Recognition: unknown
Delayed Commitment for Representation Readiness in Stage-wise Audio-Visual Learning
Pith reviewed 2026-05-09 16:52 UTC · model grok-4.3
The pith
Stage-wise audio-visual encoders improve when premature fusion is delayed until intermediate states gain sufficient cross-layer support.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
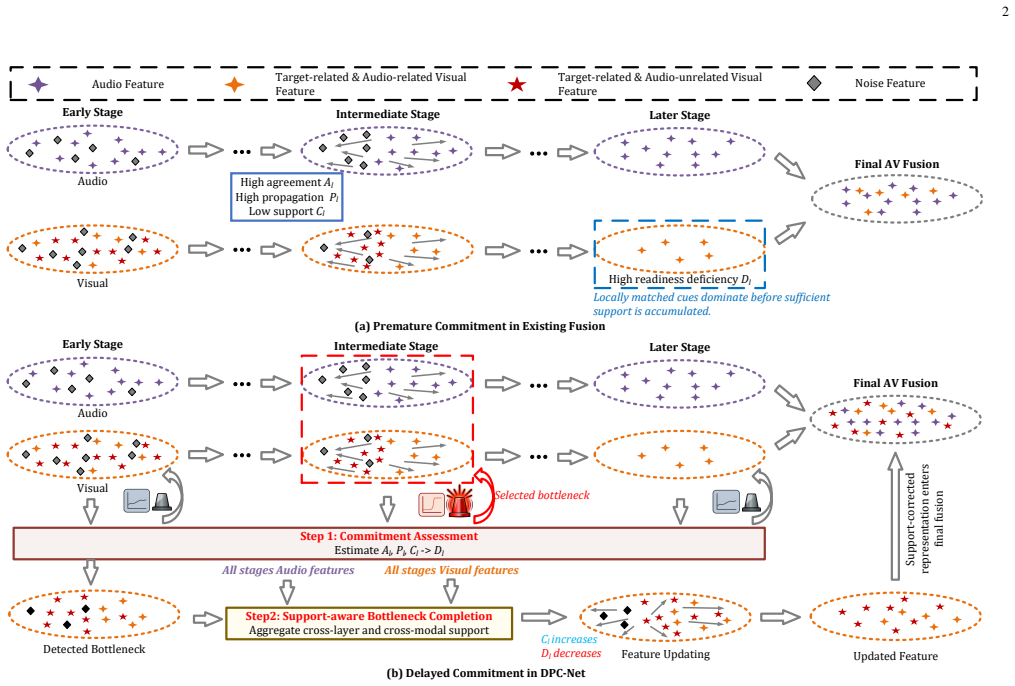
The authors claim that premature perceptual commitment occurs when an intermediate fused state lacks adequate local plausibility, propagation influence, and support insufficiency, causing later layers to receive unreliable guidance. DPC-Net estimates an observable readiness-deficiency surrogate, identifies the bottleneck stage, and performs support-aware correction with cross-layer and cross-modal evidence. This encoder-level fix produces consistent improvements on audio-visual speech separation, event localization, and speech recognition while preserving all original task-specific components and evaluation protocols.
What carries the argument
The Delayed Perceptual Commitment Network (DPC-Net), which estimates a readiness-deficiency surrogate from local plausibility, propagation influence, and support insufficiency then applies support-aware correction at the identified bottleneck.
If this is right
- The same encoder intervention yields gains across reconstruction, localization, and recognition regimes without task-specific redesign.
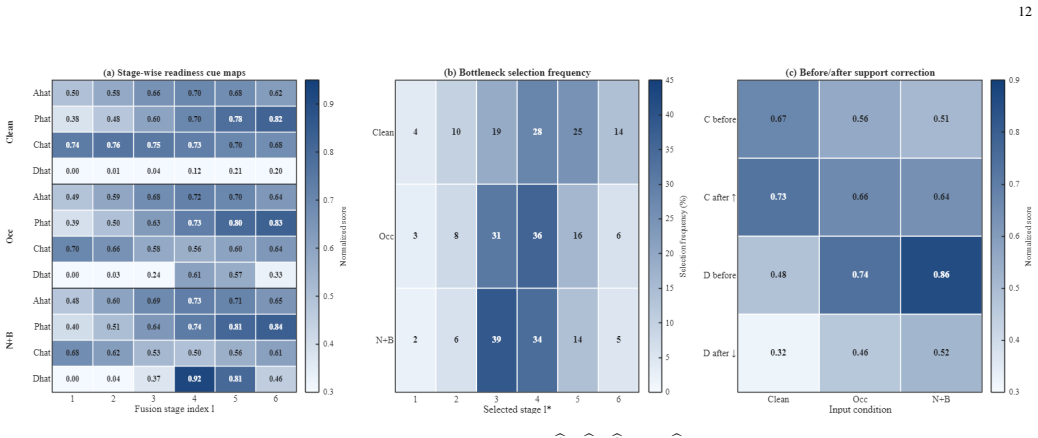
- Readiness trajectories can be tracked to show when and where bottlenecks are resolved during training.
- Component analyses confirm that both the selection of the bottleneck and the cross-evidence correction contribute to the observed improvements.
- Counterfactual tests where correction is applied at non-bottleneck stages produce smaller or no gains.
Where Pith is reading between the lines
- Similar readiness monitoring could be tested in other staged multimodal pipelines such as video-text or sensor fusion where early layers feed later ones.
- The approach points to an alternative to pure end-to-end gradient flow: explicit checks on representation support before commitment.
- One could examine whether the same surrogate works when the backbone is replaced by different layer types or when training data scale changes.
Load-bearing premise
That the readiness-deficiency surrogate built from local plausibility, propagation influence, and support insufficiency can be estimated reliably enough that correcting it at the bottleneck stage produces net performance gains without creating new instabilities.
What would settle it
A replication study in which the support-aware correction is applied at the stages flagged by the surrogate but the three audio-visual tasks show no improvement or a drop in their standard metrics such as signal-to-distortion ratio or localization accuracy would falsify the claim.
Figures




read the original abstract
Stage-wise audio-visual encoders propagate fused intermediate states across layers, making the formation of later representations depend on the readiness of earlier fusion states. Strong local audio-visual agreement provides useful correspondence evidence, yet a fused state also needs sufficient cross-layer and cross-modal support before it can reliably guide later fusion. This paper studies this issue through propagation-aware representation readiness and formulates premature perceptual commitment as a readiness-deficiency problem, where local plausibility, propagation influence, and support insufficiency jointly appear at an intermediate stage. We propose the Delayed Perceptual Commitment Network (DPC-Net), an encoder-level framework that estimates an observable readiness-deficiency surrogate, localizes the intervention-sensitive bottleneck, and applies support-aware correction with cross-layer and cross-modal evidence. DPC-Net preserves task-specific heads, losses, decoding modules, and evaluation protocols, making it applicable to different audio-visual tasks through encoder-side intervention. Experiments on audio-visual speech separation, audio-visual event localization, and audio-visual speech recognition show consistent improvements across reconstruction, localization, and recognition regimes. Further analyses on component contribution, selection criteria, counterfactual intervention, and readiness trajectories support the effectiveness of readiness-guided bottleneck correction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Delayed Perceptual Commitment Network (DPC-Net) as an encoder-level intervention for stage-wise audio-visual learning. It frames premature perceptual commitment as a readiness-deficiency problem diagnosed via an observable surrogate combining local plausibility, propagation influence, and support insufficiency. DPC-Net localizes the bottleneck and applies support-aware cross-layer/cross-modal correction while leaving task heads, losses, and evaluation protocols unchanged. Experiments across audio-visual speech separation, event localization, and speech recognition report consistent gains, with supporting analyses on component contributions, selection criteria, counterfactuals, and readiness trajectories.
Significance. If the central claim holds, the work supplies a reusable encoder-side mechanism for diagnosing and correcting representation readiness in staged multi-modal fusion without task-specific redesign. The preservation of existing heads and the provision of counterfactual and trajectory analyses are concrete strengths that could aid reproducibility and extension to other staged audio-visual pipelines.
major comments (2)
- [Experiments] Experiments section: the manuscript attributes all reported gains to readiness-guided bottleneck correction, yet provides no controlled ablation that applies the same correction module at surrogate-identified locations versus non-surrogate locations (e.g., fixed depth or random selection). Without this comparison the causal role of the readiness-deficiency surrogate remains unisolated from the general effect of adding cross-layer/cross-modal support.
- [Method] Method section: the readiness-deficiency surrogate is defined as the joint appearance of local plausibility, propagation influence, and support insufficiency, but the paper does not specify the exact functional combination or weighting used to produce the scalar surrogate value, nor does it report sensitivity of downstream localization to alternative combinations. This detail is load-bearing for claims that the surrogate reliably identifies intervention-sensitive bottlenecks.
minor comments (2)
- [Abstract] Abstract: the claim of 'consistent improvements' would be strengthened by a single sentence giving the range of relative gains or statistical significance across the three tasks.
- [Notation] Notation: ensure that symbols for the three surrogate components are introduced with explicit definitions before their first use in equations or algorithms.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The comments highlight important opportunities to strengthen the causal evidence and clarify the surrogate definition. We address each point below and will incorporate the suggested additions and clarifications in the revised manuscript.
read point-by-point responses
-
Referee: Experiments section: the manuscript attributes all reported gains to readiness-guided bottleneck correction, yet provides no controlled ablation that applies the same correction module at surrogate-identified locations versus non-surrogate locations (e.g., fixed depth or random selection). Without this comparison the causal role of the readiness-deficiency surrogate remains unisolated from the general effect of adding cross-layer/cross-modal support.
Authors: We agree that an explicit controlled ablation comparing the correction module applied at surrogate-identified bottlenecks versus non-surrogate locations (fixed depth or random selection) would more rigorously isolate the causal contribution of the readiness-deficiency surrogate. The current manuscript reports consistent gains across tasks and includes supporting analyses on component contributions, selection criteria, counterfactual intervention, and readiness trajectories. However, these do not include the precise comparison requested. We will add this ablation study to the Experiments section in the revision to address the concern directly. revision: yes
-
Referee: Method section: the readiness-deficiency surrogate is defined as the joint appearance of local plausibility, propagation influence, and support insufficiency, but the paper does not specify the exact functional combination or weighting used to produce the scalar surrogate value, nor does it report sensitivity of downstream localization to alternative combinations. This detail is load-bearing for claims that the surrogate reliably identifies intervention-sensitive bottlenecks.
Authors: We appreciate this observation. The manuscript describes the surrogate in terms of the joint appearance of the three factors but does not provide the precise functional form (e.g., conjunction, weighted sum, or product) or weighting coefficients, nor a sensitivity analysis to alternatives. We will revise the Method section to include the exact mathematical definition of the scalar surrogate and add a sensitivity analysis demonstrating robustness of the bottleneck localization to reasonable variations in combination and weighting. revision: yes
Circularity Check
No significant circularity in derivation or surrogate definition
full rationale
The paper defines a readiness-deficiency surrogate from three explicitly observable quantities (local plausibility, propagation influence, support insufficiency) and uses it to localize and correct bottlenecks in stage-wise encoders. This formulation is presented as a direct construction from data-flow properties rather than fitted to downstream task metrics or defined circularly in terms of the correction outcomes. No equations reduce a prediction to its own inputs by construction, no self-citation chains bear the central claim, and no uniqueness theorems or ansatzes are smuggled in. The method is self-contained as an encoder-side intervention that preserves task heads, with empirical gains reported separately from the surrogate's definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stage-wise audio-visual encoders propagate fused intermediate states across layers
invented entities (1)
-
DPC-Net
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep audio-visual learning: A survey,
Hao Zhu, Man-Di Luo, Rui Wang, Ai-Hua Zheng, and Ran He, “Deep audio-visual learning: A survey,”International Journal of Automation and Computing, vol. 18, no. 3, pp. 351–376, 2021
2021
-
[2]
Deep learning for visual speech analysis: A survey,
Changchong Sheng, Gangyao Kuang, Liang Bai, Chenping Hou, Yulan Guo, Xin Xu, Matti Pietikainen, and Li Liu, “Deep learning for visual speech analysis: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 09, pp. 6001–6022, 2024
2024
-
[3]
Multimodal alignment and fusion: A survey,
Songtao Li and Hao Tang, “Multimodal alignment and fusion: A survey,” International Journal of Computer Vision, vol. 134, pp. 103, 2026
2026
-
[4]
Deep audio-visual speech recognition,
T Afouras, J Chung, A Senior, O Vinyals, and A Zisserman, “Deep audio-visual speech recognition,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 12, 2018
2018
-
[5]
Looking into your speech: Learning cross-modal affinity for audio-visual speech separation,
Jiyoung Lee, Soo-Whan Chung, Sunok Kim, Hong-Goo Kang, and Kwanghoon Sohn, “Looking into your speech: Learning cross-modal affinity for audio-visual speech separation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 1336–1345
2021
-
[6]
Audio-visual event localization via recursive fusion by joint co-attention,
Bin Duan, Hao Tang, Wei Wang, Ziliang Zong, Guowei Yang, and Yan Yan, “Audio-visual event localization via recursive fusion by joint co-attention,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2021, pp. 4013–4022
2021
-
[7]
Mlca-avsr: Multi- layer cross attention fusion based audio-visual speech recognition,
He Wang, Pengcheng Guo, Pan Zhou, and Lei Xie, “Mlca-avsr: Multi- layer cross attention fusion based audio-visual speech recognition,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 8150–8154
2024
-
[8]
Learning event-specific localization preferences for audio- visual event localization,
Shiping Ge, Zhiwei Jiang, Yafeng Yin, Cong Wang, Zifeng Cheng, and Qing Gu, “Learning event-specific localization preferences for audio- visual event localization,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 3446–3454
2023
-
[9]
Unified cross- modal attention: robust audio-visual speech recognition and beyond,
Jiahong Li, Chenda Li, Yifei Wu, and Yanmin Qian, “Unified cross- modal attention: robust audio-visual speech recognition and beyond,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 1941–1953, 2024
1941
-
[10]
Iianet: an intra- and inter-modality attention network for audio-visual speech separation,
Kai Li, Runxuan Yang, Fuchun Sun, and Xiaolin Hu, “Iianet: an intra- and inter-modality attention network for audio-visual speech separation,” inProceedings of the 41st International Conference on Machine Learn- ing, 2024, pp. 29181–29200
2024
-
[11]
Vision transformers are parameter-efficient audio-visual learners,
Yan-Bo Lin, Yi-Lin Sung, Jie Lei, Mohit Bansal, and Gedas Bertasius, “Vision transformers are parameter-efficient audio-visual learners,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2299–2309
2023
-
[12]
Mixtures of experts for audio-visual learning,
Ying Cheng, Yang Li, Junjie He, and Rui Feng, “Mixtures of experts for audio-visual learning,”Advances in Neural Information Processing Systems, vol. 37, pp. 219–243, 2024
2024
-
[13]
Robust audio-visual segmentation via audio-guided visual convergent alignment,
Chen Liu, Peike Li, Liying Yang, Dadong Wang, Lincheng Li, and Xin Yu, “Robust audio-visual segmentation via audio-guided visual convergent alignment,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 28922–28931
2025
-
[14]
Rethink cross-modal fusion in weakly-supervised audio-visual video parsing,
Yating Xu, Conghui Hu, and Gim Hee Lee, “Rethink cross-modal fusion in weakly-supervised audio-visual video parsing,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 5615–5624
2024
-
[15]
Positive sample propagation along the audio-visual event line,
Jinxing Zhou, Liang Zheng, Yiran Zhong, Shijie Hao, and Meng Wang, “Positive sample propagation along the audio-visual event line,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8436–8444
2021
-
[16]
Dynamic cross attention for audio-visual person verification,
R Gnana Praveen and Jahangir Alam, “Dynamic cross attention for audio-visual person verification,” in2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG). IEEE, 2024, pp. 1–5
2024
-
[17]
Avs-mamba: Exploring temporal and multi-modal mamba for audio-visual segmentation,
Sitong Gong, Yunzhi Zhuge, Lu Zhang, Yifan Wang, Pingping Zhang, Lijun Wang, and Huchuan Lu, “Avs-mamba: Exploring temporal and multi-modal mamba for audio-visual segmentation,”IEEE Transactions on Multimedia, 2025
2025
-
[18]
Bayesian causal inference: A unifying neuroscience theory,
Ladan Shams and Ulrik Beierholm, “Bayesian causal inference: A unifying neuroscience theory,”Neuroscience & Biobehavioral Reviews, vol. 137, pp. 104619, 2022
2022
-
[19]
Older adults preserve audiovisual integration through enhanced cortical activations, not by recruiting new regions,
Samuel A Jones and Uta Noppeney, “Older adults preserve audiovisual integration through enhanced cortical activations, not by recruiting new regions,”PLoS Biology, vol. 22, no. 2, pp. e3002494, 2024
2024
-
[20]
Causal inference in multisensory perception,
Konrad P K ¨ording, Ulrik Beierholm, Wei Ji Ma, Steven Quartz, Joshua B Tenenbaum, and Ladan Shams, “Causal inference in multisensory perception,”PLoS one, vol. 2, no. 9, pp. e943, 2007
2007
-
[21]
Cortical hierarchies perform bayesian causal inference in multisensory perception,
Tim Rohe and Uta Noppeney, “Cortical hierarchies perform bayesian causal inference in multisensory perception,”PLoS biology, vol. 13, no. 2, pp. e1002073, 2015
2015
-
[22]
Neural processing of asynchronous audiovisual speech perception,
Ryan A Stevenson, Nicholas A Altieri, Sunah Kim, David B Pisoni, and Thomas W James, “Neural processing of asynchronous audiovisual speech perception,”Neuroimage, vol. 49, no. 4, pp. 3308–3318, 2010
2010
-
[23]
The neural dynamics of hierarchical bayesian causal inference in multisensory perception,
Tim Rohe, Ann-Christine Ehlis, and Uta Noppeney, “The neural dynamics of hierarchical bayesian causal inference in multisensory perception,”Nature communications, vol. 10, no. 1, pp. 1907, 2019
1907
-
[24]
A causal inference model explains perception of the mcgurk effect and other incongruent audiovisual speech,
John F Magnotti and Michael S Beauchamp, “A causal inference model explains perception of the mcgurk effect and other incongruent audiovisual speech,”PLoS computational biology, vol. 13, no. 2, pp. e1005229, 2017
2017
-
[25]
Audio-visual event localization in unconstrained videos,
Yapeng Tian, Jing Shi, Bochen Li, Zhiyao Duan, and Chenliang Xu, “Audio-visual event localization in unconstrained videos,” inProceed- ings of the European conference on computer vision (ECCV), 2018, pp. 247–263
2018
-
[26]
End-to-end audiovisual speech recognition,
Stavros Petridis, Themos Stafylakis, Pingehuan Ma, Feipeng Cai, Geor- gios Tzimiropoulos, and Maja Pantic, “End-to-end audiovisual speech recognition,” inICASSP 2018-2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 6548–6552. 13
2018
-
[27]
Looking to listen at the cocktail party: a speaker-independent audio- visual model for speech separation,
Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T Freeman, and Michael Rubinstein, “Looking to listen at the cocktail party: a speaker-independent audio- visual model for speech separation,”ACM Transactions on Graphics (TOG), vol. 37, no. 4, pp. 1–11, 2018
2018
-
[28]
Dual attention matching for audio-visual event localization,
Yu Wu, Linchao Zhu, Yan Yan, and Yi Yang, “Dual attention matching for audio-visual event localization,” in2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE Computer Society, 2019, pp. 6291–6299
2019
-
[29]
Prompt image to watch and hear: Multimodal prompting for parameter- efficient audio-visual learning,
Kai Wang, Shentong Mo, Yapeng Tian, and Dimitrios Hatzinakos, “Prompt image to watch and hear: Multimodal prompting for parameter- efficient audio-visual learning,” in36th British Machine Vision Confer- ence (BMVC). 2025, BMV A
2025
-
[30]
Contribution-aware dynamic multi-modal balance for audio-visual speech separation,
Xinmeng Xu, Weiping Tu, Yuhong Yang, Jizhen Li, Yiqun Zhang, and Hongyang Chen, “Contribution-aware dynamic multi-modal balance for audio-visual speech separation,”IEEE Transactions on Multimedia, 2026
2026
-
[31]
Efficient audio–visual information fusion using encoding pace synchronization for audio–visual speech separation,
Xinmeng Xu, Weiping Tu, and Yuhong Yang, “Efficient audio–visual information fusion using encoding pace synchronization for audio–visual speech separation,”Information Fusion, vol. 115, pp. 102749, 2025
2025
-
[32]
Facefilter: Audio-visual speech separation using still images,
Soo-Whan Chung, Soyeon Choe, Joon Son Chung, and Hong-Goo Kang, “Facefilter: Audio-visual speech separation using still images,” inProc. Interspeech 2020, 2020, pp. 3481–3485
2020
-
[33]
Visualvoice: Audio-visual speech separation with cross-modal consistency,
Ruohan Gao and Kristen Grauman, “Visualvoice: Audio-visual speech separation with cross-modal consistency,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 15495–15505
2021
-
[34]
Reliability-based large-vocabulary audio-visual speech recognition,
Wentao Yu, Steffen Zeiler, and Dorothea Kolossa, “Reliability-based large-vocabulary audio-visual speech recognition,”Sensors, vol. 22, no. 15, 2022
2022
-
[35]
c 2av-tse: Context and confidence-aware audio visual target speaker extraction,
Wenxuan Wu, Xueyuan Chen, Shuai Wang, Jiadong Wang, Lingwei Meng, Xixin Wu, Helen Meng, and Haizhou Li, “c 2av-tse: Context and confidence-aware audio visual target speaker extraction,”IEEE Journal of Selected Topics in Signal Processing, vol. 19, no. 4, pp. 646–657, 2025
2025
-
[36]
Cross-modal prompts: Adapting large pre-trained models for audio-visual downstream tasks,
Haoyi Duan, Yan Xia, Zhou Mingze, Li Tang, Jieming Zhu, and Zhou Zhao, “Cross-modal prompts: Adapting large pre-trained models for audio-visual downstream tasks,” inAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds. 2023, vol. 36, pp. 56075–56094, Curran Associates, Inc
2023
-
[37]
Towards efficient audio-visual learners via empowering pre-trained vision transformers with cross-modal adaptation,
Kai Wang, Yapeng Tian, and Dimitrios Hatzinakos, “Towards efficient audio-visual learners via empowering pre-trained vision transformers with cross-modal adaptation,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2024, pp. 1837–1846
2024
-
[38]
Progressive homeostatic and plastic prompt tuning for audio-visual multi-task incremental learning,
Jiong Yin, Liang Li, Jiehua Zhang, Yuhan Gao, Chenggang Yan, and Xichun Sheng, “Progressive homeostatic and plastic prompt tuning for audio-visual multi-task incremental learning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 2022–2033
2025
-
[39]
Causal inference and temporal predictions in audiovisual perception of speech and music,
Uta Noppeney and Hwee Ling Lee, “Causal inference and temporal predictions in audiovisual perception of speech and music,”Annals of the New York Academy of Sciences, vol. 1423, no. 1, pp. 102–116, 2018
2018
-
[40]
Causal inference in the multisensory brain,
Yinan Cao, Christopher Summerfield, Hame Park, Bruno Lucio Gior- dano, and Christoph Kayser, “Causal inference in the multisensory brain,”Neuron, vol. 102, no. 5, pp. 1076–1087, 2019
2019
-
[41]
Reliability-weighted integration of audiovisual signals can be modulated by top-down attention,
Uta Noppeney and Tim Rohe, “Reliability-weighted integration of audiovisual signals can be modulated by top-down attention,”eNeuro, vol. 5, no. 1, pp. e0315–17, 2018
2018
-
[42]
The role of conflict processing in multisensory perception: behavioural and elec- troencephalography evidence,
Adri `a Marly, Arek Yazdjian, and Salvador Soto-Faraco, “The role of conflict processing in multisensory perception: behavioural and elec- troencephalography evidence,”Philosophical Transactions of the Royal Society B: Biological Sciences, vol. 378, no. 1886, 2023
2023
-
[43]
Explicit estimation of magni- tude and phase spectra in parallel for high-quality speech enhancement,
Ye-Xin Lu, Yang Ai, and Zhen-Hua Ling, “Explicit estimation of magni- tude and phase spectra in parallel for high-quality speech enhancement,” Neural Networks, vol. 189, pp. 107562, 2025
2025
-
[44]
V oxceleb2: Deep speaker recognition,
Joon Son Chung, Arsha Nagrani, and Andrew Zisserman, “V oxceleb2: Deep speaker recognition,” inInterspeech 2018, 2018, pp. 1086–1090
2018
-
[45]
Av-crossnet: An audiovisual complex spectral mapping network for speech separation by leveraging narrow- and cross- band modeling,
Vahid Ahmadi Kalkhorani, Cheng Yu, Anurag Kumar, Ke Tan, Buye Xu, and DeLiang Wang, “Av-crossnet: An audiovisual complex spectral mapping network for speech separation by leveraging narrow- and cross- band modeling,”IEEE Journal of Selected Topics in Signal Processing, vol. 19, no. 4, pp. 685–694, 2025
2025
-
[46]
Audio set: An ontology and human-labeled dataset for audio events,
Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 776–780
2017
-
[47]
Cross-modal background suppression for audio-visual event localization,
Yan Xia and Zhou Zhao, “Cross-modal background suppression for audio-visual event localization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 19989–19998
2022
-
[48]
Unified cross- modal attention: Robust audio-visual speech recognition and beyond,
Jiahong Li, Chenda Li, Yifei Wu, and Yanmin Qian, “Unified cross- modal attention: Robust audio-visual speech recognition and beyond,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 1941–1953, 2024
1941
-
[49]
Combining residual networks with lstms for lipreading,
Themos Stafylakis and Georgios Tzimiropoulos, “Combining residual networks with lstms for lipreading,” inInterspeech 2017, 2017, pp. 3652–3656
2017
-
[50]
Deep residual learning for image recognition,
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
2016
-
[51]
Branch- former: Parallel MLP-attention architectures to capture local and global context for speech recognition and understanding,
Yifan Peng, Siddharth Dalmia, Ian Lane, and Shinji Watanabe, “Branch- former: Parallel MLP-attention architectures to capture local and global context for speech recognition and understanding,” inProceedings of the 39th International Conference on Machine Learning, Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato...
2022
-
[52]
Mlca-avsr: Multi- layer cross attention fusion based audio-visual speech recognition,
He Wang, Pengcheng Guo, Pan Zhou, and Lei Xie, “Mlca-avsr: Multi- layer cross attention fusion based audio-visual speech recognition,” in ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 8150–8154
2024
-
[53]
The npu-aslp system for audio-visual speech recognition in misp 2022 challenge,
Pengcheng Guo, He Wang, Bingshen Mu, Ao Zhang, and Peikun Chen, “The npu-aslp system for audio-visual speech recognition in misp 2022 challenge,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–2
2022
-
[54]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[55]
Time domain audio visual speech separation,
Jian Wu, Yong Xu, Shi-Xiong Zhang, Lian-Wu Chen, Meng Yu, Lei Xie, and Dong Yu, “Time domain audio visual speech separation,” in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2019, pp. 667–673
2019
-
[56]
Audio-visual speech separation in noisy environments with a lightweight iterative model,
H ´ector Martel, Julius Richter, Kai Li, Xiaolin Hu, and Timo Gerk- mann, “Audio-visual speech separation in noisy environments with a lightweight iterative model,” inInterspeech 2023, 2023, pp. 1673–1677
2023
-
[57]
RTFS-Net: Recurrent Time- Frequency Modelling for Efficient Audio-Visual Speech Separation,
Samuel Pegg, Kai Li, and Xiaolin Hu, “RTFS-Net: Recurrent Time- Frequency Modelling for Efficient Audio-Visual Speech Separation,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[58]
Time-domain audio-visual speech separation on low quality videos,
Yifei Wu, Chenda Li, Jinfeng Bai, Zhongqin Wu, and Yanmin Qian, “Time-domain audio-visual speech separation on low quality videos,” inICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 256–260
2022
-
[59]
LRS3-TED: a large- scale dataset for visual speech recognition,
Triantafyllos Afouras, Joon Son Chung, and Andrew Zisserman, “LRS3- TED: a large-scale dataset for visual speech recognition,”arXiv preprint arXiv: 1809.00496, 2018
-
[60]
Im- proving Visual Speech Enhancement Network by Learning Audio-visual Affinity with Multi-head Attention,
Xinmeng Xu, Yang Wang, Jie Jia, Binbin Chen, and Dejun Li, “Im- proving Visual Speech Enhancement Network by Learning Audio-visual Affinity with Multi-head Attention,” inProc. Interspeech 2022, 2022, pp. 971–975
2022
-
[61]
Ravss: Robust audio-visual speech separation in multi-speaker scenarios with missing visual cues,
Tianrui Pan, Jie Liu, Bohan Wang, Jie Tang, and Gangshan Wu, “Ravss: Robust audio-visual speech separation in multi-speaker scenarios with missing visual cues,” inProceedings of the 32nd ACM International Conference on Multimedia, New York, NY , USA, 2024, MM ’24, p. 4748–4756, Association for Computing Machinery
2024
-
[62]
Dual perspective network for audio-visual event localization,
Varshanth Rao, Md Ibrahim Khalil, Haoda Li, Peng Dai, and Juwei Lu, “Dual perspective network for audio-visual event localization,” in European Conference on Computer Vision. Springer, 2022, pp. 689–704
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.