Recognition: unknown
FT-RAG: A Fine-grained Retrieval-Augmented Generation Framework for Complex Table Reasoning
Pith reviewed 2026-05-09 14:11 UTC · model grok-4.3
The pith
FT-RAG achieves higher accuracy in complex table reasoning by decomposing tables into semantic entry units and using graph-based neighbor expansion for retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FT-RAG decomposes tables into entry-level semantic units to construct a structured graph, employs a structural neighbor expansion mechanism to retrieve semantically connected entities, and uses multi-modal fusion to consolidate context, resulting in 23.5% and 59.2% improvements in table-level and cell-level Hit Rates along with a 62.2% increase in exact value accuracy recall on the new Multi-Table-RAG-Lib benchmark.
What carries the argument
The structured graph of entry-level semantic units with structural neighbor expansion for retrieval and multi-modal fusion for context consolidation.
If this is right
- Surpasses previous methods with 23.5% better table-level Hit Rates on complex queries.
- Delivers 59.2% improvement in cell-level Hit Rates by pinpointing specific data entries.
- Increases exact value accuracy recall by 62.2% during answer generation.
- Supports both pure tabular data and mixed table-text documents for factual grounding.
- Provides a new benchmark dataset for testing multi-table integration capabilities.
Where Pith is reading between the lines
- The graph expansion technique could help with other structured data like spreadsheets or databases where relationships are implicit.
- Future work might test whether the same decomposition helps in non-English tables or very large enterprise datasets.
- Improved retrieval precision may lower the rate at which models generate incorrect numbers or facts from tables.
- The benchmark could encourage development of systems that handle real-world documents containing many interconnected tables.
Load-bearing premise
Decomposing tables into individual entry units and linking them in a graph will preserve all necessary context and relationships for multi-table reasoning while avoiding retrieval of irrelevant information.
What would settle it
Running the system on a new collection of questions that require chaining information across four or more tables and finding no gain over standard RAG methods would show that the graph expansion fails to capture the required connections.
Figures





read the original abstract
Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by grounding responses in external knowledge during inference. However, conventiona RAG systems under-perform on structured tabular data, largely due to coarse retrieval granularity and insufficient table semantic comprehension. To address these limitations, we introduce FT-RAG, a fine-grained framework that employs knowledge association by decomposing tables into entry-level semantic units to construct a structured graph. FT-RAG employs a structural neighbor expansion mechanism to find semantically connected entities during graph retrieval, followed by multi-modal fusion to consolidate the context of table retrieval results. Further, to address the scarcity of specialized datasets in this domain, we introduce Multi-Table-RAG-Lib, a benchmark comprising 9870 QA pairs with high complexity and difficulty, curated to demand multi-table integration and text-table information fusion for reasoning. FT-RAG surpasses top-performing baselines across all metrics, achieving a 23.5\% and 59.2\% improvement in table-level and cell-level Hit Rates, respectively. Generation performance also sees a remarkable 62.2\% increase in exact value accuracy recall. These metrics verify the framework's effectiveness in factual grounding across both pure tabular and heterogeneous table-text contexts. Therefore, our method establishes a new state-of-the-art performance for complex reasoning over mixed-modality documents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FT-RAG, a fine-grained RAG framework for complex table reasoning over mixed-modality documents. It decomposes tables into entry-level semantic units to build a structured graph, applies structural neighbor expansion during retrieval, and performs multi-modal fusion of results. To support evaluation, the authors release Multi-Table-RAG-Lib, a new benchmark of 9870 QA pairs requiring multi-table integration and text-table fusion. The central empirical claim is that FT-RAG outperforms prior baselines by 23.5% (table-level Hit Rate), 59.2% (cell-level Hit Rate), and 62.2% (exact-value accuracy recall).
Significance. If the reported gains prove robust, FT-RAG would represent a meaningful advance in retrieval-augmented reasoning over structured data, particularly for multi-table and heterogeneous contexts where conventional coarse-grained RAG fails. The new benchmark itself is a useful contribution, as it targets a documented scarcity of complex, multi-table evaluation resources.
major comments (3)
- [§4 and abstract] §4 (Experiments) and abstract: the headline improvements (23.5% table-level Hit Rate, 59.2% cell-level Hit Rate, 62.2% exact-value recall) are presented without any description of the Multi-Table-RAG-Lib curation protocol, question-generation method, human validation steps, or checks for leakage and distribution bias. Because the central claim rests entirely on performance deltas on this new benchmark, the absence of these details renders the deltas uninterpretable.
- [§4] §4 (Experiments): no information is supplied on how the baseline systems were re-implemented or re-run on Multi-Table-RAG-Lib, including retrieval budget, prompt templates, decoding parameters, or evaluation scripts. Without identical experimental conditions, the reported gains cannot be attributed to the fine-grained graph mechanism rather than differences in setup.
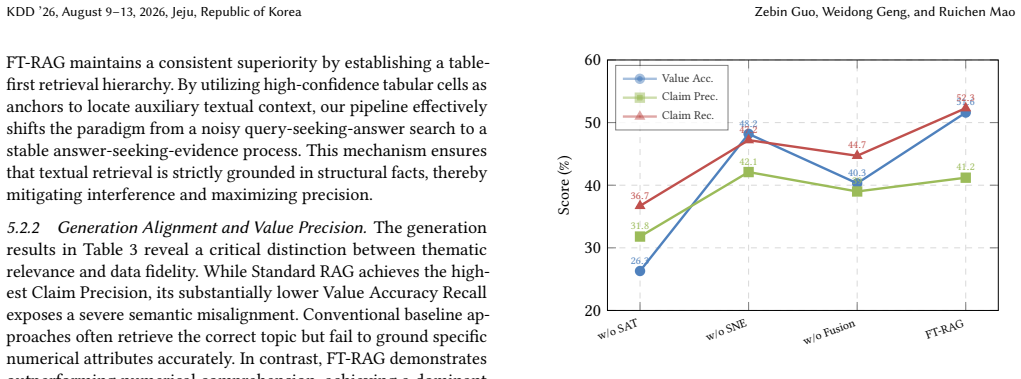
- [§3] §3 (Methodology): the core modeling assumption—that entry-level semantic decomposition plus structural neighbor expansion captures all necessary cross-table and text-table relations without context loss or retrieval noise—is stated but not tested via targeted ablations or failure-case analysis. This assumption is load-bearing for the claimed superiority over coarse-grained baselines.
minor comments (3)
- [Abstract] Abstract: 'conventiona RAG' is a typo.
- [§4] The manuscript would be strengthened by reporting statistical significance, error bars, or results across multiple random seeds for all metrics.
- [§3] Notation for graph nodes, edges, and the multi-modal fusion step could be made more explicit (e.g., a small diagram or pseudocode) to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify key areas where additional details will improve the interpretability and reproducibility of our results. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4 and abstract] §4 (Experiments) and abstract: the headline improvements (23.5% table-level Hit Rate, 59.2% cell-level Hit Rate, 62.2% exact-value recall) are presented without any description of the Multi-Table-RAG-Lib curation protocol, question-generation method, human validation steps, or checks for leakage and distribution bias. Because the central claim rests entirely on performance deltas on this new benchmark, the absence of these details renders the deltas uninterpretable.
Authors: We agree that these details are necessary to properly interpret the reported gains. In the revised manuscript we will add a dedicated subsection in §4 describing the Multi-Table-RAG-Lib curation protocol, the question-generation procedure, human validation steps, leakage-prevention measures, and any distribution-bias checks performed. revision: yes
-
Referee: [§4] §4 (Experiments): no information is supplied on how the baseline systems were re-implemented or re-run on Multi-Table-RAG-Lib, including retrieval budget, prompt templates, decoding parameters, or evaluation scripts. Without identical experimental conditions, the reported gains cannot be attributed to the fine-grained graph mechanism rather than differences in setup.
Authors: We acknowledge that complete experimental specifications are required for fair comparison. We will expand §4 to document the re-implementation details for all baselines, including retrieval budgets, prompt templates, decoding parameters, and the evaluation scripts used to compute the reported metrics. revision: yes
-
Referee: [§3] §3 (Methodology): the core modeling assumption—that entry-level semantic decomposition plus structural neighbor expansion captures all necessary cross-table and text-table relations without context loss or retrieval noise—is stated but not tested via targeted ablations or failure-case analysis. This assumption is load-bearing for the claimed superiority over coarse-grained baselines.
Authors: While the overall performance improvements relative to coarse-grained baselines provide supporting evidence, we agree that targeted ablations would more directly validate the contribution of each component. In the revision we will add ablation experiments isolating the effects of entry-level decomposition and structural neighbor expansion, together with a failure-case analysis. revision: yes
Circularity Check
No circularity in framework or empirical claims
full rationale
The paper describes an empirical framework (table decomposition into semantic units, graph construction, neighbor expansion, multi-modal fusion) and reports performance gains on a newly introduced benchmark (Multi-Table-RAG-Lib). No equations, first-principles derivations, or parameter-fitting steps are present that reduce by construction to the paper's own inputs. Claims rest on external baseline comparisons rather than self-referential definitions, fitted predictions, or load-bearing self-citations. The absence of any mathematical chain or ansatz smuggling keeps the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Muhammad Arslan, Hussam Ghanem, Saba Munawar, and Christophe Cruz. 2024. A Survey on RAG with LLMs.Procedia Computer Science246 (1 2024), 3781–3790. doi:10.1016/j.procs.2024.09.178
-
[2]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. arXiv:2310.11511 [cs.CL] https://arxiv.org/abs/2310.11511
work page internal anchor Pith review arXiv 2023
-
[3]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models.KDD ’24: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(8 2024), 6491–6501. doi:10.1145/3637528.3671470
- [4]
-
[5]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2025. LightRAG: Simple and Fast Retrieval-Augmented Generation. arXiv:2410.05779 [cs.IR] https: //arxiv.org/abs/2410.05779
work page internal anchor Pith review arXiv 2025
-
[6]
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su
-
[7]
Hipporag: Neurobiologically inspired long-term memory for large language models,
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. arXiv:2405.14831 [cs.CL] https://arxiv.org/abs/2405.14831
-
[8]
Yujin Kang, Park Seong Woo, and Yoon-Sik Cho. 2025. GRIT: Guided Rela- tional Integration for Efficient Multi-Table Understanding. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Chris- tos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Suzh...
-
[9]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401 [cs.CL] https://arxiv.org/abs/ 2005.11401
work page internal anchor Pith review arXiv 2021
-
[10]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81. https://aclanthology.org/W04-1013/
2004
- [11]
- [12]
- [13]
- [14]
-
[15]
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Frame- work: BM25 and Beyond.Found. Trends Inf. Retr.3, 4 (April 2009), 333–389. doi:10.1561/1500000019
-
[16]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. arXiv:2401.18059 [cs.CL] https://arxiv.org/abs/2401. 18059
work page internal anchor Pith review arXiv 2024
-
[17]
Jiejun Tan, Zhicheng Dou, Wen Wang, Mang Wang, Weipeng Chen, and Ji-Rong Wen. 2025. HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems. InProceedings of the ACM on Web Conference 2025 (WWW ’25). ACM, 1733–1746. doi:10.1145/3696410.3714546
-
[18]
Yixuan Tang and Yi Yang. 2024. MultiHop-RAG: Benchmarking Retrieval- Augmented Generation for Multi-Hop Queries. arXiv:2401.15391 [cs.CL] https: //arxiv.org/abs/2401.15391
work page internal anchor Pith review arXiv 2024
-
[19]
Bin Wang, Chao Xu, Xiaomeng Zhao, Linke Ouyang, Fan Wu, Zhiyuan Zhao, Rui Xu, Kaiwen Liu, Yuan Qu, Fukai Shang, Bo Zhang, Liqun Wei, Zhihao Sui, Wei Li, Botian Shi, Yu Qiao, Dahua Lin, and Conghui He. 2024. MinerU: An Open-Source Solution for Precise Document Content Extraction. arXiv:2409.18839 [cs.CV] https://arxiv.org/abs/2409.18839
-
[20]
Xianjie Wu, Jian Yang, Linzheng Chai, Ge Zhang, Jiaheng Liu, Xinrun Du, Di Liang, Daixin Shu, Xianfu Cheng, Tianzhen Sun, Guanglin Niu, Tongliang Li, and Zhoujun Li. 2025. TableBench: A Comprehensive and Complex Benchmark for Table Question Answering. arXiv:2408.09174 [cs.CL] https://arxiv.org/abs/ 2408.09174
- [21]
- [22]
-
[23]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi
-
[24]
In8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020
BERTScore: Evaluating Text Generation with BERT. In8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=SkeHuCVFDr
2020
-
[25]
Xuanliang Zhang, Dingzirui Wang, Keyan Xu, Qingfu Zhu, and Wanxiang Che
-
[26]
arXiv:2505.15110 [cs.CL] https://arxiv.org/abs/2505.15110
RoT: Enhancing Table Reasoning with Iterative Row-Wise Traversals. arXiv:2505.15110 [cs.CL] https://arxiv.org/abs/2505.15110
-
[27]
Yilun Zhao, Yunxiang Li, Chenying Li, and Rui Zhang. 2022. MultiHiertt: Numer- ical Reasoning over Multi Hierarchical Tabular and Textual Data. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (Eds.). Association for Computational L...
- [28]
- [29]
- [30]
-
[31]
arXiv preprint arXiv:2504.01346 , year=
Jiaru Zou, Dongqi Fu, Sirui Chen, Xinrui He, Zihao Li, Yada Zhu, Jiawei Han, and Jingrui He. 2025. RAG over Tables: Hierarchical Memory Index, Multi-Stage Retrieval, and Benchmarking. https://arxiv.org/abs/2504.01346 A Data Preparation The data construction pipeline consists of two phases: (1) Entity Enrichment for metadata restoration, and (2) Randomized...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.