Recognition: unknown
LIE: LiDAR-only HD Map Construction with Intensity Enhancement via Online Knowledge Distillation
Pith reviewed 2026-05-09 14:44 UTC · model grok-4.3
The pith
LiDAR-only HD map construction outperforms camera-based methods by using online knowledge distillation on intensity-enhanced features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
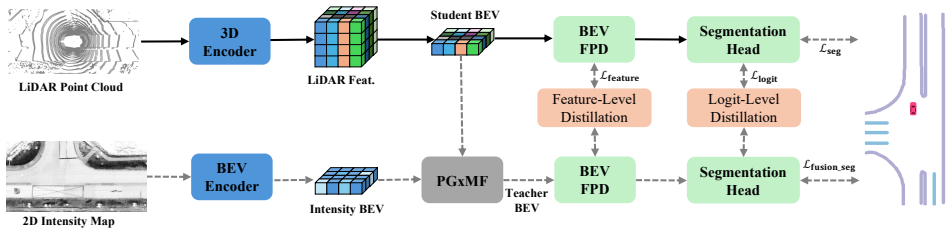
The central discovery is that online knowledge distillation, with a teacher that fuses the student's LiDAR features and the corresponding 2D intensity map tile, can supply the dense semantic supervision needed to train an effective LiDAR-only semantic HD map construction model.
What carries the argument
The teacher branch in the online knowledge distillation scheme that fuses LiDAR features with intensity map tiles to provide supervision.
If this is right
- It outperforms all single-modality approaches on the nuScenes dataset.
- It achieves 8.2% higher mIoU than the state-of-the-art camera-based model.
- It remains robust over long ranges and under challenging weather and lighting conditions.
- It adapts to Argoverse2 with only 10% fine-tuning data while surpassing camera-based models trained on the full dataset.
Where Pith is reading between the lines
- The intensity maps from LiDAR appear to carry enough information to bridge the semantic gap when distilled properly.
- This could allow autonomous vehicles to operate with fewer sensors during deployment.
- Similar distillation techniques might improve other LiDAR-based perception tasks like object detection.
- The efficient adaptation hints at good generalization properties across different driving datasets.
Load-bearing premise
The teacher branch fusing student LiDAR features with the 2D intensity map tile can reliably supply dense semantic supervision that transfers to the LiDAR-only student without introducing systematic biases or artifacts.
What would settle it
A direct comparison on nuScenes where the LIE mIoU does not exceed the camera-based SOTA by 8.2 percentage points, or an adaptation experiment on Argoverse2 where 10% fine-tuning fails to beat full-dataset camera models.
Figures




read the original abstract
Online High-Definition (HD) map construction is a key component of autonomous driving. Recent methods rely on multi-view camera images for cost-effective HD map segmentation, but cameras lack depth information for accurate scene geometry. In contrast, LiDAR provides precise 3D measurements but lacks dense semantic cues. In this work, we propose LIE, LiDAR-only semantic map construction method that employ Knowledge Distillation (KD) to handle the lack of dense semantic and texture cues. Specifically, the teacher branch fuses student LiDAR features and the corresponding 2D intensity map tile to provide dense supervision for segmenting map elements using online distillation scheme. Experimental results show that our method outperforms all single-modality approaches, achieving 8.2% higher mIoU than the state-of-the-art camera-based model on nuScenes. LIE is robust over long ranges and under challenging weather and lighting, and efficiently adapts to Argoverse2 with only 10% fine-tuning, surpassing camera-based models trained on the full dataset. Source code will be available \href{https://iv.ee.hm.edu/lie/}{here}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LIE, a LiDAR-only method for online HD map construction. It uses an online knowledge distillation scheme in which a teacher branch fuses the student's LiDAR features with corresponding 2D intensity map tiles to generate dense semantic supervision for the student network. Experiments on nuScenes report an 8.2% mIoU improvement over the state-of-the-art camera-based model, with additional claims of robustness across long ranges and adverse weather/lighting conditions, plus efficient adaptation to Argoverse2 using only 10% fine-tuning data while surpassing camera models trained on the full dataset.
Significance. If the reported gains are shown to be robust and the distillation mechanism supplies genuinely unbiased semantic targets, the work would advance single-modality HD mapping by leveraging LiDAR's geometric precision without camera inputs at inference. This is particularly relevant for autonomous driving in conditions where visual sensors degrade, and the cross-dataset adaptation results would indicate practical utility for deployment.
major comments (2)
- [Method section (teacher branch description)] The central construction (teacher fuses student LiDAR features with the 2D intensity map tile to supply dense supervision) is load-bearing for all robustness and outperformance claims. The manuscript provides no ablation isolating the intensity-map contribution, no qualitative inspection of teacher logits for projection artifacts or intensity-induced hallucinations, and no error analysis on the student under the adverse conditions cited in the abstract; without these, it remains unclear whether the 8.2% mIoU gain reflects genuine LiDAR-only capability or transferred biases the student cannot correct at inference.
- [Experiments section] Experimental results section: the 8.2% mIoU gain, long-range robustness, and Argoverse2 adaptation (10% fine-tuning) are presented without reported data splits, training protocol details, number of runs, or statistical significance tests. This absence prevents verification that the gains are stable rather than sensitive to post-hoc choices, directly undermining the cross-dataset and adverse-condition claims.
minor comments (2)
- [Abstract] The abstract states that source code will be available at the provided link; ensure a persistent, functional repository is included in the camera-ready version.
- [Introduction] Notation for intensity map tiles and map element classes could be introduced with a small diagram or table to improve readability for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that will strengthen the presentation of our method and results.
read point-by-point responses
-
Referee: [Method section (teacher branch description)] The central construction (teacher fuses student LiDAR features with the 2D intensity map tile to supply dense supervision) is load-bearing for all robustness and outperformance claims. The manuscript provides no ablation isolating the intensity-map contribution, no qualitative inspection of teacher logits for projection artifacts or intensity-induced hallucinations, and no error analysis on the student under the adverse conditions cited in the abstract; without these, it remains unclear whether the 8.2% mIoU gain reflects genuine LiDAR-only capability or transferred biases the student cannot correct at inference.
Authors: We agree that additional evidence is needed to isolate the intensity-map contribution and rule out potential biases. In the revised manuscript we will add an ablation that removes the 2D intensity map input from the teacher branch while keeping all other components fixed, and report the resulting mIoU drop on nuScenes. We will also include qualitative visualizations of teacher logits alongside student outputs to inspect for projection artifacts or intensity-induced hallucinations. Finally, we will provide a per-condition error analysis on nuScenes subsets stratified by weather and lighting, demonstrating that the student network (which receives only LiDAR at inference) retains its advantage without camera input. These additions will clarify that the reported gains arise from effective online distillation rather than uncorrectable transferred biases. revision: yes
-
Referee: [Experiments section] Experimental results section: the 8.2% mIoU gain, long-range robustness, and Argoverse2 adaptation (10% fine-tuning) are presented without reported data splits, training protocol details, number of runs, or statistical significance tests. This absence prevents verification that the gains are stable rather than sensitive to post-hoc choices, directly undermining the cross-dataset and adverse-condition claims.
Authors: We acknowledge that greater experimental transparency is required. In the revision we will explicitly document the data splits (standard nuScenes and Argoverse2 partitions), full training protocols including optimizer settings, learning-rate schedules, and batch sizes, results averaged over at least three random seeds with standard deviations, and statistical significance tests (paired t-tests) for the primary comparisons against camera baselines. These details will be added to both the main text and supplementary material to allow verification of stability. revision: yes
Circularity Check
No circularity; empirical method with external validation
full rationale
The paper proposes an architectural method (teacher fuses student LiDAR features with 2D intensity tile for online KD supervision to the LiDAR-only student) and validates it via comparative experiments on nuScenes and Argoverse2. No mathematical derivation, parameter fitting, or prediction is claimed that reduces by construction to inputs defined inside the paper. Performance numbers (e.g., 8.2% mIoU gain) are measured against independent prior baselines rather than generated from self-referential equations or self-citations. The design choice of intensity-enhanced teacher supervision is a modeling decision, not a tautological loop. This is a standard self-contained empirical CV contribution with no load-bearing self-definition or fitted-input-as-prediction patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard supervised segmentation loss plus distillation loss can transfer semantic cues from intensity-augmented features to pure LiDAR features
Reference graph
Works this paper leans on
-
[1]
High-definition maps: Comprehensive survey, challenges, and future perspectives,
G. Elghazaly, R. Frank, S. Harvey, and S. Safko, “High-definition maps: Comprehensive survey, challenges, and future perspectives,” IEEE Open Journal of Intelligent Transportation Systems, vol. 4, pp. 527–550, 2023
2023
-
[2]
A review of high- definition map creation methods for autonomous driving,
Z. Bao, S. Hossain, H. Lang, and X. Lin, “A review of high- definition map creation methods for autonomous driving,”Engineering Applications of Artificial Intelligence, vol. 122, p. 106125, 2023
2023
-
[3]
Semvecnet: Generalizable vector map generation for arbitrary sensor configurations,
N. E. Ranganatha, H. Zhang, S. Venkatramani, J.-Y . Liao, and H. I. Christensen, “Semvecnet: Generalizable vector map generation for arbitrary sensor configurations,” in2024 IEEE Intelligent Vehicles Symposium (IV), 2024, pp. 2820–2827
2024
-
[4]
Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,
Z. Liuet al., “Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,” inIEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 2774–2781
2023
-
[5]
Generation of a precise and efficient lane-level road map for intelligent vehicle systems,
G.-P. Gwon, W.-S. Hur, S.-W. Kim, and S.-W. Seo, “Generation of a precise and efficient lane-level road map for intelligent vehicle systems,”IEEE Transactions on Vehicular Technology, vol. 66, no. 6, pp. 4517–4533, 2017
2017
-
[6]
Laser data based automatic generation of lane-level road map for intelligent vehicles,
Z. Yuet al., “Laser data based automatic generation of lane-level road map for intelligent vehicles,”arXiv preprint arXiv:2101.05066, 2021
-
[7]
Hdmapnet: An online hd map construction and evaluation framework,
Q. Li, Y . Wang, Y . Wang, and H. Zhao, “Hdmapnet: An online hd map construction and evaluation framework,” in2022 International Conference on Robotics and Automation (ICRA), 2022, pp. 4628–4634
2022
-
[8]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” inIEEE/CVF European Conference on Computer Vision (ECCV), 2020, vol. 12359, pp. 194–210
2020
-
[9]
Simple- bev: What really matters for multi-sensor bev perception?
A. W. Harley, Z. Fang, J. Li, R. Ambrus, and K. Fragkiadaki, “Simple- bev: What really matters for multi-sensor bev perception?” inIEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 2759–2765
2023
-
[10]
Cross-view transformers for real-time map-view semantic segmentation,
B. Zhou and P. Krahenbuhl, “Cross-view transformers for real-time map-view semantic segmentation,” inIEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2022, pp. 13 750– 13 759
2022
-
[11]
Bevformer: Learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,
Z. Liet al., “Bevformer: Learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 3, pp. 2020– 2036, 2025
2020
-
[12]
Petr: Position embedding transformation for multi-view 3d object detection,
Y . Liu, T. Wang, X. Zhang, and J. Sun, “Petr: Position embedding transformation for multi-view 3d object detection,” inIEEE/CVF European Conference on Computer Vision (ECCV), 2022, vol. 13687, pp. 531–548
2022
-
[13]
Lidar2map: In de- fense of lidar-based semantic map construction using online camera distillation,
S. Wang, W. Li, W. Liu, X. Liu, and J. Zhu, “Lidar2map: In de- fense of lidar-based semantic map construction using online camera distillation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 5186–5195
2023
-
[14]
Broadbev: Collaborative lidar-camera fusion for broad-sighted bird’s eye view map construc- tion,
M. Kim, G. Kim, K. H. Jin, and S. Choi, “Broadbev: Collaborative lidar-camera fusion for broad-sighted bird’s eye view map construc- tion,” inIEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 11 125–11 132
2024
-
[15]
P-mapnet: Far-seeing map generator enhanced by both sdmap and hdmap priors,
Z. Jianget al., “P-mapnet: Far-seeing map generator enhanced by both sdmap and hdmap priors,”IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 8539–8546, 2024
2024
-
[16]
Complementing onboard sensors with satellite maps: A new perspective for hd map construction,
W. Gaoet al., “Complementing onboard sensors with satellite maps: A new perspective for hd map construction,” inIEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 11 103– 11 109
2024
-
[17]
Satmap: Revisiting satellite maps as prior for online hd map construction,
K. Mazumder and F. B. Flohr, “Satmap: Revisiting satellite maps as prior for online hd map construction,”arXiv preprint arXiv:2601.10512, 2026
-
[18]
Neural map prior for autonomous driving,
X. Xionget al., “Neural map prior for autonomous driving,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 17 535–17 544
2023
-
[19]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
Bevdistill: Cross-modal BEV distillation for multi- view 3d object detection,
Z. Chenet al., “Bevdistill: Cross-modal BEV distillation for multi- view 3d object detection,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[21]
Distillbev: Boosting multi-camera 3d object detection with cross-modal knowledge distil- lation,
Z. Wang, D. Li, C. Luo, C. Xie, and X. Yang, “Distillbev: Boosting multi-camera 3d object detection with cross-modal knowledge distil- lation,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 8603–8612
2023
-
[22]
Unidistill: A universal cross-modality knowledge distillation framework for 3d object detec- tion in bird’s-eye view,
S. Zhou, W. Liu, C. Hu, S. Zhou, and C. Ma, “Unidistill: A universal cross-modality knowledge distillation framework for 3d object detec- tion in bird’s-eye view,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 5116–5125
2023
-
[23]
Mapdistill: Boosting efficient camera-based hd map construction via camera-lidar fusion model distillation,
X. Haoet al., “Mapdistill: Boosting efficient camera-based hd map construction via camera-lidar fusion model distillation,” inIEEE/CVF European Conference on Computer Vision (ECCV), vol. 15061, 2025, pp. 166–183
2025
-
[24]
Mapkd: Unlocking prior knowledge with cross-modal distillation for efficient online hd map construction,
Z. Yanet al., “Mapkd: Unlocking prior knowledge with cross-modal distillation for efficient online hd map construction,” 2025, to be published
2025
-
[25]
Pointpillars: Fast encoders for object detection from point clouds,
A. H. Langet al., “Pointpillars: Fast encoders for object detection from point clouds,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 12 689–12 697
2019
-
[26]
Pointnet: Deep learning on point sets for 3d classification and segmentation,
R. Q. Charles, H. Su, M. Kaichun, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 77–85
2017
-
[27]
Fast ground segmentation for 3d lidar point cloud based on jump-convolution-process,
Z. Shenet al., “Fast ground segmentation for 3d lidar point cloud based on jump-convolution-process,”Remote Sensing, vol. 13, 2021
2021
-
[28]
Patchwork++: Fast and robust ground segmentation solving partial under-segmentation using 3d point cloud,
S. Lee, H. Lim, and H. Myung, “Patchwork++: Fast and robust ground segmentation solving partial under-segmentation using 3d point cloud,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022, pp. 13 276–13 283
2022
-
[29]
Reliable graph-slam framework to generate 2d lidar intensity maps for au- tonomous vehicles,
M. Aldibaja, N. Suganuma, R. Yanase, and K. Yoneda, “Reliable graph-slam framework to generate 2d lidar intensity maps for au- tonomous vehicles,” inIEEE Vehicular Technology Conference (VTC), 2020, pp. 1–6
2020
-
[30]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liuet al., “Swin transformer: Hierarchical vision transformer using shifted windows,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 9992–10 002
2021
-
[31]
Feature pyramid networks for object detection,
T.-Y . Linet al., “Feature pyramid networks for object detection,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 936–944
2017
-
[32]
Attentional feature fusion,
Y . Dai, F. Gieseke, S. Oehmcke, Y . Wu, and K. Barnard, “Attentional feature fusion,” inIEEE Winter Conference on Applications of Com- puter Vision (WACV), 2021, pp. 3559–3568
2021
-
[33]
Learnable tree filter for structure-preserving feature transform,
L. Songet al., “Learnable tree filter for structure-preserving feature transform,” inAdvances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[34]
Tree energy loss: Towards sparsely annotated semantic segmentation,
Z. Liang, T. Wang, X. Zhang, J. Sun, and J. Shen, “Tree energy loss: Towards sparsely annotated semantic segmentation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 16 886–16 895
2022
-
[35]
xmuda: Cross-modal unsupervised domain adaptation for 3d semantic segmen- tation,
M. Jaritz, T.-H. Vu, R. De Charette, E. Wirbel, and P. Perez, “xmuda: Cross-modal unsupervised domain adaptation for 3d semantic segmen- tation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 12 602–12 611
2020
-
[36]
The lovasz-softmax loss: A tractable surrogate for the optimization of the intersection- over-union measure in neural networks,
M. Berman, A. R. Triki, and M. B. Blaschko, “The lovasz-softmax loss: A tractable surrogate for the optimization of the intersection- over-union measure in neural networks,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 4413– 4421
2018
-
[37]
Unifusion: Unified multi-view fusion transformer for spatial-temporal representation in bird’s-eye-view,
Z. Qin, J. Chen, C. Chen, X. Chen, and X. Li, “Unifusion: Unified multi-view fusion transformer for spatial-temporal representation in bird’s-eye-view,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 8656–8665
2023
-
[38]
Diffmap: Enhancing map segmentation with map prior using diffusion model,
P. Jiaet al., “Diffmap: Enhancing map segmentation with map prior using diffusion model,”IEEE Robotics and Automation Letters, vol. 9, no. 11, pp. 9836–9843, 2024
2024
-
[39]
Bevsegformer: Bird’s eye view semantic segmentation from arbitrary camera rigs,
L. Peng, Z. Chen, Z. Fu, P. Liang, and E. Cheng, “Bevsegformer: Bird’s eye view semantic segmentation from arbitrary camera rigs,” inIEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023, pp. 5924–5932
2023
-
[40]
arXiv preprint arXiv:2205.09743 (2022)
Y . Zhanget al., “Beverse: Unified perception and prediction in birds-eye-view for vision-centric autonomous driving,”arXiv preprint arXiv:2205.09743, 2022
-
[41]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesaret al., “nuscenes: A multimodal dataset for autonomous driving,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 11 618–11 628
2020
-
[42]
Streammapnet: Streaming mapping network for vectorized online hd map construc- tion,
T. Yuan, Y . Liu, Y . Wang, Y . Wang, and H. Zhao, “Streammapnet: Streaming mapping network for vectorized online hd map construc- tion,” inIEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024, pp. 7341–7350
2024
-
[43]
Localization is all you evaluate: Data leakage in online mapping datasets and how to fix it,
A. Lilja, J. Fu, E. Stenborg, and L. Hammarstrand, “Localization is all you evaluate: Data leakage in online mapping datasets and how to fix it,” in2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 22 150–22 159
2024
-
[44]
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
B. Wilsonet al., “Argoverse 2: Next generation datasets for self-driving perception and forecasting,”arXiv preprint arXiv:2301.00493, 2023
work page internal anchor Pith review arXiv 2023
-
[45]
Vectormapnet: End-to-end vectorized hd map learning,
Y . Liu, T. Yuan, Y . Wang, Y . Wang, and H. Zhao, “Vectormapnet: End-to-end vectorized hd map learning,” inInternational Conference on Machine Learning (ICML), 2023
2023
-
[46]
Imagenet: A large-scale hierarchical image database,
J. Denget al., “Imagenet: A large-scale hierarchical image database,” in2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009, pp. 248–255
2009
-
[47]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inInternational Conference for Learning Representations (ICLR), 2015
2015
-
[48]
Maptr: Structured modeling and learning for online vec- torized hd map construction,
B. Liaoet al., “Maptr: Structured modeling and learning for online vec- torized hd map construction,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[49]
MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction,
——, “Maptrv2: An end-to-end framework for online vectorized hd map construction,”arXiv preprint arXiv:2308.05736, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.