Recognition: unknown
Focus on the Core: Empowering Diffusion Large Language Models by Self-Contrast
Pith reviewed 2026-05-09 14:55 UTC · model grok-4.3
The pith
Diffusion language models generate higher-quality code and math answers when decoding focuses on early-converging high-density tokens via self-contrast.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
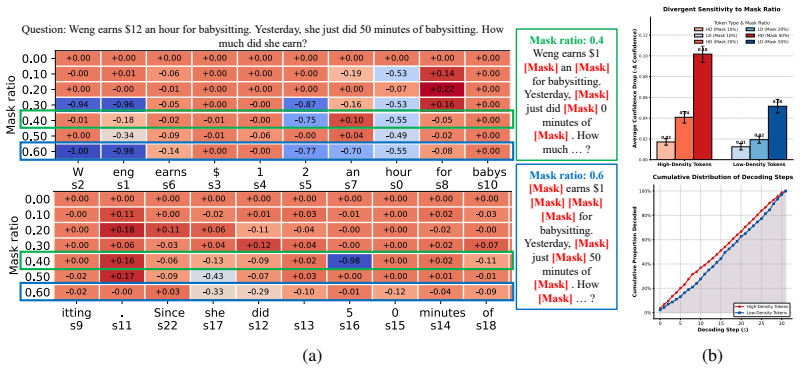
FoCore is a training-free decoding strategy for diffusion large language models that identifies high-information-density tokens, which tend to converge early, and temporarily remasks them as negative samples to create a self-contrast signal that guides the model toward higher-quality generations. This approach leverages the iterative denoising process to better utilize global context. The method also includes an efficient acceleration where, upon convergence detection, parallel decoding is performed over stable candidates in a local window.
What carries the argument
FoCore, the self-contrast decoding mechanism that remasks high-information-density tokens as negative samples to guide generation toward better global outputs.
If this is right
- On HumanEval, pass@1 rises from 39.02 to 42.68 compared to standard Classifier-Free Guidance.
- FoCore-A cuts decoding steps by a factor of 2.07 and reduces per-sample latency by 58.4 percent from 20.76s to 8.64s.
- Consistent quality and efficiency gains appear across math, code, and logical reasoning benchmarks on both LLaDA and Dream backbones.
- The entire strategy requires no additional training or parameter changes.
Where Pith is reading between the lines
- The same self-contrast principle on early-converging tokens could be tested in other iterative generation settings such as diffusion models for images or audio.
- If the identification of high-density tokens generalizes, it might reduce reliance on reranking or multiple sampling passes in production LLM systems.
- Hybrid systems that combine this focus mechanism with standard autoregressive contrastive decoding could be explored to blend global and local strengths.
Load-bearing premise
High-information-density tokens can be reliably identified during decoding and temporarily remasking them as negative samples will consistently guide the model toward higher-quality global outputs without introducing new errors.
What would settle it
Replace the high-density token identification step with random token selection for remasking and measure whether the reported gains on HumanEval and other reasoning benchmarks disappear.
Figures



read the original abstract
The iterative denoising paradigm of Diffusion Large Language Models (DLMs) endows them with a distinct advantage in global context modeling. However, current decoding strategies fail to leverage this capability, typically exhibiting a local preference that overlooks the heterogeneous information density within the context, ultimately degrading generation quality. To address this limitation, we systematically investigate high-information-density (HD) tokens and present two key findings: (1) explicitly conditioning on HD tokens substantially improves output quality; and (2) HD tokens exhibit an early-decoding tendency, converging earlier than surrounding tokens. Motivated by these findings, we propose Focus on the Core \textbf{(FoCore)}, a training-free decoding strategy that utilizes HD tokens in a self-contrast manner, wherein HD tokens are temporarily remasked as negative samples, to guide generation. We further introduce FoCore\_Accelerate \textbf{(FoCore\_A)}, an efficient variant that, upon detecting HD token convergence, performs parallel decoding over stable candidates within a local context window, substantially accelerating generation. Extensive experiments on math, code and logical reasoning benchmarks demonstrate that FoCore consistently improves generation quality and efficiency across both LLaDA and Dream backbones. For instance, on HumanEval, FoCore improves pass@1 from 39.02 to 42.68 over standard Classifier-Free Guidance, while FoCore-A reduces the number of decoding steps by 2.07x and per-sample latency from 20.76s to 8.64s (-58.4\%).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates high-information-density (HD) tokens in Diffusion Large Language Models (DLMs) and reports two empirical findings: conditioning on HD tokens improves output quality, and HD tokens exhibit early convergence during denoising. Motivated by this, it proposes FoCore, a training-free decoding method that identifies HD tokens on-the-fly and applies self-contrast by temporarily remasking them as negative samples to steer generation. An accelerated variant FoCore-A performs parallel decoding over converged tokens in local windows. Experiments on math, code, and logical reasoning benchmarks with LLaDA and Dream backbones show quality gains (e.g., HumanEval pass@1 rising from 39.02 to 42.68 over standard Classifier-Free Guidance) and efficiency improvements (FoCore-A yields 2.07x fewer steps and 58.4% lower latency).
Significance. If the empirical findings and decoding strategy hold under rigorous verification, the work offers a practical, training-free enhancement to DLM decoding that better exploits their global context modeling advantage over standard CFG. The acceleration component is particularly notable for practical deployment. The absence of new parameters or training is a strength, but the significance is tempered by the provisional nature of the reported gains and the need for clearer validation of the HD-token identification heuristic.
major comments (2)
- [§3 and §4] The central quality and acceleration claims rest on reliable on-the-fly identification of HD tokens from the current denoising state without future information. The manuscript provides no formal definition or pseudocode for the identification heuristic (likely in §3 or §4), nor ablation on its sensitivity to noise or early-stage uncertainty; this directly affects whether remasking consistently improves trajectories or introduces inconsistencies.
- [Results section / Table 1] Table or results section reporting HumanEval (and other benchmarks): the pass@1 improvement from 39.02 to 42.68 and the latency reduction to 8.64s are presented without number of runs, standard deviations, statistical significance tests, or explicit data-split details. This makes it impossible to assess whether the gains are robust or could be explained by variance in the identification step.
minor comments (2)
- [§4] Notation for the self-contrast step (negative-sample remasking) should be formalized with an equation rather than prose description to allow exact reproduction.
- [§3.2] The early-convergence property is stated as a key motivation for FoCore-A, but the precise convergence criterion (e.g., token stability threshold across denoising steps) is not specified, complicating independent implementation.
Simulated Author's Rebuttal
Thank you for the thoughtful review of our manuscript. We address the major comments point by point below and outline the revisions we will make to improve the clarity and rigor of the work.
read point-by-point responses
-
Referee: [§3 and §4] The central quality and acceleration claims rest on reliable on-the-fly identification of HD tokens from the current denoising state without future information. The manuscript provides no formal definition or pseudocode for the identification heuristic (likely in §3 or §4), nor ablation on its sensitivity to noise or early-stage uncertainty; this directly affects whether remasking consistently improves trajectories or introduces inconsistencies.
Authors: We agree with the referee that a formal definition and pseudocode are necessary for reproducibility. The HD token identification heuristic operates exclusively on the current denoising state at each step, without access to future tokens or information, as it relies on the model's predicted probabilities in the current iteration. In the revised manuscript, we will add a formal definition in Section 3, along with pseudocode for the entire FoCore algorithm. We will also include an ablation study on the heuristic's sensitivity to noise and early uncertainty, with results showing consistent improvements in generation quality and no introduction of inconsistencies in the denoising trajectories. revision: yes
-
Referee: [Results section / Table 1] Table or results section reporting HumanEval (and other benchmarks): the pass@1 improvement from 39.02 to 42.68 and the latency reduction to 8.64s are presented without number of runs, standard deviations, statistical significance tests, or explicit data-split details. This makes it impossible to assess whether the gains are robust or could be explained by variance in the identification step.
Authors: We acknowledge that the current presentation lacks details on experimental variability. The results in Table 1 are from single runs using the standard test splits of the benchmarks (e.g., the official HumanEval test set). The HD identification is deterministic, minimizing stochastic variance. To strengthen the claims, we will revise the results section to report averages and standard deviations over 3 independent runs with different random seeds, include statistical significance tests (e.g., paired t-tests), and explicitly detail the data splits and evaluation protocol. revision: yes
Circularity Check
No circularity: empirical findings and training-free heuristic
full rationale
The paper's core contribution is an empirical investigation of high-information-density tokens in diffusion LLMs, followed by a training-free decoding heuristic (FoCore) motivated by two observed patterns: improved quality when conditioning on HD tokens and their early convergence. No equations, fitted parameters, or derivations are presented that reduce the claimed quality or speed gains to a self-definition, a renamed input, or a self-citation chain. The method is explicitly described as training-free and is validated on external benchmarks (HumanEval, math, code, logical reasoning) rather than being forced by construction from the same data used to identify the patterns. Self-citations, if any, are not load-bearing for the central claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Iterative denoising in DLMs provides a global context modeling advantage that current decoding strategies fail to exploit.
invented entities (1)
-
High-information-density (HD) tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021a. Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc...
work page internal anchor Pith review arXiv
-
[2]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b. arXiv preprint arXiv:2512.15745,
work page internal anchor Pith review arXiv
-
[3]
Changxiao Cai and Gen Li. Confidence-based decoding is provably efficient for diffusion language models.arXiv preprint arXiv:2603.22248,
-
[4]
Search or accelerate: Confidence-switched position beam search for diffusion language models
Mingyu Cao, Alvaro Correia, Christos Louizos, Shiwei Liu, and Lu Yin. Search or accelerate: Confidence-switched position beam search for diffusion language models. InICLR 2026 2nd Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy. Michael Cardei, Jacob K Christopher, Bhavya Kailkhura, Thomas Hartvigsen, and Ferdinando F...
2026
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Tianlang Chen, Minkai Xu, Jure Leskovec, and Stefano Ermon. Rfg: Test-time scaling for diffusion large language model reasoning with reward-free guidance.arXiv preprint arXiv:2509.25604,
-
[7]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Inference-Time Scaling of Diffusion Language Models via Trajectory Refinement
Meihua Dang, Jiaqi Han, Minkai Xu, Kai Xu, Akash Srivastava, and Stefano Ermon. Inference- time scaling of diffusion language models with particle gibbs sampling.arXiv preprint arXiv:2507.08390,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Continu- ous diffusion for categorical data.arXiv preprint arXiv:2211.15089, 2022
Sander Dieleman, Laurent Sartran, Arman Roshannai, Nikolay Savinov, Yaroslav Ganin, Pierre H Richemond, Arnaud Doucet, Robin Strudel, Chris Dyer, Conor Durkan, et al. Continuous diffusion for categorical data.arXiv preprint arXiv:2211.15089,
-
[10]
Liancheng Fang, Aiwei Liu, Henry Peng Zou, Yankai Chen, Enze Ma, Leyi Pan, Chunyu Miao, Wei- Chieh Huang, Xue Liu, and Philip S Yu. Locally confident, globally stuck: The quality-exploration dilemma in diffusion language models.arXiv preprint arXiv:2604.00375,
-
[11]
Stream of search (sos): Learning to search in language, 2024,
Kanishk Gandhi, Denise Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma, and Noah D Goodman. Stream of search (sos): Learning to search in language.arXiv preprint arXiv:2404.03683,
-
[12]
10 Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, et al. Scaling diffusion language models via adaptation from autoregressive models.arXiv preprint arXiv:2410.17891,
-
[13]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review arXiv
-
[14]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review arXiv
-
[15]
Zemin Huang, Yuhang Wang, Zhiyang Chen, and Guo-Jun Qi. Don’t settle too early: Self-reflective remasking for diffusion language models.arXiv preprint arXiv:2509.23653,
-
[16]
Klass: Kl-guided fast inference in masked diffusion models
Seo Hyun Kim, Sunwoo Hong, Hojung Jung, Youngrok Park, and Se-Young Yun. Klass: Kl-guided fast inference in masked diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. Cheuk Kit Lee, Paul Jeha, Jes Frellsen, Pietro Lio, Michael Samuel Albergo, and Francisco Var- gas. Debiasing guidance for discrete diffusion wit...
-
[17]
Pengxiang Li, Shilin Yan, Joey Tsai, Renrui Zhang, Ruichuan An, Ziyu Guo, and Xiaowei Gao. Adaptive classifier-free guidance via dynamic low-confidence masking.arXiv preprint arXiv:2505.20199, 2025a. Pengxiang Li, Yefan Zhou, Dilxat Muhtar, Lu Yin, Shilin Yan, Li Shen, Soroush V osoughi, and Shiwei Liu. Diffusion language models know the answer before dec...
-
[18]
Diffusion guided language modeling
Justin Lovelace, Varsha Kishore, Yiwei Chen, and Kilian Weinberger. Diffusion guided language modeling. InFindings of the Association for Computational Linguistics: ACL 2024, pages 14936–14952,
2024
-
[19]
Dsb: Dynamic sliding block scheduling for diffusion llms.arXiv preprint arXiv:2602.05992,
Lizhuo Luo, Shenggui Li, Yonggang Wen, and Tianwei Zhang. Dsb: Dynamic sliding block scheduling for diffusion llms.arXiv preprint arXiv:2602.05992,
-
[20]
Linrui Ma, Yufei Cui, Kai Han, and Yunhe Wang. Mask is what dllm needs: A masked data training paradigm for diffusion llms.arXiv preprint arXiv:2603.15803,
-
[21]
Decoding large language diffusion models with foreseeing movement.arXiv preprint arXiv:2512.04135,
Yichuan Mo, Quan Chen, Mingjie Li, Zeming Wei, and Yisen Wang. Decoding large language diffusion models with foreseeing movement.arXiv preprint arXiv:2512.04135,
-
[22]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji- Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review arXiv
-
[23]
11 Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are nlp models really able to solve simple math word problems? InProceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies, pages 2080–2094,
2021
-
[24]
Wen Wang, Bozhen Fang, Chenchen Jing, Yongliang Shen, Yangyi Shen, Qiuyu Wang, Hao Ouyang, Hao Chen, and Chunhua Shen. Time is a feature: Exploiting temporal dynamics in diffusion language models.arXiv preprint arXiv:2508.09138,
-
[25]
Qingyan Wei, Yaojie Zhang, Zhiyuan Liu, Dongrui Liu, and Linfeng Zhang. Accelerating diffusion large language models with slowfast sampling: The three golden principles.arXiv preprint arXiv:2506.10848,
-
[26]
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding.arXiv preprint arXiv:2505.22618,
-
[27]
Jingxuan Wu, Zhenglin Wan, Xingrui Yu, Yuzhe Yang, Yiqiao Huang, Ivor Tsang, and Yang You. Time-annealed perturbation sampling: Diverse generation for diffusion language models.arXiv preprint arXiv:2601.22629,
-
[28]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487,
work page internal anchor Pith review arXiv
-
[29]
Breaking Block Boundaries: Anchor-based History-stable Decoding for Diffusion Large Language Models
Shun Zou, Yong Wang, Zehui Chen, Lin Chen, Chongyang Tao, Feng Zhao, and Xiangxiang Chu. Breaking block boundaries: Anchor-based history-stable decoding for diffusion large language models.arXiv preprint arXiv:2604.08964,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
12 A Related Works Diffusion Language ModelsWhile autoregressive (AR) models dominate natural language genera- tion, their strict left-to-right causal nature restricts bidirectional context modeling and suffers from error propagation. Diffusion Language Models (DLMs) have emerged as a compelling alternative, evolving from early continuous formulations [Ha...
2023
-
[31]
and SlowFast sampling [Wei et al., 2025] modulate decoding step sizes to accelerate parallel generation without compromising output quality. Advancing inference-time scaling and reasoning, techniques like trajectory refinement [Dang et al., 2025] and time-annealed perturbation sampling [Wu et al., 2026] significantly boost generation fidelity. Additionall...
2025
-
[32]
Datasets: •GSM8K[Cobbe et al., 2021]: MIT License
11:ComputeL cond,P t,D (i) t ,S (i) t ,K t, ˜Xt, ˆLt 12:// Step 6: Monitor mean instability for early-exit 13:¯s t ← 1 |Ut| P j∈Ut S(j) t 14:if¯s t < τthen▷HD tokens have sufficiently converged 15:Decodemadditional high-confidence tokens in parallel via ˆLt 16:early_exit←True 17:else 18:// Normal decoding step 19:UpdateX t by unmasking high-confidence tok...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.