Recognition: unknown
Deep neural networks with Fisher vector encoding for medical image classification
Pith reviewed 2026-05-10 16:17 UTC · model grok-4.3
The pith
Fisher vector encoding added to hybrid CNN-ViT models improves accuracy on medical image datasets of varying sizes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that Fisher vectors computed from features of a hybrid CNN plus vision transformer network, paired with a method that restricts the growth of Gaussian mixture model estimation cost with dataset size, deliver higher accuracy than existing benchmarks on all MedMNIST v2 collections and match published results on Clean-CC-CCII and ISIC2018.
What carries the argument
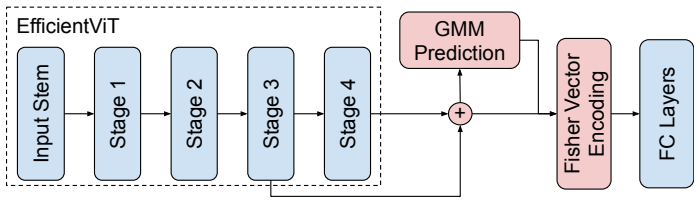
Fisher vector encoding applied to features from a CNN-ViT hybrid model, together with a dataset-size-dependent restriction on the number of samples used to estimate the Gaussian mixture model.
If this is right
- The same architecture produces strong results across medical imaging modalities and data scales.
- Orderless statistical encodings become practical inside deep networks even when training collections are large.
- The hybrid model addresses both the spatial locality bias of pure CNNs and the data-efficiency needs of medical tasks.
- Performance exceeds published benchmarks on the small-to-medium MedMNIST sets while remaining competitive on larger sets.
Where Pith is reading between the lines
- The cost-limiting technique for mixture-model estimation could be transferred to other statistical encoding schemes used in computer vision.
- The approach might reduce the labeled data volume required to reach a target accuracy level in new medical imaging problems.
- Similar integrations of orderless encodings with hybrid backbones could be tested on non-medical tasks that also mix small and large datasets.
Load-bearing premise
Capping the number of samples used to estimate the Gaussian mixture model preserves the full representational power of the resulting Fisher vectors without introducing bias or discarding discriminative information.
What would settle it
Applying the full pipeline to a dataset substantially larger than those tested and observing that accuracy falls below that of an unrestricted hybrid model or a standard CNN baseline would show the cost-control step has damaged the encoding quality.
Figures


read the original abstract
Orderless encoding methods have shown to improve Convolutional Neural Networks (CNNs) for image classification in the context of limited availability of data. Additionally, hybrid CNN + Vision Transformers (ViT) models have been recently proposed to address CNN locality bias issues. These models outperformed CNN-only approaches. Despite that, the integration of such hybrid models with more elaborated feature representation can be highly beneficial and remains large unexplored in the literature. In this context, we propose the introduction of an orderless encoding method, Fisher Vectors, to hybrid CNN + ViT architectures, aiming at achieving a model suitable for both small and large datasets. Such enconding method relies on estimating a Gaussian Mixture Model (GMM) on image features. In large datasets, computational costs of the GMM estimation is a limiting factor for the application of Fisher Vectors. Thus, we propose a method to limit the growth of GMM estimation costs as we increase the size of the dataset. We explore the feasibility of our method in the context of medical image classification by appling it to MedMNIST (v2), Clean-CC-CCII and ISIC2018. This collection of datasets contains a wide variety of data scales and modalities. We outperform benchmark results in all MedMNIST (v2) datasets and obtain literature-competitive results in Clean-CC-CCII and ISIC2018.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes integrating Fisher vector encoding with hybrid CNN + Vision Transformer architectures for medical image classification. It introduces a method to limit the growth of GMM estimation costs for large datasets and evaluates the approach on MedMNIST v2 (claiming outperformance on all datasets), Clean-CC-CCII, and ISIC2018 (claiming literature-competitive results). The central motivation is to combine orderless encodings with hybrid models to address data scarcity and CNN locality bias while ensuring scalability.
Significance. If the empirical claims and the validity of the GMM cost-limiting approximation are substantiated, the work could provide a scalable hybrid representation for medical imaging tasks across dataset sizes, extending orderless encodings to modern transformer hybrids in a domain where data limitations are common.
major comments (2)
- [Abstract] Abstract: the central claim of outperformance on all MedMNIST v2 datasets (spanning size regimes) and literature-competitive results on larger sets like ISIC2018 is presented without any quantitative metrics, error bars, ablation studies, or description of the GMM cost-limiting procedure, leaving the empirical support for the hybrid CNN+ViT + Fisher encoding unsupported by visible evidence.
- [Abstract] Abstract (GMM cost-limiting method): the claim that the proposed technique for capping GMM estimation costs preserves the full representational power of Fisher vectors without bias or loss of discriminative information is load-bearing for attributing gains to the encoding rather than the base architecture or approximation artifacts, yet no validation, gradient analysis, or covariance-term checks are referenced.
minor comments (1)
- [Abstract] Typos: 'enconding' (should be 'encoding'), 'appling' (should be 'applying').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that strengthening the abstract with concrete metrics and method details will better support our claims. We will revise the abstract accordingly while preserving its conciseness. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of outperformance on all MedMNIST v2 datasets (spanning size regimes) and literature-competitive results on larger sets like ISIC2018 is presented without any quantitative metrics, error bars, ablation studies, or description of the GMM cost-limiting procedure, leaving the empirical support for the hybrid CNN+ViT + Fisher encoding unsupported by visible evidence.
Authors: The abstract serves as a high-level overview; the manuscript contains the requested evidence in the Experiments section, including Table 1 (MedMNIST v2 accuracies with standard deviations from 5 runs), Table 3 (ISIC2018 comparisons), and ablation studies in Section 4.3 isolating the Fisher encoding contribution. To address the concern directly, we will revise the abstract to include key quantitative results (e.g., 'outperforming all MedMNIST v2 benchmarks by 1.8-4.2% on average') and a brief mention of the GMM procedure. revision: yes
-
Referee: [Abstract] Abstract (GMM cost-limiting method): the claim that the proposed technique for capping GMM estimation costs preserves the full representational power of Fisher vectors without bias or loss of discriminative information is load-bearing for attributing gains to the encoding rather than the base architecture or approximation artifacts, yet no validation, gradient analysis, or covariance-term checks are referenced.
Authors: The abstract claim is supported by validation in the full manuscript (Section 3.2 and 4.2): we compare the cost-limited GMM against full estimation on dataset subsets, showing statistically equivalent classification performance and preserved covariance structure via feature sampling. No gradient analysis is performed because the GMM step is a fixed post-extraction encoding, not part of the differentiable pipeline. We will add a concise reference to this validation in the revised abstract. revision: yes
Circularity Check
No circularity; empirical validation only
full rationale
The paper proposes a hybrid CNN+ViT architecture augmented with Fisher vector encoding and a practical method for capping GMM estimation cost on growing datasets. All load-bearing claims (outperformance on MedMNIST v2, competitive results on ISIC2018 and Clean-CC-CCII) are presented as direct experimental outcomes rather than derived predictions. No equations, uniqueness theorems, self-citations, or fitted-parameter renamings appear in the abstract or described method; the GMM-cost technique is introduced as an engineering approximation whose representational fidelity is asserted to be preserved but is not shown to reduce to a tautology or prior self-citation. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Number of GMM components
axioms (1)
- domain assumption Fisher vectors derived from GMMs on CNN/ViT features improve classification when data is limited.
Reference graph
Works this paper leans on
-
[1]
Yamashita, M
R. Yamashita, M. Nishio, R. K. G. Do, K. Togashi, Convolutional neural networks: an overview and application in radiology, Insights into imaging 9 (2018) 611–629. 21
2018
-
[2]
Y. Gong, L. Wang, R. Guo, S. Lazebnik, Multi-scale orderless pooling of deep convolutional activation features, in: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part VII 13, Springer, 2014, pp. 392–407
2014
-
[3]
Cimpoi, S
M. Cimpoi, S. Maji, A. Vedaldi, Deep filter banks for texture recognition and segmentation, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3828–3836
2015
-
[4]
O. N. Manzari, H. Ahmadabadi, H. Kashiani, S. B. Shokouhi, A. Ayatol- lahi, Medvit: a robust vision transformer for generalized medical image classification, Computers in Biology and Medicine 157 (2023) 106791
2023
-
[5]
H. Li, X. Yue, L. Meng, Enhanced mechanisms of pooling and channel attention for deep learning feature maps, PeerJ Computer Science 8 (2022) e1161
2022
-
[6]
Z. Yu, D. Ni, S. Chen, J. Qin, S. Li, T. Wang, B. Lei, Hybrid dermoscopy image classification framework based on deep convolutional neural network and fisher vector, in: 2017 IEEE 14th international symposium on biomed- ical imaging (ISBI 2017), IEEE, 2017, pp. 301–304
2017
-
[7]
L. O. Lyra, A. E. Fabris, J. B. Florindo, A multilevel pooling scheme in convolutional neural networks for texture image recognition, Applied Soft Computing (2024) 111282doi:https://doi.org/10.1016/j.asoc.2024.111282
-
[8]
X. Wang, R. Girshick, A. Gupta, K. He, Non-local neural networks, in: Proceedings of the IEEE conference on computer vision and pattern recog- nition, 2018, pp. 7794–7803
2018
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Un- terthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., An image is worth 16x16 words: Transformers for image recognition at scale, arXiv preprint arXiv:2010.11929 (2020). 22
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
Y. Li, G. Yuan, Y. Wen, J. Hu, G. Evangelidis, S. Tulyakov, Y. Wang, J. Ren, Efficientformer: Vision transformers at mobilenet speed, Advances in Neural Information Processing Systems 35 (2022) 12934–12949
2022
-
[11]
Graham, A
B. Graham, A. El-Nouby, H. Touvron, P. Stock, A. Joulin, H. Jégou, M. Douze, Levit: a vision transformer in convnet’s clothing for faster inference, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 12259–12269
2021
-
[12]
J. Yang, R. Shi, D. Wei, Z. Liu, L. Zhao, B. Ke, H. Pfister, B. Ni, Medmnist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification, Scientific Data 10 (1) (2023) 41. doi:https://doi.org/10.1038/s41597-022-01721-8
-
[13]
X. He, S. Wang, S. Shi, X. Chu, J. Tang, X. Liu, C. Yan, J. Zhang, G. Ding, Benchmarking deep learning models and automated model design for covid-19 detection with chest ct scans, medRxiv (2021). arXiv:https://www.medrxiv.org/content/early/2021/11/04/2020.06.08.20125963.full.pdf, doi:10.1101/2020.06.08.20125963. URLhttps://www.medrxiv.org/content/early/2...
-
[14]
Tschandl, C
P. Tschandl, C. Rosendahl, H. Kittler, The ham10000 dataset, a large col- lection of multi-source dermatoscopic images of common pigmented skin lesions, Scientific data 5 (1) (2018) 1–9
2018
-
[15]
N. C. F. Codella, D. Gutman, M. E. Celebi, B. Helba, M. A. Marchetti, S. W. Dusza, A. Kalloo, K. Liopyris, N. Mishra, H. Kittler, A. Halpern, Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the inter- national skin imaging collaboration (isic) (2018). arXiv:1710.05006....
-
[16]
Zheng, J
S. Zheng, J. Lu, H. Zhao, X. Zhu, Z. Luo, Y. Wang, Y. Fu, J. Feng, T. Xiang, P. H. Torr, et al., Rethinking semantic segmentation from a 23 sequence-to-sequence perspective with transformers, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 6881–6890
2021
-
[17]
W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, L. Shao, Pyramid vision transformer: A versatile backbone for dense pre- diction without convolutions, in: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2021, pp. 568–578
2021
-
[18]
Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, B. Guo, Swin trans- former: Hierarchical vision transformer using shifted windows, in: Proceed- ings of the IEEE/CVF international conference on computer vision, 2021, pp. 10012–10022
2021
-
[19]
L. Yuan, Q. Hou, Z. Jiang, J. Feng, S. Yan, Volo: Vision outlooker for visual recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence (2022) 1–13doi:10.1109/tpami.2022.3206108. URLhttp://dx.doi.org/10.1109/TPAMI.2022.3206108
-
[20]
H. Cai, J. Li, M. Hu, C. Gan, S. Han, Efficientvit: Lightweight multi- scale attention for high-resolution dense prediction, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17302–17313
2023
-
[21]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan, A. Zisserman, Very deep convolutional networks for large- scale image recognition, arXiv preprint arXiv:1409.1556 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[22]
Z. Chen, F. Li, Y. Quan, Y. Xu, H. Ji, Deep texture recognition via exploit- ing cross-layer statistical self-similarity, in: Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2021, pp. 5231– 5240
2021
-
[23]
Scabini, K
L. Scabini, K. M. Zielinski, L. C. Ribas, W. N. Gonçalves, B. De Baets, O. M. Bruno, Radam: Texture recognition through randomized aggregated encoding of deep activation maps, Pattern Recognition 143 (2023) 109802. 24
2023
-
[24]
Z. Yang, S. Lai, X. Hong, Y. Shi, Y. Cheng, C. Qing, Dfaen: Double-order knowledge fusion and attentional encoding network for texture recognition, Expert Systems with Applications 209 (2022) 118223
2022
-
[25]
Y. Xu, F. Li, Z. Chen, J. Liang, Y. Quan, Encoding spatial distribution of convolutional features for texture representation, Advances in Neural Information Processing Systems 34 (2021) 22732–22744
2021
-
[26]
J. B. Florindo, E. E. Laureano, Boff: a bag of fuzzy deep features for texture recognition, Expert Systems with Applications 219 (2023) 119627
2023
-
[27]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recog- nition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[28]
Zhang, L
Z. Zhang, L. Zhang, L. Wang, K. Zhong, H. Huang, Lc2r-vit: Long-range cross-residual vision transformer for medical image classification, in: 2023 International Annual Conference on Complex Systems and Intelligent Sci- ence (CSIS-IAC), IEEE, 2023, pp. 445–450
2023
-
[29]
J. Liu, Y. Li, G. Cao, Y. Liu, W. Cao, Feature pyramid vision transformer for medmnist classification decathlon, in: 2022 Interna- tional Joint Conference on Neural Networks (IJCNN), 2022, pp. 1–8. doi:10.1109/IJCNN55064.2022.9892282
- [30]
-
[31]
Y. Wang, L. Zhen, J. Zhang, M. Li, L. Zhang, Z. Wang, Y. Feng, Y. Xue, X. Wang, Z. Chen, et al., Mednas: Multi-scale training-free neural architec- ture search for medical image analysis, IEEE Transactions on Evolutionary Computation (2024)
2024
- [32]
- [33]
-
[34]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in neural information processing systems 30 (2017)
2017
-
[35]
J. R. Hershey, P. A. Olsen, Approximating the kullback leibler divergence between gaussian mixture models, in: 2007 IEEE International Conference onAcoustics, SpeechandSignalProcessing-ICASSP’07, Vol.4, IEEE,2007, pp. IV–317
2007
-
[36]
Sánchez, F
J. Sánchez, F. Perronnin, T. Mensink, J. Verbeek, Image classification with the fisher vector: Theory and practice, International journal of computer vision 105 (3) (2013) 222–245
2013
-
[37]
Perronnin, J
F. Perronnin, J. Sánchez, T. Mensink, Improving the fisher kernel for large- scale image classification, in: European conference on computer vision, Springer, 2010, pp. 143–156
2010
-
[38]
R. Wightman, Pytorch image models,https://github.com/rwightman/ pytorch-image-models(2019). doi:10.5281/zenodo.4414861
- [39]
-
[40]
R. Liu, X. Wang, Q. Wu, L. Dai, X. Fang, T. Yan, J. Son, S. Tang, J. Li, Z. Gao, et al., Deepdrid: Diabetic retinopathy—grading and image quality estimation challenge, Patterns 3 (6) (2022)
2022
-
[41]
Bilic, P
P. Bilic, P. Christ, H. B. Li, E. Vorontsov, A. Ben-Cohen, G. Kaissis, A. Szeskin, C. Jacobs, G. E. H. Mamani, G. Chartrand, et al., The liver tumor segmentation benchmark (lits), Medical Image Analysis 84 (2023) 102680. 26
2023
-
[42]
X. Wang, Y. Peng, L. Lu, Z. Lu, M. Bagheri, R. M. Summers, Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2097–2106
2017
-
[43]
D. S. Kermany, M. Goldbaum, W. Cai, C. C. Valentim, H. Liang, S. L. Baxter, A. McKeown, G. Yang, X. Wu, F. Yan, et al., Identifying medical diagnoses and treatable diseases by image-based deep learning, cell 172 (5) (2018) 1122–1131
2018
-
[44]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [45]
-
[46]
B. Popović, L. Cepova, R. Cep, M. Janev, L. Krstanović, Measure of simi- larity between gmms by embedding of the parameter space that preserves kl divergence, Mathematics 9 (9) (2021). doi:10.3390/math9090957. URLhttps://www.mdpi.com/2227-7390/9/9/957
-
[47]
Cheng, S
J. Cheng, S. Tian, L. Yu, C. Gao, X. Kang, X. Ma, W. Wu, S. Liu, H. Lu, Resganet: Residual group attention network for medical image classifica- tion and segmentation, Medical Image Analysis 76 (2022) 102313
2022
-
[48]
Ryali, Y.-T
C. Ryali, Y.-T. Hu, D. Bolya, C. Wei, H. Fan, P.-Y. Huang, V. Aggarwal, A. Chowdhury, O. Poursaeed, J. Hoffman, et al., Hiera: A hierarchical vision transformer without the bells-and-whistles, in: International Con- ference on Machine Learning, PMLR, 2023, pp. 29441–29454
2023
- [49]
-
[50]
D. Qin, C. Leichner, M. Delakis, M. Fornoni, S. Luo, F. Yang, W. Wang, C. Banbury, C. Ye, B. Akin, et al., Mobilenetv4: Universal models for the mobile ecosystem, in: European Conference on Computer Vision, Springer, 2025, pp. 78–96
2025
- [51]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.