Recognition: unknown
Prosa: Rubric-Based Evaluation of LLMs on Real User Chats in Brazilian Portuguese
Pith reviewed 2026-05-09 13:59 UTC · model grok-4.3
The pith
Binary rubric scoring with multi-judge filtering produces consistent LLM rankings independent of the judge model chosen.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
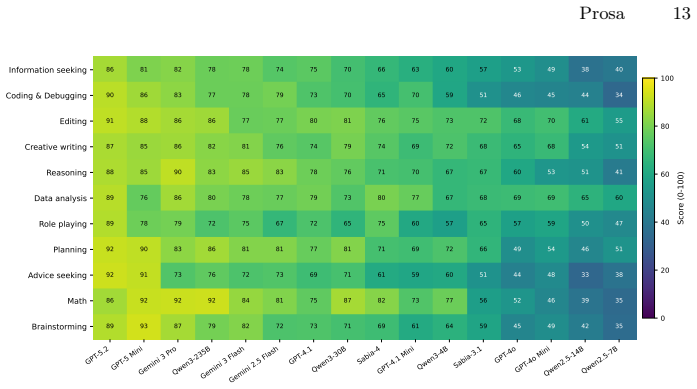
Rankings produced by holistic LLM-as-a-judge scoring are sensitive to the bias of the chosen judge model. Switching to binary rubric scoring with multi-judge filtering removes this sensitivity: decomposing the judgement matters more than the judge model itself. On the Prosa benchmark of 1,000 WildChat conversations scored by three judges from three model families across 16 models, filtered rubric scoring produces full agreement on every rank while holistic scoring agrees on only 7 ranks and the filtering step increases the average gap between adjacent models by 47 percent.
What carries the argument
Binary rubric scoring combined with multi-judge filtering, which breaks each judgment into specific yes-no criteria and retains only scores where the judges align.
If this is right
- LLM rankings remain the same regardless of which judge model performs the evaluation.
- Score gaps between successive models grow by 47 percent on average, sharpening distinctions among close performers.
- New models can be added to the benchmark at a fixed low cost using the released filtering code.
- The same rubric-plus-filter approach can be reused for other open-ended generation tasks beyond Brazilian Portuguese.
Where Pith is reading between the lines
- The approach could be ported to chat benchmarks in additional languages to test whether judge independence generalizes.
- Standardized rubrics might eventually replace ad-hoc holistic prompts in public leaderboards.
- Testing the rubrics on newer model families would reveal whether the agreement holds as judge capabilities advance.
- The method might surface subtle quality differences that holistic scoring currently masks.
Load-bearing premise
The chosen binary rubrics measure the quality dimensions that matter in real chats without being influenced by which judge model applies them, and the 1,000 conversations represent typical Brazilian Portuguese user interactions.
What would settle it
A new judge model producing a different ordering of the 16 models under the same filtered rubric pipeline would show the method has not eliminated judge sensitivity.
Figures




read the original abstract
Rankings produced by holistic LLM-as-a-judge scoring are sensitive to the bias of the chosen judge model. We show that switching to binary rubric scoring with multi-judge filtering removes this sensitivity: decomposing the judgement matters more than the judge model itself. To support this claim, we introduce Prosa, the first real user multi-turn Brazilian Portuguese chat benchmark: 1,000 WildChat conversations scored by three judges from three model families on 16 models. Under filtered rubric scoring the three judges agree on every one of the 16 ranks, whereas under holistic scoring they agree on only 7 of 16. Additionally, the rubric filtering pipeline increases the average score gap between neighbouring models by 47%, thereby improving Prosa's discriminative power. Evaluating a new model on Prosa costs approximately $2.1 when using Gemini 3 Flash as the judge. We release the benchmark and the filtering code to ensure that future models can be assessed under identical conditions. These artifacts also make our rubric-based scoring method reusable beyond Prosa, supporting other open-ended evaluation settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Prosa, a benchmark of 1,000 real-user multi-turn Brazilian Portuguese conversations sourced from WildChat. It compares holistic LLM-as-a-judge scoring against binary rubric scoring with a multi-judge filtering pipeline across three judges and 16 evaluated models. The key results are that filtered rubric scoring yields perfect agreement (16/16) on model rankings among the three judges, versus only 7/16 for holistic scoring, and that the filtering increases the average neighboring-model score gap by 47%. The benchmark and filtering code are released.
Significance. If the central claim holds after clarifying the role of filtering, the work would be significant for the field of LLM evaluation. It offers a practical approach to reduce judge-model bias in open-ended chat assessment, particularly valuable for Brazilian Portuguese where such benchmarks are scarce. The release of the dataset, rubrics, and code supports reproducibility and reuse in other settings, which is a clear strength.
major comments (2)
- [§4 and §3.3] §4 (Results) and §3.3 (Filtering pipeline): The reported perfect rank agreement (16/16) under filtered rubric scoring is presented without the corresponding inter-judge rank agreement figures for the unfiltered rubric scores on the full set of 1,000 conversations. This omission makes it impossible to isolate whether the improvement stems from rubric decomposition or from the filter retaining only low-disagreement conversations, which is load-bearing for the abstract claim that 'decomposing the judgement matters more than the judge model itself'.
- [§5] §5 (Gap analysis) and associated table: The 47% increase in average score gap between neighbouring models is reported for the rubric filtering pipeline, but it is unclear whether the comparison uses the same filtered conversation subset for both rubric and holistic methods or whether the number of retained conversations (and any statistical test for the gap change) is provided. This detail is needed to assess the scope and robustness of the discriminability claim.
minor comments (2)
- [§3.2] The exact binary rubric definitions for each quality dimension (e.g., the specific criteria and binary thresholds) are referenced but not fully enumerated in the main text; moving the complete rubric table to the appendix or a dedicated figure would improve clarity and reusability.
- [§3.3] The paper should explicitly state the number of conversations retained after each stage of the multi-judge filtering pipeline to allow readers to evaluate selection effects.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help strengthen the clarity of our claims regarding the contributions of rubric decomposition versus filtering. We address each major comment below and will revise the manuscript accordingly to improve transparency and reproducibility.
read point-by-point responses
-
Referee: [§4 and §3.3] §4 (Results) and §3.3 (Filtering pipeline): The reported perfect rank agreement (16/16) under filtered rubric scoring is presented without the corresponding inter-judge rank agreement figures for the unfiltered rubric scores on the full set of 1,000 conversations. This omission makes it impossible to isolate whether the improvement stems from rubric decomposition or from the filter retaining only low-disagreement conversations, which is load-bearing for the abstract claim that 'decomposing the judgement matters more than the judge model itself'.
Authors: We agree that reporting the unfiltered rubric inter-judge rank agreement is essential for isolating the effect of rubric decomposition from the filtering step. In the revised manuscript, we will add these results to Section 4, including the rank agreement figures for unfiltered rubric scores across the three judges on the full set of 1,000 conversations. This addition will allow direct comparison with both the filtered rubric results and the holistic baseline, thereby supporting a clearer evaluation of the claim. revision: yes
-
Referee: [§5] §5 (Gap analysis) and associated table: The 47% increase in average score gap between neighbouring models is reported for the rubric filtering pipeline, but it is unclear whether the comparison uses the same filtered conversation subset for both rubric and holistic methods or whether the number of retained conversations (and any statistical test for the gap change) is provided. This detail is needed to assess the scope and robustness of the discriminability claim.
Authors: We appreciate this observation on the need for precise methodological details. The 47% increase compares the average neighboring-model score gap under the full rubric filtering pipeline (applied to the retained conversations) against the gap under holistic scoring on the complete set of 1,000 conversations, as the filtering is an integral component of the proposed rubric-based method rather than an optional post-processing step. In the revision, we will explicitly state the number of conversations retained after filtering, add a statistical test (such as a paired t-test on the per-model-pair gaps) to assess the significance of the increase, and include a note clarifying the subsets used for each scoring approach. If space permits, we will also report the holistic gap on the filtered subset as a supplementary comparison. revision: yes
Circularity Check
No significant circularity in empirical benchmark evaluation
full rationale
The paper reports direct empirical measurements of inter-judge rank agreement and score gaps on a fixed set of 1,000 conversations under two scoring regimes (holistic vs. filtered rubric). These quantities are computed from the observed judge outputs rather than derived from any self-referential equations, fitted parameters that are then renamed as predictions, or load-bearing self-citations whose validity depends on the present work. The filtering pipeline is presented as an explicit methodological step whose effects are measured on the data; no derivation chain reduces the headline agreement numbers (16/16 vs. 7/16) or the 47% gap improvement to a tautology by construction. This is a standard empirical evaluation paper whose central claims rest on side-by-side comparison rather than mathematical reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Binary rubric scoring decomposes judgment into aspects that are less sensitive to judge-model bias than holistic scoring.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2403.09887 (2024), https: //arxiv.org/abs/2403.09887
Almeida, T.S., Abonizio, H., Nogueira, R., Pires, R.: Sabiá-2: a new generation of Portuguese large language models. arXiv preprint arXiv:2403.09887 (2024), https: //arxiv.org/abs/2403.09887
-
[2]
In: Naldi, M.C., Bianchi, R.A.C
Almeida, T.S., Laitz, T., Bonás, G.K., Nogueira, R.: BLUEX: a benchmark based on Brazilian leading universities entrance exams. In: Naldi, M.C., Bianchi, R.A.C. (eds.) Intelligent Systems. pp. 337–347. Springer Nature Switzerland (2023). https: //doi.org/10.1007/978-3-031-45368-7_22
-
[3]
arXiv preprint arXiv:2511.17808 (2025), https://arxiv.org/abs/2511.17808
Almeida,T.S.,Pires,R.,Abonizio,H.,Nogueira,R.,Pedrini,H.:PoETav2:Toward more robust evaluation of large language models in Portuguese. arXiv preprint arXiv:2511.17808 (2025), https://arxiv.org/abs/2511.17808
-
[4]
In: 2018 7th Brazilian Conference on Intelligent Systems (BRACIS)
Cataneo Silveira, I., Deratani Mauá, D.: Advances in automatically solving the ENEM. In: 2018 7th Brazilian Conference on Intelligent Systems (BRACIS). pp. 43–48 (2018). https://doi.org/10.1109/BRACIS.2018.00016
-
[5]
arXiv preprint arXiv:2603.03543 (2026), https://arxiv.org/abs/2603.03543
Corrêa, N.K., et al.: Tucano 2 Cool: Better open source LLMs for Portuguese. arXiv preprint arXiv:2603.03543 (2026), https://arxiv.org/abs/2603.03543
-
[6]
In: First Conference on Language Modeling (COLM) (2024), https: //openreview.net/forum?id=CybBmzWBX0
Dubois, Y., et al.: Length-controlled AlpacaEval: a simple way to debias automatic evaluators. In: First Conference on Language Modeling (COLM) (2024), https: //openreview.net/forum?id=CybBmzWBX0
2024
-
[7]
Kim, S., et al.: The BiGGen Bench: a principled benchmark for fine-grained evalua- tion of language models with language models. In: Proceedings of the 2025 Confer- ence of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Long Papers). pp. 5877–5919 (2025). https://doi.org/10.18653/v1/2025....
-
[8]
In: Proceedings of the 42nd International Conference on Machine Learning (ICML)
Li, T., et al.: From crowdsourced data to high-quality benchmarks: Arena-Hard and BenchBuilder pipeline. In: Proceedings of the 42nd International Conference on Machine Learning (ICML). Proceedings of Machine Learning Research, vol. 267, pp. 34209–34231 (2025), https://proceedings.mlr.press/v267/li25h.html Prosa 15
2025
-
[9]
In: The Thirteenth International Conference on Learning Representations (2025), https://openreview.net/forum?id=MKEHCx25xp
Lin, B.Y., et al.: Wildbench: Benchmarking LLMs with challenging tasks from real users in the wild. In: The Thirteenth International Conference on Learning Representations (2025), https://openreview.net/forum?id=MKEHCx25xp
2025
-
[10]
Liu, C.W., Lowe, R., Serban, I.V., Noseworthy, M., Charlin, L., Pineau, J.: How NOT To evaluate your dialogue system: An empirical study of unsupervised evalu- ation metrics for dialogue response generation. In: Proceedings of the 2016 Confer- ence on Empirical Methods in Natural Language Processing (EMNLP). pp. 2122– 2132 (2016). https://doi.org/10.18653...
-
[11]
Ma, Q., Wei, J.T.Z., Bojar, O., Graham, Y.: Results of the WMT19 metrics shared task: Segment-level and strong MT systems pose big challenges. In: Proceedings of the Fourth Conference on Machine Translation (WMT), Volume 2: Shared Task Papers, Day 1. pp. 62–90 (2019). https://doi.org/10.18653/v1/W19-5302
-
[12]
arXiv preprint arXiv:2303.17003 (2023), https://arxiv.org/abs/2303.17003
Nunes, D., Primi, R., Pires, R., Lotufo, R., Nogueira, R.: Evaluating GPT- 3.5 and GPT-4 models on Brazilian university admission exams. arXiv preprint arXiv:2303.17003 (2023), https://arxiv.org/abs/2303.17003
-
[13]
arXiv preprint arXiv:2504.21202 (2025), https://arxiv.org/abs/2504.21202
Pires, R., Malaquias Junior, R., Nogueira, R.: Automatic legal writing evaluation of LLMs. arXiv preprint arXiv:2504.21202 (2025), https://arxiv.org/abs/2504.21202
-
[14]
In: Findings of the Association for Computational Linguistics: ACL
Qin, Y., et al.: InFoBench: Evaluating instruction following ability in large lan- guage models. In: Findings of the Association for Computational Linguistics: ACL
-
[15]
pp. 13025–13048 (2024). https://doi.org/10.18653/v1/2024.findings-acl.772
-
[16]
Computational Linguistics , volume =
Reiter, E.: A structured review of the validity of BLEU. Computational Linguistics 44(3), 393–401 (2018). https://doi.org/10.1162/COLI_a_00322
-
[17]
Metacognitive Prompting Improves Understanding in Large Language Models
Sellam, T., Das, D., Parikh, A.P.: BLEURT: Learning robust metrics for text gen- eration. In: Proceedings of the 58th Annual Meeting of the Association for Com- putational Linguistics (ACL). pp. 7881–7892 (2020). https://doi.org/10.18653/v1/ 2020.acl-main.704
-
[18]
Shen, W.F., et al.: Rethinking rubric generation for improving LLM judge and reward modeling for open-ended tasks. arXiv preprint arXiv:2602.05125 (2026), https://arxiv.org/abs/2602.05125
-
[19]
Primack, Summer Yue, and Chen Xing
Sirdeshmukh, V., et al.: Multichallenge: a realistic multi-turn conversation eval- uation benchmark challenging to frontier LLMs. In: Findings of the Associa- tion for Computational Linguistics: ACL 2025. pp. 18632–18702 (2025). https: //doi.org/10.18653/v1/2025.findings-acl.958
-
[20]
In: The Thirteenth International Conference on Learning Rep- resentations (2025), https://openreview.net/forum?id=Pnk7vMbznK
Xu, Z., et al.: Magpie: Alignment data synthesis from scratch by prompting aligned LLMs with nothing. In: The Thirteenth International Conference on Learning Rep- resentations (2025), https://openreview.net/forum?id=Pnk7vMbznK
2025
-
[21]
In: The Twelfth International Conference on Learning Representations (ICLR) (2024), https://openreview.net/forum?id=CYmF38ysDa
Ye, S., et al.: FLASK: Fine-grained language model evaluation based on alignment skill sets. In: The Twelfth International Conference on Learning Representations (ICLR) (2024), https://openreview.net/forum?id=CYmF38ysDa
2024
-
[22]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Zhang, Y., et al.: Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176 (2025), https://arxiv. org/abs/2506.05176
work page internal anchor Pith review arXiv 2025
-
[23]
In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum?id=Bl8u7ZRlbM
Zhao, W., Ren, X., Hessel, J., Cardie, C., Choi, Y., Deng, Y.: Wildchat: 1m chat- GPT interaction logs in the wild. In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum?id=Bl8u7ZRlbM
2024
-
[24]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Zheng, L., et al.: Judging llm-as-a-judge with mt-bench and chatbot arena. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Information Processing Systems. vol. 36, pp. 46595 – 46623. Curran As- sociates, Inc. (2023), https://proceedings.neurips.cc/paper_files/paper/2023/file/ 91f18a1287b398d378ef22505bf4...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.