Recognition: unknown
Omni-Fake: Benchmarking Unified Multimodal Social Media Deepfake Detection
Pith reviewed 2026-05-09 14:00 UTC · model grok-4.3
The pith
The Omni-Fake dataset and Omni-Fake-R1 detector together enable more accurate, generalizable, and explainable detection of multimodal deepfakes on social media.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a unified omni-dataset spanning four modalities with realistic social-media distributions and an explicit out-of-distribution split, combined with a reinforcement-learning-driven detector that adaptively integrates cues and outputs structured explanations, produces significant gains in detection accuracy, cross-modal generalization, and explainability over prior single-modality or non-adaptive baselines.
What carries the argument
The Omni-Fake dataset that unifies image, audio, video, and talking-head modalities under a joint detection-localization-explanation protocol, together with the Omni-Fake-R1 reinforcement-learning detector that adaptively combines visual and auditory cues.
If this is right
- Improved handling of deepfakes that combine multiple modalities in realistic social-media distributions.
- Joint capability to detect fakes, localize manipulated regions, and generate natural-language explanations.
- Stronger cross-modal generalization when evaluated on the dedicated out-of-distribution split.
- A foundation for more robust digital-forensics pipelines that operate across image, audio, and video.
Where Pith is reading between the lines
- Social platforms could incorporate similar adaptive detectors to flag suspicious multimodal posts at scale.
- The dataset-construction and reinforcement-learning fusion methods could extend to related tasks such as combined text-and-media misinformation detection.
- Future work might add further modalities like text overlays or 3D content while preserving the out-of-distribution testing protocol.
Load-bearing premise
The constructed Omni-Fake dataset and its out-of-distribution split accurately capture the distribution and manipulation diversity of real-world social media deepfakes.
What would settle it
A test set of deepfakes collected directly from current social media platforms, never seen during dataset construction or training, that shows no improvement in accuracy, localization quality, or explanation usefulness compared with existing detectors.
Figures















read the original abstract
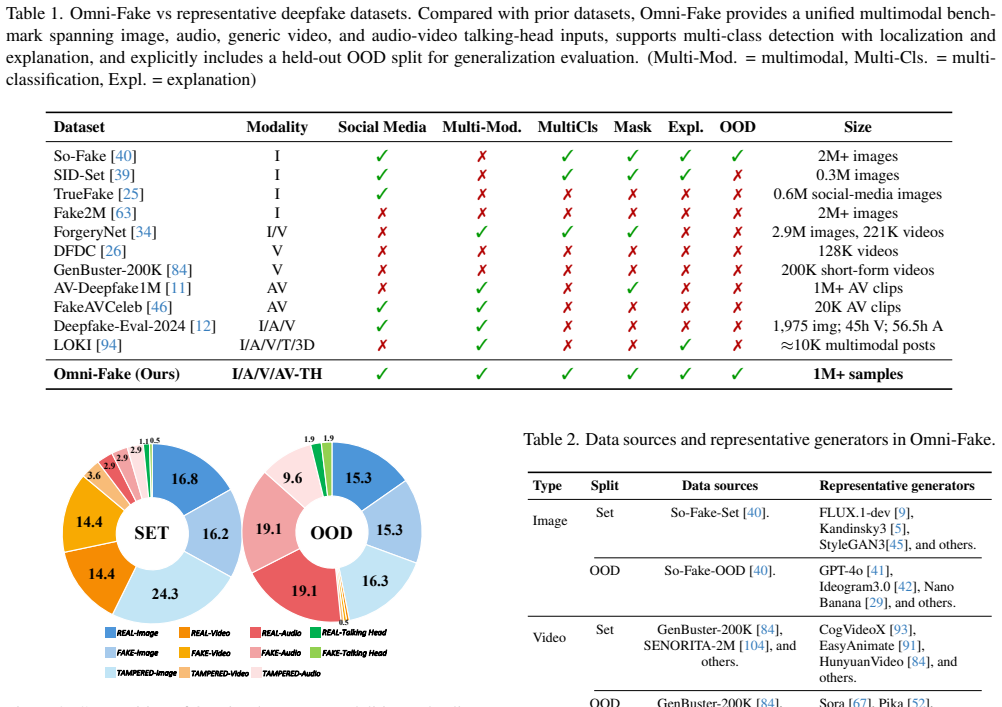
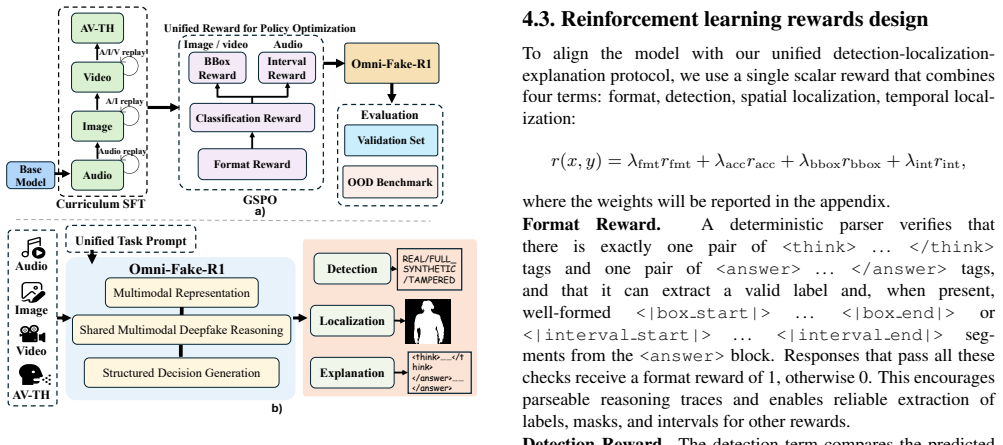
Multimodal deepfakes are proliferating on social media and threaten authenticity, information integrity, and digital forensics. Existing benchmarks are constrained by their single-modality scope, simplified manipulations, or unrealistic distributions, which limit their ability to assess real-world robustness. To address these limitations, we present Omni-Fake, a unified omni-dataset for comprehensive multimodal deepfake detection in social-media settings. It comprises Omni-Fake-Set, a large-scale, high-quality dataset with 1M+ samples, and Omni-Fake-OOD, an out-of-distribution benchmark with 200k+ samples intentionally excluded from training to evaluate generalization. Omni-Fake spans four modalities (image, audio, video, and audio-video talking head) and supports a joint detection-localization-explanation protocol. On top of Omni-Fake, we further propose Omni-Fake-R1, a reinforcement-learning-driven multimodal detector that adaptively integrates visual and auditory cues and outputs structured decisions, localization, and natural-language explanations. Extensive experiments show significant gains in detection accuracy, cross-modal generalization, and explainability over state-of-the-art baselines. Project page: https://tianxiao1201.github.io/omni-fake-project-page/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Omni-Fake, a unified multimodal dataset for social media deepfake detection comprising Omni-Fake-Set (1M+ samples across image, audio, video, and audio-video talking-head modalities) and Omni-Fake-OOD (200k+ intentionally excluded samples for generalization testing). It proposes Omni-Fake-R1, a reinforcement-learning-driven detector that adaptively integrates visual and auditory cues to produce structured detection, localization, and natural-language explanation outputs, claiming significant gains in detection accuracy, cross-modal generalization, and explainability over state-of-the-art baselines.
Significance. If the empirical claims hold with rigorous validation, the work would provide a valuable large-scale benchmark addressing gaps in existing single-modality or simplified deepfake datasets, particularly for social-media realism and multi-task evaluation (detection + localization + explanation). The RL-based adaptive cue integration is a potentially useful direction for robustness and interpretability. The dataset scale and joint protocol constitute clear strengths for the field.
major comments (2)
- [Abstract] Abstract: The central claim of 'significant gains in detection accuracy, cross-modal generalization, and explainability' is stated without any quantitative metrics, specific baseline comparisons, ablation results, error bars, or statistical tests. This absence prevents evaluation of whether the reported improvements are substantive or merely incremental.
- [Abstract / Dataset section] Dataset construction (Abstract and likely §3): Omni-Fake-OOD is defined only as '200k+ samples intentionally excluded from training.' It is not specified whether these samples introduce genuine distribution shifts (e.g., unseen generators, recording conditions, platforms, or manipulation families absent from training) or constitute a standard in-distribution held-out split. If the latter, the cross-modal generalization claims rest on improved in-distribution robustness rather than OOD performance, weakening the primary contribution.
minor comments (1)
- The abstract references a project page but provides no details on data availability, licensing, or reproducibility artifacts (e.g., code, exact train/OOD splits). These should be clarified in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'significant gains in detection accuracy, cross-modal generalization, and explainability' is stated without any quantitative metrics, specific baseline comparisons, ablation results, error bars, or statistical tests. This absence prevents evaluation of whether the reported improvements are substantive or merely incremental.
Authors: We agree that the abstract would be strengthened by including representative quantitative results to allow readers to immediately gauge the scale of the reported improvements. While the full experimental details, including accuracy metrics, baseline comparisons, ablations, and statistical significance, appear in Sections 4 and 5, we will revise the abstract to incorporate key highlights such as the observed gains in detection accuracy and cross-modal generalization performance. revision: yes
-
Referee: [Abstract / Dataset section] Dataset construction (Abstract and likely §3): Omni-Fake-OOD is defined only as '200k+ samples intentionally excluded from training.' It is not specified whether these samples introduce genuine distribution shifts (e.g., unseen generators, recording conditions, platforms, or manipulation families absent from training) or constitute a standard in-distribution held-out split. If the latter, the cross-modal generalization claims rest on improved in-distribution robustness rather than OOD performance, weakening the primary contribution.
Authors: We thank the referee for identifying this potential ambiguity in the current wording. Omni-Fake-OOD was constructed to include genuine distribution shifts (unseen generators, recording conditions, and manipulation families), as described in Section 3. To remove any doubt, we will expand the description in the abstract and Section 3 to explicitly enumerate the distribution shifts used for the OOD benchmark. revision: yes
Circularity Check
No significant circularity; empirical dataset and model contribution with no derivation chain
full rationale
The paper introduces the Omni-Fake dataset (including Omni-Fake-Set and Omni-Fake-OOD held-out split) and the Omni-Fake-R1 RL-driven detector. All reported gains in accuracy, generalization, and explainability are presented as outcomes of experimental benchmarking on this new data. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The OOD split is described as intentionally excluded samples for generalization testing, which is a standard empirical practice and does not reduce any claim to a tautology by construction. The work is self-contained as a dataset-plus-model empirical study without any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Inclusion AI, Biao Gong, Cheng Zou, Chuanyang Zheng, Chunluan Zhou, Canxiang Yan, Chunxiang Jin, Chunjie Shen, Dandan Zheng, Fudong Wang, et al. Ming-omni: A unified multimodal model for perception and generation. arXiv preprint arXiv:2506.09344, 2025. 1
-
[2]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, An- toine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems, 35: 23716–23736, 2022. 3
2022
-
[3]
Intra-modal and cross-modal synchro- nization for audio-visual deepfake detection and tempo- ral localization
Ashutosh Anshul, Shreyas Gopal, Deepu Rajan, and Eng Siong Chng. Intra-modal and cross-modal synchro- nization for audio-visual deepfake detection and tempo- ral localization. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 13826– 13836, 2025. 3
2025
-
[4]
Tyers, and Gregor Weber
Rosana Ardila, Megan Branson, Kelly Davis, Michael Hen- retty, Michael Kohler, Josh Meyer, Reuben Morais, Lindsay Saunders, Francis M. Tyers, and Gregor Weber. Common voice: A massively-multilingual speech corpus, 2020. 4
2020
-
[5]
Kandinsky 3.0 technical report, 2024
Vladimir Arkhipkin, Andrei Filatov, Viacheslav Vasilev, Anastasia Maltseva, Said Azizov, Igor Pavlov, Julia Aga- fonova, Andrey Kuznetsov, and Denis Dimitrov. Kandinsky 3.0 technical report, 2024. 4
2024
-
[6]
One token to seg them all: Language instructed reasoning seg- mentation in videos.Advances in Neural Information Pro- cessing Systems, 37:6833–6859, 2024
Zechen Bai, Tong He, Haiyang Mei, Pichao Wang, Ziteng Gao, Joya Chen, Zheng Zhang, and Mike Zheng Shou. One token to seg them all: Language instructed reasoning seg- mentation in videos.Advances in Neural Information Pro- cessing Systems, 37:6833–6859, 2024. 1, 2, 7
2024
-
[7]
Sarah Barrington, Matyas Bohacek, and Hany Farid. The deepspeak dataset.arXiv preprint arXiv:2408.05366, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Yuxuan Bian, Zhaoyang Zhang, Xuan Ju, Mingdeng Cao, Liangbin Xie, Ying Shan, and Qiang Xu. Videopainter: Any-length video inpainting and editing with plug-and-play context control.arXiv preprint arXiv:2503.05639, 2025. 4
-
[9]
FLUX.1 [dev].https : / / huggingface.co/black- forest- labs/FLUX
Black Forest Labs. FLUX.1 [dev].https : / / huggingface.co/black- forest- labs/FLUX. 1-dev, 2024. Official model card. 4
2024
-
[10]
com / boson - ai / higgs-audio, 2025
Boson AI.https : / / github . com / boson - ai / higgs-audio, 2025. 4
2025
-
[11]
Av-deepfake1m: A large-scale llm-driven audio-visual deepfake dataset
Zhixi Cai, Shreya Ghosh, Aman Pankaj Adatia, Munawar Hayat, Abhinav Dhall, Tom Gedeon, and Kalin Stefanov. Av-deepfake1m: A large-scale llm-driven audio-visual deepfake dataset. InProceedings of the 32nd ACM Interna- tional Conference on Multimedia, pages 7414–7423, 2024. 4
2024
-
[12]
Nuria Alina Chandra, Ryan Murtfeldt, Lin Qiu, Arnab Karmakar, Hannah Lee, Emmanuel Tanumihardja, Kevin Farhat, Ben Caffee, Sejin Paik, Changyeon Lee, et al. Deepfake-eval-2024: A multi-modal in-the-wild bench- mark of deepfakes circulated in 2024.arXiv preprint arXiv:2503.02857, 2025. 4
-
[13]
arXiv preprint arXiv:2310.17419 (2024)
You-Ming Chang, Chen Yeh, Wei-Chen Chiu, and Ning Yu. Antifakeprompt: Prompt-tuned vision-language models are fake image detectors.arXiv preprint arXiv:2310.17419,
-
[14]
Demamba: Ai-generated video detection on million-scale genvideo benchmark,
Haoxing Chen, Yan Hong, Zizheng Huang, Zhuoer Xu, Zhangxuan Gu, Yaohui Li, Jun Lan, Huijia Zhu, Jianfu Zhang, Weiqiang Wang, et al. Demamba: Ai-generated video detection on million-scale genvideo benchmark. arXiv preprint arXiv:2405.19707, 2024. 1, 2, 3, 7, 8
-
[15]
Shunian Chen, Hejin Huang, Yexin Liu, Zihan Ye, Pengcheng Chen, Chenghao Zhu, Michael Guan, Rong- sheng Wang, Junying Chen, Guanbin Li, et al. Talkvid: A large-scale diversified dataset for audio-driven talking head synthesis.arXiv preprint arXiv:2508.13618, 2025. 4
-
[16]
Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions,
Zhiyuan Chen, Jiajiong Cao, Zhiquan Chen, Yuming Li, and Chenguang Ma. Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions,
-
[17]
Alibaba Cloud.https://wanx.aliyun.com/, 2024. 1
2024
-
[18]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodal- ity, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
On the de- tection of synthetic images generated by diffusion models
Riccardo Corvi, Davide Cozzolino, Giada Zingarini, Gio- vanni Poggi, Koki Nagano, and Luisa Verdoliva. On the de- tection of synthetic images generated by diffusion models. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023. 1, 3
2023
-
[20]
Florinel-Alin Croitoru, Vlad Hondru, Marius Popescu, Radu Tudor Ionescu, Fahad Shahbaz Khan, and Mubarak Shah. Mavos-dd: Multilingual audio-video open- set deepfake detection benchmark.arXiv preprint arXiv:2505.11109, 2025. 4
-
[21]
Hallo2: Long-duration and high-resolution audio-driven portrait image animation, 2024
Jiahao Cui, Hui Li, Yao Yao, Hao Zhu, Hanlin Shang, Kai- hui Cheng, Hang Zhou, Siyu Zhu, and Jingdong Wang. Hallo2: Long-duration and high-resolution audio-driven portrait image animation, 2024. 4
2024
-
[22]
Hallo3: Highly dynamic and realistic portrait image animation with video diffusion transformer
Jiahao Cui, Hui Li, Yun Zhan, Hanlin Shang, Kaihui Cheng, Yuqi Ma, Shan Mu, Hang Zhou, Jingdong Wang, and Siyu Zhu. Hallo3: Highly dynamic and realistic portrait image animation with video diffusion transformer. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 21086–21095, 2025. 4
2025
-
[23]
On the detection of digital face manipulation
Hao Dang, Feng Liu, Joel Stehouwer, Xiaoming Liu, and Anil K Jain. On the detection of digital face manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern recognition, pages 5781–5790, 2020. 1, 3
2020
-
[24]
Exposing lip-syncing deepfakes from mouth inconsistencies
Soumyya Kanti Datta, Shan Jia, and Siwei Lyu. Exposing lip-syncing deepfakes from mouth inconsistencies. In2024 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2024. 7
2024
-
[25]
Stefano Dell’Anna, Andrea Montibeller, and Giulia Boato. Truefake: A real world case dataset of last generation fake images also shared on social networks.arXiv preprint arXiv:2504.20658, 2025. 4
-
[26]
The DeepFake Detection Challenge (DFDC) Dataset
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, and Cristian Canton Ferrer. The deepfake detection challenge (dfdc) dataset.arXiv preprint arXiv:2006.07397, 2020. 1, 3, 4
work page internal anchor Pith review arXiv 2006
-
[27]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, et al. Cosyvoice: A scalable multilingual zero-shot text- to-speech synthesizer based on supervised semantic tokens. arXiv preprint arXiv:2407.05407, 2024. 4
-
[28]
Self- supervised video forensics by audio-visual anomaly detec- tion
Chao Feng, Ziyang Chen, and Andrew Owens. Self- supervised video forensics by audio-visual anomaly detec- tion. Inproceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 10491–10503,
-
[29]
Nanobanana.https://aistudio.google
Google. Nanobanana.https://aistudio.google. com/models/gemini- 2- 5- flash- image, 2025. As cited in So-Fake. 4
2025
-
[30]
Language-guided hierarchical fine-grained image forgery detection and localization.International Journal of Com- puter Vision, 133(5):2670–2691, 2025
Xiao Guo, Xiaohong Liu, Iacopo Masi, and Xiaoming Liu. Language-guided hierarchical fine-grained image forgery detection and localization.International Journal of Com- puter Vision, 133(5):2670–2691, 2025. 2, 7
2025
-
[31]
Lips don’t lie: A generalisable and robust approach to face forgery detection
Alexandros Haliassos, Konstantinos V ougioukas, Stavros Petridis, and Maja Pantic. Lips don’t lie: A generalisable and robust approach to face forgery detection. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5039–5049, 2021. 2, 7, 8
2021
-
[32]
Leveraging real talking faces via self- supervision for robust forgery detection
Alexandros Haliassos, Rodrigo Mira, Stavros Petridis, and Maja Pantic. Leveraging real talking faces via self- supervision for robust forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14950–14962, 2022. 2, 7, 8
2022
-
[33]
Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? InProceedings of the IEEE conference on Com- puter Vision and Pattern Recognition, pages 6546–6555,
Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? InProceedings of the IEEE conference on Com- puter Vision and Pattern Recognition, pages 6546–6555,
-
[34]
Forgerynet: A versatile benchmark for comprehen- sive forgery analysis
Yinan He, Bei Gan, Siyu Chen, Yichun Zhou, Guojun Yin, Luchuan Song, Lu Sheng, Jing Shao, and Ziwei Liu. Forgerynet: A versatile benchmark for comprehen- sive forgery analysis. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 4360–4369, 2021. 1, 3, 4
2021
-
[35]
Hexgrad.https://huggingface.co/hexgrad/ Kokoro-82M, 2025. 4
2025
-
[36]
Fa-Ting Hong, Zunnan Xu, Zixiang Zhou, Jun Zhou, Xiu Li, Qin Lin, Qinglin Lu, and Dan Xu. Audio-visual con- trolled video diffusion with masked selective state spaces modeling for natural talking head generation.arXiv preprint arXiv:2504.02542, 2025. 4
-
[37]
Wildfake: A large-scale challenging dataset for ai-generated images detection
Yan Hong and Jianfu Zhang. Wildfake: A large-scale chal- lenging dataset for ai-generated images detection.arXiv preprint arXiv:2402.11843, 2024. 1, 3
-
[38]
Yuqi Hu, Longguang Wang, Xian Liu, Ling-Hao Chen, Yuwei Guo, Yukai Shi, Ce Liu, Anyi Rao, Zeyu Wang, and Hui Xiong. Simulating the real world: A unified survey of multimodal generative models.arXiv preprint arXiv:2503.04641, 2025. 1
-
[39]
Sida: Social media image deepfake detec- tion, localization and explanation with large multimodal model
Zhenglin Huang, Jinwei Hu, Xiangtai Li, Yiwei He, Xingyu Zhao, Bei Peng, Baoyuan Wu, Xiaowei Huang, and Guan- gliang Cheng. Sida: Social media image deepfake detec- tion, localization and explanation with large multimodal model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28831–28841, 2025. 1, 2, 3, 4, 7, 8
2025
-
[40]
Zhenglin Huang, Tianxiao Li, Xiangtai Li, Haiquan Wen, Yiwei He, Jiangning Zhang, Hao Fei, Xi Yang, Xiaowei Huang, Bei Peng, et al. So-fake: Benchmarking and explaining social media image forgery detection.arXiv preprint arXiv:2505.18660, 2025. 1, 3, 4
-
[41]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 1, 3, 4
work page internal anchor Pith review arXiv 2024
-
[42]
Ideogram 3.0.https://ideogram.ai/ features/3.0, 2025
Ideogram. Ideogram 3.0.https://ideogram.ai/ features/3.0, 2025. Official product page. 4
2025
-
[43]
Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks
Jee-weon Jung, Hee-Soo Heo, Hemlata Tak, Hye-jin Shim, Joon Son Chung, Bong-Jin Lee, Ha-Jin Yu, and Nicholas Evans. Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks. InICASSP 2022-2022 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 6367–6371. IEEE, 2022. 2, 7, 8
2022
-
[44]
Hengrui Kang, Siwei Wen, Zichen Wen, Junyan Ye, Weijia Li, Peilin Feng, Baichuan Zhou, Bin Wang, Dahua Lin, Lin- feng Zhang, and Conghui He. Legion: Learning to ground and explain for synthetic image detection.arXiv preprint arXiv:2503.15264, 2025. 7
-
[45]
Alias- free generative adversarial networks.Advances in neural information processing systems, 34:852–863, 2021
Tero Karras, Miika Aittala, Samuli Laine, Erik H ¨ark¨onen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Alias- free generative adversarial networks.Advances in neural information processing systems, 34:852–863, 2021. 3, 4
2021
- [46]
-
[47]
Klassify to verify: Audio- visual deepfake detection using ssl-based audio and hand- crafted visual features
Ivan Kukanov and Jun Wah Ng. Klassify to verify: Audio- visual deepfake detection using ssl-based audio and hand- crafted visual features. InProceedings of the 33rd ACM International Conference on Multimedia, pages 13707– 13713, 2025. 1
2025
-
[48]
Towards a univer- sal synthetic video detector: From face or background ma- nipulations to fully ai-generated content
Rohit Kundu, Hao Xiong, Vishal Mohanty, Athula Bal- achandran, and Amit K Roy-Chowdhury. Towards a univer- sal synthetic video detector: From face or background ma- nipulations to fully ai-generated content. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28050–28060, 2025. 3
2025
-
[49]
Kodf: A large-scale ko- rean deepfake detection dataset
Patrick Kwon, Jaeseong You, Gyuhyeon Nam, Sungwoo Park, and Gyeongsu Chae. Kodf: A large-scale ko- rean deepfake detection dataset. InProceedings of the IEEE/CVF international conference on computer vision, pages 10744–10753, 2021. 1, 3
2021
-
[50]
Kuaishou AI Lab.https://klingai.com/, 2024. 1
2024
-
[51]
Nari Labs.https://github.com/nari- labs/ dia, 2025. 4
2025
-
[52]
Pika Labs.https://pika.art, 2024. 4
2024
-
[53]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742, 2023. 3
2023
-
[54]
Omniflow: Any-to-any generation with multi- modal rectified flows
Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Zichun Liao, Yusuke Kato, Kazuki Kozuka, and Aditya Grover. Omniflow: Any-to-any generation with multi- modal rectified flows. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13178– 13188, 2025. 1
2025
-
[55]
Raidx: A retrieval-augmented generation and grpo rein- forcement learning framework for explainable deepfake de- tection, 2025
Tianxiao Li, Zhenglin Huang, Haiquan Wen, Yiwei He, Shuchang Lyu, Baoyuan Wu, and Guangliang Cheng. Raidx: A retrieval-augmented generation and grpo rein- forcement learning framework for explainable deepfake de- tection, 2025. 2
2025
-
[56]
Ditto: Motion-space diffusion for control- lable realtime talking head synthesis
Tianqi Li, Ruobing Zheng, Minghui Yang, Jingdong Chen, and Ming Yang. Ditto: Motion-space diffusion for control- lable realtime talking head synthesis. InProceedings of the 33rd ACM International Conference on Multimedia, pages 9704–9713, 2025. 4
2025
-
[57]
Safeear: Content privacy-preserving audio deepfake detection
Xinfeng Li, Kai Li, Yifan Zheng, Chen Yan, Xiaoyu Ji, and Wenyuan Xu. Safeear: Content privacy-preserving audio deepfake detection. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Se- curity, pages 3585–3599, 2024. 3, 7, 8
2024
-
[58]
Cross-domain audio deepfake detection: Dataset and analysis
Yuang Li, Min Zhang, Mengxin Ren, Xiaosong Qiao, Miaomiao Ma, Daimeng Wei, and Hao Yang. Cross-domain audio deepfake detection: Dataset and analysis. InPro- ceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4977–4983, 2024. 3
2024
-
[59]
Shijia Liao, Yuxuan Wang, Tianyu Li, Yifan Cheng, Ruoyi Zhang, Rongzhi Zhou, and Yijin Xing. Fish-speech: Lever- aging large language models for advanced multilingual text-to-speech synthesis.arXiv preprint arXiv:2411.01156,
-
[60]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 3, 7
2024
-
[61]
Jiaxin Liu, Jia Wang, Saihui Hou, Min Ren, Huijia Wu, Long Ma, Renwang Pei, and Zhaofeng He. Beyond face swapping: A diffusion-based digital human bench- mark for multimodal deepfake detection.arXiv preprint arXiv:2505.16512, 2025. 3
-
[62]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision- language understanding.arXiv preprint arXiv:2403.05525,
work page internal anchor Pith review arXiv
-
[63]
Seeing is not always be- lieving: Benchmarking human and model perception of ai- generated images.Advances in neural information process- ing systems, 36:25435–25447, 2023
Zeyu Lu, Di Huang, Lei Bai, Jingjing Qu, Chengyue Wu, Xihui Liu, and Wanli Ouyang. Seeing is not always be- lieving: Benchmarking human and model perception of ai- generated images.Advances in neural information process- ing systems, 36:25435–25447, 2023. 4
2023
-
[64]
Llamapartialspoof: An llm-driven fake speech dataset simulating disinformation generation
Hieu-Thi Luong, Haoyang Li, Lin Zhang, Kong Aik Lee, and Eng Siong Chng. Llamapartialspoof: An llm-driven fake speech dataset simulating disinformation generation. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025. 4
2025
-
[65]
Explainable ai for deepfake detection.Applied Sciences, 15(2):725, 2025
Nazneen Mansoor and Alexander I Iliev. Explainable ai for deepfake detection.Applied Sciences, 15(2):725, 2025. 2
2025
-
[66]
Towards uni- versal fake image detectors that generalize across genera- tive models
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. Towards uni- versal fake image detectors that generalize across genera- tive models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24480– 24489, 2023. 2, 7
2023
-
[67]
OpenAI.https://openai.com/sora, 2024. 1, 4
2024
-
[68]
Training language models to follow instructions with human feedback.Advances in neural in- formation processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, et al. Training language models to follow instructions with human feedback.Advances in neural in- formation processing systems, 35:27730–27744, 2022. 3
2022
-
[69]
Community forensics: Using thousands of generators to train fake image detec- tors
Jeongsoo Park and Andrew Owens. Community forensics: Using thousands of generators to train fake image detec- tors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8245–8257, 2025. 1, 3
2025
-
[70]
Deepfake generation and detection: A benchmark and survey.arXiv preprint arXiv:2403.17881,
Gan Pei, Jiangning Zhang, Menghan Hu, Zhenyu Zhang, Chengjie Wang, Yunsheng Wu, Guangtao Zhai, Jian Yang, Chunhua Shen, and Dacheng Tao. Deepfake generation and detection: A benchmark and survey.arXiv preprint arXiv:2403.17881, 2024. 1
-
[71]
Mls: A large-scale multilingual dataset for speech research,
Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, and Ronan Collobert. Mls: A large-scale multilingual dataset for speech research.arXiv preprint arXiv:2012.03411, 2020. 4
-
[72]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023. 3
2023
-
[73]
Resemble AI.https://github.com/resemble- ai/chatterbox, 2025. 4
2025
-
[74]
Face- forensics++: Learning to detect manipulated facial images
Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. Face- forensics++: Learning to detect manipulated facial images. InProceedings of the IEEE/CVF international conference on computer vision, pages 1–11, 2019. 1, 3
2019
-
[75]
Runway.https://runwayml.com/gen3, 2024. 4
2024
-
[76]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[77]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junx- iao Song, et al. Deepseekmath: Pushing the limits of math- ematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[78]
Circumventing shortcuts in audio-visual deepfake detection datasets with unsupervised learning
Stefan Smeu, Dragos-Alexandru Boldisor, Dan Oneata, and Elisabeta Oneata. Circumventing shortcuts in audio-visual deepfake detection datasets with unsupervised learning. In Proceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 18815–18825, 2025. 7, 8
2025
-
[79]
Hemlata Tak, Massimiliano Todisco, Xin Wang, Jee-weon Jung, Junichi Yamagishi, and Nicholas Evans. Automatic speaker verification spoofing and deepfake detection us- ing wav2vec 2.0 and data augmentation.arXiv preprint arXiv:2202.12233, 2022. 2, 7
-
[80]
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35:10078–10093, 2022
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35:10078–10093, 2022. 7
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.