Recognition: no theorem link
Hydra-DP3: Frequency-Aware Right-Sizing of 3D Diffusion Policies for Visuomotor Control
Pith reviewed 2026-05-12 03:42 UTC · model grok-4.3
The pith
Robot action trajectories are mostly low-frequency, so diffusion policies need only two denoising steps for strong performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By analyzing action trajectories in the frequency domain, the error bound of the optimal denoiser is shown to depend on the low-frequency subspace dimension and residual high-frequency energy, which implies that two-step DDIM sampling suffices for action denoising, enabling a pocket-scale policy with a Diffusion Mixer decoder.
What carries the argument
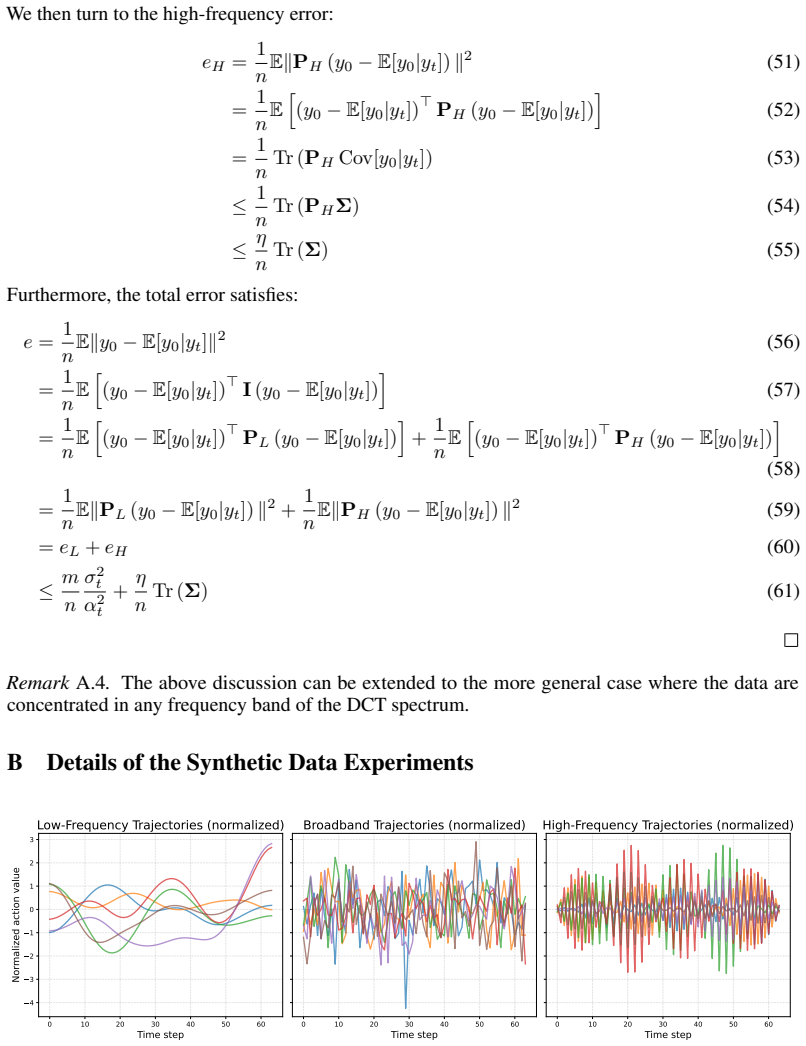
Frequency-domain analysis via discrete cosine transform on action trajectories, which reveals low-frequency concentration and bounds the denoising error to justify a simplified two-step diffusion process with a lightweight decoder.
If this is right
- State-of-the-art performance on RoboTwin2.0, Adroit, MetaWorld, and real-world robotic tasks.
- Uses fewer than 1% of the parameters compared to prior 3D diffusion-based policies.
- Substantially reduced inference latency due to two-step sampling.
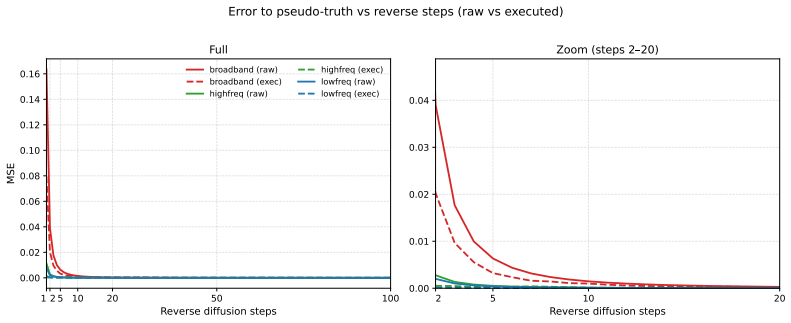
- Validated through synthetic experiments confirming the sufficiency of two-step denoising.
Where Pith is reading between the lines
- Similar frequency analysis might allow right-sizing of diffusion models in other control domains like autonomous driving or animation.
- Adaptive number of denoising steps could be implemented based on measured trajectory smoothness for further efficiency gains.
- This suggests potential for combining with other compression techniques to make real-time visuomotor control feasible on edge devices.
Load-bearing premise
That the observed low-frequency concentration in the tested action trajectories holds generally enough that exactly two denoising steps capture full performance without missing critical details in unseen scenarios.
What would settle it
Running the policy on a task with highly abrupt or high-frequency actions, such as rapid collision avoidance, and checking if two-step performance drops significantly compared to multi-step sampling.
Figures







read the original abstract
Diffusion-based visuomotor policies perform well in robotic manipulation, yet current methods still inherit image-generation-style decoders and multi-step sampling. We revisit this design from a frequency-domain perspective. Robot action trajectories are highly smooth, with most energy concentrated in a few low-frequency discrete cosine transform modes. Under this structure, we show that the error of the optimal denoiser is bounded by the low-frequency subspace dimension and residual high-frequency energy, implying that denoising error saturates after very few reverse steps. This also suggests that action denoising requires a much simpler denoising model than image generation. Motivated by this insight, we propose Hydra-DP3 (HDP3), a pocket-scale 3D diffusion policy with a lightweight Diffusion Mixer decoder that supports two-step DDIM inference. Our synthetic experiments validate the theory and support the sufficiency of two-step denoising. Futhermore, across RoboTwin2.0, Adroit, MetaWorld, and real-world tasks, HDP3 achieves state-of-the-art performance with fewer than 1% of the parameters of prior 3D diffusion-based policies and substantially lower inference latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Hydra-DP3 (HDP3), a frequency-aware right-sized 3D diffusion policy for visuomotor control. It observes that robot action trajectories concentrate energy in a small number of low-frequency DCT modes, derives an error bound for the optimal denoiser implying that denoising error saturates after very few reverse steps, and proposes a lightweight Diffusion Mixer decoder that enables two-step DDIM sampling. Synthetic experiments are said to validate the theory, and the method is reported to achieve SOTA performance on RoboTwin2.0, Adroit, MetaWorld, and real-world tasks while using <1% of the parameters of prior 3D diffusion policies and substantially lower inference latency.
Significance. If the central claims hold, the work would demonstrate a principled, frequency-domain route to dramatically smaller and faster diffusion policies for robotics without sacrificing performance. The approach could improve real-time feasibility of visuomotor diffusion models. Credit is due for the explicit frequency analysis of actions and the attempt to link it to a concrete architectural reduction (two-step DDIM + pocket-scale decoder).
major comments (3)
- [§3 (error bound derivation) and §4 (Diffusion Mixer)] The error bound (presumably §3) is stated for the optimal denoiser. The actual model is the learned Diffusion Mixer trained end-to-end with visual conditioning. No analysis or ablation shows that this low-capacity network reaches the optimal low-frequency approximation closely enough for the two-step DDIM schedule to incur negligible extra error on the real visuomotor action spaces.
- [§5 (synthetic experiments) and §6 (benchmark results)] The claim that two denoising steps suffice without hidden performance loss rests on the weakest assumption that low-frequency concentration plus the optimal-denoiser bound directly transfers to the learned model. Synthetic validation is cited but does not close this gap for the diverse real tasks (RoboTwin2.0, Adroit, MetaWorld, real-world).
- [§6 (benchmark tables)] Table or figure reporting parameter counts and latency (presumably in §6) states <1% parameters and lower latency, but lacks error bars, number of seeds, or explicit data-exclusion rules, making it difficult to assess whether the SOTA claim is robust.
minor comments (2)
- [Abstract] Abstract contains the typo 'Futhermore'.
- [§4] Notation for the Diffusion Mixer decoder and its conditioning mechanism could be clarified with a diagram or explicit equations.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important distinctions between theoretical bounds and learned models, as well as the need for stronger empirical validation. We address each point below and commit to revisions that strengthen the manuscript without overstating our claims.
read point-by-point responses
-
Referee: [§3 (error bound derivation) and §4 (Diffusion Mixer)] The error bound (presumably §3) is stated for the optimal denoiser. The actual model is the learned Diffusion Mixer trained end-to-end with visual conditioning. No analysis or ablation shows that this low-capacity network reaches the optimal low-frequency approximation closely enough for the two-step DDIM schedule to incur negligible extra error on the real visuomotor action spaces.
Authors: We agree that the error bound in §3 applies strictly to the optimal denoiser. Our synthetic experiments in §5 show that the learned Diffusion Mixer exhibits comparable saturation of denoising error after two steps on action trajectories. To directly address the gap for real visuomotor tasks, we will add a new ablation in the revised manuscript that computes the per-step denoising error of the trained model versus the optimal low-frequency projection on held-out trajectories from RoboTwin2.0 and MetaWorld, quantifying how closely the lightweight decoder approximates the bound. revision: partial
-
Referee: [§5 (synthetic experiments) and §6 (benchmark results)] The claim that two denoising steps suffice without hidden performance loss rests on the weakest assumption that low-frequency concentration plus the optimal-denoiser bound directly transfers to the learned model. Synthetic validation is cited but does not close this gap for the diverse real tasks (RoboTwin2.0, Adroit, MetaWorld, real-world).
Authors: The referee correctly notes that synthetic results alone do not fully prove transfer. While §6 already reports that two-step HDP3 matches or exceeds multi-step baselines on all four real task suites, we will expand the discussion in §5 and add a dedicated paragraph in §6 that explicitly links the observed SOTA performance (with no degradation relative to 10-step variants) to the frequency concentration measured on those same datasets, thereby providing empirical closure for the diverse real tasks. revision: partial
-
Referee: [§6 (benchmark tables)] Table or figure reporting parameter counts and latency (presumably in §6) states <1% parameters and lower latency, but lacks error bars, number of seeds, or explicit data-exclusion rules, making it difficult to assess whether the SOTA claim is robust.
Authors: We accept this criticism. In the revised manuscript we will update all benchmark tables to report mean and standard deviation over 5 independent seeds, specify the exact number of evaluation episodes per task, and include a clear statement of the data-exclusion protocol (e.g., success defined as reaching the goal within the horizon without early termination). revision: yes
Circularity Check
Frequency-derived error bound is mathematically self-contained with independent validation
full rationale
The paper starts from the empirical observation that action trajectories concentrate energy in low-frequency DCT modes, then derives a bound on optimal-denoiser error using only the subspace dimension and residual high-frequency energy. This bound is invoked to justify saturation after few steps and a lightweight decoder; the derivation does not rely on fitted parameters renamed as predictions, self-citations for uniqueness, or ansatzes smuggled from prior work. Synthetic experiments are presented as separate validation of the bound, and task performance is reported as an empirical outcome rather than a forced consequence of the bound itself. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Robot action trajectories are highly smooth, with most energy concentrated in a few low-frequency discrete cosine transform modes.
invented entities (1)
-
Diffusion Mixer decoder
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey of robot learning from demonstration.Robotics and autonomous systems, 57(5):469–483, 2009
Brenna D Argall, Sonia Chernova, Manuela Veloso, and Brett Browning. A survey of robot learning from demonstration.Robotics and autonomous systems, 57(5):469–483, 2009
work page 2009
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Minshuo Chen, Kaixuan Huang, Tuo Zhao, and Mengdi Wang. Score approximation, estimation and distribution recovery of diffusion models on low-dimensional data. InInternational Conference on Machine Learning, pages 4672–4712. PMLR, 2023
work page 2023
-
[4]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[6]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffu- sion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687, 2022
work page internal anchor Pith review arXiv 2022
-
[7]
A fourier space perspective on diffusion models
Fabian Falck, Teodora Pandeva, Kiarash Zahirnia, Rachel Lawrence, Richard Turner, Edward Meeds, Javier Zazo, and Sushrut Karmalkar. A fourier space perspective on diffusion models. arXiv preprint arXiv:2505.11278, 2025
-
[8]
Pete Florence, Corey Lynch, Andy Zeng, Oscar A Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. Implicit behavioral cloning. InConference on Robot Learning, pages 158–168. PMLR, 2022
work page 2022
-
[9]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Act3d: 3d feature field transformers for multi-task robotic manipulation
Theophile Gervet, Zhou Xian, Nikolaos Gkanatsios, and Katerina Fragkiadaki. Act3d: 3d feature field transformers for multi-task robotic manipulation. InConference on Robot Learning, pages 3949–3965. PMLR, 2023
work page 2023
-
[11]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[12]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation.arXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review arXiv 2021
-
[15]
Takayuki Osa, Joni Pajarinen, Gerhard Neumann, J Andrew Bagnell, Pieter Abbeel, and Jan Peters. An algorithmic perspective on imitation learning.Foundations and Trends® in Robotics, 7(1-2):1–179, 2018
work page 2018
-
[16]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023. 11
work page 2023
-
[17]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: A vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Aaditya Prasad, Kevin Lin, Jimmy Wu, Linqi Zhou, and Jeannette Bohg. Consistency policy: Accelerated visuomotor policies via consistency distillation.arXiv preprint arXiv:2405.07503, 2024
-
[19]
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
work page 2017
-
[20]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. InInternational conference on machine learning, pages 5301–5310. PMLR, 2019
work page 2019
-
[21]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations.arXiv preprint arXiv:1709.10087, 2017
work page Pith review arXiv 2017
-
[22]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
work page 2015
-
[24]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth interna- tional conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
work page 2011
-
[25]
Masked world models for visual control
Younggyo Seo, Danijar Hafner, Hao Liu, Fangchen Liu, Stephen James, Kimin Lee, and Pieter Abbeel. Masked world models for visual control. InConference on Robot Learning, pages 1332–1344. PMLR, 2023
work page 2023
-
[26]
Mp1: Meanflow tames policy learning in 1-step for robotic manipulation
Juyi Sheng, Ziyi Wang, Peiming Li, and Mengyuan Liu. Mp1: Meanflow tames policy learning in 1-step for robotic manipulation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18532–18539, 2026
work page 2026
-
[27]
Perceiver-actor: A multi-task transformer for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InConference on Robot Learning, pages 785–799. PMLR, 2023
work page 2023
-
[28]
Learning structured output representation using deep conditional generative models
Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning structured output representation using deep conditional generative models. InAdvances in Neural Information Processing Systems, volume 28, 2015
work page 2015
-
[29]
Haoming Song, Delin Qu, Yuanqi Yao, Qizhi Chen, Qi Lv, Yiwen Tang, Modi Shi, Guanghui Ren, Maoqing Yao, Bin Zhao, et al. Hume: Introducing system-2 thinking in visual-language- action model.arXiv preprint arXiv:2505.21432, 2025
-
[30]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[31]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023
work page 2023
-
[32]
Hengkai Tan, Songming Liu, Kai Ma, Chengyang Ying, Xingxing Zhang, Hang Su, and Jun Zhu. Fourier controller networks for real-time decision-making in embodied learning.arXiv preprint arXiv:2405.19885, 2024. 12
-
[33]
Ilya O Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. Mlp- mixer: An all-mlp architecture for vision.Advances in neural information processing systems, 34:24261–24272, 2021
work page 2021
-
[34]
One-step diffusion policy: Fast visuomotor policies via diffusion distillation
Zhendong Wang, Max Li, Ajay Mandlekar, Zhenjia Xu, Jiaojiao Fan, Yashraj Narang, Linxi Fan, Yuke Zhu, Yogesh Balaji, Mingyuan Zhou, Ming-Yu Liu, and Yu Zeng. One-step diffusion policy: Fast visuomotor policies via diffusion distillation. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[35]
One-step diffusion policy: Fast visuomotor policies via diffusion distillation
Zhendong Wang, Zhaoshuo Li, Ajay Mandlekar, Zhenjia Xu, Jiaojiao Fan, Yashraj Narang, Linxi Fan, Yuke Zhu, Yogesh Balaji, Mingyuan Zhou, et al. One-step diffusion policy: Fast visuomotor policies via diffusion distillation.arXiv preprint arXiv:2410.21257, 2024
-
[36]
Stable velocity: A variance perspective on flow matching.arXiv preprint arXiv:2602.05435, 2026
Donglin Yang, Yongxing Zhang, Xin Yu, Liang Hou, Xin Tao, Pengfei Wan, Xiaojuan Qi, and Renjie Liao. Stable velocity: A variance perspective on flow matching.arXiv preprint arXiv:2602.05435, 2026
-
[37]
arXiv preprint arXiv:2407.02398 , year=
Ling Yang, Zixiang Zhang, Zhilong Zhang, Xingchao Liu, Minkai Xu, Wentao Zhang, Chenlin Meng, Stefano Ermon, and Bin Cui. Consistency flow matching: Defining straight flows with velocity consistency.arXiv preprint arXiv:2407.02398, 2024
-
[38]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on robot learning, pages 1094–1100. PMLR, 2020
work page 2020
-
[39]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. In 2nd Workshop on Dexterous Manipulation: Design, Perception and Control (RSS), 2024
work page 2024
-
[40]
Qinglun Zhang, Zhen Liu, Haoqiang Fan, Guanghui Liu, Bing Zeng, and Shuaicheng Liu. Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 14754–14762, 2025. 13 A Proof of Theorem 4.1 We first derive the closed-form ex...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.