Multi-Scale Gaussian-Language Map for Zero-shot Embodied Navigation and Reasoning
Pith reviewed 2026-05-10 15:24 UTC · model grok-4.3
The pith
GLMap pairs natural language descriptions with 3D Gaussians in each semantic unit to support zero-shot embodied navigation and reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
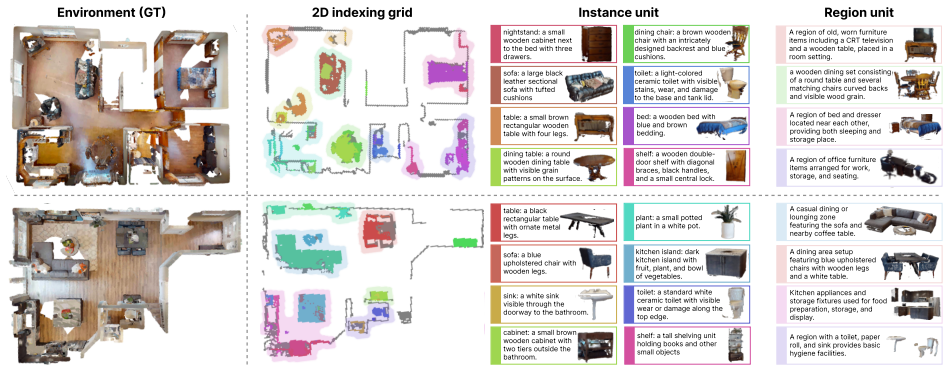
The multi-scale Gaussian-Language Map introduces explicit geometry, multi-scale semantics covering instance and region concepts, and a dual-modality interface where each semantic unit jointly stores a natural language description and a 3D Gaussian representation. The 3D Gaussians support compact storage and fast rendering of task-relevant images via Gaussian splatting. An analytical Gaussian Estimator derives the Gaussian parameters from dense point clouds without gradient-based optimization or additional training, enabling efficient incremental construction and zero-shot compatibility with large-model methods that improves results on ObjectNav, InstNav, and SQA tasks.
What carries the argument
Dual-modality semantic unit that stores a natural language description together with a 3D Gaussian representation, supported by the analytical Gaussian Estimator for parameter derivation from point clouds.
If this is right
- The map supports efficient incremental construction directly from dense point clouds without optimization steps.
- Task-relevant images can be rendered quickly using Gaussian splatting for use in navigation and reasoning.
- Zero-shot compatibility allows direct integration with large models without additional feature projection training.
- Performance gains appear on target navigation and contextual reasoning tasks in standard benchmarks.
Where Pith is reading between the lines
- The structure could support real-time map updates in changing environments by avoiding heavy retraining.
- Multi-scale language labels might help with hierarchical task planning that combines object-level and region-level understanding.
- The renderable Gaussians could extend to simulation-based testing of robot behaviors before physical deployment.
Load-bearing premise
The dual-modality interface and analytical Gaussian Estimator enable seamless zero-shot compatibility with large models and effective incremental construction without gradient-based optimization or additional feature projection training.
What would settle it
An experiment where GLMap requires extra training to work with large models or shows no improvement in success rates over prior semantic mapping methods on the ObjectNav, InstNav, or SQA benchmarks would falsify the central claim.
Figures



read the original abstract
Understanding the geometric and semantic structure of environments is essential for embodied navigation and reasoning. Existing semantic mapping methods trade off between explicit geometry and multi-scale semantics, and lack a native interface for large models, thus requiring additional training of feature projection for semantic alignment. To this end, we propose the multi-scale Gaussian-Language Map (GLMap), which introduces three key designs: (1) explicit geometry, (2) multi-scale semantics covering both instance and region concepts, and (3) a dual-modality interface where each semantic unit jointly stores a natural language description and a 3D Gaussian representation. The 3D Gaussians enable compact storage and fast rendering of task-relevant images via Gaussian splatting. To enable efficient incremental construction, we further propose a Gaussian Estimator that analytically derives Gaussian parameters from dense point clouds without gradient-based optimization. Experiments on ObjectNav, InstNav, and SQA tasks show that GLMap effectively enhances target navigation and contextual reasoning, while remaining compatible with large-model-based methods in a zero-shot manner. The code is available at https://github.com/sx-zhang/GLMap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the multi-scale Gaussian-Language Map (GLMap) for zero-shot embodied navigation and reasoning. It combines explicit 3D geometry with multi-scale semantics (both instance-level and region-level concepts) through a dual-modality interface that stores natural language descriptions alongside 3D Gaussian representations for each semantic unit. The 3D Gaussians facilitate compact storage and rapid rendering of task-relevant images using Gaussian splatting. An analytical Gaussian Estimator is introduced to derive Gaussian parameters directly from dense point clouds without requiring gradient-based optimization. The approach is evaluated on ObjectNav, InstNav, and SQA tasks, claiming improved performance and zero-shot compatibility with large models.
Significance. If the central claims hold, particularly the truly analytical and training-free construction of multi-scale semantics, this could represent a meaningful advance in semantic mapping for embodied AI. It potentially resolves the trade-off between geometric fidelity and semantic richness while providing a direct interface to large language and vision models. The emphasis on incremental construction and efficiency via splatting is a strength, and the open-sourcing of code is noted positively.
major comments (1)
- [Gaussian Estimator subsection (Method)] The claim that the Gaussian Estimator analytically derives both geometry and multi-scale semantic labels (instance and region) from point clouds without any gradient optimization or additional training is load-bearing for the zero-shot compatibility. The skeptic's concern is valid here: if multi-scale assignment involves any form of clustering, nearest-neighbor matching to external segmentations, or unstated processing steps on the point cloud, this would introduce dependencies that undermine the 'no additional feature projection training' and incremental zero-shot claims. The manuscript must provide the exact procedure, including how language descriptions are assigned at multiple scales, to confirm it is purely analytical.
minor comments (2)
- [Abstract] The abstract states positive results on ObjectNav, InstNav, and SQA but lacks any quantitative metrics, baselines, or error bars. This makes it difficult to assess the magnitude of improvements.
- [Experiments] Ensure all experimental comparisons report statistical significance, multiple runs, or ablation studies to support claims of effectiveness over baselines.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback on our manuscript. We address the major comment below and will revise the paper to enhance clarity on the Gaussian Estimator procedure while preserving the core claims.
read point-by-point responses
-
Referee: The claim that the Gaussian Estimator analytically derives both geometry and multi-scale semantic labels (instance and region) from point clouds without any gradient optimization or additional training is load-bearing for the zero-shot compatibility. The skeptic's concern is valid here: if multi-scale assignment involves any form of clustering, nearest-neighbor matching to external segmentations, or unstated processing steps on the point cloud, this would introduce dependencies that undermine the 'no additional feature projection training' and incremental zero-shot claims. The manuscript must provide the exact procedure, including how language descriptions are assigned at multiple scales, to confirm it is purely analytical.
Authors: We appreciate the referee's emphasis on this point, as the analytical nature of the estimator is central to our zero-shot claims. The Gaussian Estimator computes geometric parameters (means, covariances) directly via closed-form statistics on local point neighborhoods from the dense point cloud, with no optimization. Multi-scale semantics are derived analytically as follows: instance-level units are formed by grouping points according to provided instance masks from the input data (without any learned projection or training), while region-level units are obtained through hierarchical spatial partitioning based on point density and proximity thresholds. Language descriptions for each unit are generated zero-shot by feeding aggregated point attributes and spatial context into a frozen large language model, with no fine-tuning or additional feature alignment steps. This process avoids clustering algorithms, external segmentations beyond input, and any gradient-based components. To fully address the concern and improve accessibility, we will expand the Gaussian Estimator subsection with explicit step-by-step equations, pseudocode, and a diagram illustrating the multi-scale assignment in the revised manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes a new architecture (GLMap) with three explicit designs and an analytical Gaussian Estimator that derives parameters from point clouds without optimization or training. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described claims that reduce outputs to inputs by construction. The central claims rest on the proposed dual-modality interface and incremental construction method, which are presented as independent contributions rather than self-referential. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Gaussian splatting produces fast, compact renderings of 3D scenes from learned parameters
- domain assumption Dense point clouds contain sufficient information to analytically derive Gaussian parameters without optimization
invented entities (1)
-
Multi-scale Gaussian-Language Map (GLMap)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Semantic labeling of li- dar point clouds for uav applications
Maria Axelsson, Max Holmberg, Sabina Serra, Hannes Ovren, and Michael Tulldahl. Semantic labeling of li- dar point clouds for uav applications. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4314–4321, 2021. 2
work page 2021
-
[2]
Matterport3d: Learning from rgb-d data in indoor environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Hal- ber, Matthias Niebner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments. In2017 International Confer- ence on 3D Vision (3DV), pages 667–676. IEEE, 2017. 2, 6
work page 2017
-
[3]
Devendra Singh Chaplot, Dhiraj Prakashchand Gandhi, Ab- hinav Gupta, and Russ R Salakhutdinov. Object goal navi- gation using goal-oriented semantic exploration.Advances in Neural Information Processing Systems, 33:4247–4258,
-
[4]
Neural topological slam for vi- sual navigation
Devendra Singh Chaplot, Ruslan Salakhutdinov, Abhinav Gupta, and Saurabh Gupta. Neural topological slam for vi- sual navigation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12875– 12884, 2020. 1
work page 2020
-
[5]
Junting Chen, Guohao Li, Suryansh Kumar, Bernard Ghanem, and Fisher Yu. How to not train your dragon: Training-free embodied object goal navigation with seman- tic frontiers.Proceedings of Robotics: Science and System XIX, page 075, 2023. 2
work page 2023
-
[6]
Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning
Sijin Chen, Xin Chen, Chi Zhang, Mingsheng Li, Gang Yu, Hao Fei, Hongyuan Zhu, Jiayuan Fan, and Tao Chen. Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26428–26438, 2024. 3
work page 2024
-
[7]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 6
work page 2017
-
[8]
Rao Fu, Jingyu Liu, Xilun Chen, Yixin Nie, and Wenhan Xiong. Scene-llm: Extending language model for 3d visual reasoning.IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2(3):8, 2025. 1, 2, 8
work page 2025
-
[9]
Cows on pasture: Base- lines and benchmarks for language-driven zero-shot object navigation
Samir Yitzhak Gadre, Mitchell Wortsman, Gabriel Ilharco, Ludwig Schmidt, and Shuran Song. Cows on pasture: Base- lines and benchmarks for language-driven zero-shot object navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23171– 23181, 2023. 2
work page 2023
-
[10]
3d gaussian map with open-set semantic grouping for vision-language naviga- tion
Jianzhe Gao, Rui Liu, and Wenguan Wang. 3d gaussian map with open-set semantic grouping for vision-language naviga- tion. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 9252–9262, 2025. 2
work page 2025
-
[11]
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: In- jecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494,
-
[12]
Chat-scene: Bridging 3d scene and large language models with object identifiers
Haifeng Huang, Yilun Chen, Zehan Wang, Rongjie Huang, Runsen Xu, Tai Wang, Luping Liu, Xize Cheng, Yang Zhao, Jiangmiao Pang, et al. Chat-scene: Bridging 3d scene and large language models with object identifiers. Advances in Neural Information Processing Systems, 37: 113991–114017, 2024. 7, 8
work page 2024
-
[13]
Hao Huang, Yu Hao, Congcong Wen, Anthony Tzes, Yi Fang, et al. Gamap: Zero-shot object goal navigation with multi-scale geometric-affordance guidance.Advances in Neural Information Processing Systems, 37:39386–39408,
-
[14]
Gemma Team Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Ta- tiana Matejovicova, Alexandre Ram’e, Morgane Rivi `ere, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean- Bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gael Liu, Francesco Visin, Kathleen Kenealy, Luca...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[16]
Goat-bench: A benchmark for multi-modal lifelong navigation
Mukul Khanna, Ram Ramrakhya, Gunjan Chhablani, Sriram Yenamandra, Theophile Gervet, Matthew Chang, Zsolt Kira, Devendra Singh Chaplot, Dhruv Batra, and Roozbeh Mot- taghi. Goat-bench: A benchmark for multi-modal lifelong navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16373– 16383, 2024. 7, 8
work page 2024
-
[17]
Badi Li, Renjie Lu, Yu Zhou, Jingke Meng, and Wei-Shi Zheng. Distilling LLM prior to flow model for generaliz- able agent’s imagination in object goal navigation.Advances in Neural Information Processing Systems, 2025. 7, 8
work page 2025
-
[18]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 3
work page 2023
-
[19]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jian- wei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10965–10975, 2022. 2
work page 2022
-
[20]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEu- ropean Conference on Computer Vision, pages 38–55, 2024. 2, 4, 6
work page 2024
-
[21]
SQA3D: situ- ated question answering in 3d scenes
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. SQA3D: situ- ated question answering in 3d scenes. InThe Eleventh In- ternational Conference on Learning Representations ICLR,
-
[22]
Arjun Majumdar, Gunjan Aggarwal, Bhavika Devnani, Judy Hoffman, and Dhruv Batra. Zson: Zero-shot object-goal navigation using multimodal goal embeddings.Advances in Neural Information Processing Systems, 35:32340–32352,
-
[23]
Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu
V olodymyr Mnih, Adri`a Puigdom`enech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. InProceedings of the 33nd Interna- tional Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, pages 1928–1937,
work page 2016
-
[24]
Compressed 3d gaussian splatting for accelerated novel view synthesis
Simon Niedermayr, Josef Stumpfegger, and R ¨udiger West- ermann. Compressed 3d gaussian splatting for accelerated novel view synthesis. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 10349–10358, 2024. 2
work page 2024
-
[25]
Morris, Brandon Duderstadt, and Andriy Mulyar
Zach Nussbaum, John X. Morris, Brandon Duderstadt, and Andriy Mulyar. Nomic embed: Training a reproducible long context text embedder, 2024. 6
work page 2024
-
[26]
Zhangyang Qi, Zhixiong Zhang, Ye Fang, Jiaqi Wang, and Hengshuang Zhao. Gpt4scene: Understand 3d scenes from videos with vision-language models.arXiv preprint arXiv:2501.01428, 2025. 3, 6, 7, 8
-
[27]
Poni: Potential functions for objectgoal navigation with interaction-free learning
Santhosh Kumar Ramakrishnan, Devendra Singh Chap- lot, Ziad Al-Halah, Jitendra Malik, and Kristen Grauman. Poni: Potential functions for objectgoal navigation with interaction-free learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18890–18900, 2022. 2
work page 2022
-
[28]
Habitat: A platform for embodied AI research
Manolis Savva, Jitendra Malik, Devi Parikh, Dhruv Batra, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, and Vladlen Koltun. Habitat: A platform for embodied AI research. In 2019 IEEE/CVF International Conference on Computer Vi- sion, ICCV 2019, Seoul, Korea (South), October 27 - Novem- ber 2, 2019, pag...
work page 2019
-
[29]
Fast marching methods.SIAM review, 41 (2):199–235, 1999
James A Sethian. Fast marching methods.SIAM review, 41 (2):199–235, 1999. 5
work page 1999
-
[30]
Prioritized semantic learning for zero-shot in- stance navigation
Xinyu Sun, Lizhao Liu, Hongyan Zhi, Ronghe Qiu, and Jun- wei Liang. Prioritized semantic learning for zero-shot in- stance navigation. InEuropean Conference on Computer Vi- sion, pages 161–178. Springer, 2024. 1, 2, 6, 7, 8
work page 2024
- [31]
-
[32]
g3d-lf: Generalizable 3d- language feature fields for embodied tasks
Zihan Wang and Gim Hee Lee. g3d-lf: Generalizable 3d- language feature fields for embodied tasks. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14191–14202, 2025. 2, 3, 7, 8
work page 2025
-
[33]
Zehan Wang, Haifeng Huang, Yang Zhao, Ziang Zhang, and Zhou Zhao. Chat-3d: Data-efficiently tuning large language model for universal dialogue of 3d scenes.arXiv preprint arXiv:2308.08769, 2023. 3
-
[34]
Gridmm: Grid memory map for vision- and-language navigation
Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, and Shuqiang Jiang. Gridmm: Grid memory map for vision- and-language navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15625– 15636, 2023. 2
work page 2023
-
[35]
Zihan Wang, Seungjun Lee, and Gim Hee Lee. Dynam3d: Dynamic layered 3d tokens empower vlm for vision-and- language navigation.Advances in Neural Information Pro- cessing Systems, 2025. 2, 3
work page 2025
-
[36]
Dynam3d: Dynamic layered 3d tokens empower vlm for vision-and- language navigation
Zihan Wang, Seungjun Lee, and Gim Hee Lee. Dynam3d: Dynamic layered 3d tokens empower vlm for vision-and- language navigation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 3
work page 2025
-
[37]
Dd- ppo: Learning near-perfect pointgoal navigators from 2.5 bil- lion frames
Erik Wijmans, Abhishek Kadian, Ari Morcos, Stefan Lee, Ir- fan Essa, Devi Parikh, Manolis Savva, and Dhruv Batra. Dd- ppo: Learning near-perfect pointgoal navigators from 2.5 bil- lion frames. InInternational Conference on Learning Rep- resentations, 2019. 7, 8
work page 2019
-
[38]
V oronav: V oronoi-based zero- shot object navigation with large language model
Pengying Wu, Yao Mu, Bingxian Wu, Yi Hou, Ji Ma, Shang- hang Zhang, and Chang Liu. V oronav: V oronoi-based zero- shot object navigation with large language model. InIn- ternational Conference on Machine Learning, pages 53757– 53775. PMLR, 2024. 2
work page 2024
-
[39]
Pointllm: Empowering large language models to understand point clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiang- miao Pang, and Dahua Lin. Pointllm: Empowering large language models to understand point clouds. InEuropean Conference on Computer Vision, pages 131–147. Springer,
-
[40]
Habitat-matterport 3d semantics dataset
Karmesh Yadav, Ram Ramrakhya, Santhosh Kumar Ramakr- ishnan, Theo Gervet, John Turner, Aaron Gokaslan, Noah Maestre, Angel Xuan Chang, Dhruv Batra, Manolis Savva, et al. Habitat-matterport 3d semantics dataset. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4927–4936, 2023. 2, 6
work page 2023
-
[41]
A frontier-based approach for autonomous exploration
Brian Yamauchi. A frontier-based approach for autonomous exploration. InProceedings 1997 IEEE International Sym- posium on Computational Intelligence in Robotics and Au- tomation CIRA’97 - Towards New Computational Principles for Robotics and Automation, July 10-11, 1997, Monterey, California, USA, pages 146–151. IEEE Computer Society,
work page 1997
-
[42]
Hang Yin, Xiuwei Xu, Zhenyu Wu, Jie Zhou, and Jiwen Lu. Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation.Advances in Neural Information Processing Systems, 37:5285–5307, 2024. 1, 2, 5, 7, 8
work page 2024
-
[43]
Unigoal: Towards universal zero-shot goal- oriented navigation
Hang Yin, Xiuwei Xu, Linqing Zhao, Ziwei Wang, Jie Zhou, and Jiwen Lu. Unigoal: Towards universal zero-shot goal- oriented navigation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19057–19066,
-
[44]
Vlfm: Vision-language frontier maps for zero-shot semantic navigation
Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, and Bernadette Bucher. Vlfm: Vision-language frontier maps for zero-shot semantic navigation. In2024 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 42–48. IEEE, 2024. 1, 2, 3, 5, 6, 7, 8
work page 2024
-
[45]
Xinyao Yu, Sixian Zhang, Xinhang Song, Xiaorong Qin, and Shuqiang Jiang. Trajectory diffusion for objectgoal naviga- tion.Advances in Neural Information Processing Systems, 37:110388–110411, 2024. 2, 7, 8
work page 2024
-
[46]
3dgraphllm: Com- bining semantic graphs and large language models for 3d scene understanding
Tatiana Zemskova and Dmitry Yudin. 3dgraphllm: Com- bining semantic graphs and large language models for 3d scene understanding. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 8885–8895,
-
[47]
Faster Segment Anything: Towards Lightweight SAM for Mobile Applications
Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, and Choong Seon Hong. Faster segment anything: Towards lightweight sam for mo- bile applications.arXiv preprint arXiv:2306.14289, 2023. 2, 4, 6
work page internal anchor Pith review arXiv 2023
-
[48]
Mingjie Zhang, Yuheng Du, Chengkai Wu, Jinni Zhou, Zhenchao Qi, Jun Ma, and Boyu Zhou. Apexnav: An adap- tive exploration strategy for zero-shot object navigation with target-centric semantic fusion.IEEE Robotics Autom. Lett., 10(11):11530–11537, 2025. 6, 7, 8
work page 2025
-
[49]
Generative meta-adversarial network for unseen object navigation
Sixian Zhang, Weijie Li, Xinhang Song, Yubing Bai, and Shuqiang Jiang. Generative meta-adversarial network for unseen object navigation. InEuropean Conference on Com- puter Vision, pages 301–320. Springer, 2022. 2
work page 2022
-
[50]
Layout-based causal inference for object navigation
Sixian Zhang, Xinhang Song, Weijie Li, Yubing Bai, Xinyao Yu, and Shuqiang Jiang. Layout-based causal inference for object navigation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 10792–10802. IEEE,
work page 2023
-
[51]
Imagine before go: Self-supervised generative map for object goal navigation
Sixian Zhang, Xinyao Yu, Xinhang Song, Xiaohan Wang, and Shuqiang Jiang. Imagine before go: Self-supervised generative map for object goal navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 16414–16425, 2024. 2, 7, 8
work page 2024
-
[52]
Hoz++: Versa- tile hierarchical object-to-zone graph for object navigation
Sixian Zhang, Xinhang Song, Xinyao Yu, Yubing Bai, Xin- long Guo, Weijie Li, and Shuqiang Jiang. Hoz++: Versa- tile hierarchical object-to-zone graph for object navigation. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2025. 2
work page 2025
-
[53]
Function-centric bayesian network for zero- shot object goal navigation
Sixian Zhang, Xinyao Yu, Xinhang Song, Yiyao Wang, and Shuqiang Jiang. Function-centric bayesian network for zero- shot object goal navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19535– 19545, 2025. 5, 8
work page 2025
-
[54]
Pixel-gs: Density control with pixel-aware gradient for 3d gaussian splatting
Zheng Zhang, Wenbo Hu, Yixing Lao, Tong He, and Heng- shuang Zhao. Pixel-gs: Density control with pixel-aware gradient for 3d gaussian splatting. InEuropean Conference on Computer Vision, pages 326–342, 2024. 2
work page 2024
-
[55]
Video-3d llm: Learni ng position-aware video representation for 3d scene understanding
Duo Zheng, Shijia Huang, and Liwei Wang. Video-3d llm: Learni ng position-aware video representation for 3d scene understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8995–9006, 2025. 3
work page 2025
-
[56]
Imagine before go: Self-supervised generative map for object goal navigation
Linqing Zhong, Chen Gao, Zihan Ding, Yue Liao, and Si Liu. Topv-nav: Unlocking the top-view spatial reasoning potential of mllm for zero-shot object navigation.ArXiv, abs/2411.16425, 2024. 2
-
[57]
Esc: Ex- ploration with soft commonsense constraints for zero-shot object navigation
Kaiwen Zhou, Kaizhi Zheng, Connor Pryor, Yilin Shen, Hongxia Jin, Lise Getoor, and Xin Eric Wang. Esc: Ex- ploration with soft commonsense constraints for zero-shot object navigation. InInternational Conference on Machine Learning, pages 42829–42842. PMLR, 2023. 2, 3, 7, 8
work page 2023
-
[58]
Zibo Zhou, Yue Hu, Lingkai Zhang, Zonglin Li, and Siheng Chen. Beliefmapnav: 3d voxel-based belief map for zero- shot object navigation.Advances in Neural Information Pro- cessing Systems, 2025. 8
work page 2025
-
[59]
Target-driven vi- sual navigation in indoor scenes using deep reinforcement learning
Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph J Lim, Ab- hinav Gupta, Li Fei-Fei, and Ali Farhadi. Target-driven vi- sual navigation in indoor scenes using deep reinforcement learning. In2017 IEEE international conference on robotics and automation (ICRA), pages 3357–3364. IEEE, 2017. 1, 2
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.