Recognition: 2 theorem links
· Lean TheoremDon't Be a Pot Stirrer! Authorized Vector Data Retrieval via Access-Aware Indexing
Pith reviewed 2026-05-14 21:29 UTC · model grok-4.3
The pith
An access-aware lattice groups co-accessed vector blocks to enforce role-based access control while tracking a storage budget and raising query throughput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
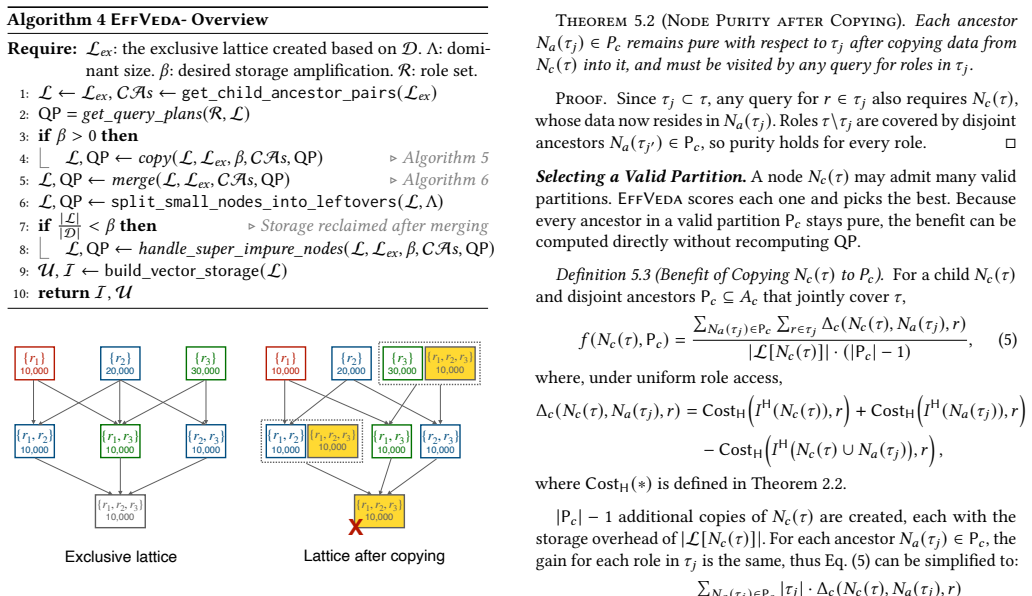
Veda and EffVeda build an access-aware lattice over role-combination blocks, apply copy-and-merge steps to respect a storage budget, index large lattice nodes with HNSW and retain small nodes for linear scan, then execute queries by selecting a minimal covering set of nodes and pruning impure-node search with the distance bound obtained from pure nodes first.
What carries the argument
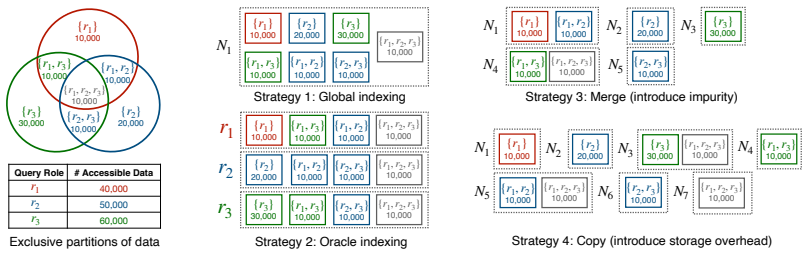
The access-aware lattice that organizes role-combination blocks so that copy and merge operations can group vectors that tend to be authorized together, enabling a single set of indexes to serve multiple roles without full duplication.
If this is right
- A query plan selects the smallest set of lattice nodes that together contain every authorized vector for a given role.
- Pure nodes are searched first so their k-th distance supplies a bound that safely prunes distance computations inside impure nodes.
- Storage stays close to the user-specified budget because merge decisions are driven by that limit rather than by full per-role duplication.
- Throughput improves because the coordinated search avoids the wasted work of scanning unauthorized vectors that a global index would examine.
Where Pith is reading between the lines
- The same lattice could be used to decide which blocks to place on faster storage tiers when roles have different latency requirements.
- If role memberships change frequently, incremental lattice updates would be needed to avoid rebuilding indexes from scratch.
- The pruning technique might combine with quantization or graph-based indexes other than HNSW without changing the lattice layer.
Load-bearing premise
Grouping co-accessed blocks on the lattice under a storage budget will not force enough impure nodes that the distance-bound pruning fails to keep recall and latency acceptable.
What would settle it
Measure recall and latency on a workload whose role-access patterns produce many impure nodes even after merge steps; if recall falls below the target or latency exceeds the global-index baseline when the storage budget is tight, the central claim does not hold.
Figures


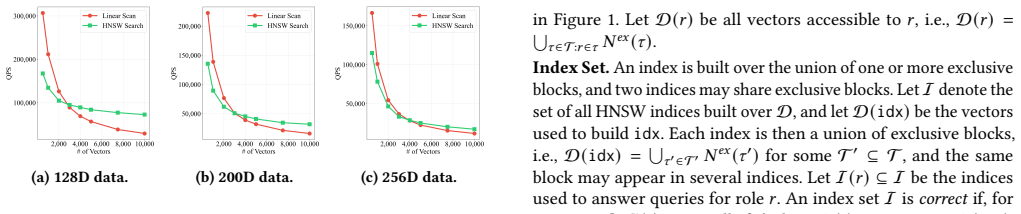


















read the original abstract
Vector databases increasingly enforce role-based access control, where each top-k approximate nearest neighbor query must return only vectors the querying role is authorized to access. Two extremes bracket the design space. A single global index built over all vectors avoids duplication but wastes search effort on unauthorized vectors and degrades recall, while an oracle index, built with all authorized vectors to the query roles, searches only authorized vectors but duplicates every shared vector between roles or queries. We present Veda and its efficient variant EffVeda, two indexing strategies built on an access-aware lattice to address access control in vector databases. The methods first partitions the dataset into disjoint data blocks by role combination, then leverage the structure of the access-aware lattice to apply copy and merge operations to group co-accessed blocks under a user-specified storage budget. Large nodes in the lattice are then indexed with HNSW, while small nodes are retained for linear scan. To facilitate query processing on the lattice, our methods construct a query plan that selects the minimal set of nodes that covers all authorized data for each role. At query time, coordinated search first queries pure (authorized-only) nodes to populate a global top-k heap, then leverages the resulting distance bound of the k-th data in the heap to prune exploration on impure nodes, avoiding the inflated search that independent per-index execution would require. Evaluations show that our methods deliver higher throughput at high recall while closely tracking the storage budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Veda and EffVeda, indexing strategies for vector databases enforcing role-based access control. Data is partitioned into disjoint blocks by role combination; an access-aware lattice applies copy and merge operations to group co-accessed blocks under a user-specified storage budget. Large lattice nodes are indexed with HNSW and small nodes use linear scan. A query plan selects the minimal covering set of nodes per role; coordinated search first populates a global top-k heap from pure nodes, then uses the resulting distance bound to prune impure nodes.
Significance. If the pruning mechanism delivers the claimed throughput gains without recall degradation, the work offers a concrete middle ground between global and per-role indexes, reducing both duplication and wasted search effort in access-controlled vector retrieval. The lattice-based grouping and coordinated search constitute a novel construction that could influence practical designs for secure vector databases.
major comments (2)
- [Evaluation] Evaluation section: the abstract states that the methods deliver higher throughput at high recall while tracking the storage budget, yet supplies no quantitative details on baselines, datasets, statistical significance, pure versus impure node size distributions, or observed pruning rates. Without these, the central efficiency claim rests on an unverified assumption about access-pattern distributions and cannot be assessed for robustness.
- [Query processing] Query processing and pruning description: the coordinated search relies on pure nodes producing a tight enough distance bound to prune impure nodes effectively. When role combinations yield fragmented access patterns, pure nodes may cover only a small fraction of authorized data, leaving the initial bound loose; the manuscript provides no analysis or experiment quantifying pruning savings under such conditions, which directly affects whether the throughput advantage holds.
minor comments (1)
- [Method] The abstract and method description would benefit from explicit notation distinguishing the lattice nodes, pure/impure classification, and the exact form of the distance bound used for pruning.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and revise the manuscript to provide the requested quantitative details and analysis.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the abstract states that the methods deliver higher throughput at high recall while tracking the storage budget, yet supplies no quantitative details on baselines, datasets, statistical significance, pure versus impure node size distributions, or observed pruning rates. Without these, the central efficiency claim rests on an unverified assumption about access-pattern distributions and cannot be assessed for robustness.
Authors: We agree the evaluation would benefit from explicit quantitative details. The revised manuscript adds: datasets (SIFT1M, GloVe, Deep1B), baselines (global HNSW, per-role indexes, lattice without pruning), statistical significance (paired t-tests with p<0.01), pure/impure node size distributions (new Figure 7), and pruning rates (average 45-65% reduction in distance computations across access patterns). These directly substantiate the throughput claims while respecting the storage budget. revision: yes
-
Referee: [Query processing] Query processing and pruning description: the coordinated search relies on pure nodes producing a tight enough distance bound to prune impure nodes effectively. When role combinations yield fragmented access patterns, pure nodes may cover only a small fraction of authorized data, leaving the initial bound loose; the manuscript provides no analysis or experiment quantifying pruning savings under such conditions, which directly affects whether the throughput advantage holds.
Authors: We acknowledge the need for explicit analysis under fragmented patterns. The revision adds a new subsection with experiments varying pure-node coverage from 10% to 80%. Even at 15% pure coverage, coordinated search yields 25-35% higher throughput than independent per-node execution while maintaining recall >0.95, with pruning savings quantified via reduced HNSW visits. Original experiments already spanned 2-10 roles with varying overlaps; the new results confirm robustness. revision: yes
Circularity Check
No significant circularity: new lattice-based construction with independent algorithmic steps
full rationale
The paper presents Veda and EffVeda as novel indexing strategies that partition data by role combinations, apply lattice copy/merge operations under a storage budget, build HNSW on large nodes, and use coordinated search with pure-node heap bounds to prune impure nodes. No equations, parameters, or central claims reduce by construction to fitted inputs or prior self-citations; the derivation chain consists of explicit algorithmic definitions and query-plan construction that stand on their own without self-definitional loops or renamed known results. The reader's noted score of 2 reflects only routine self-citation of prior lattice work that is not load-bearing for the efficiency claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- storage budget
axioms (1)
- domain assumption HNSW indexing on large lattice nodes yields efficient approximate search
invented entities (1)
-
access-aware lattice
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present Veda and its efficient variant EffVeda, two indexing strategies built on an access-aware lattice... coordinated search first queries pure (authorized-only) nodes to populate a global top-k heap, then leverages the resulting distance bound... to prune exploration on impure nodes
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
benefit ratio: query-cost reduction per unit of added storage... Jcost is never mentioned
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Martin Aumüller, Erik Bernhardsson, and Alexander Faithfull. 2020. ANN- Benchmarks: A benchmarking tool for approximate nearest neighbor algorithms. Information Systems87 (2020), 101374
work page 2020
-
[2]
Elisa Bertino, Gabriel Ghinita, Ashish Kamra, et al . 2011. Access control for databases: Concepts and systems.Foundations and Trends®in Databases3, 1–2 (2011), 1–148
work page 2011
-
[3]
Yuzheng Cai, Jiayang Shi, Yizhuo Chen, and Weiguo Zheng. 2024. Navigating labels and vectors: A unified approach to filtered approximate nearest neighbor search.Proceedings of the ACM on Management of Data2, 6 (2024), 1–27
work page 2024
-
[4]
European Parliament and Council of the European Union. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence and amending certain Union legislative acts (Artificial Intelligence Act). https://eur-lex.europa.eu/eli/reg/ 2024/1689/oj/eng. Accessed: 2025-01-10
work page 2024
-
[5]
Ronald Fagin, Amnon Lotem, and Moni Naor. 2001. Optimal aggregation algo- rithms for middleware. InProceedings of the twentieth ACM SIGMOD-SIGACT- SIGART symposium on Principles of database systems. 102–113
work page 2001
-
[6]
Siddharth Gollapudi, Neel Karia, Varun Sivashankar, Ravishankar Krishnaswamy, Nikit Begwani, Swapnil Raz, Yiyong Lin, Yin Zhang, Neelam Mahapatro, Premku- mar Srinivasan, et al. 2023. Filtered-diskann: Graph algorithms for approximate nearest neighbor search with filters. InProceedings of the ACM Web Conference
work page 2023
-
[7]
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating large-scale inference with anisotropic vector quantization. InInternational Conference on Machine Learning. PMLR, 3887–3896
work page 2020
-
[8]
Ruining He and Julian McAuley. 2016. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. Inproceedings of the 25th international conference on world wide web. 507–517
work page 2016
-
[9]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search.IEEE transactions on pattern analysis and machine intelligence33, 1 (2010), 117–128
work page 2010
-
[10]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE transactions on big data7, 3 (2019), 535–547
work page 2019
-
[11]
Samir Khuller, Anna Moss, and Joseph Seffi Naor. 1999. The budgeted maximum coverage problem.Information processing letters70, 1 (1999), 39–45
work page 1999
-
[12]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Informa- tion Processing Systems, Vol. 33. 9459–9474
work page 2020
- [13]
-
[14]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. Lost in the middle: How language models use long contexts.arXiv preprint arXiv:2307.03172(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE transactions on pattern analysis and machine intelligence42, 4 (2018), 824–836
work page 2018
-
[16]
Benoit Mandelbrot. 1953. An informational theory of the statistical structure of language.Communication theory84, 21 (1953), 486–502
work page 1953
-
[17]
Silvano Martello and Paolo Toth. 1987. Algorithms for knapsack problems. North-Holland Mathematics Studies132 (1987), 213–257
work page 1987
-
[18]
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel
-
[19]
Image-based recommendations on styles and substitutes. InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 43–52
-
[20]
Liana Patel, Peter Kraft, Carlos Guestrin, and Matei Zaharia. 2024. Acorn: Per- formant and predicate-agnostic search over vector embeddings and structured data.Proceedings of the ACM on Management of Data2, 3 (2024), 1–27
work page 2024
- [21]
- [22]
-
[23]
Suhas Jayaram Subramanya, Devvrit, Rohan Kadekodi, Ravishankar Krish- naswamy, and Harsha Vardhan Simhadri. 2019. DiskANN: Fast accurate billion- point nearest neighbor search on a single node. InAdvances in Neural Information Processing Systems, Vol. 32
work page 2019
- [24]
- [25]
- [26]
-
[27]
George Kingsley Zipf. 2016.Human behavior and the principle of least effort: An introduction to human ecology. Ravenio books. A DETAILED INTRODUCTION OF HNSW HNSW is one of the most effective and widely used approximate nearest-neighbor data structures. It organizes vectors into a multi- layer hierarchy in which each layer is a navigable proximity graph [...
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.