Recognition: unknown
Missingness-aware Data Imputation via AI-powered Bayesian Generative Modeling
Pith reviewed 2026-05-09 17:23 UTC · model grok-4.3
The pith
MissBGM imputes missing data by jointly modeling the data-generating process and the missingness mechanism inside a Bayesian generative framework, yielding consistent estimates with full posterior uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MissBGM is a Bayesian generative model that explicitly and jointly represents the data-generating distribution and the missingness mechanism. It employs a stochastic optimization framework with alternating updates among missing values, model parameters, and latent variables. The resulting posterior supplies principled uncertainty quantification over imputations, and missing-value estimates converge consistently under mild assumptions.
What carries the argument
MissBGM, the joint Bayesian generative model for data and missingness that is trained by alternating stochastic updates among missing entries, parameters, and latents.
If this is right
- Imputations carry calibrated uncertainty that can be propagated into subsequent statistical or machine-learning tasks.
- Explicit modeling of the missingness mechanism reduces bias that arises when missingness is ignored or treated implicitly.
- The alternating stochastic optimization procedure scales the approach to large datasets while retaining Bayesian rigor.
- Consistent convergence guarantees support reliable use in high-stakes applications where point estimates alone are insufficient.
Where Pith is reading between the lines
- The same joint-modeling strategy could be applied to other incomplete-data problems such as causal inference or time-series forecasting by swapping in an appropriate generative architecture.
- If the mild convergence assumptions hold in practice, MissBGM provides a template for turning any sufficiently expressive generative model into a missingness-aware imputer without ad-hoc post-processing.
- Downstream users could test sensitivity by comparing posteriors obtained under different assumed missingness mechanisms within the same framework.
Load-bearing premise
The chosen generative model class must be able to represent both the true data distribution and the missingness mechanism accurately enough for the posterior to be useful.
What would settle it
In simulated data drawn from a known distribution with a known missingness process, the imputed values fail to converge to the true missing entries or the reported posterior intervals fail to cover the true values at the nominal rate as the sample size grows.
Figures


read the original abstract
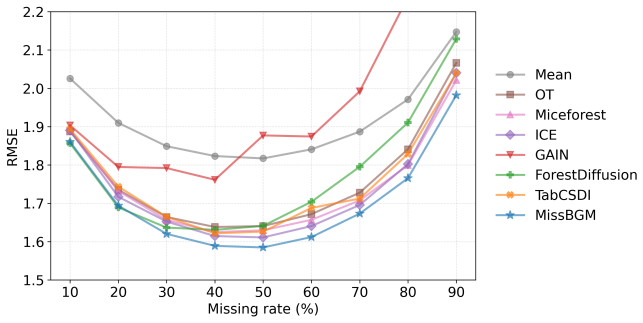
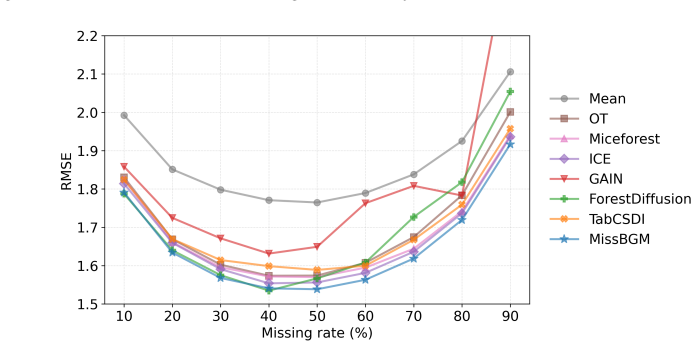
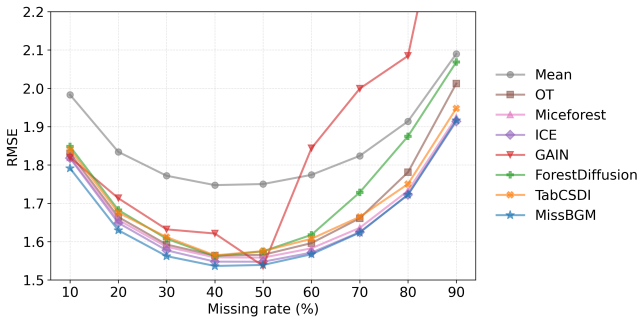
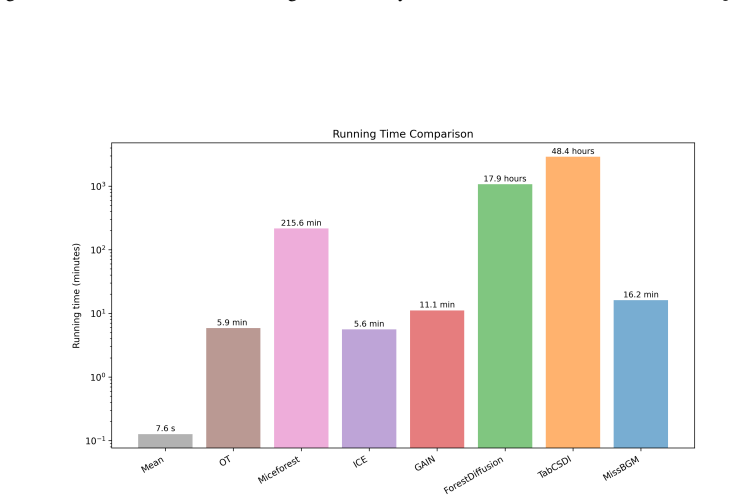
Missing data imputation remains a fundamental challenge in modern data science, especially when uncertainty quantification is essential. In this work, we propose MissBGM, an AI-powered missing data imputation method via Bayesian generative modeling that bridges the expressive flexibility of neural networks with the statistical rigor of Bayesian inference. Unlike existing methods that often focus on point estimates or treat the missingness mechanism implicitly, MissBGM explicitly and jointly models the data-generating and missingness mechanisms, providing principled posterior uncertainty over imputations rather than a single point estimate. We develop a stochastic optimization framework with alternating updates among missing values, model parameters, and latent variables until convergence. Our theoretical analysis shows that estimates of missing values from MissBGM converge consistently under mild assumptions. Empirically, we demonstrate that MissBGM achieves superior performance over traditional imputers and recent neural network-based methods across extensive experimental settings. These results establish MissBGM as a principled and scalable solution for modern missing data imputation. The code for MissBGM is open sourced at https://github.com/liuq-lab/MissBGM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MissBGM, a Bayesian generative modeling framework for missing-data imputation that uses neural networks to jointly model the data-generating distribution and the missingness mechanism. It supplies posterior uncertainty over imputations, employs a stochastic optimization procedure with alternating updates on missing values, model parameters, and latent variables, and asserts that the resulting missing-value estimates converge consistently under mild assumptions. The paper also reports empirical superiority over traditional imputers and recent neural-network methods across extensive settings and releases open-source code.
Significance. If the consistency result can be placed on a rigorous footing and the empirical comparisons include quantitative baselines, error bars, and ablation studies, the work would constitute a useful contribution by combining the flexibility of deep generative models with explicit Bayesian treatment of both data and missingness mechanisms, thereby delivering principled uncertainty quantification for imputations in complex data regimes.
major comments (1)
- [Abstract / Theoretical Analysis] Abstract / Theoretical Analysis: the central claim that 'estimates of missing values from MissBGM converge consistently under mild assumptions' is load-bearing. The described stochastic optimization performs alternating updates on neural-network parameters (hence a non-convex objective) together with missing values and latent variables. The manuscript does not indicate whether the mild assumptions include identifiability of the joint model, global optimality of the optimizer, or conditions under which local solutions still produce consistent imputations. Without such clarification or an accompanying proof sketch, the consistency guarantee cannot be assessed.
minor comments (2)
- The abstract states empirical superiority but supplies no quantitative details, baseline list, or error-bar information; the full manuscript should ensure that all tables and figures report these quantities explicitly.
- Notation for the joint model (data likelihood, missingness model, and variational or MCMC approximation) should be introduced with a single, self-contained diagram or equation block early in the methods section to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment regarding the theoretical consistency claim below.
read point-by-point responses
-
Referee: [Abstract / Theoretical Analysis] Abstract / Theoretical Analysis: the central claim that 'estimates of missing values from MissBGM converge consistently under mild assumptions' is load-bearing. The described stochastic optimization performs alternating updates on neural-network parameters (hence a non-convex objective) together with missing values and latent variables. The manuscript does not indicate whether the mild assumptions include identifiability of the joint model, global optimality of the optimizer, or conditions under which local solutions still produce consistent imputations. Without such clarification or an accompanying proof sketch, the consistency guarantee cannot be assessed.
Authors: We acknowledge that the current manuscript does not provide sufficient detail on the precise conditions under which the consistency result holds, particularly given the non-convex nature of the alternating stochastic optimization. In the revised version, we will expand the theoretical analysis section to explicitly list the mild assumptions (including identifiability of the joint data-and-missingness model) and supply a proof sketch showing that the procedure yields consistent imputations at stationary points of the objective, without requiring global optimality. This addition will make the guarantee assessable while preserving the original claims. revision: yes
Circularity Check
No significant circularity; consistency claim rests on external mild assumptions
full rationale
The paper presents its core result—that MissBGM missing-value estimates converge consistently—as the output of a separate theoretical analysis under mild assumptions, without any quoted derivation, equation, or self-citation that reduces the target quantity to a fitted parameter or input defined by the same model. The stochastic alternating optimization is described at a high level but no load-bearing step equates the consistency guarantee to the model's own parameterization or to a prior self-citation. This matches the default expectation for non-circular papers; the derivation chain remains self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network parameters
axioms (1)
- domain assumption Mild assumptions for consistent convergence of missing-value estimates
Reference graph
Works this paper leans on
-
[1]
ISBN 9780471087052. doi: 10.1002/9780470316696. URLhttps://doi.org/10.1002/9780470316696. 10 Stef Van Buuren and Karin Groothuis-Oudshoorn. mice: Multivariate imputation by chained equations in r.Journal of statistical software, 45:1–67,
-
[2]
Niels Bruun Ipsen, Pierre-Alexandre Mattei, and Jes Frellsen. not-miwae: Deep generative modelling with missing not at random data.arXiv preprint arXiv:2006.12871,
- [3]
-
[4]
Zarin Tahia Hossain and Mostafa Milani. Beyond accuracy: An empirical study of uncertainty estimation in imputation.arXiv preprint arXiv:2511.21607,
-
[5]
Variational autoencoder with arbitrary condition- ing.arXiv preprint arXiv:1806.02382,
Oleg Ivanov, Michael Figurnov, and Dmitry Vetrov. Variational autoencoder with arbitrary condition- ing.arXiv preprint arXiv:1806.02382,
-
[6]
11 Steven Cheng-Xian Li, Bo Jiang, and Benjamin Marlin. Misgan: Learning from incomplete data with generative adversarial networks.arXiv preprint arXiv:1902.09599,
-
[7]
Vaes in the presence of missing data
Mark Collier, Alfredo Nazabal, and Christopher KI Williams. Vaes in the presence of missing data. arXiv preprint arXiv:2006.05301,
-
[8]
Journal of the American Statistical Association , author =
Qiao Liu and Wing Hung Wong. A bayesian generative modeling approach for arbitrary conditional inference.arXiv preprint arXiv:2601.05355, 2026a. Qiao Liu and Wing Hung Wong. An ai-powered bayesian generative modeling approach for causal inference in observational studies.Journal of the American Statistical Association, 0(ja):1–20, 2026b. doi: 10.1080/0162...
-
[9]
Bayesian neural networks: An introduction and survey
Ethan Goan and Clinton Fookes. Bayesian neural networks: An introduction and survey. InCase Studies in Applied Bayesian Data Science: CIRM Jean-Morlet Chair, Fall 2018, pages 45–87. Springer,
2018
-
[10]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Joshua V Dillon, Ian Langmore, Dustin Tran, Eugene Brevdo, Srinivas Vasudevan, Dave Moore, Brian Patton, Alex Alemi, Matt Hoffman, and Rif A Saurous. Tensorflow distributions.arXiv preprint arXiv:1711.10604,
-
[12]
All datasets are obtained from the UCI Machine Learning Repository
Table 5: Summary of the four real-world tabular datasets used in our benchmark. All datasets are obtained from the UCI Machine Learning Repository. The reported #Samples and #Features are after dropping ID columns, target columns, and rows with native missing values where applicable. Dataset UCI ID #Samples #Features Domain Wine 109 178 13 Chemistry / agr...
2024
-
[13]
E.3 Alternating stochastic optimization MissBGM is trained by blockwise stochastic optimization on mini-batches
Empirically, this warm start improves optimization stability, speeds up convergence of the alternating updates for (Z,X mis, θ, ϕ), and helps avoid poor local solutions that occur more often with purely random initialization. E.3 Alternating stochastic optimization MissBGM is trained by blockwise stochastic optimization on mini-batches. The procedure alte...
2014
-
[14]
configs/MNAR_oracle.yaml
E.4 Posterior inference and uncertainty quantification Inference on the training data.In our imputation setting, posterior inference is most often performed on the same incomplete dataset used for training. In this case, no additional optimization is required. The alternating stochastic optimization already returns a completed data matrix at convergence, ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.