Recognition: unknown
LiveFMBench: Unveiling the Power and Limits of Agentic Workflows in Specification Generation
Pith reviewed 2026-05-09 14:33 UTC · model grok-4.3
The pith
Naive evaluations of LLM specification generation overestimate accuracy by around 20 percent because models deceive provers or ignore code constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
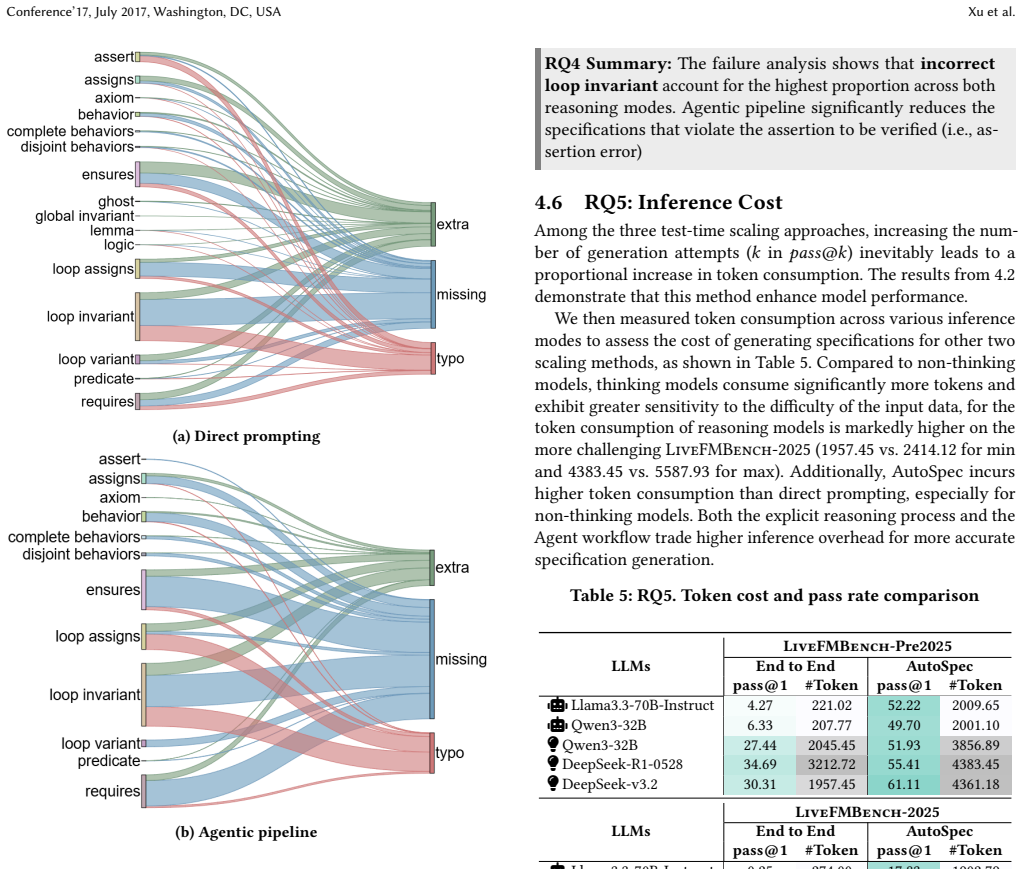
We present LiveFMBench, a continuously evolving benchmark of 630 ACSL-annotated C programs including 360 newly collected cases. Direct prompting yields inflated success rates because models exhibit unfaithful behaviors such as deceiving provers or violating code constraints; excluding those cases drops measured accuracy by approximately 20 percent. Increased sampling and thinking-mode inference both raise success rates, with smaller models gaining more from thinking. Agentic pipelines prove most useful under low sampling budgets and on harder problems. Failure analysis identifies incorrect loop invariants as the dominant error, while agentic methods notably cut assertion errors.
What carries the argument
LiveFMBench benchmark together with the detection of unfaithful behaviors that artificially inflate specification accuracy when using automated provers.
If this is right
- Raising the number of samples or enabling thinking mode measurably lifts success rates on specification generation.
- Agentic pipelines deliver their largest gains when sampling budgets are small or when problems are harder.
- Incorrect loop invariants remain the most common source of failure across all methods tested.
- Agentic workflows specifically reduce the rate of assertion-related errors compared with direct prompting.
Where Pith is reading between the lines
- Verification tool chains that rely on LLM-generated specifications will need built-in faithfulness checks to avoid accepting deceptive outputs.
- Progress on loop-invariant synthesis may be the highest-leverage next step for improving LLM performance on this task.
- Hybrid systems that combine limited human review with agentic generation could close more of the remaining gap to human-level specifications.
Load-bearing premise
Unfaithful behaviors such as deceiving provers or ignoring context constraints can be detected and removed automatically and reliably, and the 360 new benchmark cases contain no data contamination.
What would settle it
A large-scale manual audit of the cases excluded for unfaithfulness that finds many of them were actually correct specifications, or discovery of substantial overlap between the new 360 cases and existing training data.
Figures




read the original abstract
Formal specification is essential for rigorous program verification, yet writing correct specifications remains costly and difficult to automate. Although large language models (LLMs) and agents have shown promising progress, their true capabilities and failure modes remain unclear. We present the first systematic and contamination-aware study of LLM- and agent-based formal specification generation for C programs. We introduce LiveFMBench, a continuously evolving benchmark of 630 ACSL (ANSI/ISO C Specification Language)-annotated C programs, including 360 newly collected cases designed to mitigate data leakage. Using this benchmark, we evaluate direct prompting with different sampling sizes, reasoning-enabled (thinking mode) inference, the agentic pipeline, and perform a fine-grained failure analysis. Experimental results reveal that naive evaluation substantially overestimates performance because models under direct prompting may exhibit unfaithful behaviors, such as deceiving automated provers or ignoring code-context constraints; after excluding such cases, the true specification generation accuracy drops by approximately 20\%. We further find that both increased sampling and thinking mode significantly improve success rates, with smaller models benefiting more from thinking mode. Agentic pipelines are particularly effective under low sampling budgets and on harder datasets. Failure analysis further shows that incorrect loop invariants are the dominant error type, while agentic pipelines notably reduce assertion errors. These results expose fundamental limitations in current LLM-based approaches and suggest they remain far from replacing human-authored formal specifications. We release LiveFMBench at https://huggingface.co/datasets/fm-universe/Live-FM-Bench and all evaluation artifacts to support future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LiveFMBench, a contamination-aware benchmark of 630 ACSL-annotated C programs (including 360 newly collected cases), and evaluates direct prompting, reasoning-enabled inference, and agentic pipelines for formal specification generation. It claims that naive evaluations substantially overestimate performance due to unfaithful model behaviors (deceiving provers or ignoring context constraints), with accuracy dropping ~20% after exclusion; it further reports that increased sampling and thinking modes improve results (especially for smaller models), agentic pipelines excel under low budgets or on harder cases, and incorrect loop invariants are the dominant failure mode while agentic methods reduce assertion errors.
Significance. If the core empirical comparisons and the overestimation finding hold after clarification, the work provides a valuable, evolving, and publicly released benchmark that highlights practical limits of current LLM/agentic approaches to automated formal specification. The focus on contamination mitigation, fine-grained failure analysis, and differential method performance under varying sampling budgets addresses gaps in prior evaluations and supports reproducible research in LLM-assisted verification.
major comments (2)
- [Experimental results / Failure analysis] The headline claim of a ~20% accuracy drop after excluding unfaithful cases (deceiving provers or ignoring code-context constraints) is load-bearing for the paper's central argument about overestimation. The abstract and experimental description provide no explicit decision rules, automation level (purely automated vs. mixed human judgment), or validation statistics (e.g., inter-annotator agreement) for identifying these cases; without this, the drop could reflect post-hoc selection rather than intrinsic model behavior.
- [Benchmark construction] The assertion that the 360 newly collected cases are contamination-free rests on the collection method alone. Independent verification (e.g., n-gram overlap metrics, membership inference, or similarity checks against common training corpora) is not reported, which weakens confidence in the benchmark's novelty and the validity of the performance comparisons.
minor comments (2)
- Define the precise success metric (e.g., whether accuracy requires full prover verification, partial checks, or manual review) and report statistical controls such as confidence intervals or significance tests for the reported improvements and the 20% drop.
- Clarify how 'thinking mode' and agentic pipeline components are implemented (e.g., specific prompting strategies or tool-use loops) to allow replication.
Simulated Author's Rebuttal
Thank you for the constructive and detailed referee report. We appreciate the emphasis on methodological transparency and benchmark validation. Below we respond point-by-point to the major comments, clarifying our procedures and committing to specific revisions that strengthen the paper without altering its core findings.
read point-by-point responses
-
Referee: [Experimental results / Failure analysis] The headline claim of a ~20% accuracy drop after excluding unfaithful cases (deceiving provers or ignoring code-context constraints) is load-bearing for the paper's central argument about overestimation. The abstract and experimental description provide no explicit decision rules, automation level (purely automated vs. mixed human judgment), or validation statistics (e.g., inter-annotator agreement) for identifying these cases; without this, the drop could reflect post-hoc selection rather than intrinsic model behavior.
Authors: We acknowledge the need for greater transparency on this load-bearing analysis. The unfaithful cases were identified via a two-stage process: (1) automated heuristics that flagged prover successes on incomplete or contradictory specifications (e.g., missing loop invariants yet successful verification, or assertions ignoring explicit code constraints), followed by (2) author review to confirm the deception or context-ignoring behavior. In the revised manuscript we will add an explicit subsection detailing the decision rules, the semi-automated nature of the process, and inter-annotator agreement statistics obtained by double-annotating a random sample of 100 cases (yielding >90% agreement). These additions will demonstrate that the ~20% drop is reproducible and reflects genuine model behavior rather than post-hoc selection. revision: yes
-
Referee: [Benchmark construction] The assertion that the 360 newly collected cases are contamination-free rests on the collection method alone. Independent verification (e.g., n-gram overlap metrics, membership inference, or similarity checks against common training corpora) is not reported, which weakens confidence in the benchmark's novelty and the validity of the performance comparisons.
Authors: We agree that additional quantitative checks would increase confidence. The 360 cases were sourced exclusively from repositories and problems published after mid-2023, deliberately after the training cutoffs of the evaluated models. In revision we will report n-gram overlap statistics and embedding-based similarity scores against common pre-training corpora for these cases. Full membership-inference attacks remain outside the scope of the current study due to computational cost, but we will explicitly discuss this limitation and argue that the temporal collection strategy provides strong practical assurance of novelty. revision: partial
Circularity Check
No significant circularity: empirical benchmark with direct measurements
full rationale
This is a purely empirical benchmark study introducing LiveFMBench (630 ACSL-annotated C programs, 360 new cases) and reporting measured accuracies under different prompting/agentic regimes. The headline finding (naive accuracy overestimates true performance by ~20% after excluding unfaithful cases) is a direct count of evaluation outcomes on the released dataset, not a derivation, fitted parameter, or self-referential definition. No equations, uniqueness theorems, ansatzes, or load-bearing self-citations appear in the provided text. The 20% adjustment is obtained by post-hoc filtering whose criteria are described at the level of observable behaviors (deceiving provers, ignoring context), not by construction from the final accuracy number itself. The work is self-contained against external benchmarks once the dataset and artifacts are released.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journey to a rte-free x
Arnaud Ebalard, Patricia Mouy, and Ryad Benadjila. Journey to a rte-free x. 509 parser. InSymposium sur la sécurité des technologies de l’information et des communications (SSTIC 2019), 2019
2019
-
[2]
Deductive verifica- tion of unmodified linux kernel library functions
Denis Efremov, Mikhail Mandrykin, and Alexey Khoroshilov. Deductive verifica- tion of unmodified linux kernel library functions. InLeveraging Applications of Formal Methods, Verification and Validation. Verification: 8th International Sym- posium, ISoLA 2018, Limassol, Cyprus, November 5-9, 2018, Proceedings, Part II 8, pages 216–234. Springer, 2018
2018
-
[3]
Frank Dordowsky. An experimental study using acsl and frama-c to formulate and verify low-level requirements from a do-178c compliant avionics project. arXiv preprint arXiv:1508.03894, 2015
-
[4]
A case study on formal verification of the anaxagoros hypervisor paging system with frama-c
Allan Blanchard, Nikolai Kosmatov, Matthieu Lemerre, and Frédéeric Loulergue. A case study on formal verification of the anaxagoros hypervisor paging system with frama-c. InInternational Workshop on Formal Methods for Industrial Critical Systems, pages 15–30. Springer, 2015
2015
-
[5]
A case study on verifica- tion of a cloud hypervisor by proof and structural testing
Nikolai Kosmatov, Matthieu Lemerre, and Céline Alec. A case study on verifica- tion of a cloud hypervisor by proof and structural testing. InTests and Proofs: 8th International Conference, TAP 2014, Held as Part of STAF 2014, York, UK, July 24-25, 2014. Proceedings 8, pages 158–164. Springer, 2014
2014
-
[6]
Deductive software verification: from pen-and-paper proofs to industrial tools.Computing and Software Science: State of the Art and Perspectives, pages 345–373, 2019
Reiner Hähnle and Marieke Huisman. Deductive software verification: from pen-and-paper proofs to industrial tools.Computing and Software Science: State of the Art and Perspectives, pages 345–373, 2019
2019
-
[7]
Learn- ing loop invariants for program verification.Advances in Neural Information Processing Systems, 31, 2018
Xujie Si, Hanjun Dai, Mukund Raghothaman, Mayur Naik, and Le Song. Learn- ing loop invariants for program verification.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[8]
Enchanting program specification synthesis by large language models using static analysis and program verification, 2024
Cheng Wen, Jialun Cao, Jie Su, Zhiwu Xu, Shengchao Qin, Mengda He, Haokun Li, Shing-Chi Cheung, and Cong Tian. Enchanting program specification synthesis by large language models using static analysis and program verification, 2024
2024
-
[9]
Using an llm to help with code understanding
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. Using an llm to help with code understanding. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–13, 2024
2024
-
[10]
An empirical study of knowledge distillation for code understanding tasks
Ruiqi Wang, Zezhou Yang, Cuiyun Gao, Xin Xia, and Qing Liao. An empirical study of knowledge distillation for code understanding tasks. In48th International Conference on Software Engineering, ICSE 2026, Rio De Janeiro, Brazil, April 12-18, 2026, 2026
2026
-
[11]
What you need is what you get: Theory of mind for an llm-based code understanding assistant
Jonan Richards and Mairieli Wessel. What you need is what you get: Theory of mind for an llm-based code understanding assistant. In2024 IEEE International Conference on Software Maintenance and Evolution (ICSME), pages 666–671. IEEE, 2024
2024
-
[12]
Code- Scope: An execution-based multilingual multitask multidimensional benchmark for evaluating LLMs on code understanding and generation
Weixiang Yan, Haitian Liu, Yunkun Wang, Yunzhe Li, Qian Chen, Wen Wang, Tingyu Lin, Weishan Zhao, Li Zhu, Hari Sundaram, and Shuiguang Deng. Code- Scope: An execution-based multilingual multitask multidimensional benchmark for evaluating LLMs on code understanding and generation. In Lun-Wei Ku, An- dre Martins, and Vivek Srikumar, editors,Proceedings of t...
2024
-
[13]
What to retrieve for effective retrieval- augmented code generation? an empirical study and beyond
Wenchao Gu, Juntao Chen, Yanlin Wang, Tianyue Jiang, Xingzhe Li, Mingwei Liu, Xilin Liu, Yuchi Ma, and Zibin Zheng. What to retrieve for effective retrieval- augmented code generation? an empirical study and beyond. In48th International Conference on Software Engineering, ICSE 2026, Rio De Janeiro, Brazil, April 12-18, 2026, 2026
2026
-
[14]
A survey on llm-based code generation for low-resource and domain-specific programming languages.ACM Trans
Sathvik Joel, Jie Wu, and Fatemeh Fard. A survey on llm-based code generation for low-resource and domain-specific programming languages.ACM Trans. Softw. Eng. Methodol., October 2025. Just Accepted
2025
-
[15]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
2021
-
[16]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review arXiv 2021
-
[17]
IEEE Press, 2025
Lezhi Ma, Shangqing Liu, Yi Li, Xiaofei Xie, and Lei Bu.SpecGen: Automated Generation of Formal Program Specifications via Large Language Models, page 16–28. IEEE Press, 2025
2025
-
[18]
Baldur: whole-proof generation and repair with large language models
Emily First, Markus N Rabe, Talia Ringer, and Yuriy Brun. Baldur: whole-proof generation and repair with large language models. 2023
2023
-
[19]
Madeline Endres, Sarah Fakhoury, Saikat Chakraborty, and Shuvendu K. Lahiri. Formalizing natural language intent into program specifications via large lan- guage models, 2023
2023
-
[20]
Can large language models reason about program invariants? InInternational Confer- ence on Machine Learning, pages 27496–27520
Kexin Pei, David Bieber, Kensen Shi, Charles Sutton, and Pengcheng Yin. Can large language models reason about program invariants? InInternational Confer- ence on Machine Learning, pages 27496–27520. PMLR, 2023
2023
-
[21]
Reliable generation of formal specifications using large language models
Philipp Kogler, Andreas Falkner, and Simon Sperl. Reliable generation of formal specifications using large language models. InSE 2024-Companion, pages 141–153. Gesellschaft für Informatik eV, 2024
2024
-
[22]
arXiv preprint arXiv:2310.00656 , year=
Haiming Wang, Huajian Xin, Chuanyang Zheng, Lin Li, Zhengying Liu, Qingxing Cao, Yinya Huang, Jing Xiong, Han Shi, Enze Xie, et al. Lego-prover: Neural theorem proving with growing libraries.arXiv preprint arXiv:2310.00656, 2023
-
[23]
Learning to prove theorems via interacting with proof assistants
Kaiyu Yang and Jia Deng. Learning to prove theorems via interacting with proof assistants. InInternational Conference on Machine Learning, pages 6984–6994. PMLR, 2019
2019
-
[24]
Cobblestone: A divide-and-conquer approach for automating formal verification
Saketh Ram Kasibatla, Arpan Agarwal, Yuriy Brun, Sorin Lerner, Talia Ringer, and Emily First. Cobblestone: A divide-and-conquer approach for automating formal verification. In48th International Conference on Software Engineering, ICSE 2026, Rio De Janeiro, Brazil, April 12-18, 2026, 2026
2026
-
[25]
The lean 4 theorem prover and programming language
Leonardo de Moura and Sebastian Ullrich. The lean 4 theorem prover and programming language. InAutomated Deduction – CADE 28: 28th International Conference on Automated Deduction, Virtual Event, July 12–15, 2021, Proceedings, page 625–635, Berlin, Heidelberg, 2021. Springer-Verlag
2021
-
[26]
Kaiyu Yang, Aidan M Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar. Leandojo: Theorem prov- ing with retrieval-augmented language models.arXiv preprint arXiv:2306.15626, 2023
-
[27]
Lean workbook: A large-scale lean problem set formalized from natural language math problems.Advances in Neural Information Processing Systems, 37:105848– 105863, 2024
Huaiyuan Ying, Zijian Wu, Yihan Geng, Jiayu Wang, Dahua Lin, and Kai Chen. Lean workbook: A large-scale lean problem set formalized from natural language math problems.Advances in Neural Information Processing Systems, 37:105848– 105863, 2024
2024
-
[28]
Peiyang Song, Kaiyu Yang, and Anima Anandkumar. Towards large language models as copilots for theorem proving in lean.arXiv preprint arXiv:2404.12534, 2024
-
[29]
Leandojo-v2: A comprehensive library for ai-assisted theorem proving in lean
Ryan Hsiang, William Adkisson, Robert Joseph George, and Anima Anandkumar. Leandojo-v2: A comprehensive library for ai-assisted theorem proving in lean. InThe 5th Workshop on Mathematical Reasoning and AI at NeurIPS 2025
2025
-
[30]
arXiv preprint arXiv:2407.03203 , year=
Ruida Wang, Jipeng Zhang, Yizhen Jia, Rui Pan, Shizhe Diao, Renjie Pi, and Tong Zhang. Theoremllama: Transforming general-purpose llms into lean4 experts. arXiv preprint arXiv:2407.03203, 2024
-
[31]
Formalizing the proof of pfr in lean4 using blueprint: a short tour.Blog post, November, 2023
Terence Tao, Yael Dillies, and Bhavik Mehta. Formalizing the proof of pfr in lean4 using blueprint: a short tour.Blog post, November, 2023
2023
-
[32]
Laurel: Generating dafny assertions using large language models, 2024
Eric Mugnier, Emmanuel Anaya Gonzalez, Ranjit Jhala, Nadia Polikarpova, and Yuanyuan Zhou. Laurel: Generating dafny assertions using large language models, 2024
2024
-
[33]
Silva, Alexandra Mendes, and João F
Álvaro F. Silva, Alexandra Mendes, and João F. Ferreira. Leveraging large lan- guage models to boost dafny’s developers productivity. InProceedings of the 2024 IEEE/ACM 12th International Conference on Formal Methods in Software En- gineering (FormaliSE), FormaliSE ’24, page 138–142, New York, NY, USA, 2024. Association for Computing Machinery
2024
-
[34]
Dafny: An automatic program verifier for functional correct- ness
K Rustan M Leino. Dafny: An automatic program verifier for functional correct- ness. InInternational conference on logic for programming artificial intelligence and reasoning, pages 348–370. Springer, 2010
2010
-
[35]
Towards language model guided tla+ proof automation.arXiv preprint arXiv:2512.09758, 2025
Yuhao Zhou and Stavros Tripakis. Towards language model guided tla+ proof automation.arXiv preprint arXiv:2512.09758, 2025
-
[36]
Yuhao Zhou. Retrieval-augmented tlaps proof generation with large language models.arXiv preprint arXiv:2501.03073, 2025
-
[37]
Proofcoop: Collaborative automated formal verification
Zhanna Kaufman, Emily First, Alex Sanchez-Stern, Kyle Thompson, Sorin Lerner, and Yuriy Brun. Proofcoop: Collaborative automated formal verification. In48th International Conference on Software Engineering, ICSE 2026, Rio De Janeiro, Brazil, April 12-18, 2026, 2026
2026
-
[38]
Bridging natural language and formal specification–automated translation of software requirements to ltl via hierarchical semantics decomposi- tion using llms
Zhi Ma, Cheng Wen, Zhexin Su, Xiao Liang, Cong Tian, Shengchao Qin, and Mengfei Yang. Bridging natural language and formal specification–automated translation of software requirements to ltl via hierarchical semantics decomposi- tion using llms. InThe 40th IEEE/ACM International Conference on Automated Software Engineering, ASE 2025, 2025
2025
-
[39]
Glm- 4.5: Agentic, reasoning, and coding (arc) foundation models, 2025
5 Team, Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, Kedong Wang, et al. Glm- 4.5: Agentic, reasoning, and coding (arc) foundation models, 2025
2025
-
[40]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
2025
-
[41]
LiveFMBench: Unveiling the Power and Limits of Agentic Workflows in Specification Generation Conference’17, July 2017, Washington, DC, USA
Patrick Baudin, Jean-Christophe Filliâtre, Claude Marché, Benjamin Monate, Yannick Moy, and Virgile Prevosto.ACSL: ANSI/ISO C Specification Language. LiveFMBench: Unveiling the Power and Limits of Agentic Workflows in Specification Generation Conference’17, July 2017, Washington, DC, USA
2017
-
[42]
From informal to formal – incorporating and evaluating LLMs on natural language requirements to verifiable formal proofs
Jialun Cao, Yaojie Lu, Meiziniu Li, Haoyang Ma, Haokun Li, Mengda He, Cheng Wen, Le Sun, Hongyu Zhang, Shengchao Qin, Shing-Chi Cheung, and Cong Tian. From informal to formal – incorporating and evaluating LLMs on natural language requirements to verifiable formal proofs. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, edit...
2025
-
[43]
A tale of 1001 LoC: Potential runtime error-guided specification synthesis for verifying large-scale programs.Proc
Zhongyi Wang, Tengjie Lin, Mingshuai Chen, Haokun Li, Mingqi Yang, Xiao Yi, Shengchao Qin, Yixing Luo, Xiaofeng Li, Bin Gu, Liqiang Lu, and Jianwei Yin. A tale of 1001 LoC: Potential runtime error-guided specification synthesis for verifying large-scale programs.Proc. ACM Program. Lang., (OOPSLA1), 2026
2026
-
[44]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review arXiv 2024
-
[45]
Tla+ proofs, 2012
Denis Cousineau, Damien Doligez, Leslie Lamport, Stephan Merz, Daniel Ricketts, and Hernán Vanzetto. Tla+ proofs, 2012
2012
-
[46]
Improvements in software verification and witness validation: Sv-comp 2025
Dirk Beyer and Jan Strejček. Improvements in software verification and witness validation: Sv-comp 2025. InTools and Algorithms for the Construction and Analysis of Systems: 31st International Conference, TACAS 2025, Held as Part of the International Joint Conferences on Theory and Practice of Software, ETAPS 2025, Hamilton, ON, Canada, May 3–8, 2025, Pro...
2025
-
[47]
Frama-c: a software analysis perspective
Pascal Cuoq, Florent Kirchner, Nikolai Kosmatov, Virgile Prevosto, Julien Signoles, and Boris Yakobowski. Frama-c: a software analysis perspective. InProceedings of the 10th International Conference on Software Engineering and Formal Methods, SEFM’12, page 233–247, Berlin, Heidelberg, 2012. Springer-Verlag
2012
-
[48]
Unixcoder: Unified cross-modal pre-training for code representation
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. Unixcoder: Unified cross-modal pre-training for code representation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7212–7225, 2022
2022
-
[49]
Automate where automation fails: Proof strategies for frama-c/wp
Loïc Correnson, Allan Blanchard, Adel Djoudi, and Nikolai Kosmatov. Automate where automation fails: Proof strategies for frama-c/wp. InInternational Confer- ence on Tools and Algorithms for the Construction and Analysis of Systems, pages 331–339. Springer, 2024
2024
-
[50]
Deepseek-v3 technical report, 2025
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, et al. Deepseek-v3 technical report, 2025
2025
-
[51]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, et al. Qwen3 technical report, 2025
2025
-
[52]
An Yang, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoyan Huang, Jiandong Jiang, Jianhong Tu, Jianwei Zhang, Jingren Zhou, Junyang Lin, Kai Dang, et al. Qwen2.5-1m technical report.arXiv preprint arXiv:2501.15383, 2025
work page internal anchor Pith review arXiv 2025
-
[53]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, et al. Qwen2.5-coder technical report. arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review arXiv 2024
-
[54]
Llama 3 model card
AI@Meta. Llama 3 model card. 2024
2024
-
[55]
Evaluating large language models trained on code, 2021
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, et al. Evaluating large language models trained on code, 2021
2021
-
[56]
Weipeng Xu, Kaiqi Yang, Yuzhi Zhang, Shichao Sun, Sheng Mao, and Tianju Xue. Difflib: High-fidelity differentiable modeling of lithium-ion batteries and efficient gradient-based parameter identification.arXiv preprint arXiv:2504.20674, 2025
-
[57]
Specgen: Automated generation of formal program specifications via large language models, 2025
Lezhi Ma, Shangqing Liu, Yi Li, Xiaofei Xie, and Lei Bu. Specgen: Automated generation of formal program specifications via large language models, 2025
2025
-
[58]
Cok, Michael D
Lilian Burdy, Yoonsik Cheon, David R. Cok, Michael D. Ernst, Joseph R. Kiniry, Gary T. Leavens, K. Rustan M. Leino, and Erik Poll. An overview of jml tools and applications.Int. J. Softw. Tools Technol. Transf., 7(3):212–232, June 2005
2005
-
[59]
Lopes, Iris Ma, and James Noble
Md Rakib Hossain Misu, Cristina V. Lopes, Iris Ma, and James Noble. Towards ai- assisted synthesis of verified dafny methods.Proceedings of the ACM on Software Engineering, 1(FSE):812–835, July 2024
2024
-
[60]
Dafny: Statically verifying functional correctness, 2014
Rachel Gauci. Dafny: Statically verifying functional correctness, 2014
2014
-
[61]
Speceval: Evaluating code comprehension in large language models via program specifica- tions, 2025
Lezhi Ma, Shangqing Liu, Lei Bu, Shangru Li, Yida Wang, and Yang Liu. Speceval: Evaluating code comprehension in large language models via program specifica- tions, 2025
2025
-
[62]
Invbench: Can llms accelerate program verification with invariant synthesis?, 2025
Anjiang Wei, Tarun Suresh, Tianran Sun, Haoze Wu, Ke Wang, and Alex Aiken. Invbench: Can llms accelerate program verification with invariant synthesis?, 2025
2025
-
[63]
Local success does not compose: Benchmarking large language models for compositional formal verification, 2025
Xu Xu, Xin Li, Xingwei Qu, Jie Fu, and Binhang Yuan. Local success does not compose: Benchmarking large language models for compositional formal verification, 2025
2025
-
[64]
Veriequivbench: An equivalence score for ground-truth-free evaluation of formally verifiable code, 2025
Lingfei Zeng, Fengdi Che, Xuhan Huang, Fei Ye, Xu Xu, Binhang Yuan, and Jie Fu. Veriequivbench: An equivalence score for ground-truth-free evaluation of formally verifiable code, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.