Recognition: 3 theorem links
· Lean TheoremTRIMMER: A New Paradigm for Video Summarization through Self-Supervised Reinforcement Learning
Pith reviewed 2026-05-08 19:25 UTC · model grok-4.3
The pith
Self-supervised reinforcement learning with entropy rewards summarizes videos competitively with supervised methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TRIMMER first learns robust representations via self-supervised learning and then performs spatio-temporal decision making through reinforcement learning guided by entropy-based information-theoretic reward functions that capture higher-order temporal dynamics and semantic diversity, computing rewards directly over selected frame indices to achieve state-of-the-art performance among unsupervised and self-supervised methods while remaining competitive with leading supervised approaches.
What carries the argument
Entropy-based information-theoretic reward functions that guide reinforcement learning by measuring temporal relative information and semantic diversity directly from frame index selections.
If this is right
- State-of-the-art performance among unsupervised and self-supervised video summarization methods on standard benchmarks.
- Competitive results with leading supervised approaches without requiring manual annotations.
- Improved computational efficiency by computing rewards directly over selected frame indices instead of full similarity computations.
- Better capture of long-range temporal dependencies and semantic structure across video domains.
- Reduced need for expensive labeled data while maintaining generalization.
Where Pith is reading between the lines
- The two-stage design could be adapted to other sequential decision tasks in vision such as action localization.
- If the entropy rewards hold up, they might reduce reliance on large annotated datasets for video AI applications.
- Testing the method on unlabeled real-world streams from new domains could expose where the self-supervised stage falls short.
- Minimal human feedback could be added later to the RL stage to handle edge cases without full supervision.
Load-bearing premise
Entropy-based information-theoretic reward functions can reliably capture higher-order temporal dynamics and semantic diversity without any labeled supervision.
What would settle it
Reproducing the benchmark experiments and finding that human evaluators rate TRIMMER summaries as less semantically coherent or diverse than those from a basic supervised baseline on the same datasets.
Figures





read the original abstract
The rapid growth of video content across domains such as surveillance, education, and social media has made efficient content understanding increasingly critical. Video summarization addresses this challenge by generating concise yet semantically meaningful representations, but existing approaches often rely on expensive manual annotations, struggle to generalize across domains, and incur significant computational costs due to complex architectures. Moreover, unsupervised and weakly supervised methods typically underperform compared to supervised counterparts in capturing long-range temporal dependencies and semantic structure. In this work, we propose TRIMMER (Temporal Relative Information Maximization for Multi-objective Efficient Reinforcement), a novel self-supervised reinforcement learning framework for video summarization. TRIMMER operates in two stages: it first learns robust representations via self-supervised learning and then performs spatio-temporal decision making through reinforcement learning guided by information-theoretic reward functions. Unlike prior approaches that rely on similarity-based objectives, our method introduces entropy-based metrics to capture higher-order temporal dynamics and semantic diversity, while computing rewards directly over selected frame indices to improve computational efficiency. Extensive experiments on standard benchmarks demonstrate that TRIMMER achieves state-of-the-art performance among unsupervised and self-supervised methods, while remaining competitive with leading supervised approaches, highlighting its effectiveness for scalable and generalizable video summarization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TRIMMER, a two-stage self-supervised reinforcement learning framework for video summarization. The first stage performs self-supervised pretraining to learn robust representations; the second stage uses an RL policy for spatio-temporal frame selection, with rewards defined via entropy-based information-theoretic metrics computed directly on the selected frame indices rather than similarity objectives. The method claims to capture higher-order temporal dynamics and semantic diversity more effectively than prior unsupervised approaches. Extensive experiments on standard benchmarks are said to establish state-of-the-art results among unsupervised and self-supervised methods while remaining competitive with leading supervised techniques.
Significance. If the empirical claims are substantiated, TRIMMER would offer a scalable, annotation-free alternative that reduces reliance on labeled data and potentially lowers computational overhead through direct index-based rewards. The shift to entropy metrics for multi-objective RL guidance could improve generalization across domains such as surveillance and education, addressing a known weakness of existing unsupervised video summarization methods.
major comments (3)
- [Abstract] Abstract: The central claim of achieving SOTA performance among unsupervised/self-supervised methods (and competitiveness with supervised ones) is asserted without any reference to specific datasets, metrics (e.g., F1-score), baselines, ablation studies, or statistical significance in the abstract itself. This absence prevents immediate assessment of whether the data support the stated result.
- [§3] §3 (Method, reward definition): The entropy-based reward is computed directly over selected frame indices to capture 'higher-order temporal dynamics and semantic diversity.' However, the description provides no indication of long-horizon state maintenance in the policy (e.g., recurrent memory, attention over the full sequence, or explicit temporal modeling). Local entropy over index sets is information-theoretically insufficient for global coherence without such mechanisms, undermining the claim that these rewards reliably encode long-range structure in the absence of labels.
- [§4] §4 (Experiments): The assertion that TRIMMER remains competitive with supervised methods requires explicit quantitative comparison (performance deltas, tables with error bars). If the unsupervised gap is small, this would be a strong result, but the lack of reported details on how the two-stage pipeline was ablated (pretraining vs. RL contribution) makes the load-bearing empirical support unverifiable from the given information.
minor comments (2)
- [Abstract] Abstract: The full expansion of TRIMMER ('Temporal Relative Information Maximization for Multi-objective Efficient Reinforcement') introduces 'Relative' without immediate motivation; a brief parenthetical on its meaning would improve clarity.
- [Introduction] Introduction: Prior work is criticized for 'complex architectures' and 'significant computational costs,' but no concrete references to parameter counts, FLOPs, or inference times of those baselines are supplied. Adding such numbers would make the efficiency advantage concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and describe the revisions we will make to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: The central claim of achieving SOTA performance among unsupervised/self-supervised methods (and competitiveness with supervised ones) is asserted without any reference to specific datasets, metrics (e.g., F1-score), baselines, ablation studies, or statistical significance in the abstract itself. This absence prevents immediate assessment of whether the data support the stated result.
Authors: We agree that the abstract would be strengthened by including concrete references to support the performance claims. In the revised manuscript, we will update the abstract to explicitly mention the key datasets (TVSum and SumMe), the primary metric (F1-score), the main unsupervised and supervised baselines, and the nature of the reported improvements. revision: yes
-
Referee: The entropy-based reward is computed directly over selected frame indices to capture 'higher-order temporal dynamics and semantic diversity.' However, the description provides no indication of long-horizon state maintenance in the policy (e.g., recurrent memory, attention over the full sequence, or explicit temporal modeling). Local entropy over index sets is information-theoretically insufficient for global coherence without such mechanisms, undermining the claim that these rewards reliably encode long-range structure in the absence of labels.
Authors: The referee correctly notes that the current method description lacks explicit detail on the policy's temporal state handling. The sequential nature of the RL decision process, combined with the global entropy objective over the selected index set, is intended to promote long-range coherence, but we acknowledge the need for clarification. We will revise §3 to describe the policy's state representation and how it incorporates sequence-level information during frame selection. revision: yes
-
Referee: The assertion that TRIMMER remains competitive with supervised methods requires explicit quantitative comparison (performance deltas, tables with error bars). If the unsupervised gap is small, this would be a strong result, but the lack of reported details on how the two-stage pipeline was ablated (pretraining vs. RL contribution) makes the load-bearing empirical support unverifiable from the given information.
Authors: We appreciate this point on the experimental presentation. Our current experiments include baseline comparisons and some ablation results, but we agree that more explicit quantitative details are warranted. In the revised §4, we will add tables reporting performance deltas with error bars and expand the ablation study to clearly isolate the contributions of the self-supervised pretraining stage versus the RL stage. revision: yes
Circularity Check
No circularity: method description self-contained without equation-level reductions
full rationale
The abstract and available description introduce TRIMMER as a two-stage self-supervised RL pipeline using entropy-based rewards computed on frame indices, but contain no equations, reward definitions, or derivation steps. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear. The claim of capturing higher-order dynamics via entropy metrics is presented as a design choice rather than derived from prior results by construction, leaving the framework independent of its own outputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J-cost uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RPTRIM = (1/(|S|−1)) Σ Δ_t ; Δ_t = |(H_t − H_{t-1})/H_t| ; H_t = −Σ D^j_t log D^j_t
-
Foundation.LogicAsFunctionalEquationderivedCost / J-uniqueness corollary unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RREP = exp(−(1/N) Σ min_{t'∈S} |H_t − H_{t'}|)
-
Foundation (parameter-free derivation theme)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
λ serves as a scaling factor to balance the contributions of the individual reward components ... optimal value of λ is 0.85
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Progressive video summarization via multimodal self-supervised learning,
H. Li, Q. Ke, M. Gong, and T. Drummond, “Progressive video summarization via multimodal self-supervised learning,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2023, pp. 5584–5593
2023
-
[2]
Video joint modelling based on hierarchical transformer for co-summarization,
H. Li, Q. Ke, M. Gong, and R. Zhang, “Video joint modelling based on hierarchical transformer for co-summarization,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3904–3917, 2022
2022
-
[4]
Align and attend: Multimodal summarization with dual contrastive losses,
B. He, J. Wang, J. Qiu, T. Bui, A. Shrivastava, and Z. Wang, “Align and attend: Multimodal summarization with dual contrastive losses,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 14 867–14 878
2023
-
[5]
Relational reasoning over spatial-temporal graphs for video summarization,
W. Zhu, Y . Han, J. Lu, and J. Zhou, “Relational reasoning over spatial-temporal graphs for video summarization,”IEEE Transactions on Image Processing, vol. 31, pp. 3017–3031, 2022
2022
-
[6]
Deep reinforcement learning for unsupervised video summa- rization with diversity-representativeness reward,
K. Zhou, Y . Qiao, and T. Xiang, “Deep reinforcement learning for unsupervised video summa- rization with diversity-representativeness reward,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, 2018
2018
-
[7]
Unsupervised video summarization with adver- sarial lstm networks,
B. Mahasseni, M. Lam, and S. Todorovic, “Unsupervised video summarization with adver- sarial lstm networks,” inProceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 202–211
2017
-
[8]
Unsupervised video summarization via attention-driven adversarial learning,
E. Apostolidis, E. Adamantidou, A. I. Metsai, V . Mezaris, and I. Patras, “Unsupervised video summarization via attention-driven adversarial learning,” inMultiMedia Modeling: 26th International Conference, MMM 2020, Daejeon, South Korea, January 5–8, 2020, Proceedings, Part I 26. Springer, 2020, pp. 492–504
2020
-
[9]
Discriminative feature learning for unsuper- vised video summarization,
Y . Jung, D. Cho, D. Kim, S. Woo, and I. S. Kweon, “Discriminative feature learning for unsuper- vised video summarization,” in Proceedings of the AAAI Conference on artificial intelligence, vol. 33, 2019, pp. 8537–8544
2019
-
[10]
Masked autoencoder for unsupervised video summarization,
M. Shim, T. Kim, J. Kim, and D. Wee, “Masked autoencoder for unsupervised video summarization,” 2023. [Online]. Available: https://arxiv.org/abs/2306.01395
-
[11]
Csta: Cnn-based spatiotemporal attention for video summarization,
J. Son, J. Park, and K. Kim, “Csta: Cnn-based spatiotemporal attention for video summarization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 847–18 856
2024
-
[12]
Supervised video summarization via multiple feature sets with parallel attention,
J. A. Ghauri, S. Hakimov, and R. Ewerth, “Supervised video summarization via multiple feature sets with parallel attention,” in 2021 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2021, pp. 1–6s
2021
-
[13]
Query twice: Dual mixture attention meta learning for video summarization,
J. Wang, Y . Bai, Y . Long, B. Hu, Z. Chai, Y . Guan, and X. Wei, “Query twice: Dual mixture attention meta learning for video summarization,” inProceedings of the 28th ACM international conference on multimedia, 2020, pp. 4023–4031
2020
-
[14]
P. Mishra, C. Ballester, and D. Karatzas, “Trim: A self-supervised video summarization framework maximizing temporal relative information and representativeness,” 2025. [Online]. Available: https://arxiv.org/abs/2506.20588
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Discovering important people and objects for egocentric video summarization,
Y . J. Lee, J. Ghosh, and K. Grauman, “Discovering important people and objects for egocentric video summarization,” in2012 IEEE Conference on Computer Vision and Pattern Recognition, 2012, pp. 1346–1353
2012
-
[16]
Summarizing videos with attention,
J. Fajtl, H. S. Sokeh, V . Argyriou, D. Monekosso, and P. Remagnino, “Summarizing videos with attention,” inComputer Vision–ACCV 2018 Workshops: 14th Asian Conference on Computer Vision, Perth, Australia, December 2–6, 2018, Revised Selected Papers 14. Springer, 2019, pp. 39–54
2018
-
[17]
Video summarization with long short-term memory,
K. Zhang, W.-L. Chao, F. Sha, and K. Grauman, “Video summarization with long short-term memory,” in Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part VII 14. Springer, 2016, pp. 766–782. 13
2016
-
[18]
Collaborative multi-agent video fast-forwarding,
S. Lan, Z. Wang, E. Wei, A. K. Roy-Chowdhury, and Q. Zhu, “Collaborative multi-agent video fast-forwarding,”IEEE Transactions on Multimedia, 2023
2023
-
[19]
Memorable and rich video summarization,
M. Fei, W. Jiang, and W. Mao, “Memorable and rich video summarization,”Journal of Visual Communication and Image Representation, vol. 42, pp. 207–217, 2017. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1047320316302498
2017
-
[20]
Text-driven video acceleration: a weakly-supervised reinforcement learning method,
W. Ramos, M. Silva, E. Araujo, V . Moura, K. Oliveira, L. S. Marcolino, and E. R. Nascimento, “Text-driven video acceleration: a weakly-supervised reinforcement learning method,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 2, pp. 2492–2504, 2022
2022
-
[21]
Straight to the point: fast-forwarding videos via reinforcement learning using textual data,
W. Ramos, M. Silva, E. Araujo, L. S. Marcolino, and E. Nascimento, “Straight to the point: fast-forwarding videos via reinforcement learning using textual data,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10 931–10 940
2020
-
[22]
Ffnet: Video fast-forwarding via reinforcement learning,
S. Lan, R. Panda, Q. Zhu, and A. K. Roy-Chowdhury, “Ffnet: Video fast-forwarding via reinforcement learning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6771–6780
2018
-
[23]
A weighted sparse sampling and smoothing frame transition approach for semantic fast-forward first-person videos,
M. Silva, W. Ramos, J. Ferreira, F. Chamone, M. Campos, and E. R. Nascimento, “A weighted sparse sampling and smoothing frame transition approach for semantic fast-forward first-person videos,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 2383–2392
2018
-
[24]
Summarization of egocentric moving videos for generating walking route guidance,
M. Okamoto and K. Yanai, “Summarization of egocentric moving videos for generating walking route guidance,” in Image and Video Technology: 6th Pacific-Rim Symposium, PSIVT 2013, Guanajuato, Mexico, October 28-November 1, 2013. Proceedings 6. Springer, 2014, pp. 431–442
2013
-
[25]
Fast-forward video based on semantic extraction,
W. L. S. Ramos, M. M. Silva, M. F. M. Campos, and E. R. Nascimento, “Fast-forward video based on semantic extraction,” inIEEE International Conference on Image Processing (ICIP), Phoenix, USA, Sep. 2016, pp. 3334–3338
2016
-
[26]
Making a long story short: A multi-importance fast-forwarding egocentric videos with the emphasis on relevant objects,
M. M. Silva, W. L. S. Ramos, F. C. Chamone, J. P. K. Ferreira, M. F. M. Campos, and E. R. Nascimento, “Making a long story short: A multi-importance fast-forwarding egocentric videos with the emphasis on relevant objects,” Journal of Visual Communication and Image Representation, vol. 53, p. 55 – 64, 2018
2018
-
[27]
Video summarization with spatiotemporal vision transformer,
T.-C. Hsu, Y .-S. Liao, and C.-R. Huang, “Video summarization with spatiotemporal vision transformer,”IEEE Transactions on Image Processing, vol. 32, pp. 3013–3026, 2023
2023
-
[28]
Dsnet: A flexible detect-to-summarize network for video summarization,
W. Zhu, J. Lu, J. Li, and J. Zhou, “Dsnet: A flexible detect-to-summarize network for video summarization,”IEEE Transactions on Image Processing, vol. 30, pp. 948–962, 2020
2020
-
[29]
Multi-annotation attention model for video summarization,
H. Terbouche, M. Morel, M. Rodriguez, and A. Othmani, “Multi-annotation attention model for video summarization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 3143–3152
2023
-
[30]
Hsa-rnn: Hierarchical structure-adaptive rnn for video summa- rization,
B. Zhao, X. Li, and X. Lu, “Hsa-rnn: Hierarchical structure-adaptive rnn for video summa- rization,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7405–7414
2018
-
[31]
Exploring global diverse attention via pairwise temporal relation for video summarization,
P. Li, Q. Ye, L. Zhang, L. Yuan, X. Xu, and L. Shao, “Exploring global diverse attention via pairwise temporal relation for video summarization,” Pattern Recognition, vol. 111, p. 107677, 2021
2021
-
[32]
Summarizing videos using concentrated attention and considering the uniqueness and diversity of the video frames,
E. Apostolidis, G. Balaouras, V . Mezaris, and I. Patras, “Summarizing videos using concentrated attention and considering the uniqueness and diversity of the video frames,” inProceedings of the 2022 international conference on multimedia retrieval, 2022, pp. 407–415
2022
-
[33]
Combining global and local attention with positional encoding for video summarization,
——, “Combining global and local attention with positional encoding for video summarization,” in 2021 IEEE international symposium on multimedia (ISM). IEEE, 2021, pp. 226–234
2021
-
[34]
Weakly supervised deep reinforcement learning for video summarization with semantically meaningful reward,
Z. Li and L. Yang, “Weakly supervised deep reinforcement learning for video summarization with semantically meaningful reward,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV), January 2021, pp. 3239–3247
2021
-
[35]
Barlow twins: Self-supervised learning via redundancy reduction,
J. Zbontar, L. Jing, I. Misra, Y . LeCun, and S. Deny, “Barlow twins: Self-supervised learning via redundancy reduction,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 12 310–12 320. 14
2021
-
[36]
Bootstrap your own latent-a new approach to self-supervised learning,
J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar et al., “Bootstrap your own latent-a new approach to self-supervised learning,” Advances in neural information processing systems, vol. 33, pp. 21 271–21 284, 2020
2020
-
[37]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in International conference on machine learning. PMLR, 2020, pp. 1597–1607
2020
-
[38]
Clip-it! language-guided video summarization,
M. Narasimhan, A. Rohrbach, and T. Darrell, “Clip-it! language-guided video summarization,” Advances in neural information processing systems, vol. 34, pp. 13 988–14 000, 2021
2021
-
[39]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review arXiv 2014
-
[40]
Creating summaries from user videos,
M. Gygli, H. Grabner, H. Riemenschneider, and L. Van Gool, “Creating summaries from user videos,” in Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part VII 13. Springer, 2014, pp. 505–520
2014
-
[41]
Tvsum: Summarizing web videos using titles,
Y . Song, J. Vallmitjana, A. Stent, and A. Jaimes, “Tvsum: Summarizing web videos using titles,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015
2015
-
[42]
Simple statistical gradient-following algorithms for connectionist reinforcement learning,
R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,”Machine learning, vol. 8, pp. 229–256, 1992
1992
-
[43]
Category-specific video summarization,
D. Potapov, M. Douze, Z. Harchaoui, and C. Schmid, “Category-specific video summarization,” in Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part VI 13. Springer, 2014, pp. 540–555
2014
-
[44]
Video summarization with a dual attention capsule network,
H. Fu, H. Wang, and J. Yang, “Video summarization with a dual attention capsule network,” in 2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021, pp. 446–451
2020
-
[45]
Global-and-local relative position embedding for unsupervised video summarization,
Y . Jung, D. Cho, S. Woo, and I. S. Kweon, “Global-and-local relative position embedding for unsupervised video summarization,” in European conference on computer vision. Springer, 2020, pp. 167–183
2020
-
[46]
Video summarization with a dual-path attentive network,
G. Liang, Y . Lv, S. Li, X. Wang, and Y . Zhang, “Video summarization with a dual-path attentive network,”Neurocomputing, vol. 467, pp. 1–9, 2022
2022
-
[47]
Hierarchical multimodal transformer to summarize videos,
B. Zhao, M. Gong, and X. Li, “Hierarchical multimodal transformer to summarize videos,” Neurocomputing, vol. 468, pp. 360–369, 2022
2022
-
[48]
Joint video summarization and moment localization by cross-task sam- ple transfer,
H. Jiang and Y . Mu, “Joint video summarization and moment localization by cross-task sam- ple transfer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 388–16 398
2022
-
[49]
Vss-net: Visual semantic self-mining network for video summarization,
Y . Zhang, Y . Liu, W. Kang, and R. Tao, “Vss-net: Visual semantic self-mining network for video summarization,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 4, pp. 2775–2788, 2023
2023
-
[50]
Rethinking the evaluation of video summaries,
M. Otani, Y . Nakashima, E. Rahtu, and J. Heikkila, “Rethinking the evaluation of video summaries,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 7596–7604
2019
-
[51]
Trim: A self-supervised video summarization framework maximizing temporal relative information and representativeness,
P. Mishra, C. Ballester, and D. Karatzas, “Trim: A self-supervised video summarization framework maximizing temporal relative information and representativeness,” inProceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2026, accepted for publication
2026
-
[52]
Evaluation campaigns and trecvid,
A. F. Smeaton, P. Over, and W. Kraaij, “Evaluation campaigns and trecvid,” inProceedings of the 8th ACM international workshop on Multimedia information retrieval, 2006, pp. 321–330. 15 A Appendix A.1 Dataset Description SumMe DatasetThe SumMe dataset [ 40] is a widely used benchmark to evaluate video summa- rization algorithms. It contains 25 user-genera...
2006
-
[53]
eQu1rNs0an0
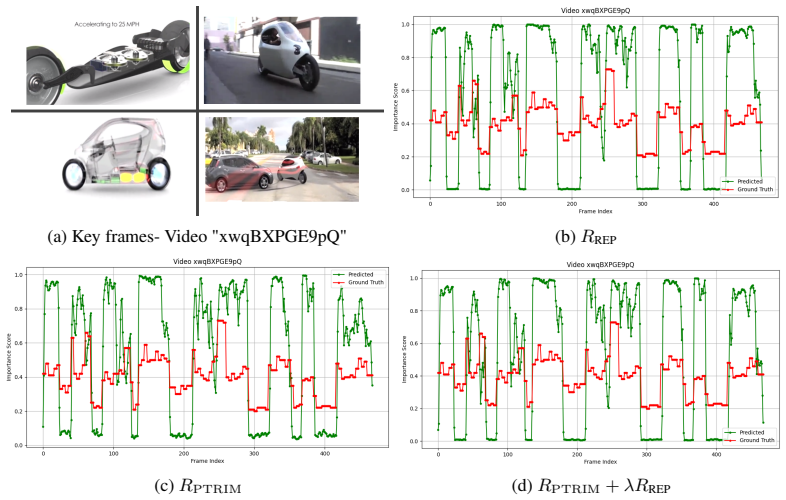
(Figure 5a) and SUMME dataset [40] (Figure 5b). For improved visual clarity, reward values were scaled to facilitate alignment across curves. the conceptual framework described in Section 5.1, thereby validating our reward design through both qualitative and quantitative evidence. (a) Key frames- Video "eQu1rNs0an0" (b)R REP (c)R PTRIM (d)R PTRIM +λR REP ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.