Recognition: unknown
A Multi-View Media Profiling Suite: Resources, Evaluation, and Analysis
Pith reviewed 2026-05-09 15:19 UTC · model grok-4.3
The pith
Multi-view representations from graphs, articles and descriptions set new standards for predicting news outlet bias and factuality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce MBFC-2025, a label set for approximately 2,600 outlets drawn from Media Bias/Fact Check, and construct multi-view representations spanning Alexa graphs, hyperlink graphs, LLM-derived graphs, articles, and Wikipedia descriptions for both the ACL-2020 collection of around 900 outlets and MBFC-2025. Systematic evaluation of the individual views and several fusion strategies, including a reinforcement-learning variant, yields state-of-the-art results on ACL-2020 and establishes strong benchmarks on MBFC-2025.
What carries the argument
Multi-view embeddings drawn from Alexa graphs, hyperlink graphs, LLM-derived graphs, articles, and Wikipedia descriptions, combined through learned fusion strategies including reinforcement learning.
If this is right
- Automated profiling can now cover thousands more outlets than earlier single-view systems.
- Combining structural graph views with content and knowledge views consistently outperforms any single view alone.
- Reinforcement learning provides an effective way to learn how to weight the different views for each prediction task.
- The new MBFC-2025 resource supports future work on label-sparse or highly diverse outlet collections.
Where Pith is reading between the lines
- If the approach scales, it could support near-real-time monitoring of new or low-coverage outlets as they appear online.
- The results suggest that relational signals from hyperlink and traffic graphs capture bias patterns invisible in text alone.
- Similar multi-view fusion might be tested on social-media accounts or in languages beyond English to check for consistent patterns.
Load-bearing premise
The MBFC labels accurately reflect true bias and factuality levels, and the chosen multi-view representations plus fusion strategies capture the key signals needed for reliable prediction across diverse outlets.
What would settle it
An independent human rating study or cross-check against verified fact-checker verdicts on a held-out sample of outlets that were not used to train or tune the models.
Figures



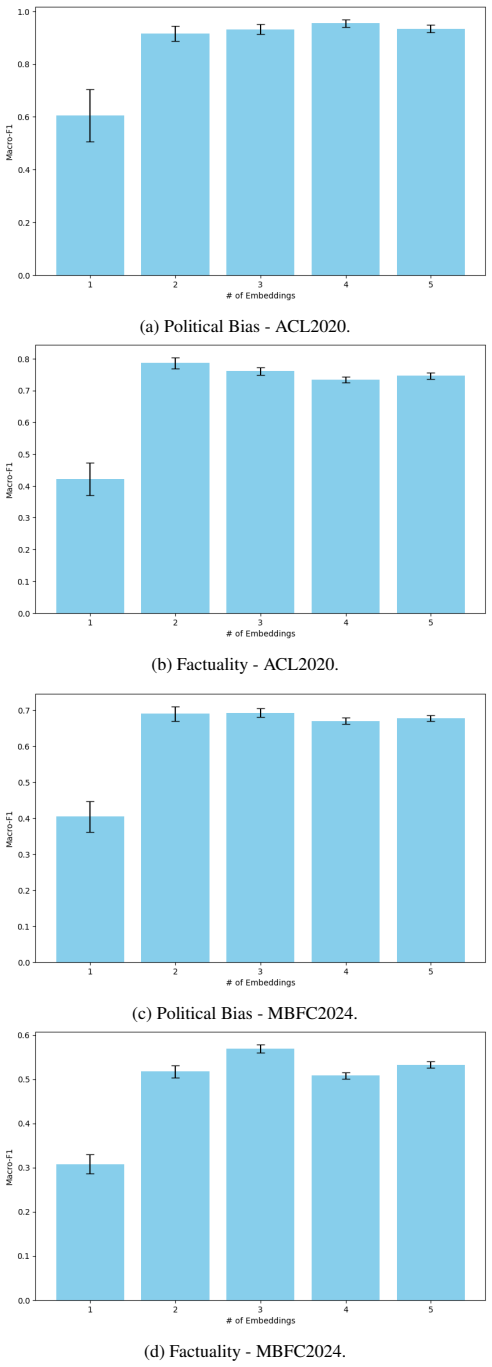
read the original abstract
News outlets shape public opinion at a scale that makes automated detection of political bias and factuality essential. However, the field still lacks unified resources, comprehensive evaluations across diverse approaches, and systematic analyses of the representations and fusion strategies that matter most, especially under label sparsity and dataset diversity. In addition, there is little empirical work reporting broad, observation-driven findings about what consistently works, what fails, and why. We address these gaps through four main contributions. First, we introduce MBFC-2025, a large-scale label set covering approximately 2,600 outlets from Media Bias/Fact Check (MBFC). Second, we construct multiview representations for ACL-2020 (Panayotov et al., 2022), which includes around 900 outlets, as well as for MBFC-2025. These representations span Alexa graphs, hyperlink graphs, LLM-derived graphs, articles, and Wikipedia descriptions. Third, we provide a systematic evaluation and analysis of embedding views and fusion strategies, including a reinforcement learning-based fusion variant. Fourth, we conduct extensive experiments that achieve state-of-the-art results on ACL-2020 and establish strong benchmarks on MBFC-2025.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MBFC-2025, a new label set for ~2,600 news outlets drawn from Media Bias/Fact Check, constructs multi-view representations (Alexa graphs, hyperlink graphs, LLM-derived graphs, articles, Wikipedia descriptions) for both this dataset and the existing ACL-2020 set (~900 outlets), performs a systematic evaluation of embedding views and fusion strategies (including an RL-based fusion variant), and reports state-of-the-art results on ACL-2020 together with new benchmarks on MBFC-2025.
Significance. If the empirical claims hold after verification, the work would be significant as a resource contribution that supplies a large new labeled collection and an observation-driven comparison of multi-view inputs and fusion methods for media bias and factuality prediction, addressing the noted lack of unified resources and broad analyses in the area.
major comments (3)
- [§3] §3 (MBFC-2025 construction): The manuscript treats MBFC ratings as ground-truth targets for bias and factuality without reporting any external validation, inter-rater reliability statistics, or comparison against alternative annotation sources. Because the central benchmark claims rest on performance against these labels (especially the newly introduced MBFC-2025 set), the absence of such checks is load-bearing for interpreting the reported results as capturing genuine media properties rather than dataset-specific artifacts.
- [§5] §5 (Experiments and results): The abstract asserts SOTA performance on ACL-2020 and strong benchmarks on MBFC-2025, yet the text supplies no equations for the fusion methods, no ablation tables, no error bars, no explicit data-split descriptions, and no detailed baseline comparisons. Without these elements the empirical claims cannot be verified or reproduced from the manuscript.
- [§4.3] §4.3 (RL-based fusion): The reinforcement-learning fusion variant is presented as a contribution, but the description lacks the state/action/reward formulation, policy details, or comparison metrics that would establish whether it meaningfully outperforms standard fusion strategies. This detail is required to support the claim that the multi-view suite includes effective new fusion approaches.
minor comments (2)
- [Abstract] The abstract introduces acronyms (ACL-2020, MBFC-2025) without spelling them out on first use.
- [Figures/Tables] Figure and table captions could more explicitly state the evaluation metric (e.g., accuracy, F1, or MAE) used for each reported number.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating the revisions we will incorporate to improve clarity, reproducibility, and rigor.
read point-by-point responses
-
Referee: §3 (MBFC-2025 construction): The manuscript treats MBFC ratings as ground-truth targets for bias and factuality without reporting any external validation, inter-rater reliability statistics, or comparison against alternative annotation sources. Because the central benchmark claims rest on performance against these labels (especially the newly introduced MBFC-2025 set), the absence of such checks is load-bearing for interpreting the reported results as capturing genuine media properties rather than dataset-specific artifacts.
Authors: We acknowledge that the manuscript relies on MBFC labels without new external validation or inter-rater statistics. MBFC is a standard, widely used source in media bias research (including the ACL-2020 dataset we compare against), and prior work has examined its alignment with other annotations. To address the concern directly, we will add a new paragraph in §3 summarizing known properties and limitations of MBFC labels, with citations to external studies comparing MBFC to crowdsourced or alternative sources. We will also add an explicit limitations subsection noting that our benchmarks reflect performance against these established labels rather than newly validated ground truth. New inter-rater studies fall outside the scope of this resource-focused paper. revision: partial
-
Referee: §5 (Experiments and results): The abstract asserts SOTA performance on ACL-2020 and strong benchmarks on MBFC-2025, yet the text supplies no equations for the fusion methods, no ablation tables, no error bars, no explicit data-split descriptions, and no detailed baseline comparisons. Without these elements the empirical claims cannot be verified or reproduced from the manuscript.
Authors: We agree that the current experimental section lacks critical details for verification and reproducibility. In the revised manuscript we will expand §5 to include: (i) the full mathematical formulations and equations for every fusion method; (ii) comprehensive ablation tables for all view combinations and fusion strategies; (iii) error bars from multiple runs with different random seeds; (iv) explicit train/validation/test split descriptions (including how outlets were partitioned); and (v) more detailed baseline comparisons with prior methods on ACL-2020. These additions will make the SOTA claims and new MBFC-2025 benchmarks fully verifiable. revision: yes
-
Referee: §4.3 (RL-based fusion): The reinforcement-learning fusion variant is presented as a contribution, but the description lacks the state/action/reward formulation, policy details, or comparison metrics that would establish whether it meaningfully outperforms standard fusion strategies. This detail is required to support the claim that the multi-view suite includes effective new fusion approaches.
Authors: We concur that the RL fusion description is too brief. We will substantially expand §4.3 to provide the complete state/action/reward formulation, policy network architecture and training details, and quantitative comparisons against standard fusion baselines (concatenation, averaging, attention). These additions will demonstrate whether and why the RL variant contributes meaningfully to the multi-view suite. revision: yes
Circularity Check
No significant circularity: standard empirical evaluation on external labels
full rationale
The paper introduces MBFC-2025 as an external label set from Media Bias/Fact Check and constructs multi-view inputs (Alexa, hyperlink, LLM graphs, articles, Wikipedia) for both this set and the prior ACL-2020 benchmark. It then trains and evaluates standard embedding and fusion models (including an RL variant) to predict the provided labels, reporting SOTA on ACL-2020 and benchmarks on MBFC-2025. No equations, predictions, or central claims reduce by construction to fitted parameters defined from the same outputs; performance is measured on held-out splits against independent external annotations. No self-citation load-bearing uniqueness theorems, ansatzes smuggled via citation, or self-definitional loops appear. This is self-contained supervised evaluation work.
Axiom & Free-Parameter Ledger
free parameters (1)
- embedding and fusion hyperparameters
axioms (1)
- domain assumption MBFC-2025 labels serve as reliable ground truth for bias and factuality
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. https://arxiv.org/abs/2303.08774 GPT-4 technical report . arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Dilshod Azizov, Preslav Nakov, and Shangsong Liang. 2023. https://ceur-ws.org/Vol-3497/paper-025.pdf Frank at checkthat!-2023: Detecting the political bias of news articles and news media . In Working Notes of the Conference and Labs of the Evaluation Forum (CLEF 2023), Thessaloniki, Greece, September 18th to 21st, 2023 , CEUR Workshop Proceedings, pages ...
2023
-
[9]
Cheema, Dilshod Azizov, and Preslav Nakov
Alberto Barr \' o n - Cede \ n o, Firoj Alam, Tommaso Caselli, Giovanni Da San Martino, Tamer Elsayed, Andrea Galassi, Fatima Haouari, Federico Ruggeri, Julia Maria Stru , Rabindra Nath Nandi, Gullal S. Cheema, Dilshod Azizov, and Preslav Nakov. 2023 a . https://doi.org/10.1007/978-3-031-28241-6\_59 The CLEF-2023 checkthat! lab: Checkworthiness, subjectiv...
-
[10]
Alberto Barr \' o n - Cede \ n o, Firoj Alam, Andrea Galassi, Giovanni Da San Martino, Preslav Nakov, Tamer Elsayed, Dilshod Azizov, Tommaso Caselli, Gullal S. Cheema, Fatima Haouari, Maram Hasanain, M \" u cahid Kutlu, Chengkai Li, Federico Ruggeri, Julia Maria Stru , and Wajdi Zaghouani. 2023 b . https://doi.org/10.1007/978-3-031-42448-9\_20 Overview of...
-
[11]
Mont \' u far, Pietro Li \' o , and Michael M
Cristian Bodnar, Fabrizio Frasca, Yuguang Wang, Nina Otter, Guido F. Mont \' u far, Pietro Li \' o , and Michael M. Bronstein. 2021. http://proceedings.mlr.press/v139/bodnar21a.html Weisfeiler and lehman go topological: Message passing simplicial networks . In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021...
2021
-
[12]
Michael P Boyle, Mike Schmierbach, and Douglas M McLeod. 2007. Ideology, issues, and limited information: Implications for voting behavior. Atlantic Journal of Communication, 15(4):284--302
2007
- [13]
-
[14]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gr...
2020
-
[15]
Sergio Burdisso, Dairazalia Sanchez-cortes, Esa \'u Villatoro-tello, and Petr Motlicek. 2024. https://aclanthology.org/2024.naacl-long.383 Reliability estimation of news media sources: Birds of a feather flock together . In Proceedings of the 2024 Conference of the North American Chapter of the Assoc. for Comp. Linguistics: Human Language Technologies (Vo...
2024
-
[17]
Nadia K Conroy, Victoria L Rubin, and Yimin Chen. 2015. https://doi.org/10.1002/pra2.2015.145052010082 Automatic deception detection: Methods for finding fake news . Proceedings of the Association for Information Science and Technology, 52(1):1--4
-
[20]
Kaize Ding, Zhe Xu, Hanghang Tong, and Huan Liu. 2022. https://doi.org/10.1145/3575637.3575646 Data augmentation for deep graph learning: A survey . SIGKDD Explorations Newsletter, pages 61--77
-
[21]
James N Druckman and Michael Parkin. 2005. The impact of media bias: How editorial slant affects voters. The Journal of Politics, 67(4):1030--1049
2005
-
[22]
James Fairbanks, Natalie Fitch, Nathan Knauf, and Erica Briscoe. 2018. http://jpfairbanks.net/doc/mis2news.pdf Credibility assessment in the news: do we need to read? In Proceedings of the MIS2 Workshop on 11th Int. Conf. on Web Search and Data Mining, WSDM'18, pages 799--800. ACM
2018
-
[23]
A Decision - Theoretic Generalization of On - Line Learning and an Application to Boosting
Yoav Freund and Robert E. Schapire. 1997. https://doi.org/10.1006/JCSS.1997.1504 A decision-theoretic generalization of on-line learning and an application to boosting . J. Comput. Syst. Sci., 55(1):119--139
-
[25]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. http://papers.neurips.cc/paper/6703-inductive-representation-learning-on-large-graphs.pdf Inductive representation learning on large graphs . In Proceedings of the 31st International Conference on Neural Information Processing Systems, volume 30 of NeurIPS'17, page 1025–1035, Long Beach, CA, USA. Curran...
2017
-
[26]
Hearst, Susan T Dumais, Edgar Osuna, John Platt, and Bernhard Scholkopf
Marti A. Hearst, Susan T Dumais, Edgar Osuna, John Platt, and Bernhard Scholkopf. 1998. Support vector machines. IEEE Intelligent Systems and their applications, 13(4):18--28
1998
-
[27]
Austin Hounsel, Jordan Holland, Ben Kaiser, Kevin Borgolte, Nick Feamster, and Jonathan Mayer. 2020. https://www.usenix.org/system/files/foci20-paper-hounsel.pdf Identifying disinformation websites using infrastructure features . In Proceedings of the 10th USENIX Workshop on Free and Open Communications on the Internet, FOCI'20, Virtual
2020
-
[28]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lo RA : Low-rank adaptation of large language models . In Proceedings of the International Conference on Learning Representations, ICLR '22, virtual
2022
-
[30]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. 2023. https://arxiv.org/abs/2310.06825 Mistral 7B . arXiv preprint arXiv:2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2020. https://openreview.net/forum?id=H1eA7AEtvS ALBERT : A lite BERT for self-supervised learning of language representations . In Proceedings of the International Conference on Learning Representations, ICLR'20
2020
-
[32]
Yuanyuan Lei and Ruihong Huang. 2024. https://doi.org/10.18653/v1/2024.naacl-long.292 Sentence-level media bias analysis with event relation graph . In Proceedings of the 2024 Conference of the North American Chapter of the Assoc. for Comp. Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL'24, pages 5225--5238, Mexico City, Mexico. ACL
-
[33]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. https://doi.org/10.18653/v1/2020.acl-main.703 BART : Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension . In Proceedings of the 58th Annual Meeting of the Assoc. f...
-
[34]
Luyang Lin, Lingzhi Wang, Xiaoyan Zhao, Jing Li, and Kam-Fai Wong. 2024. https://doi.org/10.18653/v1/2024.findings-eacl.70 I ndi V ec: An exploration of leveraging large language models for media bias detection with fine-grained bias indicators . In Findings of the Assoc. for Comp. Linguistics: EACL 2024, pages 1038--1050, St. Julian ' s, Malta. ACL
-
[35]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. https://arxiv.org/abs/1907.11692 RoBERTa : A robustly optimized BERT pretraining approach . arXiv preprint arXiv:1907.11692, abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[36]
Yujian Liu, Xinliang Frederick Zhang, David Wegsman, Nicholas Beauchamp, and Lu Wang. 2022. https://doi.org/10.18653/v1/2022.findings-naacl.101 POLITICS : Pretraining with same-story article comparison for ideology prediction and stance detection . In Findings of the Assoc. for Comp. Linguistics: NAACL 2022, Seattle, United States. Association for Computa...
-
[37]
Antonio Longa, Steve Azzolin, Gabriele Santin, Giulia Cencetti, Pietro Li \`o , Bruno Lepri, and Andrea Passerini. 2024. Explaining the explainers in graph neural networks: a comparative study. ACM Computing Surveys
2024
-
[39]
Iffat Maab, Edison Marrese-Taylor, Sebastian Pad \'o , and Yutaka Matsuo. 2024. https://doi.org/10.18653/v1/2024.naacl-long.227 Media bias detection across families of language models . In Proceedings of the 2024 Conference of the North American Chapter of the Assoc. for Comp. Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL'24, pag...
-
[40]
Muhammad Arslan Manzoor, Ruihong Zeng, Dilshod Azizov, Preslav Nakov, and Shangsong Liang. 2025. MGM : Global understanding of audience overlap graphs for predicting the factuality and the bias of news media. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Assoc. for Comp. Linguistics: Human Language Technologies (Volum...
2025
-
[41]
Giovanni Da San Martino, Firoj Alam, Maram Hasanain, Rabindra Nath Nandi, Dilshod Azizov, and Preslav Nakov. 2023. https://ceur-ws.org/Vol-3497/paper-021.pdf Overview of the CLEF-2023 checkthat! lab task 3 on political bias of news articles and news media . In Working Notes of the Conference and Labs of the Evaluation Forum (CLEF 2023), Thessaloniki, Gree...
2023
-
[42]
Nikhil Mehta and Dan Goldwasser. 2023. https://api.semanticscholar.org/CorpusID:261822509 An interactive framework for profiling news media sources . In North American Chapter of the Association for Computational Linguistics
2023
-
[46]
Subhabrata Mukherjee and Gerhard Weikum. 2015. https://doi.org/10.1145/2806416.2806537 Leveraging joint interactions for credibility analysis in news communities . In Proceedings of the 24th International Conference on Information and Knowledge Management, CIKM'15, pages 353--362, Melbourne, VIC, Australia. ACM
-
[48]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/b...
2022
-
[50]
Ver \'o nica P \'e rez-Rosas, Bennett Kleinberg, Alexandra Lefevre, and Rada Mihalcea. 2018. https://aclanthology.org/C18-1287/ Automatic detection of fake news . In Proceedings of the 27th International Conference on Computational Linguistics, CCL'18, pages 3391--3401, Santa Fe, New Mexico, USA. ACL
2018
-
[51]
Kashyap Popat, Subhabrata Mukherjee, Jannik Str \" o tgen, and Gerhard Weikum. 2017. https://dl.acm.org/doi/pdf/10.1145/3041021.3055133 Where the truth lies: Explaining the credibility of emerging claims on the W eb and social media . In WWW Companion, pages 1003--1012, Perth, Australia
-
[52]
Markus Prior. 2013. Media and political polarization. Annual review of political science, 16(1):101--127
2013
-
[53]
Changyuan Qiu, Winston Wu, Xinliang Frederick Zhang, and Lu Wang. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.659 Late fusion with triplet margin objective for multimodal ideology prediction and analysis . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP'22, pages 9720--9736, Abu Dhabi, United Arab Emi...
-
[54]
Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. 2021. http://jmlr.org/papers/v22/20-1364.html Stable-Baselines3 : Reliable reinforcement learning implementations . Journal of Machine Learning Research, 22(268):1--8
2021
-
[55]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. https://arxiv.org/abs/1910.01108 DistilBERT , a distilled version of bert: smaller, faster, cheaper and lighter . arXiv preprint arXiv:1910.01108
work page internal anchor Pith review arXiv 2019
-
[57]
Karen Sparck Jones. 1972. A statistical interpretation of term specificity and its application in retrieval. Journal of documentation, 28(1):11--21
1972
-
[58]
Ke Sun, Zhouchen Lin, and Zhanxing Zhu. 2020. https://arxiv.org/pdf/1902.11038.pdf Multi-stage self-supervised learning for graph convolutional networks on graphs with few labeled nodes . In Proceedings of the Conference on Artificial Intelligence, volume 34 of AAAI'20, pages 5892--5899
- [59]
-
[60]
Nurbek Tastan, Stefanos Laskaridis, Martin Tak \'a c , Karthik Nandakumar, and Samuel Horv \'a th. 2026 b . https://openreview.net/forum?id=86P3sb1dpr Lo FT : Low-rank adaptation that behaves like full fine-tuning . In The Fourteenth Int. Conf. on Learning Representations, ICLR'26, Rio de Janeiro, Brazil
2026
-
[61]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. https://arxiv.org/abs/2302.13971 LLaMA : Open and efficient foundation language models . arXiv preprint arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. https://openreview.net/pdf?id=_VjQlMeSB_J Chain-of-thought prompting elicits reasoning in large language models . In Proceedings of the 36th International Conference on Neural Information Processing Systems, NeurIPS '22, New Orleans,...
2022
-
[64]
Kai-Cheng Yang and Filippo Menczer. 2025. https://doi.org/10.1145/3717867.3717903 Accuracy and political bias of news source credibility ratings by large language models . In Proceedings of the 17th ACM Web Science Conference, Websci '25, page 127–137, New Brunswick, New Jersey, USA. ACM
-
[65]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/271db9922b8d1f4dd7aaef84ed5ac703-Paper-Conference.pdf Tree of thoughts: deliberate problem solving with large language models . In Proceedings of the 37th International Conference on Neur...
2023
-
[68]
Wenqian Zhang, Shangbin Feng, Zilong Chen, Zhenyu Lei, Jundong Li, and Minnan Luo. 2022. https://doi.org/10.18653/v1/2022.naacl-main.304 KCD : Knowledge walks and textual cues enhanced political perspective detection in news media . In Proceedings of the 2022 Conference of the North American Chapter of the Assoc. for Comp. Linguistics: Human Language Tech...
-
[69]
Denny Zhou, Nathanael Sch \"a rli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, and Quoc V. Le. 2023. https://arxiv.org/abs/2205.10625 Least-to-most prompting enables complex reasoning in large language models . In Proceedings of the International Conference on Learning Representations, ICLR '23, Kigali, Rwanda
work page internal anchor Pith review arXiv 2023
-
[70]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Mark Towers and Ariel Kwiatkowski and Jordan K. Terry and John U. Balis and Gianluca De Cola and Tristan Deleu and Manuel Goul. Gymnasium:. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2407.17032 , eprinttype =. 2407.17032 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2407.17032 2024
-
[71]
Journal of Machine Learning Research , year =
Antonin Raffin and Ashley Hill and Adam Gleave and Anssi Kanervisto and Maximilian Ernestus and Noah Dormann , title =. Journal of Machine Learning Research , year =
-
[72]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
Yang, Jingfeng and Jin, Hongye and Tang, Ruixiang and Han, Xiaotian and Feng, Qizhang and Jiang, Haoming and Zhong, Shaochen and Yin, Bing and Hu, Xia , title =. 2024 , issue_date =. doi:10.1145/3649506 , journal =
-
[74]
QLoRA: Efficient Finetuning of Quantized LLMs
Qlora: Efficient finetuning of quantized llms , author=. arXiv preprint arXiv:2305.14314 , year=
work page internal anchor Pith review arXiv
-
[75]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , series=
2022
-
[76]
Journal of documentation , volume=
A statistical interpretation of term specificity and its application in retrieval , author=. Journal of documentation , volume=. 1972 , publisher=
1972
-
[77]
Findings of the Association for Computational Linguistics:
Dilshod Azizov and Zain Muhammad Mujahid and Hilal AlQuabeh and Preslav Nakov and Shangsong Liang , editor =. Findings of the Association for Computational Linguistics:. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-EMNLP.712 , timestamp =
-
[78]
Manzoor, Muhammad Arslan and Zeng, Ruihong and Azizov, Dilshod and Nakov, Preslav and Liang, Shangsong , booktitle=
-
[79]
Tastan, Nurbek and Laskaridis, Stefanos and Nandakumar, Karthik and Horvath, Samuel , journal=
-
[80]
Mujahid, Zain Muhammad and Azizov, Dilshod and Agro, Maha Tufail and Nakov, Preslav. Profiling News Media for Factuality and Bias Using LLM s and the Fact-Checking Methodology of Human Experts. Findings of the Assoc. for Comp. Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.45
-
[81]
Nurbek Tastan and Stefanos Laskaridis and Martin Tak. Lo. The Fourteenth Int. Conf. on Learning Representations , series=. 2026 , url=
2026
-
[82]
2023 , url =
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and Aleman, Florencia Leoni and Almeida, Diogo and Altenschmidt, Janko and Altman, Sam and Anadkat, Shyamal and others , journal=. 2023 , url =
2023
-
[83]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[84]
Training language models to follow instructions with human feedback , url =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F and Leike, Jan and Lowe,...
-
[85]
Multimodal fusion methods with deep neural networks and meta-information for aggression detection in surveillance , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.eswa.2022.118523 , url =
-
[86]
2022 , eprint=
Self-attention fusion for audiovisual emotion recognition with incomplete data , author=. 2022 , eprint=
2022
-
[87]
Findings , year=
Multimodal Fusion with Co-Attention Networks for Fake News Detection , author=. Findings , year=
-
[88]
Predicting Factuality of Reporting and Bias of News Media Sources. EMNLP. 2018
2018
-
[89]
Machine learning models and algorithms for big data classification: thinking with examples for effective learning , pages=
Support vector machine , author=. Machine learning models and algorithms for big data classification: thinking with examples for effective learning , pages=. 2016 , publisher=
2016
-
[90]
GREENER : Graph Neural Networks for News Media Profiling
Panayotov, Panayot and Shukla, Utsav and Sencar, Husrev Taha and Nabeel, Mohamed and Nakov, Preslav. GREENER : Graph Neural Networks for News Media Profiling. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.506
-
[91]
A Survey on Predicting the Factuality and the Bias of News Media
Nakov, Preslav and An, Jisun and Kwak, Haewoon and Manzoor, Muhammad Arslan and Mujahid, Zain Muhammad and Sencar, Husrev Taha. A Survey on Predicting the Factuality and the Bias of News Media. Findings of the Assoc. for Comp. Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.944
-
[92]
Proceedings of the European conference on computer vision (ECCV) , pages=
Fighting fake news: Image splice detection via learned self-consistency , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[93]
Proceedings of the 10th USENIX Workshop on Free and Open Communications on the Internet , series=
Identifying disinformation websites using infrastructure features , author=. Proceedings of the 10th USENIX Workshop on Free and Open Communications on the Internet , series=. 2020 , address=
2020
-
[94]
Proceedings of the Association for Information Science and Technology , volume=
Automatic deception detection: Methods for finding fake news , author=. Proceedings of the Association for Information Science and Technology , volume=. 2015 , address=
2015
-
[95]
Afroz, Sadia and Brennan, Michael and Greenstadt, Rachel , title =. 2012 , publisher =. doi:10.1109/SP.2012.34 , booktitle =
-
[96]
Multimedia Forensics , publisher =
-
[97]
2019 , organization=
Singhal, Shivangi and Shah, Rajiv Ratn and Chakraborty, Tanmoy and Kumaraguru, Ponnurangam and Satoh, Shin'ichi , booktitle=. 2019 , organization=
2019
-
[98]
arXiv preprint arXiv:1908.11722 , year=
Fact-checking meets fauxtography: Verifying claims about images , author=. arXiv preprint arXiv:1908.11722 , year=
-
[99]
Almeida and Anas Elghafari and A
Sonia Castelo and Thais G. Almeida and Anas Elghafari and A. A Topic-Agnostic Approach for Identifying Fake News Pages , booktitle =. 2019 , url =. doi:10.1145/3308560.3316739 , address=
-
[100]
Proceedings of the MIS2 Workshop on 11th Int
Credibility assessment in the news: do we need to read? , author=. Proceedings of the MIS2 Workshop on 11th Int. Conf. on Web Search and Data Mining , pages=. 2018 , organization=
2018
-
[101]
Proceedings of the International AAAI Conference on Web and Social Media , volume=
Unsupervised user stance detection on Twitter , author=. Proceedings of the International AAAI Conference on Web and Social Media , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.