Recognition: 3 theorem links
· Lean TheoremCvxCluster: Solving Large, Complex, Granular Resource Allocation Problems 100-1000x Faster
Pith reviewed 2026-05-08 19:37 UTC · model grok-4.3
The pith
CvxCluster reformulates cluster resource allocation as a convex problem solved via relaxation for prices followed by greedy placement, achieving 100-2500x speedups over MIP solvers while staying within 3% of optimal on large Azure traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CvxCluster runs 100 to 2,500x faster than a state-of-the-art MIP solver while remaining within 3% of the optimal objective and scales to 100,480 servers under proportional workload growth.
Load-bearing premise
That the per-machine resource prices obtained from the convex relaxation of the placement problem can effectively drive a lightweight greedy procedure to produce near-optimal task placements even when complex constraints such as job anti-affinity, machine types, and GPU servers are present.
Figures


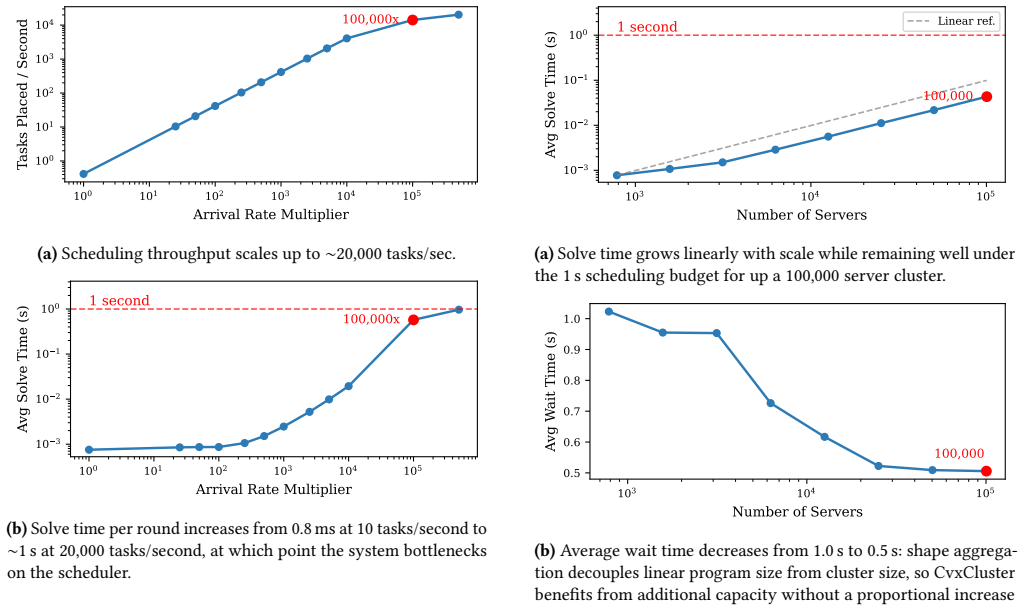
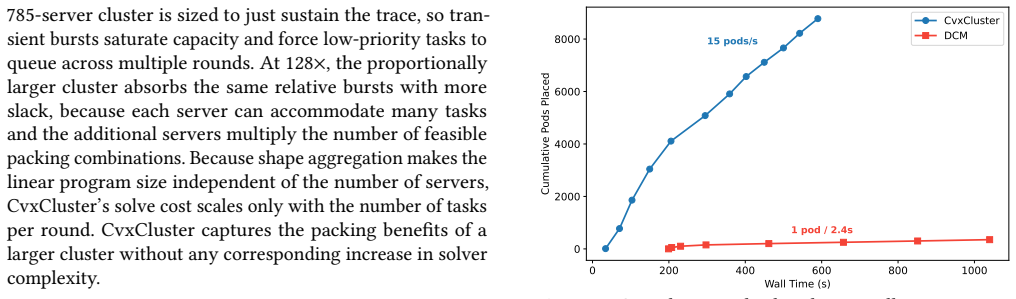
read the original abstract
Cluster resource allocation is a multidimensional search problem that finds the best allocation of tasks to servers. Because the search space grows exponentially, modern approaches frame it as a mixed integer program (MIP) or a complex set of search heuristics. This paper proposes using a different approach: convex optimization, which has extremely fast solution methods. The research challenge is devising how to transform cluster resource allocation into a convex problem that generates good placements. We describe CvxCluster, which allocates cluster resources with a two-stage algorithm. The first stage solves a convex relaxation of the placement problem to yield a principled set of per-machine resource prices. The second stage uses these prices to drive a lightweight greedy procedure to place tasks. Experimental results with Azure traces find that CvxCluster scales to 100,480 servers under proportional workload growth and sustains arrival rates up to 500,000x the baseline trace. CvxCluster runs 100 to 2,500x faster than a state-of-the-art MIP solver while remaining within 3% of the optimal objective. CvxCluster can support complex constraints such as job anti-affinity, machine types, and GPU servers. The key insight behind CvxCluster is that reformulating placement as a continuous rather than discrete problem enables much faster methods that find solutions just as good or better than prior heuristics.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The discrete cluster placement problem admits a useful convex relaxation whose solution yields per-machine resource prices that guide effective greedy allocation.
Reference graph
Works this paper leans on
-
[1]
Akshay Agrawal, Stephen Boyd, Deepak Narayanan, Fiodar Kazhami- aka, and Matei Zaharia. 2022. Allocation of Fungible Resources via a Fast, Scalable Price Discovery Method.Mathematical Programming Computation14 (2022), 593–622. doi:10.1007/s12532-022-00220-6
-
[2]
Bertsekas
Dimitri P. Bertsekas. 1999.Nonlinear Programming(2 ed.). Athena Scientific
1999
-
[3]
Eric Boutin, Jaliya Ekanayake, Wei Lin, Bing Shi, Jingren Zhou, Zheng- ping Qian, Ming Wu, and Lidong Zhou. 2014. Apollo: Scalable and Coordinated Scheduling for Cloud-Scale Computing. In11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14). 285–300.https://www.usenix.org/conference/osdi14/technical- sessions/presentation/boutin
2014
-
[4]
2004.Convex Optimization
Stephen Boyd and Lieven Vandenberghe. 2004.Convex Optimization. Cambridge University Press
2004
-
[5]
Stephen Boyd, Lin Xiao, Almir Mutapcic, and Jacob Mattingley. 2008. Notes on Decomposition Methods. Technical Report. Stanford Univer- sity. Notes for EE364B, Winter 2006–07
2008
-
[6]
Shubham Chaudhary, Ramachandran Ramjee, Muthian Sivathanu, Nipun Kwatra, and Srinidhi Viswanatha. 2020. Balancing Efficiency and Fairness in Heterogeneous GPU Clusters for Deep Learning. In Proceedings of the Fifteenth European Conference on Computer Systems (EuroSys ’20). ACM, Heraklion, Greece, 1:1–1:16
2020
-
[7]
Mung Chiang, Steven H. Low, A. Robert Calderbank, and John C. Doyle. 2007. Layering as Optimization Decomposition: A Mathemati- cal Theory of Network Architectures.Proc. IEEE95, 1 (2007), 255–312. doi:10.1109/JPROC.2006.887322
-
[8]
Hellerstein, Bikash Sharma, and Chita R
Victor Chudnovsky, Rasekh Rifaat, Joseph L. Hellerstein, Bikash Sharma, and Chita R. Das. 2011. Modeling and Synthesizing Task Placement Constraints in Google Compute Clusters. InProceed- ings of the 2nd ACM Symposium on Cloud Computing (SoCC ’11). doi:10.1145/2038916.2038919
-
[9]
Eli Cortez, Anand Bonde, Alexandre Muzio, Mark Russinovich, Mar- cus Fontoura, and Ricardo Bianchini. 2017. Resource Central: Un- derstanding and Predicting Workloads for Improved Resource Man- agement in Large Cloud Platforms. InProceedings of the 26th ACM Symposium on Operating Systems Principles (SOSP ’17). ACM, 153–167. doi:10.1145/3132747.3132772
-
[10]
Christina Delimitrou and Christos Kozyrakis. 2013. Paragon: QoS- Aware Scheduling for Heterogeneous Datacenters. InProceedings of the 18th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’13). 77–88. doi:10.1145/ 2451116.2451125
-
[11]
Garey and David S
Michael R. Garey and David S. Johnson. 1979.Computers and In- tractability: A Guide to the Theory of NP-Completeness. W. H. Freeman and Company, New York
1979
-
[12]
Ali Ghodsi, Matei Zaharia, Benjamin Hindman, Andy Konwinski, Scott Shenker, and Ion Stoica. 2011. Dominant Resource Fairness: Fair Allocation of Multiple Resource Types. In8th USENIX Sym- posium on Networked Systems Design and Implementation (NSDI 11).https://www.usenix.org/conference/nsdi11/dominant-resource- fairness-fair-allocation-multiple-resource-types
2011
-
[13]
Ali Ghodsi, Matei Zaharia, Scott Shenker, and Ion Stoica. 2013. Choosy: Max-Min Fair Sharing for Datacenter Jobs with Constraints. InPro- ceedings of the 8th ACM European Conference on Computer Systems (EuroSys ’13). doi:10.1145/2465351.2465387
-
[14]
Ionel Gog, Malte Schwarzkopf, Adam Gleave, Robert N. M. Watson, and Steven Hand. 2016. Firmament: Fast, Centralized Cluster Schedul- ing at Scale. In12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16).https://www.usenix.org/conference/ osdi16/technical-sessions/presentation/gog
2016
-
[15]
Ralph E. Gomory. 1958. An Algorithm for Integer Solutions to Linear Programs.Princeton IBM Mathematics Research Report(1958)
1958
-
[16]
Robert Grandl, Ganesh Ananthanarayanan, Srikanth Kandula, Sriram Rao, and Aditya Akella. 2014. Multi-Resource Packing for Cluster Schedulers. InProceedings of the ACM SIGCOMM 2014 Conference. doi:10.1145/2619239.2626334
-
[17]
Robert Grandl, Srikanth Kandula, Sriram Rao, Aditya Akella, and Janardhan Kulkarni. 2016. GRAPHENE: Packing and Dependency- Aware Scheduling for Data-Parallel Clusters. In12th USENIX Sym- posium on Operating Systems Design and Implementation (OSDI 16).https://www.usenix.org/conference/osdi16/technical-sessions/ presentation/grandl_graphene
2016
-
[18]
Shin, Yibo Zhu, Myeong- jae Jeon, Junjie Qian, Hongqiang Harry Liu, and Chuanxiong Guo
Juncheng Gu, Mosharaf Chowdhury, Kang G. Shin, Yibo Zhu, Myeong- jae Jeon, Junjie Qian, Hongqiang Harry Liu, and Chuanxiong Guo
-
[19]
In16th USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 19)
Tiresias: A GPU Cluster Manager for Distributed Deep Learning. In16th USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 19). USENIX Association, Boston, MA, 485–500. 12
-
[20]
Michael Isard, Vijayan Prabhakaran, Jon Currey, Udi Wieder, Kunal Talwar, and Andrew Goldberg. 2009. Quincy: Fair Scheduling for Distributed Computing Clusters. InProceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles (SOSP ’09). doi:10. 1145/1629575.1629601
-
[21]
Myeongjae Jeon, Shivaram Venkataraman, Amar Phanishayee, Junjie Qian, Wencong Xiao, and Fan Yang. 2019. Analysis of Large-Scale Multi-Tenant GPU Clusters for DNN Training Workloads. In2019 USENIX Annual Technical Conference (USENIX ATC 19). USENIX Asso- ciation, 947–960
2019
-
[22]
Narayanamurthy, Alexey Tumanov, Jonathan Yaniv, Ruslan Mavlyu- tov, Íñigo Goiri, Subru Krishnan, Janardhan Kulkarni, and Sriram Rao
Sangeetha Abdu Jyothi, Carlo Curino, Ishai Menache, Shravan M. Narayanamurthy, Alexey Tumanov, Jonathan Yaniv, Ruslan Mavlyu- tov, Íñigo Goiri, Subru Krishnan, Janardhan Kulkarni, and Sriram Rao
-
[23]
In 12th USENIX Symposium on Operating Systems Design and Implemen- tation (OSDI 16)
Morpheus: Towards Automated SLOs for Enterprise Clusters. In 12th USENIX Symposium on Operating Systems Design and Implemen- tation (OSDI 16). USENIX Association, 117–134.https://www.usenix. org/conference/osdi16/technical-sessions/presentation/jyothi
-
[24]
2004.Knapsack Problems
Hans Kellerer, Ulrich Pferschy, and David Pisinger. 2004.Knapsack Problems. Springer, Berlin, Heidelberg
2004
-
[25]
Kelly, Aman K
Frank P. Kelly, Aman K. Maulloo, and David K. H. Tan. 1998. Rate Control for Communication Networks: Shadow Prices, Proportional Fairness and Stability.Journal of the Operational Research Society49, 3 (1998), 237–252
1998
-
[26]
Neeraj Kumar, Pol Mauri Ruiz, Vijay Menon, Igor Kabiljo, Mayank Pundir, Andrew Newell, Daniel Lee, Liyuan Wang, and Chunqiang Tang. 2024. Optimizing Resource Allocation in Hyperscale Datacen- ters: Scalability, Usability, and Experiences. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 507–528. https://www.usenix.org/conf...
2024
-
[27]
An Automatic Method of Solving Discrete Programming Problems,
Ailsa H. Land and Alison G. Doig. 1960. An Automatic Method of Solving Discrete Programming Problems.Econometrica28, 3 (1960), 497–520. doi:10.2307/1910129
-
[28]
E. L. Lawler and D. E. Wood. 1966. Branch-and-Bound Methods: A Survey.Operations Research14, 4 (1966), 699–719
1966
-
[29]
Le, Xiao Sun, Mosharaf Chowdhury, and Zhenhua Liu
Tan N. Le, Xiao Sun, Mosharaf Chowdhury, and Zhenhua Liu. 2019. Allox: Compute Allocation in Hybrid Clusters. InProceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP ’19). ACM, 416–429
2019
-
[30]
Philip Levis, Kun Lin, and Amy Tai. 2023. A Case Against CXL Memory Pooling. InThe 22nd ACM Workshop on Hot Topics in Networks (HotNets ’23). ACM, Cambridge, MA, USA, 48–55. doi:10.1145/3626111.3628195
-
[31]
Jiamin Li, Hong Xu, Yibo Zhu, Zherui Liu, Chuanxiong Guo, and Cong Wang. 2023. Lyra: Elastic Scheduling for Deep Learning Clusters. InProceedings of the Eighteenth European Conference on Computer Systems (EuroSys ’23). doi:10.1145/3552326.3587445
-
[32]
Kshiteej Mahajan, Arjun Balasubramanian, Arjun Singhvi, Shivaram Venkataraman, Aditya Akella, Amar Phanishayee, and Shuchi Chawla
-
[33]
In17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20).https://www.usenix.org/conference/nsdi20/presentation/ mahajan
Themis: Fair and Efficient GPU Cluster Scheduling. In17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20).https://www.usenix.org/conference/nsdi20/presentation/ mahajan
-
[34]
Morrison, Sheldon H
David R. Morrison, Sheldon H. Jacobson, Jason J. Sauppe, and Ed- ward C. Sewell. 2016. Branch-and-bound algorithms: A survey of recent advances in searching, branching, and pruning.Discrete Opti- mization19 (2016), 79–102
2016
-
[35]
Deepak Narayanan, Fiodar Kazhamiaka, Firas Abuzaid, Peter Kraft, Akshay Agrawal, Srikanth Kandula, Stephen Boyd, and Matei Za- haria. 2021. Solving Large-Scale Granular Resource Allocation Problems Efficiently with POP. InProceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles (SOSP ’21). 521–537. doi:10.1145/3477132.3483588
-
[36]
Deepak Narayanan, Keshav Santhanam, Fiodar Kazhamiaka, Amar Phanishayee, and Matei Zaharia. 2020. Heterogeneity-Aware Cluster Scheduling Policies for Deep Learning Workloads. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). USENIX Association, 481–498
2020
-
[37]
Nemhauser and Laurence A
George L. Nemhauser and Laurence A. Wolsey. 1988.Integer and Combinatorial Optimization. Wiley
1988
-
[38]
Kay Ousterhout, Patrick Wendell, Matei Zaharia, and Ion Stoica. 2013. Sparrow: Distributed, Low Latency Scheduling. InProceedings of the 24th ACM Symposium on Operating Systems Principles (SOSP ’13). doi:10.1145/2517349.2522716
-
[39]
Daniel P. Palomar and Mung Chiang. 2006. A Tutorial on Decom- position Methods for Network Utility Maximization.IEEE Jour- nal on Selected Areas in Communications24, 8 (2006), 1439–1451. doi:10.1109/JSAC.2006.879350
-
[40]
Yanghua Peng, Yixin Bao, Yangrui Chen, Chuan Wu, and Chuanx- iong Guo. 2018. Optimus: An Efficient Dynamic Resource Scheduler for Deep Learning Clusters. InProceedings of the Thirteenth EuroSys Conference (EuroSys ’18). ACM, Porto, Portugal, 3:1–3:14
2018
-
[41]
Laurent Perron and Frédéric Didier. 2023. CP-SAT.https://developers. google.com/optimization/cp/cp_solver/
2023
-
[42]
Anders Rantzer. 2009. Dynamic Dual Decomposition for Distributed Control. InProceedings of the American Control Conference (ACC). 884–888
2009
-
[43]
R. Tyrrell Rockafellar. 1993. Lagrange Multipliers and Optimality. SIAM Rev.35, 2 (1993), 183–238. doi:10.1137/1035041
-
[44]
Lalith Suresh, João Loff, Faria Kalim, Sangeetha Abdu Jyothi, Nina Narodytska, Leonid Ryzhyk, Sahan Gamage, Brian Oki, Pranshu Jain, and Michael Gasch. 2020. Building Scalable and Flexible Cluster Man- agers Using Declarative Programming. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). 827–844. https://www.usenix.org/conf...
2020
-
[45]
Douglas Thain, Todd Tannenbaum, and Miron Livny. 2005. Distributed Computing in Practice: The Condor Experience.Concurrency and Computation: Practice and Experience17, 2–4 (2005), 323–356. doi:10. 1002/cpe.938
2005
-
[46]
The Kubernetes Authors. 2014. Kubernetes: Production-Grade Con- tainer Orchestration.https://kubernetes.ioOpen-source container orchestration system
2014
-
[47]
Korupolu, David Oppen- heimer, Eric Tune, and John Wilkes
Abhishek Verma, Luis Pedrosa, Madhukar R. Korupolu, David Oppen- heimer, Eric Tune, and John Wilkes. 2015. Large-Scale Cluster Manage- ment at Google with Borg. InProceedings of the Tenth European Confer- ence on Computer Systems (EuroSys ’15). doi:10.1145/2741948.2741964
-
[48]
Lin Xiao, Mikael Johansson, and Stephen Boyd. 2004. Simultane- ous Routing and Resource Allocation via Dual Decomposition.IEEE Transactions on Communications52, 7 (2004), 1136–1144
2004
-
[49]
Wencong Xiao, Romil Bhardwaj, Ramachandran Ramjee, Muthian Sivathanu, Nipun Kwatra, Zhenhua Han, Pratyush Patel, Xuan Peng, Hanyu Zhao, Quanlu Zhang, Fan Yang, and Lidong Zhou. 2018. Gan- diva: Introspective Cluster Scheduling for Deep Learning. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18). USENIX Association, Carlsbad,...
2018
-
[50]
Matei Zaharia, Dhruba Borthakur, Joydeep Sen Sarma, Khaled Elmele- egy, Scott Shenker, and Ion Stoica. 2010. Delay Scheduling: A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling. InProceedings of the 5th European Conference on Computer Systems (EuroSys ’10). doi:10.1145/1755913.1755940
-
[51]
Pengfei Zheng, Rui Pan, Tarannum Khan, Shivaram Venkataraman, and Aditya Akella. 2023. Shockwave: Fair and Efficient Cluster Scheduling for Dynamic Adaptation in Machine Learning. In20th USENIX Symposium on Networked Systems Design and Implementa- tion (NSDI 23). 703–723.https://www.usenix.org/conference/nsdi23/ presentation/zheng 13
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.