Recognition: unknown
Using LLMs in Software Design: An Empirical Study of GitHub and A Practitioner Survey
Pith reviewed 2026-05-09 14:36 UTC · model grok-4.3
The pith
An empirical study of 291 GitHub ChatGPT conversations and 65 practitioner surveys maps nine categories of software design tasks where LLMs are used, along with interaction patterns, seven benefits, and six limitations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
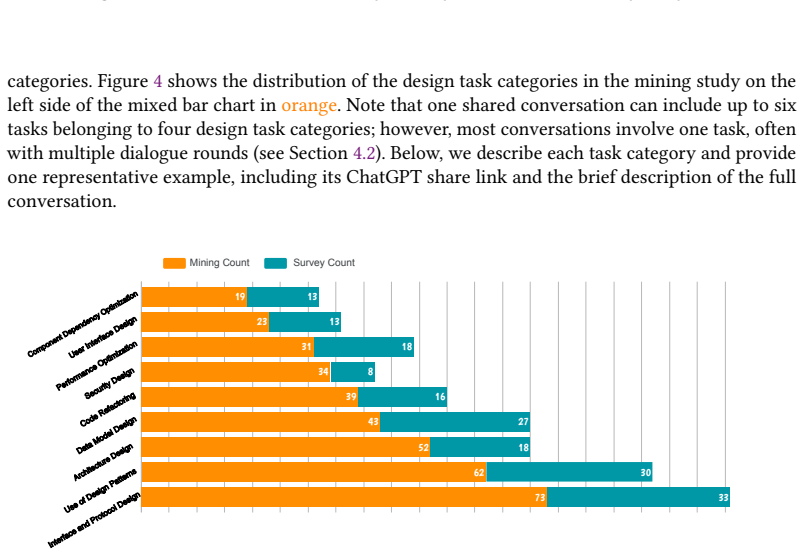
Mining 291 developer-ChatGPT conversations shared on GitHub and surveying 65 software practitioners reveals nine distinct categories of design tasks supported by the model, such as architecture design, data model design, and application of design patterns. Interactions center on knowledge acquisition and design-related code generation, with the majority of tasks occurring at the detailed design level. Developers report seven benefits including better technology selection and early detection of design flaws, alongside six limitations such as overly lengthy or difficult-to-read outputs, generation of inexecutable or incorrect code, and hallucinations arising from heavy context dependence.
What carries the argument
The mixed-methods empirical analysis that extracts task categories, interaction modes, benefits, and limitations directly from GitHub conversation logs and practitioner survey responses.
If this is right
- Design tools can be specialized to assist at the detailed level where most current LLM use occurs.
- Practitioners gain concrete guidance on prompting strategies that maximize benefits like technology selection while reducing risks of incorrect code.
- Integration efforts should prioritize mechanisms for context management to limit hallucinations.
- The identified task categories provide a starting taxonomy for evaluating future LLM design assistants.
- Training programs for developers can incorporate the observed interaction patterns to improve effective use of these models.
Where Pith is reading between the lines
- The tension between benefits and limitations implies that effective LLM integration in design will require hybrid human-AI workflows rather than full automation.
- Findings on context dependence suggest that pairing LLMs with project-specific knowledge bases could reduce hallucinations more reliably than general prompting alone.
- The concentration at detailed design level raises the question of whether LLMs could scale to earlier architectural stages if supplied with higher-level constraints.
Load-bearing premise
The collected GitHub conversations and survey responses form a representative sample of how software developers in general use LLMs for design work.
What would settle it
A larger, independently collected dataset of LLM-assisted design sessions from closed-source projects or enterprise tools that shows markedly different task distributions, interaction patterns, or net negative instead of mixed outcomes would undermine the reported categories and balance of benefits versus limitations.
Figures







read the original abstract
Recent advancements in Large Language Models (LLMs) have demonstrated significant potential across a wide range of software engineering tasks, including software design, an area traditionally regarded as highly dependent on human expertise and judgment. However, there has been little research focusing on how LLMs are used in software design, nor on the associated benefits and drawbacks. This paper aims to bridge this gap by empirically investigating how software developers utilize LLMs in the context of software design. We conduct a mixed-methods study, combining a mining study of 291 developer-ChatGPT conversations shared on GitHub with a survey of 65 software practitioners. Our findings reveal nine distinct categories of design tasks supported by ChatGPT, including architecture design, data model design, and the use of design patterns. We further characterize developer-ChatGPT interactions, showing that developers primarily use ChatGPT for knowledge acquisition and design-related code generation, with most tasks situated at the detailed design level. The study identifies seven key benefits of utilizing LLMs in software design as perceived by developers, such as better technology selection and the early detection of design flaws. We also uncover six limitations, including the generation of overly lengthy and difficult-to-read outputs, the creation of inexecutable or incorrect code, and a heavy reliance on context that can lead to hallucinated results. These findings provide an evidence-based characterization of current LLM use in software design from both open-source and practitioner perspectives, highlighting a tension between perceived benefits and limitations, which lays a foundation for future research and the development of effective techniques and tools to integrate LLMs into software design practices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a mixed-methods empirical study that combines mining of 291 developer-ChatGPT conversations shared on GitHub with a survey of 65 software practitioners. It identifies nine categories of design tasks supported by LLMs (e.g., architecture design, data model design, design patterns), characterizes interactions as primarily focused on knowledge acquisition and design-related code generation at the detailed-design level, and reports seven perceived benefits (e.g., improved technology selection, early flaw detection) alongside six limitations (e.g., overly lengthy outputs, inexecutable code, context-dependent hallucinations).
Significance. If the samples are shown to be sufficiently representative, the work supplies a timely, evidence-based snapshot of LLM adoption in a traditionally human-centric SE activity. The mixed-methods design linking public conversation logs to practitioner perceptions is a positive feature, and the explicit enumeration of benefits versus limitations could usefully inform both tool design and follow-on studies. The absence of parameter fitting or circular derivations is also a methodological strength.
major comments (4)
- [§3.1] §3.1 (GitHub mining): The paper does not specify the exact search queries, inclusion/exclusion criteria, or temporal window used to collect the 291 conversations, nor does it report how many candidate threads were discarded as non-design-related; without these details the claim that the sample captures 'real-world' use cannot be evaluated.
- [§3.2] §3.2 (Survey): The recruitment method, response rate, and demographic profile of the 65 respondents are not reported, leaving open the possibility of convenience or self-selection bias that could systematically over-represent developers already favorably disposed toward LLMs.
- [§4] §4 (Qualitative analysis): No information is given on the coding scheme development, number of coders, inter-rater reliability statistic, or disagreement-resolution process used to derive the nine task categories, seven benefits, and six limitations; standard practice in empirical SE requires these metrics to support reliability of the thematic findings.
- [§6] §6 (Threats to validity): The discussion acknowledges self-selection but does not quantify or bound its likely impact on the reported distributions (e.g., over-representation of successful interactions), which is load-bearing for the general statements about 'how software developers utilize LLMs'.
minor comments (2)
- [Abstract / §1] The abstract and §1 could more explicitly state the final sample sizes (291 conversations, 65 respondents) rather than burying them in the methods section.
- [Figure 1] Figure 1 (interaction characterization) would benefit from an accompanying table that reports exact percentages or counts for each interaction type to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our paper. We address each of the major comments below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (GitHub mining): The paper does not specify the exact search queries, inclusion/exclusion criteria, or temporal window used to collect the 291 conversations, nor does it report how many candidate threads were discarded as non-design-related; without these details the claim that the sample captures 'real-world' use cannot be evaluated.
Authors: We will update Section 3.1 to include the specific search queries used for mining the GitHub conversations, the inclusion and exclusion criteria applied to identify design-related threads, the temporal window of data collection, and the number of candidate threads that were reviewed and discarded. These details will strengthen the transparency of our data collection process and allow for better evaluation of the sample's representativeness. revision: yes
-
Referee: [§3.2] §3.2 (Survey): The recruitment method, response rate, and demographic profile of the 65 respondents are not reported, leaving open the possibility of convenience or self-selection bias that could systematically over-represent developers already favorably disposed toward LLMs.
Authors: We will revise Section 3.2 to report the survey recruitment methods, including the platforms and channels used to reach participants, the response rate based on the number of completed surveys out of those invited or accessed, and a demographic breakdown of the 65 respondents. This will help readers assess potential biases such as self-selection. revision: yes
-
Referee: [§4] §4 (Qualitative analysis): No information is given on the coding scheme development, number of coders, inter-rater reliability statistic, or disagreement-resolution process used to derive the nine task categories, seven benefits, and six limitations; standard practice in empirical SE requires these metrics to support reliability of the thematic findings.
Authors: We will expand Section 4 to describe the qualitative coding process in detail, including how the coding scheme was developed, the number of coders involved, any inter-rater reliability statistics computed, and how disagreements were resolved. If formal reliability metrics were not calculated, we will explain the collaborative approach taken to ensure consistency in deriving the categories, benefits, and limitations. revision: partial
-
Referee: [§6] §6 (Threats to validity): The discussion acknowledges self-selection but does not quantify or bound its likely impact on the reported distributions (e.g., over-representation of successful interactions), which is load-bearing for the general statements about 'how software developers utilize LLMs'.
Authors: We will enhance the threats to validity section (Section 6) by providing a more thorough discussion of self-selection bias, including potential impacts on the distributions of tasks, benefits, and limitations (such as over-representation of successful interactions in public GitHub shares). We will bound these effects where possible and clarify the scope of our general statements about LLM utilization in software design. revision: yes
Circularity Check
No circularity: empirical claims rest on direct analysis of external GitHub conversations and survey responses
full rationale
The paper conducts a mixed-methods empirical study by collecting and analyzing 291 developer-ChatGPT conversations from GitHub plus 65 practitioner survey responses. All reported findings—nine task categories, interaction patterns, seven benefits, and six limitations—are obtained through standard qualitative coding and quantitative summarization of this primary external data. No mathematical derivations, equations, fitted parameters presented as predictions, or self-citation chains appear in the derivation of the central claims. The analysis is self-contained against the collected artifacts; representativeness concerns affect external validity but do not create internal circularity by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 291 GitHub conversations and 65 survey responses constitute a representative sample of developer-LLM interactions in software design.
Reference graph
Works this paper leans on
-
[1]
Shrikara Arun, Meghana Tedla, and Karthik Vaidhyanathan. 2025. LLMs for Generation of Architectural Components: An Exploratory Empirical Study in the Serverless World. InProceedings of the 22nd IEEE International Conference on Software Architecture (ICSA). IEEE, 25–36
2025
-
[2]
James, and Nadia Polikarpova
Shraddha Barke, Michael B. James, and Nadia Polikarpova. 2023. Grounded Copilot: How Programmers Interact with Code-Generating Models.Proceedings of the ACM on Programming Languages7, OOPSLA1 (2023), 85–111
2023
- [3]
-
[4]
1996.Pattern-Oriented Software Architecture - Volume 1: A System of Patterns
Frank Buschmann, Regine Meunier, Hans Rohnert, Peter Sommerlad, and Michael Stal. 1996.Pattern-Oriented Software Architecture - Volume 1: A System of Patterns. Wiley Publishing
1996
-
[5]
John L Campbell, Charles Quincy, Jordan Osserman, and Ove K Pedersen. 2013. Coding in-depth semistructured interviews: Problems of unitization and intercoder reliability and agreement.Sociological Methods & Research42, 3 (2013), 294–320
2013
-
[6]
2014.Constructing Grounded Theory
Kathy Charmaz. 2014.Constructing Grounded Theory. Sage Publishing
2014
-
[7]
Daniele De Bari, Giacomo Garaccione, Riccardo Coppola, Marco Torchiano, and Luca Ardito. 2024. Evaluating Large Language Models in Exercises of UML Class Diagram Modeling. InProceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM). ACM, 393–399
2024
-
[8]
Rudra Dhar, Karthik Vaidhyanathan, and Vasudeva Varma. 2024. Can LLMs Generate Architectural Design Decisions? - An Exploratory Empirical Study. InProceedings of the 21st IEEE International Conference on Software Architecture (ICSA). IEEE, 79–89
2024
-
[9]
Andrés Díaz-Pace, Antonela Tommasel, and Rafael Capilla
J. Andrés Díaz-Pace, Antonela Tommasel, and Rafael Capilla. 2024. Helping Novice Architects to Make Quality Design Decisions Using LLM-Based Assistants. InProceedings of the 17th European Conference on Software Architecture (ECSA). Springer, 324–332
2024
-
[10]
Matteo Esposito, Xiaozhou Li, Sergio Moreschini, Noman Ahmad, Tomas Cerny, Karthik Vaidhyanathan, Valentina Lenarduzzi, and Davide Taibi. 2026. Generative AI for Software Architecture: Applications, Challenges, and Future Directions.Journal of Systems and Software231 (2026), 112607
2026
-
[11]
Davide Falessi, Lionel C Briand, Giovanni Cantone, Rafael Capilla, and Philippe Kruchten. 2013. The value of design rationale information.ACM Transactions on Software Engineering and Methodology22, 3 (2013), 1–32
2013
-
[12]
Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M Zhang. 2023. Large language models for software engineering: Survey and open problems. InProceedings of the IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE). IEEE, 31–53
2023
-
[13]
2003.The Survey Handbook
Arlene Fink. 2003.The Survey Handbook. Sage Publishing
2003
-
[14]
1995.Design Patterns: Elements of Reusable Object- Oriented Software
Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides. 1995.Design Patterns: Elements of Reusable Object- Oriented Software. Addison-Wesley
1995
-
[15]
1994.An Introduction to Software Architecture
David Garlan and Mary Shaw. 1994.An Introduction to Software Architecture. Technical Report. Carnegie Mellon University, Software Engineering Institute. https://resources.sei.cmu.edu/library/asset-view.cfm?assetid=5141
1994
-
[16]
Polydoros Giannouris and Sophia Ananiadou. 2025. NOMAD: A Multi-Agent LLM System for UML Class Diagram Generation from Natural Language Requirements.arXiv preprint arXiv:2511.22409(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
GitHub. 2022. Research: Quantifying GitHub Copilot’s impact on developer productivity and happiness. GitHub Blog
2022
-
[18]
Github REST API documentation. 2022. Retrieved April 12, 2025 from https://docs.github.com/en/rest?apiVersion=2022- 11-28
2022
-
[19]
Binnur Görer and Fatma Başak Aydemir. 2023. Generating Requirements Elicitation Interview Scripts with Large Language Models. InProceedings of the 31st IEEE International Requirements Engineering Conference Workshops (REW). IEEE, 44–51
2023
-
[20]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
-
[21]
Jasmin Jahic and Ashkan Sami. 2024. State of Practice: LLMs in Software Engineering and Software Architecture. In Proceedings of the 21st IEEE International Conference on Software Architecture Companion (ICSA-C). IEEE, 311–318
2024
-
[22]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?. InProceedings of the International Conference ACM Trans. Softw. Eng. Methodol., Vol. 0, No. 0, Article 0. Publication date: 2026. 0:28 Wang et al. on Learning Representations (IC...
2024
-
[23]
Parampreet Kaur, Jill Stoltzfus, and Vikas Yellapu. 2018. Descriptive statistics.International Journal of Academic Medicine4, 1 (2018), 60–63
2018
-
[24]
Kitchenham and Shari L
Barbara A. Kitchenham and Shari L. Pfleeger. 2008.Personal Opinion Surveys. Springer, Chapter 3, 63–92
2008
-
[25]
Ruiyin Li, Peng Liang, Mohamed Soliman, and Paris Avgeriou. 2022. Understanding software architecture erosion: A systematic mapping study.Journal of Software: Evolution and Process34, 3 (2022), e2423
2022
-
[26]
Ruiyin Li, Peng Liang, Yifei Wang, Yangxiao Cai, Weisong Sun, and Zengyang Li. 2026. Unveiling the Role of ChatGPT in Software Development: Insights from Developer-ChatGPT Interactions on GitHub.ACM Transactions on Software Engineering and Methodology(2026)
2026
-
[27]
Yishu Li, Jacky Keung, Xiaoxue Ma, Chun Yong Chong, Jingyu Zhang, and Yihan Liao. 2024. LLM-Based Class Diagram Derivation from User Stories with Chain-of-Thought Promptings. InProceedings of the 48th IEEE Annual Computers, Software, and Applications Conference (COMPSAC). IEEE, 45–50
2024
-
[28]
Jenny T Liang, Chenyang Yang, and Brad A Myers. 2024. A large-scale survey on the usability of AI programming assis- tants: Successes and challenges. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering (ICSE). ACM, 1–13
2024
-
[29]
Hussein Mozannar, Gagan Bansal, Adam Fourney, and Eric Horvitz. 2024. Reading between the lines: Modeling user behavior and costs in AI-assisted programming. InProceedings of the 44th CHI Conference on Human Factors in Computing Systems (CHI). ACM, 1–16
2024
-
[30]
Mohit Pandey, Tanmay Chand, Jennifer Horkoff, Miroslaw Staron, Miroslaw Ochodek, and Milos Durisic. 2025. Design Pattern Recognition: A Study of Large Language Models.Empirical Software Engineering30, 3, Article 69 (2025)
2025
-
[31]
Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. 2023. The Impact of AI on Developer Productivity: Evidence from GitHub Copilot.Microsoft Research(2023)
2023
-
[32]
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. ChatDev: Communicative Agents for Software Development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). ACL, 15174–15186
2024
-
[33]
2024.Requirements Engineering Using Generative AI: Prompts and Prompting Patterns
Krishna Ronanki, Beatriz Cabrero-Daniel, Jennifer Horkoff, and Christian Berger. 2024.Requirements Engineering Using Generative AI: Prompts and Prompting Patterns. Springer, Chapter 5, 109–127
2024
-
[34]
Ross, Fernando Martinez, Stephanie Houde, Michael Muller, and Justin D
Steven I. Ross, Fernando Martinez, Stephanie Houde, Michael Muller, and Justin D. Weisz. 2023. The Programmer’s Assistant: Conversational Interaction with a Large Language Model for Software Development. InProceedings of the 28th International Conference on Intelligent User Interfaces (IUI). ACM, 491–514
2023
-
[35]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, et al. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools.arXiv preprint arXiv:2302.04761(2023)
work page internal anchor Pith review arXiv 2023
- [36]
-
[37]
Antony Tang and Hans Van Vliet. 2009. Modeling constraints improves software architecture design reasoning. In Proceedings of the Joint Working IEEE/IFIP Conference on Software Architecture & European Conference on Software Architecture (WICSA/ECSA). IEEE, 253–256
2009
-
[38]
Dan Tofan, Matthias Galster, and Paris Avgeriou. 2013. Difficulty of Architectural Decisions – A Survey with Professional Architects. InProceedings of the 7th European Conference on Software Architecture (ECSA). Springer, 192–199
2013
-
[39]
Yifei Wang, Ruiyin Li, Peng Liang, Yangxiao Cai, Zengyang Li, and Mojtaba Shahin. 2026. Replication Package of the Paper: Using LLMs in Software Design: An Empirical Study of GitHub and A Practitioner Survey. https: //github.com/WhitenWhiten/LLM4Design
2026
- [40]
-
[41]
2012.Experimentation in Software Engineering
Claes Wohlin, Per Runeson, Martin Höst, Magnus C Ohlsson, Björn Regnell, and Anders Wesslén. 2012.Experimentation in Software Engineering. Springer Science & Business Media
2012
-
[42]
Chen Yang, Peng Liang, and Paris Avgeriou. 2018. Assumptions and their management in software development: A systematic mapping study.Information and Software Technology94 (2018), 82–110
2018
-
[43]
Shunyu Yao, Jeffrey Zhao, Dian Yu, et al. 2022. ReAct: Synergizing Reasoning and Acting in Language Models.arXiv preprint arXiv:2210.03629(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Jiarui Zhang et al . 2024. Agentless: Demystifying LLM-based Software Engineering Agents.arXiv preprint arXiv:2407.01489(2024). ACM Trans. Softw. Eng. Methodol., Vol. 0, No. 0, Article 0. Publication date: 2026. Using LLMs in Software Design: An Empirical Study of GitHub and A Practitioner Survey 0:29
work page internal anchor Pith review arXiv 2024
-
[45]
Xiyu Zhou, Ruiyin Li, Peng Liang, Beiqi Zhang, Mojtaba Shahin, Zengyang Li, and Chen Yang. 2025. Using LLMs in generating design rationale for software architecture decisions.ACM Transactions on Software Engineering and Methodology(2025). ACM Trans. Softw. Eng. Methodol., Vol. 0, No. 0, Article 0. Publication date: 2026
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.