Recognition: 2 theorem links
· Lean TheoremThe Perceptual Bandwidth Bottleneck in Vision-Language Models: Active Visual Reasoning via Sequential Experimental Design
Pith reviewed 2026-05-12 01:36 UTC · model grok-4.3
The pith
Vision-language models improve high-resolution reasoning by actively selecting task-relevant image regions instead of processing the full view at once.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
High-resolution visual reasoning in vision-language models is not only semantic reasoning but also task-relevant evidence acquisition under limited perceptual bandwidth. Since exact Bayesian inference is intractable in continuous gigapixel spaces, a tractable coverage-resolution objective acts as a proxy for task-relevant information gain. Instantiating the framework with the FOVEA procedure, which refines VLM crop proposals through evidence-oriented probing, produces consistent performance gains over direct and ReAct-style baselines on high-resolution benchmarks, with the largest improvements in search-dominated remote-sensing settings.
What carries the argument
The coverage-resolution objective, a proxy for task-relevant information gain derived from sequential Bayesian optimal experimental design that balances broad image coverage against fine detail resolution to guide which regions to examine next.
If this is right
- Models following this approach will show larger gains on tasks that require locating specific details within large images.
- The method works without any additional training or fine-tuning of the underlying vision-language model.
- Improvements concentrate in search-heavy domains such as remote sensing where evidence must be gathered piece by piece.
- Standard one-shot or reactive prompting underperforms when the task demands sequential evidence decisions.
Where Pith is reading between the lines
- The same active-selection framing could extend to other bandwidth-limited inputs such as long documents or video streams.
- Real-time systems could adopt similar probing to reduce compute by skipping irrelevant high-resolution areas.
- End-to-end learning of the probing policy might further improve the sequential choices beyond the current training-free version.
- Testing the objective on multi-turn dialogues with changing questions would check whether the proxy generalizes when task goals evolve.
Load-bearing premise
The coverage-resolution objective accurately approximates the actual information gain from acquiring specific visual evidence, and the performance improvements result from this active selection rather than other factors.
What would settle it
An experiment on the same high-resolution benchmarks in which FOVEA-guided crops are replaced by random or uniform selections and no accuracy difference appears would show the claimed mechanism does not drive the gains.
Figures





read the original abstract
Visual perception in modern Vision-Language Models (VLMs) is constrained by a perceptual bandwidth bottleneck: a broad field of view preserves global context but sacrifices the fine-grained details required for complex reasoning. We argue that high-resolution visual reasoning is therefore not only semantic reasoning but also task-relevant evidence acquisition under limited perceptual bandwidth. Inspired by active vision and information foraging, we formalise this process as sequential Bayesian optimal experimental design (S-BOED), where an agent decides which visual evidence to acquire before answering. Since exact Bayesian inference is intractable in continuous gigapixel spaces, we derive a tractable coverage--resolution objective as a proxy for task-relevant information gain. We instantiate this framework with FOVEA, a training-free procedure that refines VLM crop proposals through evidence-oriented probing. Experiments on high-resolution benchmarks show consistent gains over direct and ReAct-style baselines, with particularly strong improvements in search-dominated remote-sensing settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
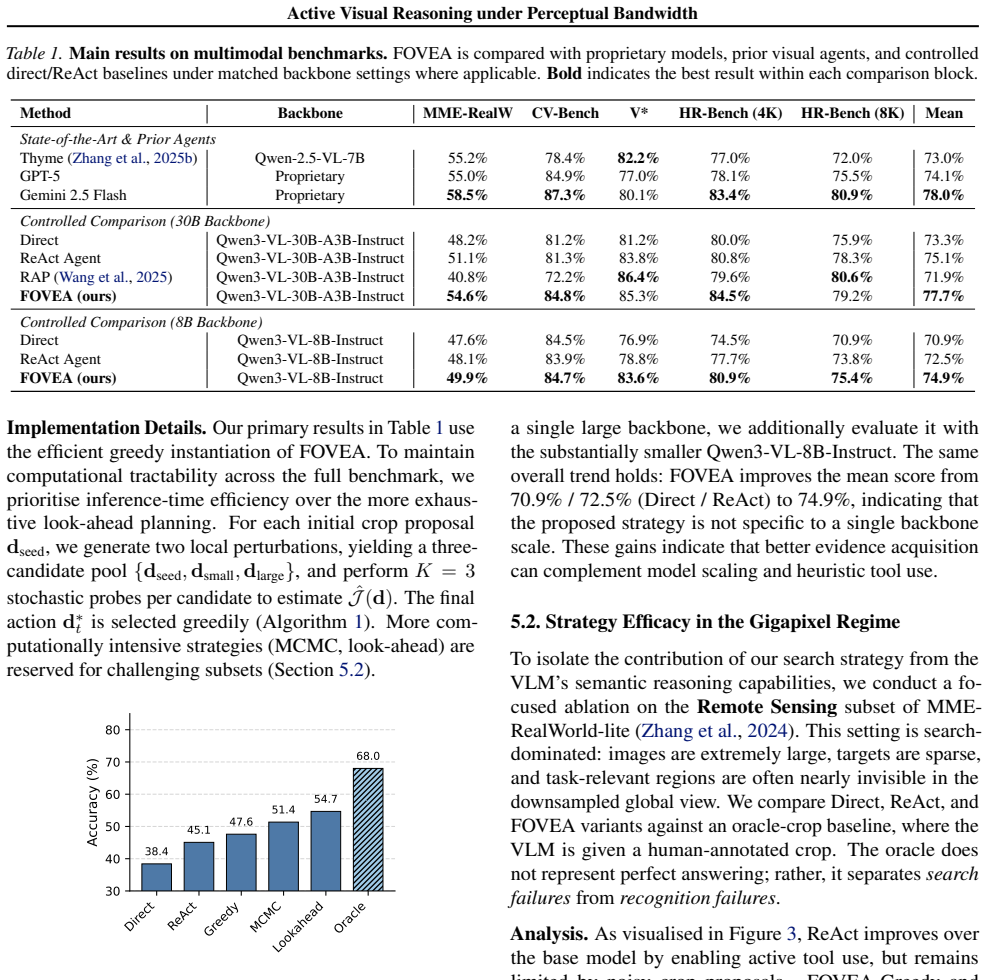
Summary. The manuscript claims that VLMs face a perceptual bandwidth bottleneck in high-resolution images, where broad fields of view sacrifice fine details needed for complex reasoning. It formalizes high-resolution visual reasoning as sequential Bayesian optimal experimental design (S-BOED) for task-relevant evidence acquisition, derives a tractable coverage-resolution objective as a proxy for information gain (due to intractability in gigapixel spaces), and instantiates this in the training-free FOVEA procedure for refining VLM crop proposals. Experiments on high-resolution benchmarks report consistent gains over direct and ReAct-style baselines, with strongest improvements in search-dominated remote-sensing settings.
Significance. If the coverage-resolution proxy is shown to preserve key monotonicity and ranking properties of expected information gain under the S-BOED intractability assumptions, the work would provide a principled, training-free mechanism for active visual evidence acquisition in VLMs. This could meaningfully improve performance on detail-sensitive tasks without model retraining and would strengthen connections between active vision, information foraging, and modern multimodal models, particularly in domains like remote sensing.
major comments (1)
- [Abstract and derivation of coverage-resolution objective] The central load-bearing step is the substitution of the coverage-resolution objective for task-relevant information gain in S-BOED (abstract and the derivation section). The manuscript notes exact inference is intractable in continuous gigapixel spaces but does not demonstrate that the proxy retains the monotonicity or action-ranking properties required for the agent to select evidence-acquiring actions that maximize expected utility; without this (e.g., via correlation checks against exact MI on downscaled problems), FOVEA gains could stem from generic cropping heuristics rather than active design.
minor comments (2)
- [Experiments] The experimental section would benefit from explicit reporting of the number of trials, variance across runs, and statistical significance tests for the reported gains over baselines.
- [Method] Notation for the coverage-resolution objective and its relation to the S-BOED utility function should be introduced with an equation label for easier reference in later sections.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful feedback on our manuscript. We address the major comment below and outline planned revisions to strengthen the justification of our approach.
read point-by-point responses
-
Referee: [Abstract and derivation of coverage-resolution objective] The central load-bearing step is the substitution of the coverage-resolution objective for task-relevant information gain in S-BOED (abstract and the derivation section). The manuscript notes exact inference is intractable in continuous gigapixel spaces but does not demonstrate that the proxy retains the monotonicity or action-ranking properties required for the agent to select evidence-acquiring actions that maximize expected utility; without this (e.g., via correlation checks against exact MI on downscaled problems), FOVEA gains could stem from generic cropping heuristics rather than active design.
Authors: We agree that explicitly demonstrating the proxy's preservation of monotonicity and action-ranking properties is a valuable addition for rigor. The coverage-resolution objective is derived in the manuscript as a tractable surrogate that decomposes expected information gain into coverage of task-relevant regions and sufficient resolution for detail capture, under the intractability of exact inference in gigapixel spaces; we posit this retains the necessary ordering because actions improving either factor increase downstream task utility. However, we acknowledge the manuscript does not include empirical correlation checks against exact mutual information on downscaled problems. We will add such validation in the revision, using synthetic or lower-dimensional scenarios where exact MI computation is feasible, to confirm the proxy maintains monotonicity and correct rankings. Additionally, our experiments compare against ReAct-style baselines employing generic cropping and reasoning without the sequential proxy-driven selection, which helps attribute gains to the active design rather than heuristics alone. These changes will directly address the concern. revision: yes
Circularity Check
No significant circularity; derivation is self-contained approximation
full rationale
The paper's central step is deriving a coverage-resolution objective explicitly as a tractable proxy for information gain under the acknowledged intractability of exact S-BOED in gigapixel spaces. This is introduced as an approximation rather than a quantity defined circularly in terms of fitted parameters from the target task data or VLM outputs. The framework builds on established Bayesian optimal experimental design and active-vision literature without load-bearing self-citations or uniqueness theorems imported from the authors' prior work. No step reduces by construction to renaming inputs, fitting then predicting the same quantity, or smuggling an ansatz via citation. The experimental gains are presented as empirical validation of the proxy procedure (FOVEA), not as proof of the derivation itself. The derivation chain therefore remains independent of the results it is used to produce.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Exact Bayesian inference is intractable in continuous gigapixel spaces
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we derive a tractable coverage–resolution objective as a proxy for task-relevant information gain... J_t(d) = (∫_{x∈d} p_t(x) dx) ϕ(d)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Perceptual Bandwidth B... ρ(d) ≜ B/A(d)... ϕ(d) = f_sat(ρ(d))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
BED-LLM: Intelligent Information Gathering with LLMs and Bayesian Experimental Design
URL https://openreview.net/forum? id=Q5RYn6jagC. Chaloner, K. and Verdinelli, I. Bayesian experimental de- sign: A review.Statistical science, pp. 273–304, 1995. Choudhury, D., Williamson, S., Goli ´nski, A., Miao, N., Smith, F. B., Kirchhof, M., Zhang, Y ., and Rainforth, T. Bed-llm: Intelligent information gathering with llms and bayesian experimental d...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.emnlp-main 1995
-
[2]
URL https://aclanthology.org/2025. emnlp-main.564/. MacKay, D. J. Information-based objective functions for active data selection.Neural computation, 4(4):590–604, 1992. Najemnik, J. and Geisler, W. S. Optimal eye movement strategies in visual search.Nature, 434(7031):387–391, 2005. Niu, J., Liu, Z., Gu, Z., Wang, B., Ouyang, L., Zhao, Z., Chu, T., He, T....
-
[3]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
URL https://api.semanticscholar. org/CorpusID:12037187. 11 Active Visual Reasoning under Perceptual Bandwidth Singh, A., Natarjan, V ., Shah, M., Jiang, Y ., Chen, X., Parikh, D., and Rohrbach, M. Towards vqa models that can read. InProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition, pp. 8317–8326, 2019. Snell, C., Lee, J., Xu...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[4]
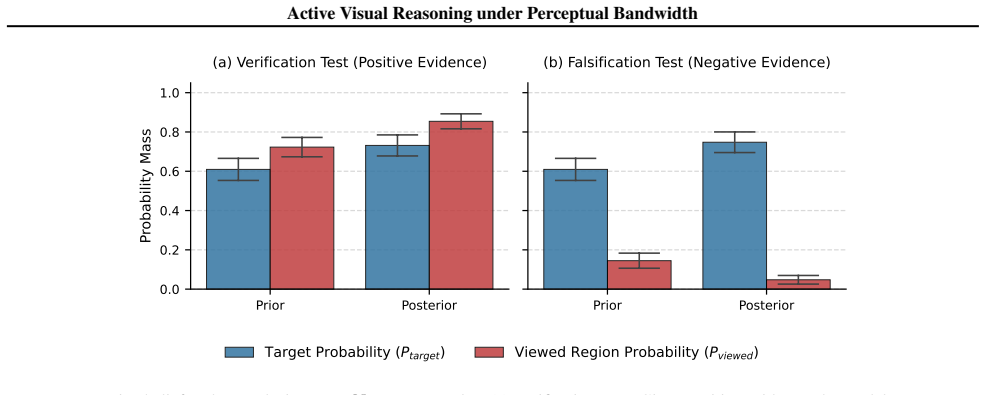
Viewed Region Probability( Pviewed): The total probability mass assigned to the region currently visible in the zoomed-in crop. Pviewed = X j∈Goverlap P(Grid i) where Goverlap denotes the grid cells covered by the current intervention crop to a certain extent (15% of the grid area in our experiments). E.3. Quantitative Analysis Figure 5 illustrates the ag...
-
[5]
can the model produce an answer
This confirms the model’s capacity forexploitation, that is, when presented with the correct view, it confidently locks onto the target. Falsification Test (Negative Evidence).Figure 5 (b) demonstrates the model’s capacity forexplorationand error correction. In the Prior state, the model assigns non-zero probability to the distractor region (Pviewed >0 )....
work page 2024
-
[6]
The original image (provided with the question)
-
[7]
The image the agent wants to crop
-
[8]
A candidate cropped region Instructions
-
[9]
Analyze the correlation: What’s the relationship between these images? How does the candidate cropped region relate to the original question?
-
[10]
Identify mismatch: If the candidate cropped region is on a different part of the original image from where the question asks, this region contains no information and you should answer with “No”
-
[11]
Be confident of your choice: Trust your reasoning and perception, based on which you can always give a “Yes” or “No” to whether this cropped region helps answer the question. Constraints • MUST NOT answer anything other than “Yes” and “No”; you don’t need to answer the original question. • MUST use the thinking section to reason about the relationships be...
-
[12]
Analyze the correlation:
-
[13]
Thorough analysis (Reason about if you can answer the question correctly given the cropped region based on the previous thinking): ... **Answer:** <answer>[Your Answer]</answer> 26 Active Visual Reasoning under Perceptual Bandwidth System Prompt for CV Agent Persona You are an advanced Computer Vision (CV) Agent equipped with sophisticated image analysis ...
-
[14]
Turn Management:At the start of every response, check the current turn against max turns. If current turn == max turns, you must skip tool usage and provide the most accurate<answer>possible based on existing information
-
[15]
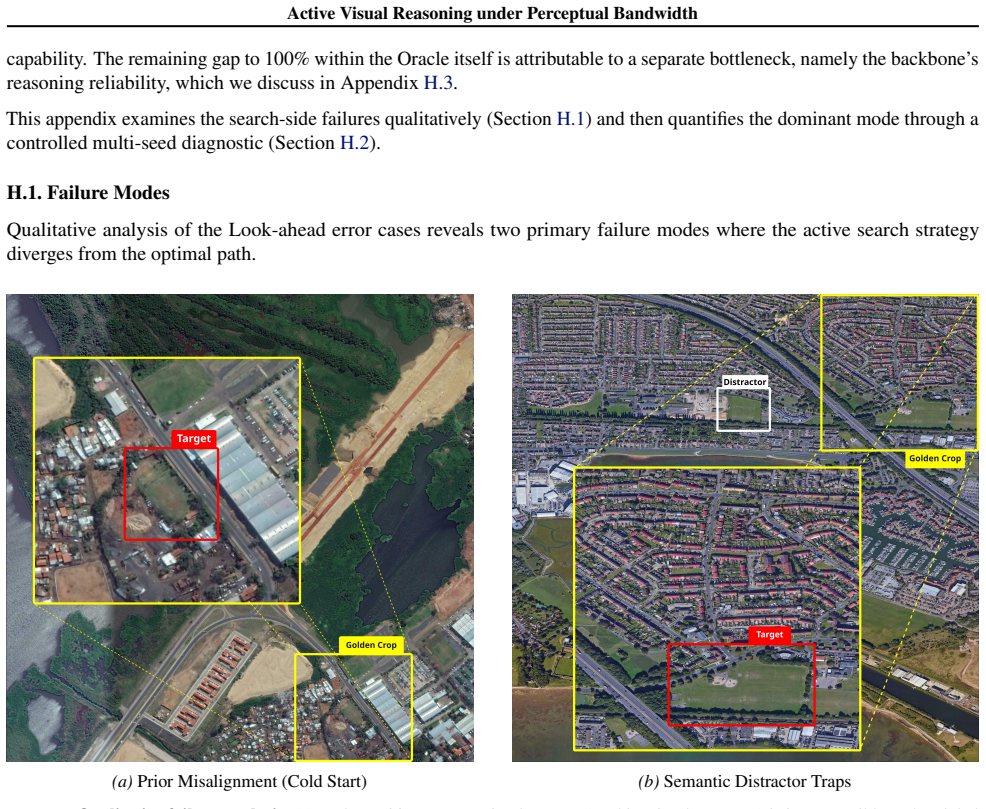
Crop first, perception (e.g., detection) later
Heavy Reasoning:Think first. Analyze the current state, the user’s question, and previous observations. Plan the next logical step. 3.Good Tool Use Strategy: • “Crop first, perception (e.g., detection) later” is always a good exploration strategy in early rounds. It’s not wise to call detectionon a quite large picture without zooming in first. • When you ...
-
[16]
Termination:Once a concrete answer is found or the turn limit is reached, conclude the loop and output the final answer wrapped in<answer>tags. Problem-Solving Strategy 1.Locate the object of interest first: • If the question provides the approximate location, zoom in that area to locate the object. • If not, reason about what particular regions it can be...
-
[17]
You can verify your judgment with detection, but never treat its results as arguments
Use detection results only as a reference:When the detection can work well, you can also see it well. You can verify your judgment with detection, but never treat its results as arguments. 3.Always use the depth estimation tool when asked about ”which one is closer”:It’s hard to rely on pure reasoning to restore depth information lost in 2D images, but th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.