Recognition: unknown
MelShield: Robust Mel-Domain Audio Watermarking for Provenance Attribution of AI Generated Synthesized Speech
Pith reviewed 2026-05-10 16:01 UTC · model grok-4.3
The pith
MelShield embeds keyed binary payloads as low-energy perturbations in the Mel-spectrogram before vocoder synthesis to enable reliable attribution of AI-generated speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MelShield treats the intermediate Mel-spectrogram as the host signal and embeds a short binary payload via low-energy, keyed spread-spectrum perturbations distributed across carefully selected time-frequency regions prior to waveform synthesis, enabling plug-and-play watermarking for Mel-conditioned TTS architectures without requiring changes to the vocoder.
What carries the argument
Keyed spread-spectrum perturbation embedding performed on the Mel-spectrogram, which distributes the binary payload across chosen time-frequency bins so the marks remain extractable after synthesis and distortion.
If this is right
- Watermark extraction reaches near-100 percent bit accuracy after common distortions such as compression and additive noise.
- The same embedding step works across different Mel-conditioned vocoders without retraining or architectural modification.
- Multi-user keyed construction supports scalable attribution while limiting unauthorized extraction.
- Perceptual audio quality remains high because the perturbations are low-energy and confined to selected regions.
Where Pith is reading between the lines
- The method could be adapted to other Mel-based audio generators beyond speech, such as music or sound-effect models.
- If extraction stays reliable under more aggressive attacks, regulators could require similar marks for public disclosure of synthetic media.
- Combining the keyed payload with existing metadata standards might create a layered provenance system that survives re-encoding.
- Testing on longer utterances or streaming synthesis would reveal whether the time-frequency selection strategy scales without quality loss.
Load-bearing premise
Low-energy keyed perturbations placed in the Mel-spectrogram will survive vocoder synthesis and everyday signal distortions without noticeably reducing audio quality or forcing changes to the TTS model.
What would settle it
Run the extraction detector on audio produced by a Mel-conditioned TTS model after standard MP3 compression at 128 kbps or additive white noise at 20 dB SNR and measure whether bit accuracy falls substantially below the reported near-100 percent level.
Figures



read the original abstract
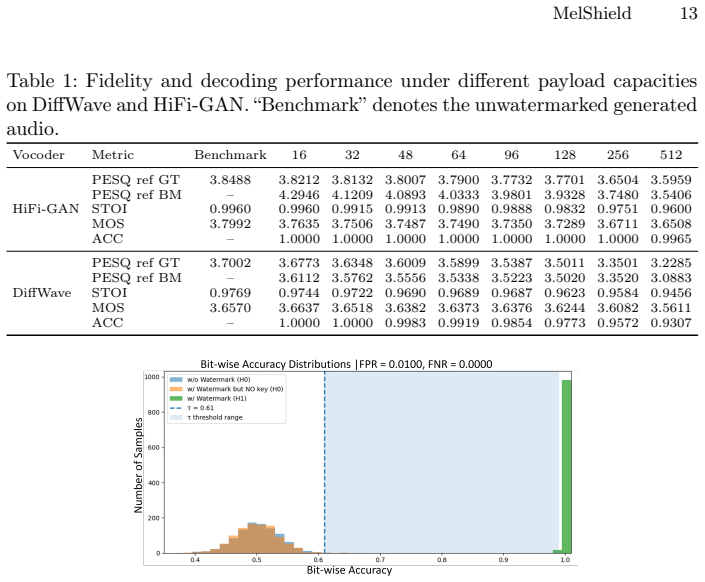
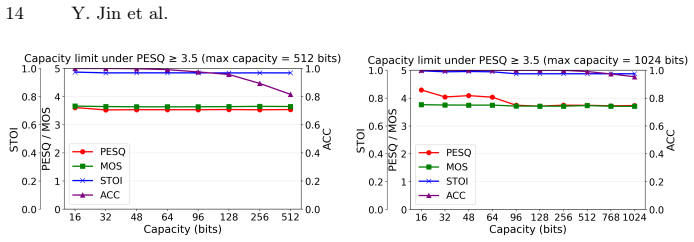
In this paper, we propose MelShield, a robust, in-generation, keyed audio watermarking framework that embeds identifiable signals into AI-generated audio for copyright protection and reliable attribution. Specifically, MelShield operates in the Mel-spectrogram domain during the generation process, targeting intermediate acoustic representations in Mel-conditioned pipelines for text-to-speech (TTS) generation. The core idea is to treat the intermediate Mel-spectrogram as the host signal and embed a short binary payload via low-energy, keyed spread-spectrum perturbations distributed across carefully selected time-frequency regions prior to waveform synthesis. By performing watermarking before vocoder inference, MelShield remains plug-and-play for Mel-conditioned TTS architectures and does not require modification or retraining of the underlying TTS generation vocoder, such as DiffWave and HiFi-GAN. Moreover, the multi-user keyed construction enables scalable user-specific attribution, while the keyed verification mechanism limits unauthorized decoding, thereby reducing the risk of large-scale extractor probing and adversarial analysis. Extensive experiments on DiffWave and HiFi-GAN demonstrate that MelShield achieves reliable watermark extraction, approaching 100\% bit accuracy, even under signal distortions, e.g., compression and additive noise, while preserving high perceptual audio quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MelShield, a keyed audio watermarking framework that embeds short binary payloads as low-energy spread-spectrum perturbations directly into the Mel-spectrogram of Mel-conditioned TTS pipelines (e.g., DiffWave, HiFi-GAN) prior to vocoder synthesis. The method is presented as plug-and-play, supporting multi-user attribution via keyed verification while claiming near-100% bit-extraction accuracy under common distortions such as compression and additive noise, without perceptible quality loss or TTS model retraining.
Significance. If the robustness and quality claims hold, the work would offer a practical, non-intrusive solution for provenance attribution of AI-generated speech, addressing a timely need for copyright protection and scalable user-specific tracing. The in-generation, keyed design and compatibility with existing vocoders are notable strengths that could facilitate adoption.
major comments (2)
- Abstract: the central claim of 'approaching 100% bit accuracy' under distortions is stated without any quantitative tables, error bars, exact distortion parameters (e.g., SNR levels, compression bitrates), baseline comparisons, or statistical tests, preventing verification of the reported performance.
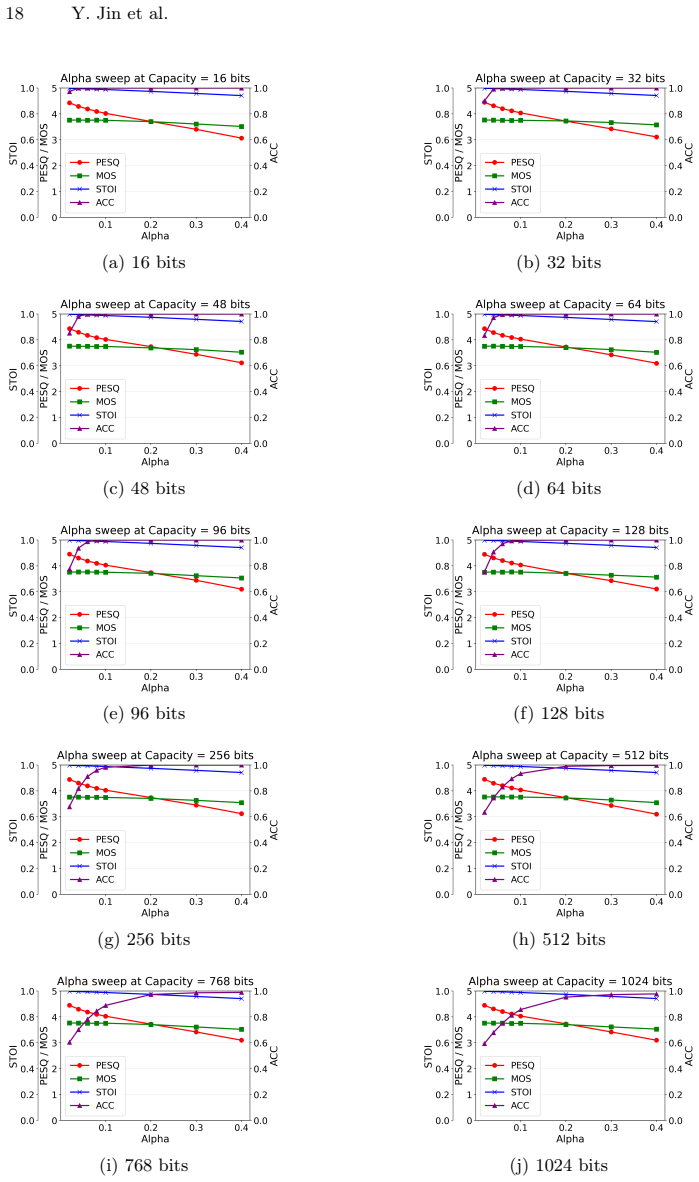
- Method and Experiments: the load-bearing assumption that low-energy keyed perturbations survive the non-linear vocoder mapping (HiFi-GAN, DiffWave) and remain extractable at high accuracy is not supported by reported ablation studies on perturbation energy levels, post-vocoder Mel reconstruction error, or accuracy-quality trade-offs.
minor comments (2)
- Abstract: the phrase 'approaching 100% bit accuracy' is imprecise; specific percentages, conditions, and confidence intervals should be provided.
- The description of 'carefully selected time-frequency regions' lacks detail on selection criteria or how they are determined from the payload and key.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We have addressed each major comment point by point below, with revisions made to improve clarity, verifiability, and empirical support where appropriate.
read point-by-point responses
-
Referee: Abstract: the central claim of 'approaching 100% bit accuracy' under distortions is stated without any quantitative tables, error bars, exact distortion parameters (e.g., SNR levels, compression bitrates), baseline comparisons, or statistical tests, preventing verification of the reported performance.
Authors: We agree that the abstract presents the performance claim at a high level and would benefit from greater specificity to enable direct verification. In the revised manuscript, we have updated the abstract to include references to the quantitative results from our experiments (e.g., bit accuracy under specific compression bitrates and SNR levels for additive noise), along with pointers to the tables, figures, error bars, baseline comparisons, and statistical tests provided in the main text. This revision ensures the claim is grounded and verifiable without changing the underlying experimental findings. revision: yes
-
Referee: Method and Experiments: the load-bearing assumption that low-energy keyed perturbations survive the non-linear vocoder mapping (HiFi-GAN, DiffWave) and remain extractable at high accuracy is not supported by reported ablation studies on perturbation energy levels, post-vocoder Mel reconstruction error, or accuracy-quality trade-offs.
Authors: The manuscript reports extensive end-to-end experiments on DiffWave and HiFi-GAN demonstrating high post-vocoding extraction accuracy under distortions, which empirically indicates that the low-energy perturbations survive the non-linear vocoder mapping. We acknowledge, however, that dedicated ablation studies on perturbation energy levels, post-vocoder Mel reconstruction error, and accuracy-quality trade-offs would provide more direct support for this assumption. We have therefore added these ablation studies to the revised manuscript (new subsection in Experiments), including sweeps of energy levels, reconstruction error metrics, and trade-off curves, to strengthen the evidence. revision: yes
Circularity Check
No circularity: MelShield's embedding construction and reported extraction accuracies are independent empirical results
full rationale
The paper presents a plug-and-play watermarking method that adds keyed spread-spectrum perturbations to the Mel-spectrogram prior to vocoder synthesis, then validates extraction bit accuracy under distortions via experiments on DiffWave and HiFi-GAN. No equations, fitted parameters, or self-citations are shown that reduce the claimed near-100% accuracy or robustness to a definition or input by construction. The central claims rest on external experimental validation rather than self-referential derivations, satisfying the criteria for a self-contained non-circular result.
Axiom & Free-Parameter Ledger
free parameters (1)
- perturbation energy level
axioms (1)
- domain assumption Spread-spectrum embedding can survive subsequent vocoding and common audio distortions when applied to Mel-spectrograms
Reference graph
Works this paper leans on
-
[1]
Wavmark: Watermarking for audio generation,
Chen, G., Wu, Y., Liu, S., Liu, T., Du, X., Wei, F.: Wavmark: Watermarking for audio generation. arXiv preprint arXiv:2308.12770 (2023)
-
[2]
https://keithito.com/LJ-Speech- Dataset/ (2017)
Ito, K., Johnson, L.: The lj speech dataset. https://keithito.com/LJ-Speech- Dataset/ (2017)
2017
-
[3]
Jia, Y., Zhang, Y., Weiss, R., Wang, Q., et al.: Transfer learning from speaker verification to multispeaker text-to-speech synthesis. Proc. of NeurIPS31(2018)
2018
-
[4]
In: Proc
Kim, J., Kim, S., Kong, J., Yoon, S.: Glow-tts: a generative flow for text-to-speech via monotonic alignment search. In: Proc. of NeurIPS (2020)
2020
-
[5]
Source tracing of audio deepfake systems.arXiv preprint arXiv:2407.08016,
Klein,N.,Chen,T.,Tak,H.,Casal,R.,Khoury,E.:Sourcetracingofaudiodeepfake systems. arXiv preprint arXiv:2407.08016 (2024) 20 Y. Jin et al
-
[6]
Kong, J., Kim, J., Bae, J.: Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Proc. of NeurIPS33, 17022–17033 (2020)
2020
-
[7]
Diffwave: A versatile diffusion model for audio synthesis.arXiv preprint arXiv:2009.09761,
Kong, Z., Ping, W., Huang, J., Zhao, K., Catanzaro, B.: Diffwave: A versatile diffusion model for audio synthesis. arXiv preprint arXiv:2009.09761 (2020)
-
[8]
In: Proc
Lee, S.g., Ping, W., Ginsburg, B., Catanzaro, B., Yoon, S.: Bigvgan: A universal neural vocoder with large-scale training. In: Proc. of International Conference on Learning Representations (2023)
2023
-
[9]
Li, Q., Lin, X.: Proactive audio authentication using speaker identity watermark- ing. In: PST. pp. 1–10 (2024)
2024
-
[10]
In: Network and Distributed System Security Symposium (2024)
Liu, C., Zhang, J., Zhang, T., Yang, X., Zhang, W., Yu, N.: Detecting voice cloning attacks via timbre watermarking. In: Network and Distributed System Security Symposium (2024)
2024
-
[11]
In: Proc
Liu, W., Li, Y., Lin, D., Tian, H., Li, H.: Groot: Generating robust watermark for diffusion-model-based audio synthesis. In: Proc. of ACM MM (2024)
2024
- [12]
-
[13]
In: Proc
Reddy, C.K.A., Gopal, V., Cutler, R.: Dnsmos: A non-intrusive perceptual objec- tive speech quality metric to evaluate noise suppressors. In: Proc. of ICASSP. pp. 6493–6497 (2021)
2021
-
[14]
Fastspeech 2: Fast and high-quality end-to-end text to speech,
Ren, Y., Hu, C., Tan, X., Qin, T., Zhao, S., Zhao, Z., Liu, T.Y.: Fastspeech 2: Fast and high-quality end-to-end text to speech. arXiv preprint arXiv:2006.04558 (2020)
-
[15]
In: Proc
Rix, A.W., Beerends, J.G., Hollier, M.P., Hekstra, A.P.: Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs. In: Proc. of ICASSP. vol. 2, pp. 749–752 (2001)
2001
-
[16]
arXiv preprint arXiv:2401.17264 (2024)
Roman, R.S., Fernandez, P., Défossez, A., Furon, T., Tran, T., Elsahar, H.: Proactive detection of voice cloning with localized watermarking. arXiv preprint arXiv:2401.17264 (2024)
-
[17]
In: Proc
Shen, J., Pang, R., Weiss, R.J., Schuster, M., Jaitly, N., Yang, Z., Chen, Z., Zhang, Y.,Wang,Y.,Skerrv-Ryan,R.,etal.:Naturalttssynthesisbyconditioningwavenet on mel spectrogram predictions. In: Proc. of ICASSP. pp. 4779–4783 (2018)
2018
-
[18]
The Journal of the Acoustical Society of America 8(3), 185–190 (1937)
Stevens, S.S., Volkmann, J., Newman, E.B.: A scale for the measurement of the psychological magnitude pitch. The Journal of the Acoustical Society of America 8(3), 185–190 (1937)
1937
-
[19]
IEEE Transactions on Audio, Speech, and Language Processing19(7), 2125–2136 (2011)
Taal,C.H.,Hendriks,R.C.,Heusdens,R.,Jensen,J.:Analgorithmforintelligibility prediction of time-frequency weighted noisy speech. IEEE Transactions on Audio, Speech, and Language Processing19(7), 2125–2136 (2011)
2011
-
[20]
WaveNet: A Generative Model for Raw Audio
Van Den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A., Kavukcuoglu, K., et al.: Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.0349912, 1 (2016)
work page internal anchor Pith review arXiv 2016
-
[21]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Wang, C., Chen, S., Wu, Y., Zhang, Z., Zhou, L., Liu, S., Chen, Z., Liu, Y., Wang, H., Li, J., He, L., Zhao, S., Wei, F.: Neural codec language models are zero-shot text to speech synthesizers (2023). https://doi.org/10.48550/arXiv.2301.02111
work page internal anchor Pith review doi:10.48550/arxiv.2301.02111 2023
- [22]
- [23]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.