Recognition: unknown
Led to Mislead: Adversarial Content Injection for Attacks on Neural Ranking Models
Pith reviewed 2026-05-09 17:34 UTC · model grok-4.3
The pith
CRAFT uses large language models to generate fluent adversarial text that boosts targeted documents in neural ranking models across multiple architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
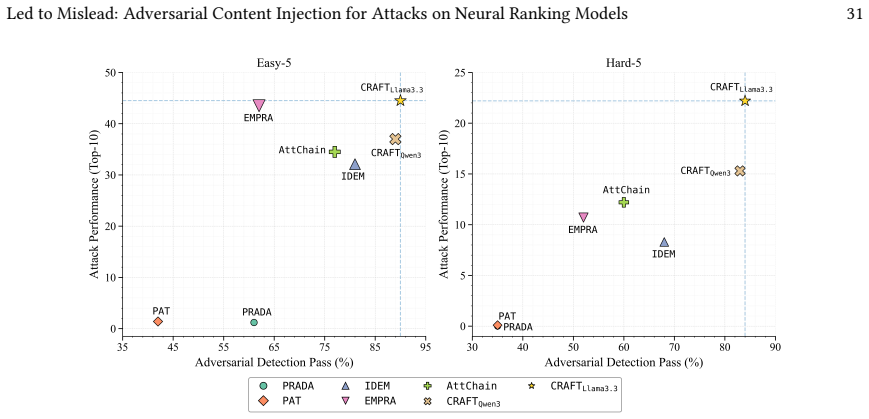
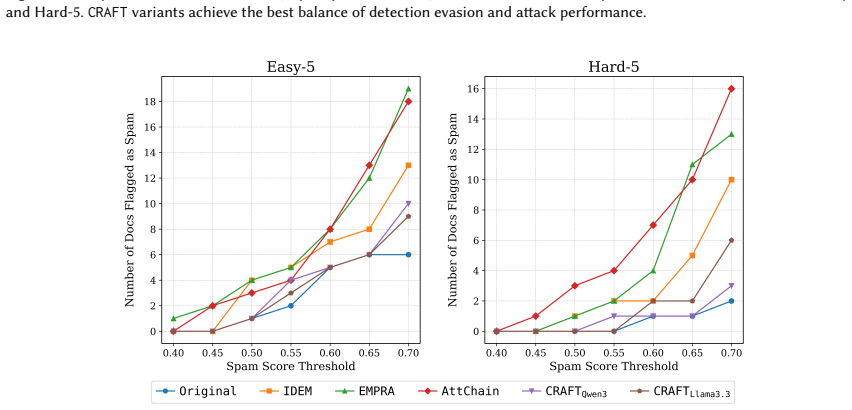
CRAFT is a supervised black-box framework that generates adversarial content via retrieval-augmented generation and self-refinement, followed by supervised fine-tuning and preference-guided optimization; on MS MARCO, TREC DL 2019, and TREC DL 2020 it achieves higher promotion rates and rank boosts than existing baselines while preserving fluency and semantic fidelity, and the attacks transfer across cross-encoder, embedding-based, and LLM-based ranking architectures.
What carries the argument
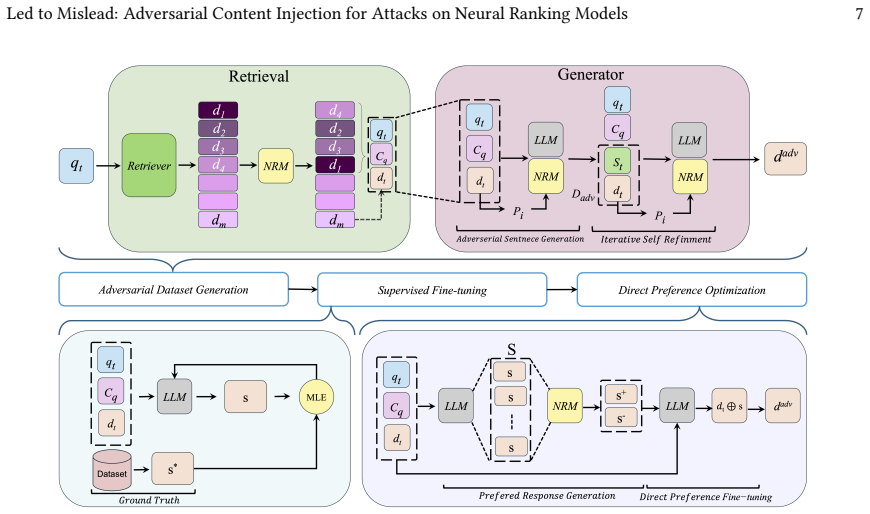
CRAFT, the three-stage supervised framework that produces rank-promoting adversarial examples through retrieval-augmented generation with self-refinement, supervised fine-tuning on those examples, and preference-guided optimization aligned to promotion objectives.
Load-bearing premise
The adversarial content generated this way will remain effective and undetected when inserted into real-world deployed ranking systems that may apply additional filters or human review.
What would settle it
Inserting the generated adversarial passages into an operational neural ranking system and checking whether they achieve comparable promotion rates and rank boosts without being filtered or flagged as low quality.
Figures




read the original abstract
Neural Ranking Models (NRMs) are central to modern information retrieval but remain highly vulnerable to adversarial manipulation. Existing attacks often rely on heuristics or surrogate models, limiting effectiveness and transferability. We propose CRAFT, a supervised framework for black-box adversarial rank attacks powered by large language models (LLMs). CRAFT operates in three stages: adversarial dataset generation via retrieval-augmented generation and self-refinement, supervised fine-tuning on curated adversarial examples, and preference-guided optimization to align generations with rank-promotion objectives. Extensive experiments on the MS MARCO passage dataset, TREC Deep Learning 2019, and TREC Deep Learning 2020 benchmarks show that CRAFT significantly outperforms state-of-the-art baselines, achieving higher promotion rates and rank boosts while preserving fluency and semantic fidelity. Moreover, CRAFT transfers effectively across diverse ranking architectures, including cross-encoder, embedding-based, and LLM-based rankers, underscoring vulnerabilities in real-world retrieval systems. This work provides a principled framework for studying adversarial threats in NRMs, underscores the risks of generative AI in rank manipulation, and provides a foundation for developing more robust retrieval systems. To support reproducibility, we publicly release our source code, trained models, and prompt templates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CRAFT, a three-stage supervised framework that uses large language models to generate adversarial content for black-box attacks on neural ranking models. The stages are: (1) adversarial dataset creation via retrieval-augmented generation and self-refinement, (2) supervised fine-tuning on curated examples, and (3) preference-guided optimization to promote higher ranks. Experiments on the MS MARCO passage dataset and TREC Deep Learning 2019/2020 benchmarks report that CRAFT outperforms prior baselines in promotion rates and rank boosts while preserving fluency and semantic fidelity, and that the attacks transfer across cross-encoder, embedding-based, and LLM-based rankers. The authors release code, trained models, and prompt templates.
Significance. If the performance and transferability results hold with proper ablations and statistical controls, the work would be significant for the IR community by supplying a reproducible, LLM-driven methodology for studying adversarial threats to neural rankers. The public release of source code, trained models, and prompt templates is a clear strength that enables independent verification and extension. The findings could help motivate defenses against generative-AI-enabled rank manipulation.
major comments (2)
- [Abstract] Abstract: The statement that the results 'underscore vulnerabilities in real-world retrieval systems' extrapolates from benchmark-only experiments (MS MARCO passage, TREC DL 2019, TREC DL 2020) without any evaluation of whether the generated passages trigger production quality filters, spam detectors, duplicate-content rules, or human review.
- [§4 (Experiments)] §4 (Experiments) and Abstract: The central claims of outperformance and cross-architecture transfer are presented without reported quantitative metrics, error bars, ablation results on the contribution of each stage, or statistical significance tests, making it impossible to assess the magnitude and reliability of the reported gains from the summary alone.
minor comments (2)
- [Abstract] Abstract: Key numerical results (e.g., promotion rates, rank boosts) should be included to make the summary self-contained and informative.
- Ensure all acronyms (NRM, LLM, RAG, etc.) are defined at first use and that section headings clearly delineate the three stages of CRAFT.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of claim precision and experimental reporting that we will address through targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that the results 'underscore vulnerabilities in real-world retrieval systems' extrapolates from benchmark-only experiments (MS MARCO passage, TREC DL 2019, TREC DL 2020) without any evaluation of whether the generated passages trigger production quality filters, spam detectors, duplicate-content rules, or human review.
Authors: We agree that the abstract phrasing extrapolates beyond the scope of our benchmark experiments. MS MARCO and TREC DL benchmarks are standard proxies for real-world retrieval but do not incorporate production filters or human review. In the revised version, we will rephrase the abstract to state that the results demonstrate vulnerabilities in neural ranking models on these representative benchmarks and add a limitations paragraph explicitly noting the lack of evaluation against spam detectors, duplicate rules, or live production systems. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments) and Abstract: The central claims of outperformance and cross-architecture transfer are presented without reported quantitative metrics, error bars, ablation results on the contribution of each stage, or statistical significance tests, making it impossible to assess the magnitude and reliability of the reported gains from the summary alone.
Authors: Section 4 of the full manuscript already reports concrete quantitative metrics such as promotion rates and rank improvements relative to baselines. To strengthen rigor, we will add error bars from repeated runs, ablation studies quantifying the contribution of each CRAFT stage (RAG, self-refinement, fine-tuning, preference optimization), and statistical significance tests (e.g., paired t-tests with p-values) for key comparisons. These additions will be incorporated into §4 and briefly referenced in the abstract. revision: yes
Circularity Check
No circularity: empirical framework with benchmark comparisons
full rationale
The paper proposes CRAFT as a three-stage supervised LLM-based attack framework and validates it through experiments on MS MARCO, TREC DL 2019, and TREC DL 2020. Performance claims rest on direct comparisons to baselines rather than any derivation chain, equations, or fitted parameters that reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes; the method description and results are self-contained within the reported benchmarks. The extrapolation to real-world systems is an untested assumption but does not constitute circularity in the derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Naveed Akhtar and Ajmal Mian. 2018. Threat of adversarial attacks on deep learning in computer vision: A survey.Ieee Access6 (2018), 14410–14430
2018
-
[2]
Marwah Alaofi, Negar Arabzadeh, Charles LA Clarke, and Mark Sanderson. 2024. Generative information retrieval evaluation. InInformation access in the era of generative ai. Springer, 135–159. Manuscript submitted to ACM Led to Mislead: Adversarial Content Injection for Attacks on Neural Ranking Models 37
2024
-
[3]
Negar Arabzadeh, Amin Bigdeli, and Charles LA Clarke. 2024. Adapting standard retrieval benchmarks to evaluate generated answers. InEuropean Conference on Information Retrieval. Springer, 399–414
2024
-
[4]
Arian Askari, Mohammad Aliannejadi, Evangelos Kanoulas, and Suzan Verberne. 2023. A test collection of synthetic documents for training rankers: Chatgpt vs. human experts. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 5311–5315
2023
-
[5]
Arian Askari, Mohammad Aliannejadi, Chuan Meng, Evangelos Kanoulas, and Suzan Verberne. 2023. Expand, highlight, generate: RL-driven document generation for passage reranking. InProceedings of the 2023 conference on empirical methods in natural language processing. 10087–10099
2023
-
[6]
Barrett, Isam Faik, and Tawfik Jelassi
Michael I. Barrett, Isam Faik, and Tawfik Jelassi. 2025. Platform governance as institutional custodianship: multi-actor collaboration in combating AI-enabled mis/disinformation.Inf. Organ.35, 3 (2025), 100590. https://doi.org/10.1016/J.INFOANDORG.2025.100590
- [7]
-
[8]
Amin Bigdeli, Negar Arabzadeh, Ebrahim Bagheri, and Charles L. A. Clarke. 2026. EMPRA: Embedding Perturbation Rank Attack against Neural Ranking Models.ACM Trans. Inf. Syst.(March 2026). https://doi.org/10.1145/3801943 Just Accepted
-
[9]
Marco Braga, Pranav Kasela, Alessandro Raganato, and Gabriella Pasi. 2024. Synthetic Data Generation with Large Language Models for Personalized Community Question Answering. In2024 IEEE/WIC International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT). IEEE, 360–366
2024
-
[10]
Carlos Castillo, Brian D Davison, et al. 2011. Adversarial web search.Foundations and trends®in information retrieval4, 5 (2011), 377–486
2011
-
[11]
Xuanang Chen, Ben He, Zheng Ye, Le Sun, and Yingfei Sun. 2023. Towards Imperceptible Document Manipulations against Neural Ranking Models. InFindings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, 6648–66...
-
[12]
Zhuo Chen, Yuyang Gong, Jiawei Liu, Miaokun Chen, Haotan Liu, Qikai Cheng, Fan Zhang, Wei Lu, and Xiaozhong Liu. 2025. FlippedRAG: Black-Box Opinion Manipulation Adversarial Attacks to Retrieval-Augmented Generation Models. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, CCS 2025. ACM, 4109–4123. https://doi.org/10...
- [13]
- [14]
-
[15]
DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948 [cs.CL] https: //arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [16]
-
[17]
Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, Lhassane Idoumghar, and Pierre-Alain Muller. 2019. Adversarial attacks on deep neural networks for time series classification. In2019 International joint conference on neural networks (IJCNN). IEEE, 1–8
2019
-
[18]
Yuyang Gong, Zhuo Chen, Jiawei Liu, Miaokun Chen, Fengchang Yu, Wei Lu, Xiaofeng Wang, and Xiaozhong Liu. 2025. Topic-FlipRAG: Topic- Orientated Adversarial Opinion Manipulation Attacks to Retrieval-Augmented Generation Models. In34th USENIX Security Symposium, USENIX Security 2025, Seattle, W A, USA, August 13–15, 2025. USENIX Association
2025
-
[19]
Zoltán Gyöngyi and Hector Garcia-Molina. 2005. Web Spam Taxonomy. InAIRWeb 2005, First International Workshop on Adversarial Information Retrieval on the Web, co-located with the WWW conference, Chiba, Japan, May 2005. 39–47. http://airweb.cse.lehigh.edu/2005/gyongyi.pdf
2005
-
[20]
Madiha Khalid, Muhammad Faheem Mushtaq, Urooj Akram, Mejdl Safran, Sultan Alfarhood, and Imran Ashraf. 2025. Sentiment analysis for deepfake X posts using novel transfer learning based word embedding and hybrid LGR approach.Scientific Reports15, 1 (2025), 28305
2025
-
[21]
VI Lcvenshtcin. 1966. Binary coors capable or ‘correcting deletions, insertions, and reversals. InSoviet physics-doklady, Vol. 10
1966
-
[22]
Yongkang Li, Panagiotis Eustratiadis, and Evangelos Kanoulas. 2025. Reproducing HotFlip for Corpus Poisoning Attacks in Dense Retrieval. In European Conference on Information Retrieval. Springer, 95–111
2025
-
[23]
Yongkang Li, Panagiotis Eustratiadis, Simon Lupart, and Evangelos Kanoulas. 2025. Unsupervised Corpus Poisoning Attacks in Continuous Space for Dense Retrieval. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2452–2462
2025
-
[24]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
2004
-
[25]
2022.Pretrained transformers for text ranking: Bert and beyond
Jimmy Lin, Rodrigo Nogueira, and Andrew Yates. 2022.Pretrained transformers for text ranking: Bert and beyond. Springer Nature
2022
-
[26]
Jiawei Liu, Yangyang Kang, Di Tang, Kaisong Song, Changlong Sun, Xiaofeng Wang, Wei Lu, and Xiaozhong Liu. 2022. Order-Disorder: Imitation Adversarial Attacks for Black-box Neural Ranking Models. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, CCS 2022, Los Angeles, CA, USA, November 7-11, 2022, Heng Yin, Angelos S...
-
[27]
Yu-An Liu, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Wei Chen, Yixing Fan, and Xueqi Cheng. 2023. Black-box Adversarial Attacks against Dense Retrieval Models: A Multi-view Contrastive Learning Method. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 1647–1656
2023
-
[28]
Yu-An Liu, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, and Xueqi Cheng. 2024. Multi-granular Adversarial Attacks against Black-box Neural Ranking Models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1391–1400. Manuscript submitted to ACM 38 Amin Bigdeli et al
2024
-
[29]
Yu-An Liu, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, and Xueqi Cheng. 2025. Attack-in-the-chain: bootstrapping large language models for attacks against black-box neural ranking models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 12229–12237
2025
-
[30]
Florence Martin, Jennifer DeLarm, Min Zhuang, Yang Cheng, William Rand, and Jaekuk Lee. 2025. Combating Dark-side of Computing - Exploring Perceptions of AI-augmented Mis/disinformation among Higher Education Students. InProceedings of the 2025 ACM Conference on International Computing Education Research V.2, ICER 2025, CharlottesvilleV AUSA, August 3-6, ...
- [31]
-
[32]
Rami Mohawesh, Islam Obaidat, Ahmed Abdallah AlQarni, Ali Abdulaziz Aljubailan, Moy’awiah A Al-Shannaq, Haythem Bany Salameh, Ali Al-Yousef, Ahmad A Saifan, Suboh M Alkhushayni, and Sumbal Maqsood. 2025. Truth be told: a multimodal ensemble approach for enhanced fake news detection in textual and visual media.Journal of Big Data12, 1 (2025), 197
2025
- [33]
-
[34]
Nina Narodytska and Shiva Prasad Kasiviswanathan. 2017. Simple Black-Box Adversarial Attacks on Deep Neural Networks.. InCVPR workshops, Vol. 2
2017
-
[35]
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. InProceedings of the Workshop on Cognitive Computation: Integrating neural and symbolic approaches 2016 co-located with the 30th Annual Conference on Neural Information Processing Systems...
2016
- [36]
- [37]
- [38]
-
[39]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog1, 8 (2019), 9
2019
-
[40]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
-
[41]
Hossein A Rahmani, Clemencia Siro, Mohammad Aliannejadi, Nick Craswell, Charles LA Clarke, Guglielmo Faggioli, Bhaskar Mitra, Paul Thomas, and Emine Yilmaz. 2024. Llm4eval: Large language model for evaluation in ir. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 3040–3043
2024
-
[42]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, Kentaro Inui, Jing Jiang, Vincent...
-
[43]
Stephen Robertson, Hugo Zaragoza, et al. 2009. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends®in Information Retrieval3, 4 (2009), 333–389
2009
-
[44]
Minoru Sasaki and Hiroyuki Shinnou. 2005. Spam detection using text clustering. In2005 International Conference on Cyberworlds (CW’05). IEEE, 4–pp
2005
-
[45]
Sahel Sharifymoghaddam, Ronak Pradeep, Andre Slavescu, Ryan Nguyen, Andrew Xu, Zijian Chen, Yilin Zhang, Yidi Chen, Jasper Xian, and Jimmy Lin. 2025. RankLLM: A Python Package for Reranking with LLMs. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(Padua, Italy)(SIGIR ’25). Association for ...
2025
-
[46]
Junshuai Song, Jiangshan Zhang, Jifeng Zhu, Mengyun Tang, and Yong Yang. 2022. TRAttack: Text rewriting attack against text retrieval. In Proceedings of the 7th Workshop on Representation Learning for NLP. 191–203
2022
- [47]
-
[48]
Weiwei Sun, Lingyong Yan, Xinyu Ma, Pengjie Ren, Dawei Yin, and Zhaochun Ren. 2023. Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 14918–14937
2023
-
[49]
Qwen Team. 2025. QwQ-32B: Embracing the Power of Reinforcement Learning. https://qwenlm.github.io/blog/qwq-32b/
2025
- [50]
- [51]
-
[52]
Xinru Wang, Hannah Kim, Sajjadur Rahman, Kushan Mitra, and Zhengjie Miao. 2024. Human-llm collaborative annotation through effective verification of llm labels. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–21. Manuscript submitted to ACM Led to Mislead: Adversarial Content Injection for Attacks on Neural Ranking Models 39
2024
-
[53]
Yumeng Wang, Lijun Lyu, and Avishek Anand. 2022. BERT Rankers are Brittle: A Study using Adversarial Document Perturbations. InICTIR ’22: The 2022 ACM SIGIR International Conference on the Theory of Information Retrieval, Madrid, Spain, July 11 - 12, 2022, Fabio Crestani, Gabriella Pasi, and Éric Gaussier (Eds.). ACM, 115–120. https://doi.org/10.1145/3539...
-
[54]
Alex Warstadt, Amanpreet Singh, and Samuel R Bowman. 2019. Neural network acceptability judgments.Transactions of the Association for Computational Linguistics7 (2019), 625–641
2019
-
[55]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, Novem...
-
[56]
Chen Wu, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, and Xueqi Cheng. 2023. PRADA: Practical Black-box Adversarial Attacks against Neural Ranking Models.ACM Trans. Inf. Syst.41, 4 (2023), 89:1–89:27. https://doi.org/10.1145/3576923
-
[57]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675(2019)
work page internal anchor Pith review arXiv 2019
-
[59]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176 (2025)
work page internal anchor Pith review arXiv 2025
- [60]
-
[61]
Bin Zhou and Jian Pei. 2009. OSD: An online web spam detection system. InIn Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD, Vol. 9
2009
-
[62]
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. 2025. PoisonedRAG: Knowledge Corruption Attacks to Retrieval-Augmented Generation of Large Language Models. In34th USENIX Security Symposium, USENIX Security 2025, Seattle, W A, USA, August 13–15, 2025. USENIX Association, 3827–3844. A Prompt Design and Templates In this appendix, we present the prompt...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.