Recognition: unknown
Mitigating Multimodal LLMs Hallucinations via Relevance Propagation at Inference Time
Pith reviewed 2026-05-10 15:24 UTC · model grok-4.3
The pith
Multimodal LLMs reduce hallucinations by updating key-value caches at inference time to favor perceptual inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LIME is a training-free framework that leverages Layer-wise Relevance Propagation to quantify token-level contributions and defines a relevance-based objective that promotes increased reliance on perceptual inputs. This objective is enforced through inference-time updates to the model's key-value representations, without modifying model parameters or requiring additional training data. Evaluations across multiple multimodal benchmarks in both vision and audio domains demonstrate consistent reductions in hallucinations and enhanced grounding while preserving generation quality, with further analysis showing increased modality contribution and more localized relevance patterns.
What carries the argument
Layer-wise Relevance Propagation (LRP) applied to compute token contributions, followed by inference-time updates to the key-value cache that optimize a relevance objective favoring perceptual inputs.
If this is right
- Hallucination rates drop consistently on vision and audio multimodal benchmarks.
- The contribution of perceptual modalities to generated outputs increases.
- Relevance patterns become more localized and semantically aligned with inputs.
- Overall generation quality and fluency remain unchanged.
Where Pith is reading between the lines
- The same relevance-driven update mechanism might be tested on other generation biases such as factual errors unrelated to modality.
- Combining LIME with lightweight retrieval of additional perceptual data could further strengthen grounding in open-ended tasks.
- The approach implies that post-hoc attribution tools like LRP can serve as practical levers for controlling model behavior after training.
Load-bearing premise
That LRP scores from the current forward pass accurately reflect the causal contribution of perceptual tokens and that the chosen key-value updates will steer generation toward better grounding without creating new inconsistencies.
What would settle it
Applying LIME to a standard vision-language benchmark and measuring no drop in hallucination rate, or a rise in incoherent outputs, would show the relevance-based key-value updates fail to improve grounding.
Figures


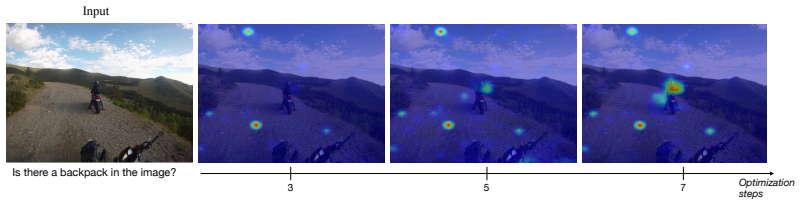

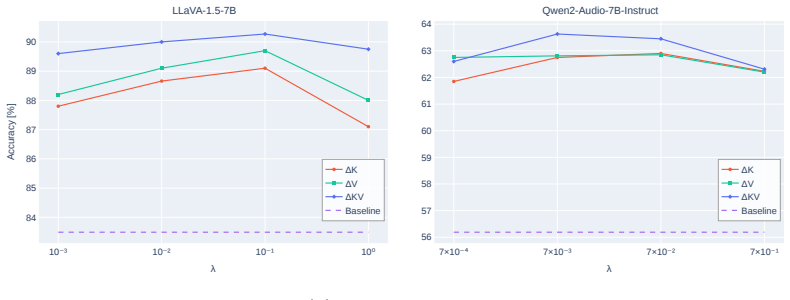



read the original abstract
Multimodal large language models (MLLMs) have revolutionized the landscape of AI, demonstrating impressive capabilities in tackling complex vision and audio-language tasks. However, a critical challenge remains: these models often suffer from hallucinations, generating outputs that diverge from the provided perceptual inputs. This tendency stems from an inherent imbalance in modality utilization during inference, where the dominance of textual tokens undermines the potential of perceptual inputs. As a result, the model frequently resorts to textual language priors at the expense of grounded evidence. To tackle this issue, we propose Learning Inference-time Modality Enhancement (LIME), a training-free framework designed to bolster multimodal grounding by explicitly enhancing modality usage during decoding. LIME leverages Layer-wise Relevance Propagation (LRP) to quantify token-level contributions and defines a relevance-based objective that promotes increased reliance on perceptual inputs. This objective is enforced through inference-time updates to the model's key-value representations, without modifying model parameters or requiring additional training data. We evaluate LIME across multiple multimodal benchmarks in both vision and audio domains, demonstrating consistent reductions in hallucinations and enhanced grounding while preserving generation quality. Further analysis shows that LIME increases modality contribution and produces more localized and semantically aligned relevance patterns.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Learning Inference-time Modality Enhancement (LIME), a training-free framework to mitigate hallucinations in multimodal LLMs. LIME applies Layer-wise Relevance Propagation (LRP) to quantify token-level contributions, defines a relevance-based objective favoring perceptual inputs, and enforces it via inference-time updates to the key-value cache without changing model parameters or using extra training data. Evaluations on vision and audio multimodal benchmarks claim consistent hallucination reductions, improved grounding, and preserved generation quality, with further analysis showing increased modality contribution and more localized relevance patterns.
Significance. If the central claims hold, LIME provides a practical, parameter-free inference-time intervention to address modality imbalance and hallucinations in MLLMs, a timely and impactful contribution given the widespread deployment of these models. Strengths include the training-free design, no requirement for additional data, and the post-hoc analysis of relevance patterns; these elements could enable easy adoption and further research on grounded generation.
major comments (3)
- [§3] §3 (Method, LRP application and KV update): The central claim requires that LRP scores from a single forward pass accurately quantify causal contributions of perceptual tokens so that the relevance objective and KV cache updates reduce hallucinations. No verification (e.g., perturbation tests, comparison to interventional baselines, or conservation checks under the update rule) is provided to establish causality over correlation or model-specific artifacts.
- [§4] §4 (Experiments and results): The reported 'consistent reductions in hallucinations' lack quantitative effect sizes, statistical tests, ablation studies isolating the KV update rule, or controls for prompt sensitivity. Without these, it is impossible to determine whether improvements are robust or attributable to the proposed mechanism.
- [§3.2] §3.2 (Relevance-based objective): The iterative enforcement of the relevance objective via KV updates may invalidate the original LRP scores on subsequent forward passes; the paper does not demonstrate that the update rule preserves LRP conservation properties or avoids introducing new inconsistencies in the generated output.
minor comments (2)
- [§3] The notation for relevance scores, the exact form of the objective, and the KV update equations should be presented with explicit mathematical definitions to facilitate reproducibility.
- [§4] Figure captions and axis labels in the relevance pattern visualizations could be expanded to clarify what 'localized' and 'semantically aligned' mean quantitatively.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and outline specific revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [§3] §3 (Method, LRP application and KV update): The central claim requires that LRP scores from a single forward pass accurately quantify causal contributions of perceptual tokens so that the relevance objective and KV cache updates reduce hallucinations. No verification (e.g., perturbation tests, comparison to interventional baselines, or conservation checks under the update rule) is provided to establish causality over correlation or model-specific artifacts.
Authors: We agree that direct verification of causality is necessary to support the central claim. The manuscript applies LRP based on its established conservation properties but does not include perturbation tests, interventional baselines, or post-update conservation checks. In the revised version we will add (i) token-perturbation experiments measuring hallucination changes when high-relevance perceptual tokens are masked, (ii) comparison against random and gradient-based update baselines, and (iii) explicit conservation metrics before and after each KV update step. revision: yes
-
Referee: [§4] §4 (Experiments and results): The reported 'consistent reductions in hallucinations' lack quantitative effect sizes, statistical tests, ablation studies isolating the KV update rule, or controls for prompt sensitivity. Without these, it is impossible to determine whether improvements are robust or attributable to the proposed mechanism.
Authors: The referee is correct that the experimental section would benefit from greater statistical rigor. The current results report average improvements across benchmarks without effect sizes, significance tests, or isolated ablations of the KV update. We will revise §4 to include (a) effect sizes (e.g., Cohen’s d) and paired statistical tests with p-values, (b) an ablation that disables the KV update while keeping the relevance objective, and (c) results across multiple prompt templates to quantify sensitivity. revision: yes
-
Referee: [§3.2] §3.2 (Relevance-based objective): The iterative enforcement of the relevance objective via KV updates may invalidate the original LRP scores on subsequent forward passes; the paper does not demonstrate that the update rule preserves LRP conservation properties or avoids introducing new inconsistencies in the generated output.
Authors: This is a legitimate technical concern. Although the updates are incremental and targeted, the manuscript does not recompute LRP after each update to verify that conservation still holds or that output consistency is maintained. In the revision we will add a dedicated analysis that (i) recomputes LRP scores on the updated KV cache at each step and reports conservation deviation, and (ii) measures generation quality and relevance localization before and after the full iterative procedure. revision: yes
Circularity Check
No significant circularity in LIME derivation chain
full rationale
The paper defines LIME by applying existing Layer-wise Relevance Propagation (LRP) to compute token-level contributions, then constructs a relevance-based objective and inference-time KV cache update rule from that computation. These steps are presented as direct consequences of the LRP formulation and the goal of increasing perceptual grounding, without any parameter fitting on evaluation data or reduction of the claimed performance gains to the method's own inputs by construction. The method is explicitly training-free and does not rely on self-citations for its core logic or uniqueness. Empirical results on benchmarks are reported separately as validation, not presupposed in the derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Layer-wise Relevance Propagation yields token-level scores that correctly measure the contribution of perceptual versus textual inputs to the next-token prediction.
Reference graph
Works this paper leans on
-
[1]
AttnLRP: Attention-aware layer-wise relevance propagation for transformers
Reduan Achtibat, Sayed Mohammad Vakilzadeh Hatefi, Maximilian Dreyer, Aakriti Jain, Thomas Wiegand, Sebastian Lapuschkin, and Wojciech Samek. AttnLRP: Attention-aware layer-wise relevance propagation for transformers. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proce...
2024
-
[2]
Mirage the illusion of visual understanding.arXiv preprint arXiv:2603.21687, 2026
Mohammad Asadi, Jack W O’Sullivan, Fang Cao, Tahoura Nedaee, Kamyar Fardi, Fei-Fei Li, Ehsan Adeli, and Euan Ashley. Mirage the illusion of visual understanding.arXiv preprint arXiv:2603.21687, 2026
-
[3]
On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation.PloS one, 10(7):e0130140, 2015
Sebastian Bach, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation.PloS one, 10(7):e0130140, 2015
2015
-
[4]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023
2023
-
[8]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuan- jun Lv, Jinzheng He, Junyang Lin, et al. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review arXiv 2024
-
[9]
Yehonatan Elisha, Oren Barkan, and Noam Koenigstein. Concept-guided fine-tuning: Steering vits away from spurious correlations to improve robustness.arXiv preprint arXiv:2603.08309, 2026
-
[10]
Detecting and preventing hallucinations in large vision language models
Anisha Gunjal, Jihan Yin, and Erhan Bas. Detecting and preventing hallucinations in large vision language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38 (16), pages 18135–18143, 2024
2024
-
[11]
Tzu-wen Hsu, Ke-Han Lu, Cheng-Han Chiang, and Hung-yi Lee. Reducing object hallucination in large audio-language models via audio-aware decoding.arXiv preprint arXiv:2506.07233, 2025
-
[12]
Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13418–13427, 2024
2024
-
[13]
Visual hallucinations of multi-modal large language models
Wen Huang, Hongbin Liu, Minxin Guo, and Neil Gong. Visual hallucinations of multi-modal large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 9614–9631, 2024
2024
-
[14]
Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673, 2020
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673, 2020. 10
2020
-
[15]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[16]
Can large audio-language models truly hear? tackling hallucinations with multi-task assessment and stepwise audio reasoning
Chun-Yi Kuan and Hung-yi Lee. Can large audio-language models truly hear? tackling hallucinations with multi-task assessment and stepwise audio reasoning. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[17]
Understanding sounds, missing the ques- tions: The challenge of object hallucination in large audio-language models
Chun-Yi Kuan, Wei-Ping Huang, and Hung-yi Lee. Understanding sounds, missing the ques- tions: The challenge of object hallucination in large audio-language models. InProc of International Speech Communication Association (INTERSPEECH), 2024
2024
-
[18]
Mitigating object hallucinations in large vision-language models through visual contrastive decoding
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872–13882, 2024
2024
-
[19]
Contrastive decoding: Open-ended text generation as optimization
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori B Hashimoto, Luke Zettlemoyer, and Mike Lewis. Contrastive decoding: Open-ended text generation as optimization. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 12286–12312, 2023
2023
-
[20]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023
2023
-
[21]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[22]
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. A survey on hallucination in large vision-language models.arXiv preprint arXiv:2402.00253, 2024
work page internal anchor Pith review arXiv 2024
-
[23]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[24]
Paying more attention to image: A training-free method for alleviating hallucination in lvlms
Shi Liu, Kecheng Zheng, and Wei Chen. Paying more attention to image: A training-free method for alleviating hallucination in lvlms. InEuropean Conference on Computer Vision, pages 125–140. Springer, 2024
2024
-
[25]
Explaining nonlinear classification decisions with deep taylor decomposition
Grégoire Montavon, Sebastian Lapuschkin, Alexander Binder, Wojciech Samek, and Klaus- Robert Müller. Explaining nonlinear classification decisions with deep taylor decomposition. Pattern recognition, 65:211–222, 2017
2017
-
[26]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[28]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning, pages 28492–28518. PMLR, 2023
2023
-
[29]
Object Hallucination in Image Captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning. In Ellen Riloff, David Chiang, Julia Hock- enmaier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045, Brussels, Belgium, October- November 2018. Ass...
-
[30]
A-okvqa: A benchmark for visual question answering using world knowledge
Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. A-okvqa: A benchmark for visual question answering using world knowledge. In European conference on computer vision, pages 146–162. Springer, 2022
2022
-
[31]
Nan Sun, Zhenyu Zhang, Xixun Lin, Kun Wang, Yanmin Shang, Naibin Gu, Shuohuan Wang, Yu Sun, Hua Wu, Haifeng Wang, et al. V-iti: Mitigating hallucinations in multimodal large language models via visual inference-time intervention.arXiv preprint arXiv:2512.03542, 2025
-
[32]
Salmonn: Towards generic hearing abilities for large language models
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun MA, and Chao Zhang. Salmonn: Towards generic hearing abilities for large language models. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=14rn7HpKVk
2024
-
[33]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Sound event detection in domestic environments with weakly labeled data and soundscape synthesis
Nicolas Turpault, Romain Serizel, Ankit Parag Shah, and Justin Salamon. Sound event detection in domestic environments with weakly labeled data and soundscape synthesis. InWorkshop on Detection and Classification of Acoustic Scenes and Events, 2019
2019
-
[35]
Mitigating hallucinations in large vision-language models with instruction contrastive decoding
Xintong Wang, Jingheng Pan, Liang Ding, and Chris Biemann. Mitigating hallucinations in large vision-language models with instruction contrastive decoding. InFindings of the Association for Computational Linguistics: ACL 2024, pages 15840–15853, 2024
2024
-
[36]
Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, Xiaohuan Zhou, Yichong Leng, Yuanjun Lv, Zhou Zhao, Chang Zhou, et al. Air-bench: Benchmarking large audio-language models via generative comprehension.arXiv preprint arXiv:2402.07729, 2024
-
[37]
Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, et al. Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13807–13816, 2024
2024
-
[38]
Reefknot: A comprehensive benchmark for relation hallucination evaluation, analysis and mitigation in multimodal large language models
Kening Zheng, Junkai Chen, Yibo Yan, Xin Zou, Huiyu Zhou, and Xuming Hu. Reefknot: A comprehensive benchmark for relation hallucination evaluation, analysis and mitigation in multimodal large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 6193–6212, 2025
2025
-
[39]
Analyzing and mitigating object hallucination in large vision-language models,
Yiyang Zhou, Chenhang Cui, Jaehong Yoon, Linjun Zhang, Zhun Deng, Chelsea Finn, Mohit Bansal, and Huaxiu Yao. Analyzing and mitigating object hallucination in large vision-language models.arXiv preprint arXiv:2310.00754, 2023
-
[40]
Xin Zou, Yizhou Wang, Yibo Yan, Yuanhuiyi Lyu, Kening Zheng, Sirui Huang, Junkai Chen, Peijie Jiang, Jia Liu, Chang Tang, et al. Look twice before you answer: Memory-space visual retracing for hallucination mitigation in multimodal large language models.arXiv preprint arXiv:2410.03577, 2024. 12 A Layer-wise Relevance Propagation for Transformer Models Thi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.