Recognition: 2 theorem links
Toward Fair Speech Technologies: A Comprehensive Survey of Bias and Fairness in Speech AI
Pith reviewed 2026-05-08 19:24 UTC · model grok-4.3
The pith
A survey of over 400 studies organizes fairness research in speech AI into seven adapted definitions and three paradigms that guide evaluation and mitigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
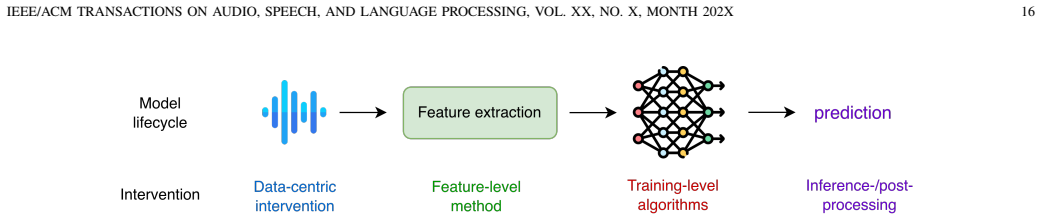
The paper establishes that fairness research in speech AI has progressed through three paradigms—Robustness, Representation, and Governance—and that seven formal definitions adapted to the speech modality can be grounded in mathematical cores to support evaluation metrics, diagnosis of bias sources along the pipeline including channel bias as a demographic proxy and annotation subjectivity, and mitigation strategies systematized across four intervention stages.
What carries the argument
The central mechanism is the unified framework that links the seven speech-adapted fairness definitions to a decision tree for metric selection, diagnosis of speech-specific bias sources, and a mapping of mitigation strategies to four intervention stages.
If this is right
- Researchers can use the decision tree to select consistent metrics for fairness evaluation across generation and perception tasks.
- Diagnosis of specific bias sources such as channel bias will allow targeted fixes at the right stage of the speech pipeline.
- Mitigation strategies mapped to diagnosed sources will replace generic approaches that overlook audio-specific issues.
- Open challenges identified for emerging speech-language models will focus future work on remaining gaps.
- Shared failure patterns across tasks will become visible, supporting transfer of solutions between different speech applications.
Where Pith is reading between the lines
- This structure could serve as a model for building similar unified frameworks in other AI areas such as image or text processing.
- Developers of speech products could apply the bias diagnosis steps to audit their own systems for overlooked proxies.
- Empirical tests could check whether the three paradigms predict which new mitigation methods succeed in practice.
- Links between subjective emotion labeling and similar problems in other subjective AI tasks could create shared practices across fields.
Load-bearing premise
The selection of over 400 studies is comprehensive enough to reveal all shared failure patterns across speech tasks, and the three-paradigm organization with the decision tree fully captures the conceptual evolution without major omissions.
What would settle it
A new study that identifies a major shared bias pattern in speech AI not classifiable under robustness, representation, or governance, or that demonstrates the seven definitions leave out essential aspects of fairness for audio data.
Figures

read the original abstract
Speech technologies are deployed in high-stakes settings, yet fairness concerns remain fragmented across tasks and disciplines. Existing surveys either adopt a general machine-learning perspective that overlooks speech-specific properties or focus on a single task, missing failure patterns shared across the speech domain. Synthesizing over 400 studies spanning generation and perception tasks and emerging speech-language models, this survey presents a unified framework that links formal fairness definitions to evaluation, diagnosis, and mitigation. We formalize seven fairness definitions adapted to the speech modality and organize the field's conceptual evolution through three paradigms: Robustness, Representation, and Governance. We then ground evaluation metrics in the mathematical cores of these definitions and offer a decision tree for metric selection. We diagnose bias sources along the speech processing pipeline, surfacing speech-specific mechanisms such as channel bias as a demographic proxy and annotation subjectivity in emotion labels. We systematize mitigation strategies across four intervention stages, mapping each to the diagnosed sources. Finally, we identify open challenges and propose directions for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys bias and fairness issues in speech AI by synthesizing over 400 studies spanning generation and perception tasks as well as emerging speech-language models. It formalizes seven fairness definitions adapted to speech, organizes the field's evolution into three paradigms (Robustness, Representation, and Governance), grounds evaluation metrics in the mathematical cores of these definitions, offers a decision tree for metric selection, diagnoses bias sources along the speech pipeline (including speech-specific mechanisms such as channel bias as a demographic proxy and annotation subjectivity in emotion labels), systematizes mitigation strategies across four intervention stages mapped to those sources, and identifies open challenges with future directions.
Significance. If the synthesis is representative, the work provides a valuable unification of fragmented research by explicitly linking formal fairness definitions to practical evaluation, diagnosis, and mitigation in the speech domain. The three-paradigm organization, decision tree, and source-to-mitigation mapping could help researchers navigate speech-specific challenges that general ML fairness surveys overlook, while surfacing cross-task patterns.
major comments (1)
- The manuscript provides no documentation of the literature search protocol, including databases, keywords, date bounds, inclusion/exclusion criteria, or inter-rater reliability measures used to identify and select the over 400 studies. This is load-bearing for the central claim that the synthesis reveals shared failure patterns and supports the three-paradigm framework plus decision tree, because without it the identified patterns (e.g., channel bias) could reflect selection or visibility bias rather than domain-wide regularities.
minor comments (2)
- The abstract and introduction repeatedly cite 'over 400 studies' without a precise count or breakdown by task/paradigm in a summary table; adding such a table would improve transparency and allow readers to assess coverage balance.
- Notation for the seven formalized fairness definitions could be clarified by including a dedicated table that contrasts each definition's mathematical core with its speech-specific adaptation.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting the value of our synthesis while identifying an important area for improvement in transparency. We address the major comment below and will incorporate the requested documentation in the revised manuscript.
read point-by-point responses
-
Referee: The manuscript provides no documentation of the literature search protocol, including databases, keywords, date bounds, inclusion/exclusion criteria, or inter-rater reliability measures used to identify and select the over 400 studies. This is load-bearing for the central claim that the synthesis reveals shared failure patterns and supports the three-paradigm framework plus decision tree, because without it the identified patterns (e.g., channel bias) could reflect selection or visibility bias rather than domain-wide regularities.
Authors: We agree that explicit documentation of the literature collection process would strengthen the manuscript's claims regarding representative patterns and the resulting frameworks. The survey was compiled through an iterative, broad search across key databases and venues (Google Scholar, arXiv, IEEE Xplore, ACL Anthology, Interspeech proceedings, and ICASSP) using terms such as 'bias in automatic speech recognition', 'fairness in speech synthesis', 'demographic disparities in speaker verification', 'bias in speech emotion recognition', and related variants, with coverage primarily from 2015 onward to capture the rise of deep learning in speech AI. Inclusion focused on peer-reviewed or preprint works that empirically examined bias, fairness, or ethical issues in speech generation or perception tasks; exclusion applied to purely theoretical works without speech-specific analysis or those outside the speech modality. No formal inter-rater reliability statistic was computed, as the process involved the author team with cross-checking and consensus discussions rather than independent raters. In the revision we will add a dedicated 'Literature Search and Selection' subsection (likely in Section 2 or as an appendix) that details these elements, along with approximate counts per paradigm and task to allow readers to assess coverage. This addition will directly support the validity of the diagnosed patterns and the three-paradigm organization without altering the core synthesis. revision: yes
Circularity Check
No circularity: external synthesis with no self-referential derivations
full rationale
This survey synthesizes over 400 external studies to present adapted fairness definitions and a three-paradigm organization. No mathematical derivations, predictions, fitted parameters, or equations appear in the provided text. All claims reference outward to the cited literature rather than reducing to self-definitions, self-citations as load-bearing premises, or renamed internal results. The selection process critique concerns representativeness but does not create a circular reduction in any derivation chain. The work is self-contained as a literature review against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yu and L
D. Yu and L. Deng,Automatic speech recognition. Springer, 2016, vol. 1
2016
-
[2]
Recent advances in end-to-end automatic speech recog- nition,
J. Liet al., “Recent advances in end-to-end automatic speech recog- nition,”APSIPA Transactions on Signal and Information Processing, 2022
2022
-
[3]
Task arithmetic can mitigate synthetic-to-real gap in automatic speech recognition,
H. Suet al., “Task arithmetic can mitigate synthetic-to-real gap in automatic speech recognition,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
2024
-
[4]
Pseudo2Real: Task Arithmetic for Pseudo-Label Correction in Automatic Speech Recognition
Y .-C. Linet al., “Pseudo2real: Task arithmetic for pseudo-label correc- tion in automatic speech recognition,”arXiv preprint arXiv:2510.08047, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
——, “Do you hear what i mean? quantifying the instruction-perception gap in instruction-guided expressive text-to-speech systems,”arXiv preprint arXiv:2509.13989, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Meta-tts: Meta-learning for few-shot speaker adaptive text-to-speech,
S.-F. Huanget al., “Meta-tts: Meta-learning for few-shot speaker adaptive text-to-speech,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022
2022
-
[7]
Conventional and contemporary approaches used in text to speech synthesis: A review,
N. Kaur and P. Singh, “Conventional and contemporary approaches used in text to speech synthesis: A review,”Artificial Intelligence Review, 2023
2023
-
[8]
Speech emotion recognition using machine learning—a systematic review,
S. Madanianet al., “Speech emotion recognition using machine learning—a systematic review,”Intelligent systems with applications, 2023
2023
-
[9]
arXiv preprint arXiv:2402.13018 , year=
H. Wuet al., “Emo-superb: An in-depth look at speech emotion recognition,”arXiv preprint arXiv:2402.13018, 2024
-
[10]
Automatic speaker verification: A review,
A. Rosenberg, “Automatic speaker verification: A review,”Proceedings of the IEEE, 1976
1976
-
[11]
MFA-Conformer: Multi-scale Feature Aggre- gation Conformer for Automatic Speaker Verification,
Yang Zhang and others, “MFA-Conformer: Multi-scale Feature Aggre- gation Conformer for Automatic Speaker Verification,” inInterspeech 2022, 2022
2022
-
[12]
Recent advances in speech language models: A survey,
W. Cuiet al., “Recent advances in speech language models: A survey,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025
2025
-
[13]
On the landscape of spoken language models: A comprehensive survey,
S. Aroraet al., “On the landscape of spoken language models: A comprehensive survey,”Transactions on Machine Learning Research, 2025
2025
-
[14]
Dynamic-SUPERB phase-2: A collaboratively expanding benchmark for measuring the capabilities of spoken language models with 180 tasks,
C. yu Huanget al., “Dynamic-SUPERB phase-2: A collaboratively expanding benchmark for measuring the capabilities of spoken language models with 180 tasks,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[15]
Towards holistic evaluation of large audio- language models: A comprehensive survey,
C.-K. Yanget al., “Towards holistic evaluation of large audio- language models: A comprehensive survey,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2025, pp. 10 144–10 170
2025
-
[16]
Cantoasr: Prosody-aware asr-lalm collaboration for low-resource cantonese,
D. Chenet al., “Cantoasr: Prosody-aware asr-lalm collaboration for low-resource cantonese,”arXiv preprint arXiv:2511.04139, 2025
-
[17]
Advancing Speech Quality Assessment Through Scientific Challenges and Open-source Activities,
W.-C. Huang, “Advancing Speech Quality Assessment Through Scientific Challenges and Open-source Activities,”arXiv preprint arXiv:2508.00317, 2025
-
[18]
Mmmos: Multi-domain multi-axis audio quality assessment,
Y .-C. Lin, J.-H. Chen, and H.-y. Lee, “Mmmos: Multi-domain multi-axis audio quality assessment,”arXiv preprint arXiv:2507.04094, 2025
-
[19]
Highratemos: Sampling-rate aware modeling for speech quality assessment,
W. Renet al., “Highratemos: Sampling-rate aware modeling for speech quality assessment,”arXiv preprint arXiv:2506.21951, 2025
-
[20]
ASTAR-NTU solution to AudioMOS Challenge 2025 Track1,
F. Ritter-Gutierrezet al., “ASTAR-NTU solution to AudioMOS Challenge 2025 Track1,”arXiv preprint arXiv:2507.09904, 2025
-
[21]
Inclusivity of ai speech in healthcare: A decade look back,
R. Larasati, “Inclusivity of ai speech in healthcare: A decade look back,” arXiv preprint arXiv:2505.10596, 2025
-
[22]
Does automatic speech recognition (asr) have a role in the transcription of indistinct covert recordings for forensic purposes?
D. Loakes, “Does automatic speech recognition (asr) have a role in the transcription of indistinct covert recordings for forensic purposes?” Frontiers in Communication, 2022
2022
-
[23]
Automated speech recognition bias in personnel selection: The case of automatically scored job interviews
L. Hickman, M. Langer, R. M. Saef, and L. Tay, “Automated speech recognition bias in personnel selection: The case of automatically scored job interviews.”Journal of Applied Psychology, 2024
2024
-
[24]
Gender biases in error mitigation by voice assistants,
A. Mahmood and C.-M. Huang, “Gender biases in error mitigation by voice assistants,”Proc. ACM Hum.-Comput. Interact., 2024
2024
-
[25]
Fairness and abstraction in sociotechnical systems,
A. D. Selbst, D. Boyd, S. A. Friedler, S. Venkatasubramanian, and J. Vertesi, “Fairness and abstraction in sociotechnical systems,” in Proceedings of the Conference on Fairness, Accountability, and Trans- parency, 2019
2019
-
[26]
Automated prediction and analysis of job interview performance: The role of what you say and how you say it,
I. Naimet al., “Automated prediction and analysis of job interview performance: The role of what you say and how you say it,” in2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), 2015
2015
-
[27]
Automatic assessment of prosody in high-stakes english tests
J. Cheng, “Automatic assessment of prosody in high-stakes english tests.” inInterspeech, 2011
2011
-
[28]
Sounding out voice biometrics: Comparing and contrasting how the state and the private sector determine identity through voice,
D. L. Palumbo and R. Prey, “Sounding out voice biometrics: Comparing and contrasting how the state and the private sector determine identity through voice,”Big Data & Society, 2024
2024
-
[29]
Fairness of automatic speech recognition: Looking through a philosophical lens,
A. S. G. Choi and H. Choi, “Fairness of automatic speech recognition: Looking through a philosophical lens,” inProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 2025
2025
-
[30]
Toward responsible asr for african american english speakers: A scoping review of bias and equity in speech technology,
J. L. Cunninghamet al., “Toward responsible asr for african american english speakers: A scoping review of bias and equity in speech technology,”Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 2025
2025
-
[31]
Decoding disparities: evaluating automatic speech recognition system performance in transcribing black and white patient verbal communication with nurses in home healthcare,
M. Zolnooriet al., “Decoding disparities: evaluating automatic speech recognition system performance in transcribing black and white patient verbal communication with nurses in home healthcare,”JAMIA open, 2024
2024
-
[32]
Automatic speech recognition and speech variability: A review,
M. Benzeghibaet al., “Automatic speech recognition and speech variability: A review,”Speech Communication, 2007
2007
-
[33]
The voiceprivacy 2022 challenge: Progress and perspectives in voice anonymisation,
M. Panarielloet al., “The voiceprivacy 2022 challenge: Progress and perspectives in voice anonymisation,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024
2022
-
[34]
Probing the information encoded in x-vectors,
D. Rajet al., “Probing the information encoded in x-vectors,” in2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2019. IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. XX, NO. X, MONTH 202X 25
2019
-
[35]
Detect and perturb: Neutral rewriting of biased and sen- sitive text via gradient-based decoding,
Z. Heet al., “Detect and perturb: Neutral rewriting of biased and sen- sitive text via gradient-based decoding,” inFindings of the Association for Computational Linguistics: EMNLP 2021, 2021
2021
-
[36]
Bias in bios: A case study of semantic representation bias in a high-stakes setting,
M. De-Arteagaet al., “Bias in bios: A case study of semantic representation bias in a high-stakes setting,” inProceedings of the Conference on Fairness, Accountability, and Transparency, 2019
2019
-
[37]
Mitigating gender bias in natural language processing: Literature review,
T. Sunet al., “Mitigating gender bias in natural language processing: Literature review,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
2019
-
[38]
S. Dehdashtianet al., “Fairness and bias mitigation in computer vision: A survey,”arXiv preprint arXiv:2408.02464, 2024
-
[39]
Boosting fairness for masked face recognition,
J. Yuet al., “Boosting fairness for masked face recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2021
2021
-
[40]
A survey of recent advances on turn-taking modeling in spoken dialogue systems,
G. Castillo-Lópezet al., “A survey of recent advances on turn-taking modeling in spoken dialogue systems,” inProceedings of the 15th International Workshop on Spoken Dialogue Systems Technology, 2025
2025
-
[41]
DailyDialog: A manually labelled multi-turn dialogue dataset,
Y . Liet al., “DailyDialog: A manually labelled multi-turn dialogue dataset,” inProceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2017
2017
-
[42]
The second dihard diarization challenge: Dataset, task, and baselines,
N. Ryantet al., “The second dihard diarization challenge: Dataset, task, and baselines,” inInterspeech 2019, 2019
2019
-
[43]
A survey on bias and fairness in machine learning,
N. Mehrabiet al., “A survey on bias and fairness in machine learning,” ACM computing surveys (CSUR), 2021
2021
-
[44]
A review on fairness in machine learning,
D. Pessach and E. Shmueli, “A review on fairness in machine learning,” ACM Comput. Surv., 2022
2022
-
[45]
Oneto and S
L. Oneto and S. Chiappa,Fairness in Machine Learning. Springer International Publishing, 2020
2020
-
[46]
What-is and how-to for fairness in machine learning: A survey, reflection, and perspective,
Z. Tanget al., “What-is and how-to for fairness in machine learning: A survey, reflection, and perspective,”ACM Comput. Surv., 2023
2023
-
[47]
Language (technology) is power: A critical survey of “bias
S. L. Blodgettet al., “Language (technology) is power: A critical survey of “bias” in NLP,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020
2020
-
[48]
Bias and fairness in large language models: A survey,
I. O. Gallegoset al., “Bias and fairness in large language models: A survey,”Computational Linguistics, 2024
2024
-
[49]
A survey on bias and fairness in natural language processing,
R. Bansal, “A survey on bias and fairness in natural language processing,” arXiv preprint arXiv:2204.09591, 2022
-
[50]
Accented speech recognition: A survey,
A. Hinsvarket al., “Accented speech recognition: A survey,”arXiv preprint arXiv:2104.10747, 2021
-
[51]
Hey asr system! why aren’t you more inclusive?
M. K. Ngueajio and G. Washington, “Hey asr system! why aren’t you more inclusive?” inHCI International 2022 – Late Breaking Papers: Interacting with eXtended Reality and Artificial Intelligence, 2022
2022
-
[52]
A systematic literature review on bias evaluation and mitigation in automatic speech recognition models for low-resource african languages,
J. Nakatumba-Nabendeet al., “A systematic literature review on bias evaluation and mitigation in automatic speech recognition models for low-resource african languages,”ACM Comput. Surv., 2025
2025
-
[53]
Bias in automatic speech recognition: The case of african american language,
J. L. Martin and K. E. Wright, “Bias in automatic speech recognition: The case of african american language,”Applied Linguistics, 2022
2022
-
[54]
From disparity to fairness: Analyzing challenges and solutions in ai systems for disabled individuals,
S. Chandet al., “From disparity to fairness: Analyzing challenges and solutions in ai systems for disabled individuals,” in2023 IEEE International Conference on Computer Vision and Machine Intelligence (CVMI), 2023
2023
-
[55]
A. Leschanowsky and S. Das, “Examining the interplay between privacy and fairness for speech processing: A review and perspective,”arXiv preprint arXiv:2408.15391, 2024
-
[56]
Re-imagining algorithmic fairness in india and beyond,
N. Sambasivan, E. Arnesen, B. Hutchinson, T. Doshi, and V . Prab- hakaran, “Re-imagining algorithmic fairness in india and beyond,” in Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 2021
2021
-
[57]
Algorithmic injustice: a relational ethics approach,
A. Birhane, “Algorithmic injustice: a relational ethics approach,” Patterns, 2021
2021
-
[58]
Racial disparities in automated speech recognition,
A. Koeneckeet al., “Racial disparities in automated speech recognition,” Proceedings of the National Academy of Sciences, 2020
2020
-
[59]
Language variation and algorithmic bias: understanding algorithmic bias in British English automatic speech recognition,
N. Markl, “Language variation and algorithmic bias: understanding algorithmic bias in British English automatic speech recognition,” in Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, 2022
2022
-
[60]
Learning about physical parameters: the importance of model discrepancy,
J. Brynjarsdóttir and A. O’Hagan, “Learning about physical parameters: the importance of model discrepancy,”Inverse Problems, vol. 30, no. 11, p. 114007, 2014
2014
-
[61]
Neural networks and the bias/variance dilemma,
S. Geman, E. Bienenstock, and R. Doursat, “Neural networks and the bias/variance dilemma,”Neural Computation, 1992
1992
-
[62]
The elements of statistical learning: data mining, inference, and prediction,
T. Hastie, “The elements of statistical learning: data mining, inference, and prediction,” 2009
2009
-
[63]
Bias does not equal bias: A socio-technical typology of bias in data-based algorithmic systems,
P. Lopez, “Bias does not equal bias: A socio-technical typology of bias in data-based algorithmic systems,”Internet Policy Review, vol. 10, no. 4, pp. 1–29, 2021
2021
-
[64]
A broader view on bias in automated decision- making: Reflecting on epistemology and dynamics,
R. Dobbeet al., “A broader view on bias in automated decision- making: Reflecting on epistemology and dynamics,”arXiv preprint arXiv:1807.00553, 2018
-
[65]
Bias in computer systems,
B. Friedman and H. Nissenbaum, “Bias in computer systems,”ACM Trans. Inf. Syst., vol. 14, no. 3, p. 330–347, 1996
1996
-
[66]
Wolfram and N
W. Wolfram and N. Schilling,American English: dialects and variation. John Wiley & Sons, 2015
2015
-
[67]
Lippi-Green,English with an accent: Language, ideology and discrimination in the United States
R. Lippi-Green,English with an accent: Language, ideology and discrimination in the United States. Routledge, 2012
2012
-
[68]
Gender and dialect bias in youtube’s automatic captions,
R. Tatman, “Gender and dialect bias in youtube’s automatic captions,” inProceedings of the first ACL workshop on ethics in natural language processing, 2017
2017
-
[69]
On the Language and Gender Biases in PSTN, V oIP and Neural Audio Codecs,
K. Altwlkanyet al., “On the Language and Gender Biases in PSTN, V oIP and Neural Audio Codecs,” inInterspeech 2025, 2025
2025
-
[70]
Electroglottographic evaluation of age and gender effects during sustained phonation and connected speech,
E. P.-M. Ma and A. L. Love, “Electroglottographic evaluation of age and gender effects during sustained phonation and connected speech,” Journal of voice, vol. 24, no. 2, pp. 146–152, 2010
2010
-
[71]
Consistency of fundamental frequency and perturbation in repeated phonations of sustained vowels, reading, and connected speech,
J. L. Fitch, “Consistency of fundamental frequency and perturbation in repeated phonations of sustained vowels, reading, and connected speech,”Journal of Speech and Hearing Disorders, vol. 55, no. 2, pp. 360–363, 1990
1990
-
[72]
Automatic speech recognition of conversational speech in individuals with disordered speech,
J. Tobinet al., “Automatic speech recognition of conversational speech in individuals with disordered speech,”Journal of Speech, Language, and Hearing Research, vol. 67, no. 11, pp. 4176–4185, 2024
2024
-
[73]
The problem with bias: Allocative versus represen- tational harms in machine learning,
S. Barocaset al., “The problem with bias: Allocative versus represen- tational harms in machine learning,” in9th Annual conference of the special interest group for computing, information and society, vol. 1, 2017
2017
-
[74]
Gender and dialect bias in YouTube’s automatic captions,
R. Tatman, “Gender and dialect bias in YouTube’s automatic captions,” inProceedings of the First ACL Workshop on Ethics in Natural Language Processing, D. Hovy, S. Spruit, M. Mitchell, E. M. Bender, M. Strube, and H. Wallach, Eds. Valencia, Spain: Association for Computational Linguistics, Apr. 2017, pp. 53–59
2017
-
[75]
Jjj-just stutter: Benchmarking whisper’s perfor- mance disparities on different stuttering patterns,
C. Sridhar and S. Wu, “Jjj-just stutter: Benchmarking whisper’s perfor- mance disparities on different stuttering patterns,” inProc. Interspeech 2025, 2025
2025
-
[76]
From user perceptions to technical improvement: Enabling people who stutter to better use speech recognition,
C. Leaet al., “From user perceptions to technical improvement: Enabling people who stutter to better use speech recognition,” inProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, 2023
2023
-
[77]
Analysis and tuning of a voice assistant system for dysfluent speech,
V . Mitraet al., “Analysis and tuning of a voice assistant system for dysfluent speech,” inInterspeech 2021, 2021
2021
-
[78]
Bias and fairness in multimodal machine learning: A case study of automated video interviews,
B. M. Boothet al., “Bias and fairness in multimodal machine learning: A case study of automated video interviews,” inProceedings of the 2021 International Conference on Multimodal Interaction, 2021
2021
-
[79]
The many dimensions of algorithmic fairness in educational applications,
A. Loukina, N. Madnani, and K. Zechner, “The many dimensions of algorithmic fairness in educational applications,” inProceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications, 2019
2019
-
[80]
Does BERT exacerbate gender or L1 biases in automated English speaking assessment?
A. Kwakoet al., “Does BERT exacerbate gender or L1 biases in automated English speaking assessment?” inProceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023), 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.