Recognition: unknown
Feedback-Normalized Developer Memory for Reinforcement-Learning Coding Agents: A Safety-Gated MCP Architecture
Pith reviewed 2026-05-09 13:57 UTC · model grok-4.3
The pith
A safety-gated memory architecture for RL coding agents reaches 80 percent expected-decision accuracy and full hard-negative suppression on a 200-case benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that feedback-normalized developer memory, implemented as an MCP-native architecture with issue_match ranking, issue_feedback reward mapping, and issue_record_resolution linking, enables reliable memory use for RL coding agents. Deterministic control and the full shadow/OPE configuration both achieve 80.0 percent expected-decision accuracy and 100.0 percent hard-negative suppression on the 200-case benchmark, while static validation passes 11/11 checks and dynamic integration passes 10/10 cases. The system requires theory-to-code metadata and review-gated governance for RL memories and reports that active learned-policy deployment and full MCP interoperability remain un
What carries the argument
The safety-gated MCP architecture consisting of a deterministic ranker in production, a contextual-bandit residual policy in shadow mode, and conservative OPE gates that only permit canary influence after evaluation.
If this is right
- Deterministic control alone achieves 80.0 percent expected-decision accuracy and 100.0 percent hard-negative suppression.
- The full shadow/OPE configuration matches the deterministic accuracy while adding learning telemetry.
- Static validation passes all 11 checks and dynamic integration passes all 10 cases.
- RL and control memories require theory-to-code metadata plus review-gated governance.
- Active learned-policy deployment and official-client MCP interoperability remain unsupported.
Where Pith is reading between the lines
- The same gating approach could be tested on non-RL coding agents that still need auditable memory across long repository sessions.
- A larger and more diverse benchmark drawn from actual developer workflows would clarify whether the current 40 residual non-RL failures are representative.
- Extending the telemetry to influence future Bellman updates directly could close the loop between memory decisions and policy improvement.
Load-bearing premise
The 200-case deterministic benchmark, built around RL algorithm bugs, hard negatives, and review-gated cases, sufficiently represents the distribution of real long software-engineering episodes where memory details affect learning targets or validation claims.
What would settle it
A live full-configuration deployment in which the learned policy is activated and either accuracy drops below 80 percent, hard-negative suppression fails, or latency regresses beyond the reported limits.
Figures



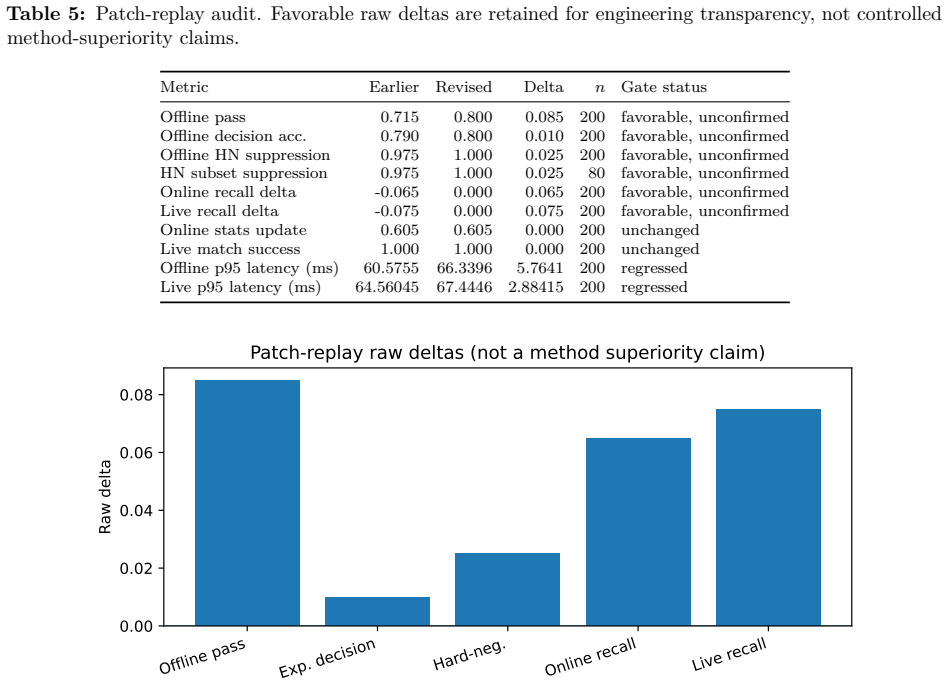
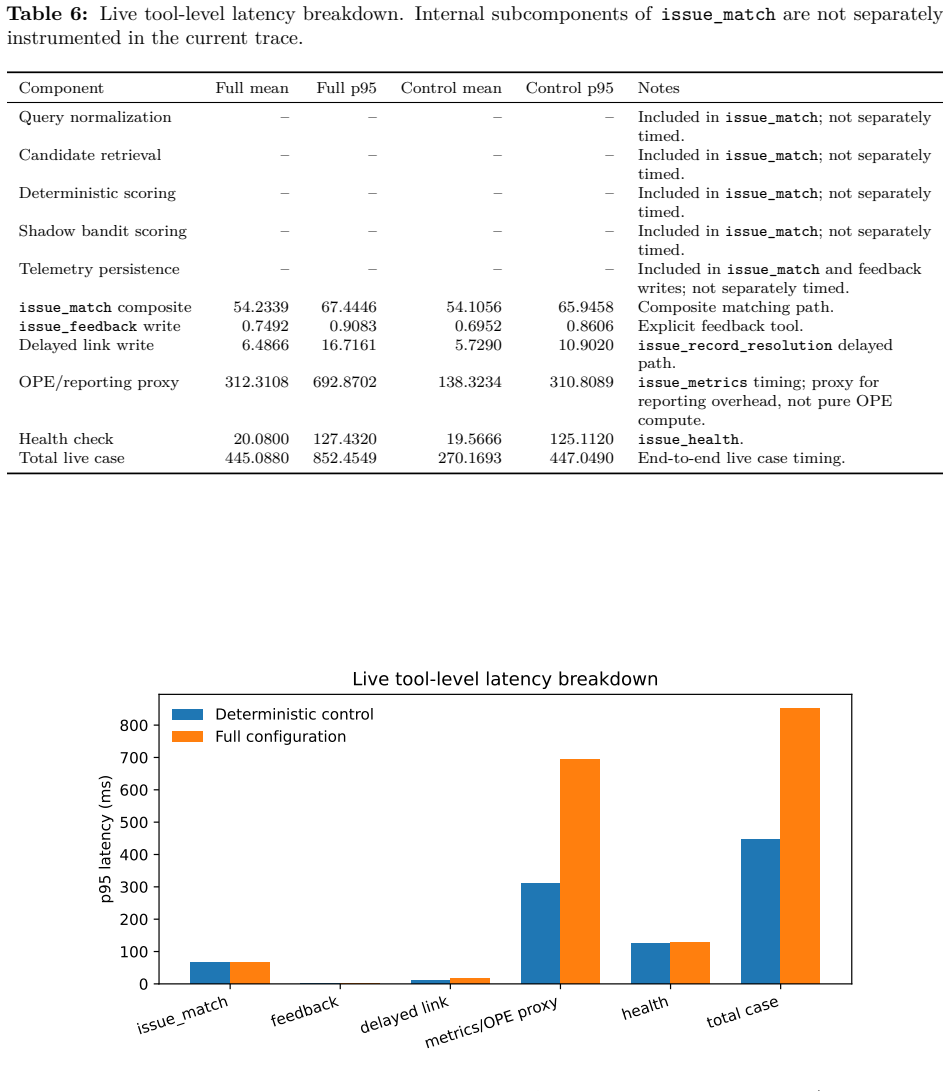
read the original abstract
Large language model (LLM) coding agents increasingly operate over repositories, terminals, tests, and execution traces across long software-engineering episodes. Persistent memory is useful, but static vector stores or generic retrieval-augmented generation (RAG) are insufficient for reinforcement-learning (RL) code development, where small details can alter Bellman targets, terminal masks, gradient flow, or validation claims. This paper presents RL Developer Memory, a local-first, Model Context Protocol (MCP)-native developer-memory architecture for RL coding agents. It treats memory selection as a logged contextual decision process: issue_match ranks candidates and records telemetry, issue_feedback maps raw labels to bounded rewards, and issue_record_resolution links verified resolutions to earlier retrieval events. A deterministic ranker remains deployed, while a contextual-bandit residual policy runs in shadow mode and can affect canary behavior only through conservative off-policy-evaluation (OPE) gates. RL/control memories require theory-to-code metadata and review-gated governance. The system is evaluated on a deterministic 200-case benchmark with RL algorithm bugs, hard negatives, review-gated RL/control cases, and low-risk failures. In the same-commit comparison, deterministic control and full shadow/OPE both achieve 80.0% expected-decision accuracy and 100.0% hard-negative suppression; the full configuration adds learning telemetry rather than accuracy gain. Static validation passed 11/11 checks; dynamic integration passed 10/10 cases. The evidence reports limits: active learned-policy deployment and official-client MCP interoperability are unsupported, live full-configuration latency regresses, and 40 residual non-RL failures remain. The contribution is an auditable memory-control architecture with explicit claim boundaries, not a universal coding-agent improvement claim.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RL Developer Memory, a local-first MCP-native architecture for persistent memory in RL coding agents. Memory selection is modeled as a logged contextual decision process with issue_match for ranking and telemetry, issue_feedback for mapping labels to bounded rewards, and issue_record_resolution for linking verified outcomes. A deterministic ranker operates in production while a contextual-bandit residual policy runs in shadow mode, subject to conservative OPE gates and review-gated governance for RL/control memories. The system is evaluated on a deterministic 200-case benchmark containing RL algorithm bugs, hard negatives, review-gated cases, and low-risk failures. In same-commit comparisons, both deterministic control and full shadow/OPE configurations achieve 80.0% expected-decision accuracy and 100.0% hard-negative suppression; the full configuration supplies learning telemetry without accuracy improvement. Static validation passes 11/11 checks and dynamic integration passes 10/10 cases, with explicit disclaimers that active learned-policy deployment, official-client MCP interoperability, and latency improvements are unsupported.
Significance. If the reported benchmark results hold, the work supplies a practical, auditable pattern for safely incorporating memory and residual learning into LLM coding agents. Its emphasis on explicit safety gates (shadow mode, OPE, review gating), transparent synthetic benchmark construction, and bounded claims (performance parity rather than superiority, plus listed limitations) provides a useful template for responsible engineering in the RL-for-code domain. The contribution is primarily architectural and governance-oriented rather than a universal performance advance.
major comments (1)
- [Evaluation] Evaluation (benchmark description): While the abstract states that the 200-case benchmark includes RL algorithm bugs, hard negatives, review-gated cases, and low-risk failures, the manuscript provides no quantitative breakdown of case construction, difficulty distribution, or how hard negatives were defined and validated. This detail is load-bearing for interpreting the 80% accuracy and 100% suppression figures as representative of the targeted RL memory issues.
minor comments (2)
- [Evaluation] The abstract and evaluation sections would benefit from a brief table summarizing the 200 cases by category (e.g., bug type, risk level) to improve reproducibility without expanding scope.
- Notation for the contextual-bandit residual policy and OPE gates could be clarified with a short pseudocode listing of the decision flow, as the textual description of shadow-mode gating is dense.
Simulated Author's Rebuttal
We thank the referee for the careful review and the recommendation of minor revision. The single major comment concerns the lack of quantitative detail in the benchmark description; we address it directly below.
read point-by-point responses
-
Referee: While the abstract states that the 200-case benchmark includes RL algorithm bugs, hard negatives, review-gated cases, and low-risk failures, the manuscript provides no quantitative breakdown of case construction, difficulty distribution, or how hard negatives were defined and validated. This detail is load-bearing for interpreting the 80% accuracy and 100% suppression figures as representative of the targeted RL memory issues.
Authors: We agree that the current manuscript does not supply a quantitative breakdown of the 200-case benchmark composition, the definition and validation criteria for hard negatives, or difficulty distribution. This information would improve interpretability of the reported metrics. In the revised version we will add a new subsection (or table) under Evaluation that enumerates the case counts by category, describes the deterministic construction process, specifies how hard negatives were identified and validated, and reports any available difficulty or coverage statistics. These additions will be placed before the accuracy and suppression results so readers can assess representativeness. revision: yes
Circularity Check
No significant circularity identified
full rationale
The manuscript describes an MCP-native memory architecture for RL coding agents, with components (issue_match ranking, issue_feedback reward mapping, issue_record_resolution linking) presented as design choices rather than derived quantities. Core performance numbers (80% expected-decision accuracy, 100% hard-negative suppression) are obtained from direct same-commit evaluation on an explicitly constructed 200-case deterministic benchmark; no equations, fitted parameters, or self-referential definitions appear in the abstract or provided text that would reduce these reported figures back to the input data by construction. No self-citations, uniqueness theorems, or ansatzes are invoked to support the central claims. The derivation chain is therefore self-contained against the stated benchmark and explicit scope limitations.
Axiom & Free-Parameter Ledger
invented entities (1)
-
RL Developer Memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A method for evaluating hyperparameter sensitivity in reinforcement learning
Jacob Adkins, Michael Bowling, and Adam White. A method for evaluating hyperparameter sensitivity in reinforcement learning. InAdvances in Neural Information Processing Systems, volume 37, pages 124820–124842, 2024. doi: 10.48550/arXiv.2412.07165. URL https: //arxiv.org/abs/2412.07165
-
[2]
Traces of memorisation in large language models for code
Ali Al-Kaswan, Maliheh Izadi, and Arie Van Deursen. Traces of memorisation in large language models for code. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–12, 2024. doi: 10.1145/3597503.3639133. URL https: //doi.org/10.1145/3597503.3639133. 21
-
[3]
Doubly robust policy evaluation and learning
Miroslav Dudık, John Langford, and Lihong Li. Doubly robust policy evaluation and learning. InProceedings of the 28th International Conference on Machine Learning, pages 1097–1104,
-
[4]
Doubly Robust Policy Evaluation and Learning
doi: 10.48550/arXiv.1103.4601. URLhttps://arxiv.org/abs/1103.4601
-
[5]
Hyperparameters in reinforcement learning and how to tune them
Theresa Eimer, Marius Lindauer, and Roberta Raileanu. Hyperparameters in reinforcement learning and how to tune them. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 9104–9149, 2023. doi: 10.48550/arXiv.2306.01324. URLhttps://proceedings.mlr.press/v202/eimer23a.html
-
[6]
GRACG: Graph retrieval augmented code generation
Konstantin Fedorov, Boris Zarubin, and Vladimir Ivanov. GRACG: Graph retrieval augmented code generation. In2025 40th IEEE/ACM International Conference on Automated Software Engineering Workshops, pages 291–298, 2025. doi: 10.1109/ASEW67777.2025.00060. URL https://doi.org/10.1109/ASEW67777.2025.00060
-
[7]
Banditrank: Learning to rank using contextual bandits
Phanideep Gampa and Sumio Fujita. Banditrank: Learning to rank using contextual bandits. InPacific-Asia Conference on Knowledge Discovery and Data Mining, pages 259–271. Springer,
-
[8]
URL https://doi.org/10.1007/978-3-030-757 68-7_21
doi: 10.1007/978-3-030-75768-7_21. URL https://doi.org/10.1007/978-3-030-757 68-7_21
-
[9]
Patrick Gassert and Matthias Althoff. Stepping out of the shadows: Reinforcement learning in shadow mode.arXiv preprint arXiv:2410.23419, 2024. doi: 10.48550/arXiv.2410.23419. URL https://arxiv.org/abs/2410.23419
-
[10]
Xiaodong Gu, Meng Chen, Yalan Lin, Yuhan Hu, Hongyu Zhang, Chengcheng Wan, Zhao Wei, Yong Xu, and Juhong Wang. On the effectiveness of large language models in domain- specific code generation.ACM Transactions on Software Engineering and Methodology, 34(3): 78:1–78:28, 2025. doi: 10.1145/3697012. URLhttps://doi.org/10.1145/3697012
-
[11]
Continuous safety assessment of updated supervised learning models in shadow mode
Hatem Guissouma, Markus Zink, and Eric Sax. Continuous safety assessment of updated supervised learning models in shadow mode. In2023 IEEE 20th International Conference on Software Architecture Companion, pages 301–308, 2023. doi: 10.1109/ICSA-C57050.2023.00069. URLhttps://doi.org/10.1109/ICSA-C57050.2023.00069
-
[12]
Deep Reinforcement Learning that Matters
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. Deep reinforcement learning that matters. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3207–3214, 2018. doi: 10.48550/arXiv.1709.06560. URL https://arxiv.org/abs/1709.06560
-
[13]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world github issues? In International Conference on Learning Representations, 2024. doi: 10.48550/arXiv.2310.06770. URL https://arxiv.org/abs/2310.06770. OpenReview: https://openreview.net/forum ?id=VTF8yNQM66
work page internal anchor Pith review doi:10.48550/arxiv.2310.06770 2024
-
[14]
Security threats in agentic ai system.arXiv preprint arXiv:2410.14728, 2024
Raihan Khan, Soumik Sarkar, Shubha Kanti Mahata, and Erwin Jose. Security threats in agentic ai system.arXiv preprint arXiv:2410.14728, 2024. doi: 10.48550/arXiv.2410.14728. URLhttps://arxiv.org/abs/2410.14728
-
[15]
Multi-agent reinforcement learning for interactive code debugging with human feedback and memory
Anjana Krishnamoorthy, Kartik Ivatury, and Benyamin Ahmadnia. Multi-agent reinforcement learning for interactive code debugging with human feedback and memory. InProceedings of the 15th International Conference on Recent Advances in Natural Language Processing - 22 Natural Language Processing in the Generative AI Era, pages 595–603, Varna, Bulgaria, 2025....
2025
-
[16]
Conservative q-learning for offline reinforcement learning, 2020
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. InAdvances in Neural Information Processing Systems, volume 33, pages 1179–1191, 2020. doi: 10.48550/arXiv.2006.04779. URLhttps://arxiv.or g/abs/2006.04779
-
[17]
Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D. Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M. Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, and Aleksandra Faust. Training language models to self-correct via reinforcement learning.arXiv preprint...
-
[18]
Eunji Lee. Towards ethical personal ai applications: Practical considerations for ai assistants withlong-termmemory.arXiv preprint arXiv:2409.11192, 2024. doi: 10.48550/arXiv.2409.11192. URLhttps://arxiv.org/abs/2409.11192
-
[19]
doi:10.48550/a rXiv.2503.06034
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. InAdvances in Neural Information Processing Systems, volume 33, pages 9459–9474, 2020. doi: 10.48550/...
work page doi:10.48550/a 2020
-
[20]
URLhttps://doi.org/10.1145/1772690.1772758
Lihong Li, Wei Chu, John Langford, and Robert E. Schapire. A contextual-bandit approach to personalized news article recommendation. InProceedings of the 19th International Conference on World Wide Web, pages 661–670, 2010. doi: 10.1145/1772690.1772758. URL https: //doi.org/10.1145/1772690.1772758
-
[21]
Liu, Kevin Lin, John Hewitt, Bhargavi Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024. doi: 10.1162/tacl_a_00638. URLhttps://doi.org/10.1162/tacl_a_00638
-
[22]
Normalization and effective learning rates in reinforcement learning
Clare Lyle, Zeyu Zheng, Khimya Khetarpal, James Martens, Hado van Hasselt, Razvan Pascanu, and Will Dabney. Normalization and effective learning rates in reinforcement learning. In Advances in Neural Information Processing Systems, volume 37, pages 106440–106473, 2024. doi: 10.48550/arXiv.2407.01800. URLhttps://arxiv.org/abs/2407.01800
-
[23]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Sean Welleck, Bodhisattwa Prasad Majumder, Shashank Gupta, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Systems, volume 36,
-
[24]
Self-Refine: Iterative Refinement with Self-Feedback
doi: 10.48550/arXiv.2303.17651. URLhttps://arxiv.org/abs/2303.17651
work page internal anchor Pith review doi:10.48550/arxiv.2303.17651
-
[25]
Model context protocol specification, 2026
Model Context Protocol. Model context protocol specification, 2026. URLhttps://modelcon textprotocol.io/specification/2025-11-25. Accessed May 2, 2026
2026
-
[26]
Locobench-agent: An interactive benchmark for LLM agents in long-context software engineering,
Jielin Qiu, Zuxin Liu, Zhiwei Liu, Rithesh Murthy, Jianguo Zhang, Haolin Chen, Shiyu Wang, Ming Zhu, Liangwei Yang, Juntao Tan, Roshan Ram, Akshara Prabhakar, Tulika 23 Awalgaonkar, Zixiang Chen, Zhepeng Cen, Cheng Qian, Shelby Heinecke, Weiran Yao, Silvio Savarese, Caiming Xiong, and Huan Wang. LoCoBench-Agent: An interactive benchmark for llm agents in ...
-
[27]
Latent reward: Llm-empowered credit assignment in episodic reinforcement learning
Yun Qu, Yuhang Jiang, Boyuan Wang, Yixiu Mao, Cheems Wang, Chang Liu, and Xiangyang Ji. Latent reward: Llm-empowered credit assignment in episodic reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 20095–20103,
-
[28]
Latent reward: Llm-empowered credit assignment in episodic reinforcement learning
doi: 10.1609/aaai.v39i19.34213. URL https://doi.org/10.1609/aaai.v39i19.34213
-
[29]
Exploring security risks and mitigation strategies in ai code helpers
Harshith Sheggam and Xiaowen Zhang. Exploring security risks and mitigation strategies in ai code helpers. In2024 IEEE Long Island Systems, Applications and Technology Conference, pages 1–6, 2024. doi: 10.1109/LISAT63094.2024.10807934. URLhttps://doi.org/10.1109/ LISAT63094.2024.10807934
-
[30]
Interactive recommendation via deep neural memory augmented contextual bandits
Yilin Shen, Yang Deng, Avik Ray, and Hongxia Jin. Interactive recommendation via deep neural memory augmented contextual bandits. InProceedings of the 12th ACM Conference on Recommender Systems, pages 122–130, 2018. doi: 10.1145/3240323.3240344. URL https://doi.org/10.1145/3240323.3240344
-
[31]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, 2023. doi: 10.48550/arXiv.2303.11366. URL https://arxiv.org/abs/2303.11366. OpenReview: https://openreview.net/forum?id= vAElhFcKW6
work page internal anchor Pith review doi:10.48550/arxiv.2303.11366 2023
-
[32]
Jiayin Song, Yike Li, Yunzhe Tian, Haoxuan Ma, Honglei Li, Jie Zuo, Jiqiang Liu, and Wenjia Niu. Investigating the bugs in reinforcement learning programs: Insights from stack overflow and github.Automated Software Engineering, 33(1):9, 2026. doi: 10.1007/s10515-025-00555-z. URLhttps://doi.org/10.1007/s10515-025-00555-z
-
[33]
Counterfactual risk minimization: Learning from logged bandit feedback
Adith Swaminathan and Thorsten Joachims. Counterfactual risk minimization: Learning from logged bandit feedback. InProceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 814–823, 2015. URL https://proceedings.mlr.press/v37/swaminathan15.html
2015
-
[34]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2024. doi: 10.48550/arXiv.2410.10813. URLhttps://arxiv.org/abs/24 10.10813
work page internal anchor Pith review doi:10.48550/arxiv.2410.10813 2024
-
[35]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems, 2024. doi: 10.48550/arXiv.2405.15793. URLhttps://arxiv.org/abs/2405.15793
work page internal anchor Pith review doi:10.48550/arxiv.2405.15793 2024
-
[36]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023. doi: 10.48550/arXiv.2210.03629. URLhttps://arxiv.or g/abs/2210.03629. OpenReview:https://openreview.net/forum?id=WE_vluYUL-X. 24
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.03629 2023
-
[37]
COMBO: Conservative offline model-based policy optimization
Tianhe Yu, Aviral Kumar, Rafael Rafailov, Aravind Rajeswaran, Sergey Levine, and Chelsea Finn. COMBO: Conservative offline model-based policy optimization. InAdvances in Neural Information Processing Systems, volume 34, pages 28954–28967, 2021. doi: 10.48550/arXiv.210 2.08363. URLhttps://arxiv.org/abs/2102.08363
-
[38]
Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, Zhiyu Li, Feiyu Xiong, Yutao Qi, Bo Tang, Weinan Zhang, and Muning Wen. MemRL: Self-evolving agents via runtime reinforcement learning on episodic memory.arXiv preprint arXiv:2601.03192, 2026. doi: 10.48550/arXiv.2601.03192. URLhttps://arxiv.org/abs/2601.03192
-
[39]
MemoryBank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19724–19731, 2024. doi: 10.1609/aaai.v38i17.29946. URLhttps://doi.org/10.1609/aaai.v38i17.29946. 25
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.