Recognition: unknown
Decompose and Recompose: Reasoning New Skills from Existing Abilities for Cross-Task Robotic Manipulation
Pith reviewed 2026-05-09 14:27 UTC · model grok-4.3
The pith
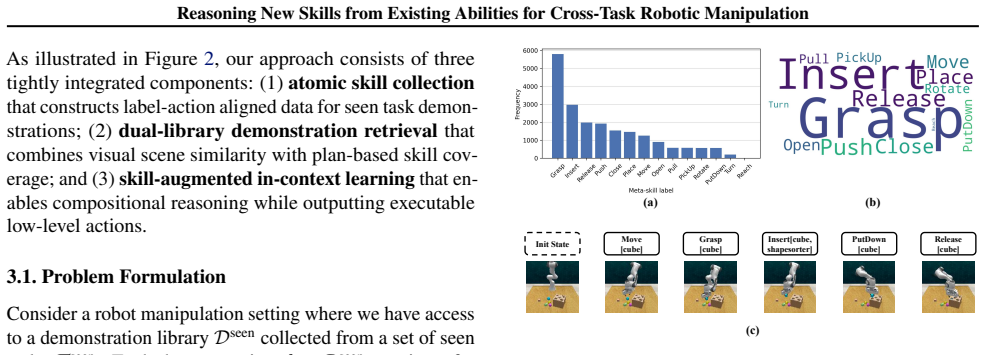
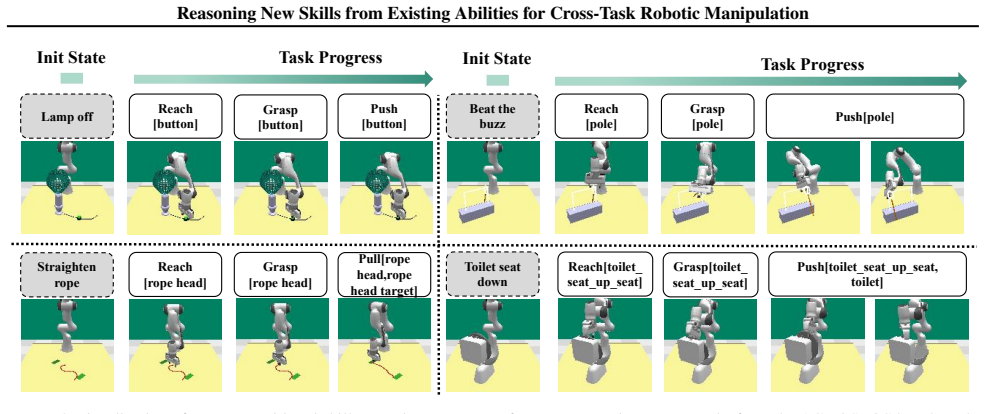
Decomposing robot demonstrations into atomic skill-action pairs enables compositional reasoning for zero-shot generalization to unseen manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The approach decomposes seen task demonstrations into interpretable skill-action alignments. It then builds a task-adaptive dynamic demonstration library through visual-semantic retrieval combined with skill sequences from a planning agent, supplemented by a coverage-aware static library. These skill-comprehensive demonstrations allow the model to recompose the alignments for unseen tasks via compositional reasoning about skill composition and execution ordering.
What carries the argument
Atomic skill-action pairs as intermediate representations that decompose demonstrations and support recomposition through retrieval-based dynamic and static libraries.
Load-bearing premise
Decomposing demonstrations into interpretable atomic skill-action alignments reliably captures composable knowledge that transfers to unseen tasks without superficial imitation.
What would settle it
A new task whose required skill sequence cannot be derived from any combination of the decomposed pairs in the libraries, resulting in incorrect or incomplete action generation despite the component skills appearing in the original demonstrations.
Figures




read the original abstract
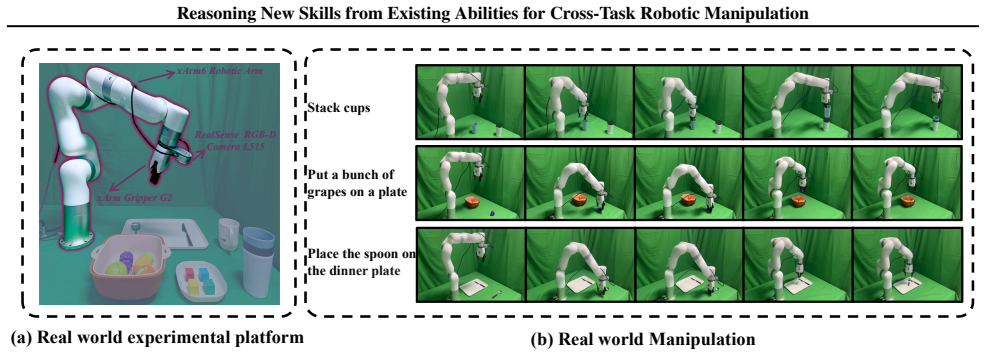
Cross-task generalization is a core challenge in open-world robotic manipulation, and the key lies in extracting transferable manipulation knowledge from seen tasks. Recent in-context learning approaches leverage seen task demonstrations to generate actions for unseen tasks without parameter updates. However, existing methods provide only low-level continuous action sequences as context, failing to capture composable skill knowledge and causing models to degenerate into superficial trajectory imitation. We propose Decompose and Recompose, a skill reasoning framework using atomic skill-action pairs as intermediate representations. Our approach decomposes seen demonstrations into interpretable skill--action alignments, enabling the model to recompose these skills for unseen tasks through compositional reasoning. Specifically, we construct a task-adaptive dynamic demonstration library via visual-semantic retrieval combined with skill sequences from a planning agent, complemented by a coverage-aware static library to fill missing skill patterns. Together, these yield skill-comprehensive demonstrations that explicitly elicit compositional reasoning for skill composition and execution ordering. Experiments on the AGNOSTOS benchmark and real-world environments validate our method's zero-shot cross-task generalization capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Decompose and Recompose, a skill-reasoning framework for cross-task robotic manipulation. Demonstrations are decomposed into atomic skill-action alignments; these are retrieved via visual-semantic matching and augmented by a planning agent to form a task-adaptive dynamic library, which is complemented by a coverage-aware static library. The resulting skill-comprehensive context is intended to elicit compositional reasoning rather than trajectory imitation, enabling zero-shot generalization to unseen tasks. Validation is reported on the AGNOSTOS benchmark and real-robot environments.
Significance. If the decomposition reliably extracts transferable atomic skills, the approach would meaningfully advance in-context learning for robotics by replacing low-level action sequences with explicit, recomposable skill representations. The dual-library construction (dynamic retrieval plus static coverage) directly targets the coverage and ordering problems that plague prior methods.
major comments (2)
- [§3] §3 (Method): The central claim that atomic skill-action alignments capture composable knowledge (rather than surface trajectories) rests on the decomposition procedure, yet the manuscript provides only a high-level description of how demonstrations are segmented and aligned. Without an explicit algorithm, similarity metric, or example of an extracted skill-action pair, it is impossible to assess whether the subsequent recomposition step is performing genuine composition or merely retrieving similar trajectories.
- [§4] §4 (Experiments): The reported success on AGNOSTOS and real robots is the primary evidence for zero-shot cross-task generalization, but the manuscript does not include per-task success rates, baseline comparisons with statistical tests, or ablations that isolate the contribution of the dynamic library versus the static library. These omissions leave open the possibility that performance gains are driven by retrieval coverage rather than the claimed compositional reasoning.
minor comments (2)
- [Abstract] The abstract and §3.2 would benefit from a concise formal notation (e.g., an equation defining a skill-action pair and the retrieval objective) to make the pipeline easier to follow.
- [§4] Figure captions and table headers should explicitly state the number of runs or seeds used for reported metrics to allow readers to judge robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to provide the requested details and analyses.
read point-by-point responses
-
Referee: [§3] §3 (Method): The central claim that atomic skill-action alignments capture composable knowledge (rather than surface trajectories) rests on the decomposition procedure, yet the manuscript provides only a high-level description of how demonstrations are segmented and aligned. Without an explicit algorithm, similarity metric, or example of an extracted skill-action pair, it is impossible to assess whether the subsequent recomposition step is performing genuine composition or merely retrieving similar trajectories.
Authors: We agree that the current description of the decomposition is high-level and insufficient for readers to fully evaluate the nature of the skill-action alignments. In the revised manuscript, we will add the explicit segmentation and alignment algorithm, the precise visual-semantic similarity metric, and a worked example of an extracted skill-action pair from a demonstration. These additions will clarify that the recomposition operates on atomic, transferable skills rather than surface-level trajectory retrieval. revision: yes
-
Referee: [§4] §4 (Experiments): The reported success on AGNOSTOS and real robots is the primary evidence for zero-shot cross-task generalization, but the manuscript does not include per-task success rates, baseline comparisons with statistical tests, or ablations that isolate the contribution of the dynamic library versus the static library. These omissions leave open the possibility that performance gains are driven by retrieval coverage rather than the claimed compositional reasoning.
Authors: We acknowledge the lack of granular experimental reporting. The revised manuscript will include per-task success rates for AGNOSTOS and the real-robot environments, baseline comparisons with appropriate statistical tests, and ablations that separately evaluate the dynamic library (visual-semantic retrieval plus planning agent) against the static coverage-aware library. These changes will help isolate the contribution of compositional skill reasoning from retrieval coverage effects. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a methodological framework for decomposing demonstrations into skill-action alignments and recomposing them via retrieval, planning agents, and static/dynamic libraries. No equations, fitted parameters, or self-referential derivations are present in the provided text. The central pipeline relies on external components (visual-semantic retrieval, planning agent) and is validated through independent experiments on AGNOSTOS and real robots rather than reducing to inputs by construction. No self-citation chains, ansatzes smuggled via prior work, or renamings of known results are load-bearing in a circular manner. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review arXiv
-
[2]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y ., Chen, X., Choromanski, K., Ding, T., Driess, D., Dubey, A., Finn, C., et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818,
work page internal anchor Pith review arXiv
-
[3]
Cai, Z., Cao, M., Chen, H., Chen, K., Chen, K., Chen, X., Chen, X., Chen, Z., Chen, Z., Chu, P., et al. Internlm2 technical report.arXiv preprint arXiv:2403.17297,
-
[4]
Chen, Z., Yin, J., Chen, Y ., Huo, J., Tian, P., Shi, J., and Gao, Y . Sigma-agent: A vision-language-action model for robotic manipulation.arXiv preprint arXiv:2411.04376,
-
[5]
Di Palo, N. and Johns, E. Keypoint action tokens enable in-context imitation learning in robotics.arXiv preprint arXiv:2403.19578,
-
[6]
A Survey on In-context Learning
Dong, Q., Li, L., Dai, D., Zheng, C., Ma, J., Li, R., Xia, H., Xu, J., Wu, Z., Liu, T., et al. A survey on in-context learning.arXiv preprint arXiv:2301.00234,
work page internal anchor Pith review arXiv
-
[7]
Fang, H., Grotz, M., Pumacay, W., Wang, Y . R., Fox, D., Krishna, R., and Duan, J. Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation.arXiv preprint arXiv:2501.18564,
-
[8]
T owards generalizable vision-language robotic manipulation: A benchmark and LLM-guided 3D policy
Garcia, R., Chen, S., and Schmid, C. Towards generalizable vision-language robotic manipulation: A benchmark and llm-guided 3d policy.arXiv preprint arXiv:2410.01345,
-
[9]
Rvt-2: Learning precise manipulation from few demonstrations.arXiv preprint arXiv:2406.08545,
Goyal, A., Blukis, V ., Xu, J., Guo, Y ., Chao, Y .-W., and Fox, D. Rvt-2: Learning precise manipulation from few demonstrations.arXiv preprint arXiv:2406.08545,
-
[10]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Huang, H., Lin, F., Hu, Y ., Wang, S., and Gao, Y . Copa: General robotic manipulation through spatial constraints of parts with foundation models. In2024 IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS), pp. 9488–9495. IEEE, 2024a. Huang, W., Wang, C., Zhang, R., Li, Y ., Wu, J., and Fei-Fei, L. V oxposer: Composable 3d value ...
work page internal anchor Pith review arXiv
-
[12]
Huang, W., Wang, C., Li, Y ., Zhang, R., and Fei-Fei, L. Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation.arXiv preprint arXiv:2409.01652, 2024b. Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux,...
-
[13]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M. J., Pertsch, K., Karamcheti, S., Xiao, T., Balakr- ishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., San- keti, P., et al. Openvla: An open-source vision-language- action model.arXiv preprint arXiv:2406.09246,
work page internal anchor Pith review arXiv
-
[14]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Liu, F., Fang, K., Abbeel, P., and Levine, S. Moka: Open- vocabulary robotic manipulation through mark-based vi- sual prompting. InFirst Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024, 2024a. 9 Reasoning New Skills from Existing Abilities for Cross-Task Robotic Manipulation Liu, S., Wu, L., Li, B., Tan, H., Chen, H., Wang,...
work page internal anchor Pith review arXiv 2024
-
[15]
R3m: A universal visual representation for robot manipulation
Nair, S., Rajeswaran, A., Kumar, V ., Finn, C., and Gupta, A. R3m: A universal visual representation for robot manipulation.arXiv preprint arXiv:2203.12601,
-
[16]
Llarva: Vision-action instruction tuning enhances robot learning.arXiv preprint arXiv:2406.11815,
Niu, D., Sharma, Y ., Biamby, G., Quenum, J., Bai, Y ., Shi, B., Darrell, T., and Herzig, R. Llarva: Vision-action instruction tuning enhances robot learning.arXiv preprint arXiv:2406.11815,
-
[17]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., V o, H., Szafraniec, M., Khalidov, V ., Fernandez, P., Haziza, D., Massa, F., El- Nouby, A., et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Learning to re- trieve prompts for in-context learning.arXiv preprint arXiv:2112.08633,
Rubin, O., Herzig, J., and Berant, J. Learning to re- trieve prompts for in-context learning.arXiv preprint arXiv:2112.08633,
-
[19]
Sim´eoni, O., V o, H. V ., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V ., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al. Dinov3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Octo: An Open-Source Generalist Robot Policy
Team, O. M., Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Kreiman, T., Xu, C., et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213,
work page internal anchor Pith review arXiv
-
[21]
arXiv preprint arXiv:2410.12782 , year=
Yin, Y ., Wang, Z., Sharma, Y ., Niu, D., Darrell, T., and Herzig, R. In-context learning enables robot action pre- diction in llms.arXiv preprint arXiv:2410.12782,
-
[22]
Zhou, J., Ma, T., Lin, K.-Y ., Wang, Z., Qiu, R., and Liang, J. Mitigating the human-robot domain discrepancy in visual pre-training for robotic manipulation.arXiv preprint arXiv:2406.14235,
-
[23]
Exploring the limits of vision-language-action manipulations in cross-task generalization
Zhou, J., Ye, K., Liu, J., Ma, T., Wang, Z., Qiu, R., Lin, K.-Y ., Zhao, Z., and Liang, J. Exploring the limits of vision-language-action manipulations in cross-task gener- alization.arXiv preprint arXiv:2505.15660,
-
[24]
Zhu, J. Y ., Cano, C. G., Bermudez, D. V ., and Drozdzal, M. Incoro: In-context learning for robotics control with feedback loops.arXiv preprint arXiv:2402.05188,
-
[25]
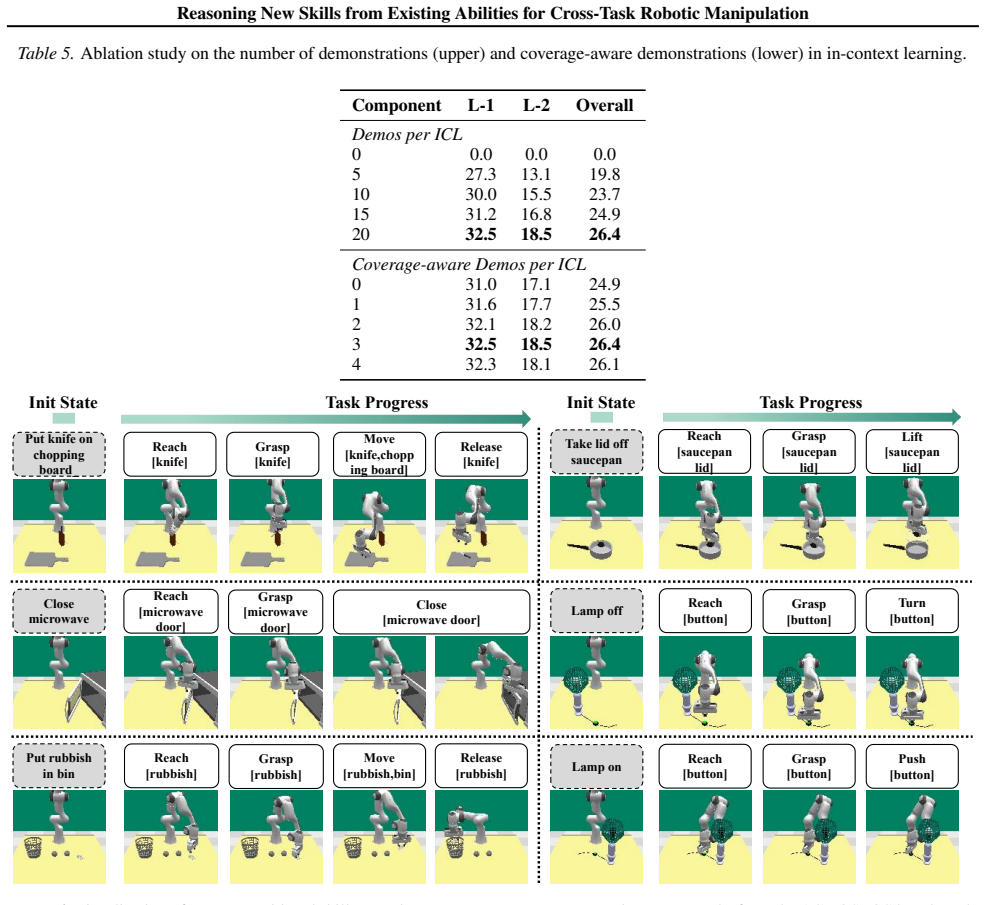
12 Reasoning New Skills from Existing Abilities for Cross-Task Robotic Manipulation Table 5.Ablation study on the number of demonstrations (upper) and coverage-aware demonstrations (lower) in in-context learning. Component L-1 L-2 Overall Demos per ICL 0 0.0 0.0 0.0 5 27.3 13.1 19.8 10 30.0 15.5 23.7 15 31.2 16.8 24.9 2032.5 18.5 26.4 Coverage-aware Demos...
2032
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.