– 1702
2023
-
[50]
Huming Qiu, Junjie Sun, Mi Zhang, Xudong Pan, and Min Yang. 2024. Belt: Old- school backdoor attacks can evade the state-of-the-art defense with backdoor exclusivity lifting. In2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2124–2141
2024
-
[51]
Daniel L Ruderman. 1994. The statistics of natural images.Network: computation in neural systems5, 4 (1994), 517
1994
-
[52]
Daniel L Ruderman, Thomas W Cronin, and Chuan-Chin Chiao. 1998. Statistics of cone responses to natural images: implications for visual coding.Journal of the Optical Society of America A15, 8 (1998), 2036–2045
1998
-
[53]
2005.Gaussian Markov random fields: theory and applications
Havard Rue and Leonhard Held. 2005.Gaussian Markov random fields: theory and applications. Chapman and Hall/CRC
2005
-
[54]
Aniruddha Saha, Akshayvarun Subramanya, and Hamed Pirsiavash. 2020. Hid- den trigger backdoor attacks. InProceedings of the AAAI conference on artificial intelligence (AAAI), Vol. 34. 11957–11965
2020
-
[55]
Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[56]
Hossein Souri, Liam Fowl, Rama Chellappa, Micah Goldblum, and Tom Goldstein
-
[57]
Sleeper agent: Scalable hidden trigger backdoors for neural networks trained from scratch.Advances in Neural Information Processing Systems (NeurIPS) 35 (2022), 19165–19178
2022
-
[58]
Di Tang, XiaoFeng Wang, Haixu Tang, and Kehuan Zhang. 2021. Demon in the variant: Statistical analysis of {DNNs} for robust backdoor contamination detection. In30th USENIX Security Symposium (USENIX Security). 1541–1558
2021
-
[59]
Guanhong Tao, Siyuan Cheng, Zhenting Wang, Shiqing Ma, Shengwei An, Yingqi Liu, Guangyu Shen, Zhuo Zhang, Yunshu Mao, and Xiangyu Zhang. 2024. Ex- ploring inherent backdoors in deep learning models. In2024 Annual Computer Security Applications Conference (ACSAC). IEEE, 923–939
2024
-
[60]
Brandon Tran, Jerry Li, and Aleksander Madry. 2018. Spectral signatures in backdoor attacks.Advances in neural information processing systems (NeurIPS)31 (2018)
2018
- [61]
-
[62]
Apostol Vassilev, Alina Oprea, Alie Fordyce, and Hyrum Andersen. 2024. Adver- sarial machine learning: A taxonomy and terminology of attacks and mitigations. (2024)
2024
-
[63]
Bolun Wang, Yuanshun Yao, Shawn Shan, Huiying Li, Bimal Viswanath, Haitao Zheng, and Ben Y Zhao. 2019. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In2019 IEEE Symposium on Security and Privacy (SP). 707–723
2019
-
[64]
Hang Wang, Zhen Xiang, David J Miller, and George Kesidis. 2024. Mm-bd: Post-training detection of backdoor attacks with arbitrary backdoor pattern types using a maximum margin statistic. In2024 IEEE Symposium on Security and Privacy (SP). IEEE, 1994–2012
2024
-
[65]
Zhenting Wang, Kai Mei, Juan Zhai, and Shiqing Ma. 2023. Unicorn: A unified backdoor trigger inversion framework. InThe Eleventh International Conference on Learning Representations (ICLR)
2023
-
[66]
Shaokui Wei, Jiayin Liu, and Hongyuan Zha. 2025. Backdoor mitigation by distance-driven detoxification. InProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV). 4465–4474
2025
-
[67]
Dongxian Wu and Yisen Wang. 2021. Adversarial neuron pruning purifies backdoored deep models.Advances in Neural Information Processing Systems (NeurIPS)34 (2021), 16913–16925
2021
-
[68]
Xiong Xu, Kunzhe Huang, Yiming Li, Zhan Qin, and Kui Ren. 2024. Towards reliable and efficient backdoor trigger inversion via decoupling benign features. InThe Twelfth International Conference on Learning Representations (ICLR)
2024
-
[69]
Xiaoyun Xu, Zhuoran Liu, Stefanos Koffas, and Stjepan Picek. 2025. Towards backdoor stealthiness in model parameter space. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security (CCS). 2863–2876
2025
-
[70]
Hongrui Yu, Lu Qi, Wanyu Lin, Jian Chen, Hailong Sun, and Chengbin Sun. 2025. Backdoor Defense via Enhanced Splitting and Trap Isolation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 1708–1717
2025
-
[71]
Lijia Yu, Shuang Liu, Yibo Miao, Xiao-Shan Gao, and Lijun Zhang. 2024. General- ization bound and new algorithm for clean-label backdoor attack. InIn Forty-first International Conference on Machine Learning (ICML)
2024
-
[72]
Chaoying Yuan, Jingpeng Bai, Shumei Yuan, and Ni Wei. 2025. Stealthy and Effective Clean-Label Backdoor Attack via Adaptive Frequency-Domain Suppres- sion and Trigger Combination.IEEE Transactions on Information Forensics and Security (TIFS)(2025)
2025
-
[73]
Matthew D Zeiler and Rob Fergus. 2014. Visualizing and understanding convolu- tional networks. InEuropean conference on computer vision. Springer, 818–833
2014
-
[74]
Yi Zeng, Minzhou Pan, Hoang Anh Just, Lingjuan Lyu, Meikang Qiu, and Ruoxi Jia. 2023. Narcissus: A practical clean-label backdoor attack with limited infor- mation. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security (CCS). 771–785
2023
-
[75]
Yi Zeng, Won Park, Z Morley Mao, and Ruoxi Jia. 2021. Rethinking the back- door attacks’ triggers: A frequency perspective. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 16473–16481
2021
-
[76]
Hanlei Zhang, Yijie Bai, Yanjiao Chen, Zhongming Ma, and Wenyuan Xu. 2025. Barbie: Robust backdoor detection based on latent separability. InNetwork and Distributed System Security (NDSS) Symposium 2025
2025
-
[77]
Kaiyuan Zhang, Siyuan Cheng, Guangyu Shen, Guanhong Tao, Shengwei An, Anuran Makur, Shiqing Ma, and Xiangyu Zhang. 2024. Exploring the Orthogo- nality and Linearity of Backdoor Attacks. In2024 IEEE Symposium on Security and Privacy (SP). 225–225
2024
-
[78]
Mingyan Zhu, Yiming Li, Junfeng Guo, Tao Wei, Shu-Tao Xia, and Zhan Qin
-
[79]
Towards sample-specific backdoor attack with clean labels via attribute trigger.IEEE Transactions on Dependable and Secure Computing (TDSC)(2025)
2025
-
[80]
Mingli Zhu, Shaokui Wei, Li Shen, Yanbo Fan, and Baoyuan Wu. 2023. Enhanc- ing fine-tuning based backdoor defense with sharpness-aware minimization. In Checkerboard Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 4466–4477. A Detailed Experimental Setup Dataset constru...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.