Recognition: unknown
Needle-in-RAG: Prompt-Conditioned Character-Level Traceback of Poisoned Spans in Retrieved Evidence
Pith reviewed 2026-05-10 14:49 UTC · model grok-4.3
The pith
A two-pass framework called RAGCharacter localizes poisoned character spans in RAG evidence by logging a prompt trace then applying budgeted counterfactual masking to isolate causal segments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RAGCharacter is a two-pass forensic framework that, after running standard RAG and logging a prompt-anchored execution trace, re-enters the triggered trace and performs event-conditioned traceback over prompt-used evidence via budgeted counterfactual masking and replay, producing both an attribution span for forensic reporting and a causal span under the logged trace.
What carries the argument
Budgeted counterfactual masking and replay over prompt-used evidence, which selectively masks retrieved spans, replays the generation trace, and measures the effect on the misgenerated output to isolate the responsible poisoned characters.
If this is right
- Enables forensic reporting that names exact character ranges inside retrieved passages rather than entire chunks.
- Supports remediation steps that remove or flag only the causal poisoned text while preserving the rest of the evidence.
- Applies uniformly across multiple poisoning attack families without attack-specific tuning.
- Provides an evaluation protocol that jointly measures chunk-level traceback and character-level localization fidelity.
- Operates in a black-box setting, requiring only the ability to log traces and replay masked inputs.
Where Pith is reading between the lines
- The same masking-replay idea could be applied to detect poisoned spans that affect non-QA tasks such as summarization or code generation.
- If masking budgets can be tightened further, the approach might support lightweight online monitoring instead of post-hoc forensics.
- Character-level attribution opens the possibility of automated corpus cleaning that edits only the offending substrings.
- Integration with retrieval scoring could create hybrid systems that both rank passages and flag suspect internal spans.
Load-bearing premise
Budgeted counterfactual masking over prompt-used evidence can isolate the causal poisoned span without introducing systematic false negatives or requiring prior knowledge of the attack type.
What would settle it
A controlled test in which a short known poisoned span is embedded in a retrieved passage, the model produces the expected erroneous output, yet RAGCharacter either misses the span or attributes the error to unrelated characters would falsify the isolation claim.
Figures


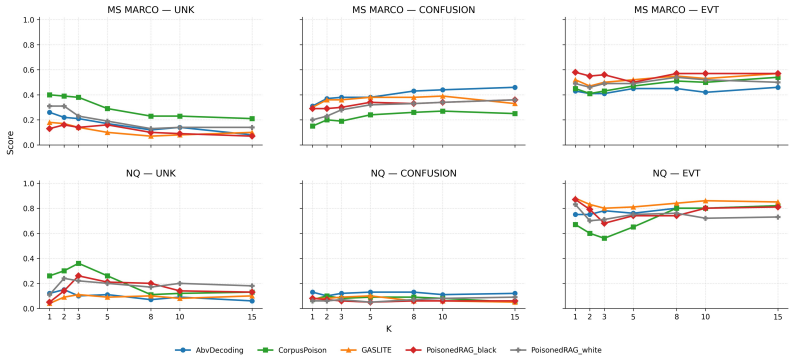


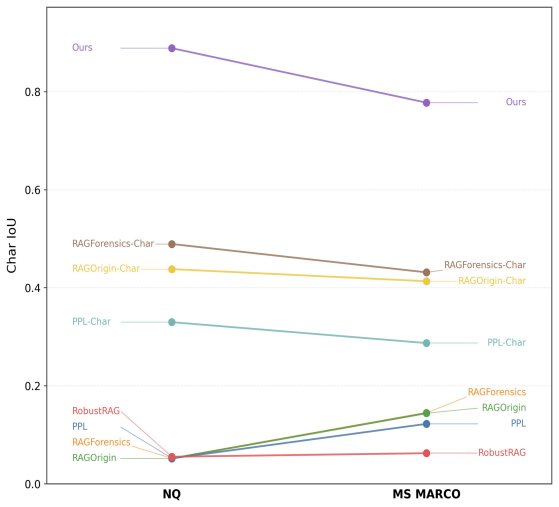




read the original abstract
Retrieval-augmented generation (RAG) improves factual grounding by conditioning large language models on retrieved evidence, but it also opens a data-layer attack surface: poisoned corpus entries can steer outputs without changing model parameters. Existing defenses and traceback methods are largely passage-level, which is too coarse for modern attacks whose effective payload may be a short fabricated claim, trigger phrase, or hidden instruction embedded inside an otherwise benign chunk. We study black-box character-level poison traceback in RAG and present RAGCharacter, a two-pass forensic framework that localizes the responsible retrieved span for a concrete misgeneration event. Pass-0 runs standard RAG while logging a prompt-anchored execution trace. Pass-1 re-enters a triggered trace and performs event-conditioned traceback over prompt-used evidence via budgeted counterfactual masking and replay, yielding an attribution span for forensic reporting and a causal span under the logged trace. We further introduce an evaluation protocol that measures both event-level chunk traceback and character-level localization fidelity. Across two QA corpora, five poisoning attack families, six target LLMs, and multiple passage- and character-level baselines, RAGCharacter achieves the best overall trade-off within our benchmark between localization accuracy and low over-attribution. These results suggest that prompt-conditioned, black-box character-level traceback can be feasible, moving RAG forensics from document-level suspicion toward finer-grained evidence auditing and potential remediation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RAGCharacter, a two-pass black-box forensic framework for localizing poisoned character spans within retrieved RAG evidence. Pass-0 executes standard RAG while logging a prompt-anchored execution trace; Pass-1 re-enters the trace and applies budgeted counterfactual masking over prompt-used evidence to produce an attribution span and a causal span for a given misgeneration. The authors also define an evaluation protocol measuring event-level chunk traceback and character-level localization fidelity. Across two QA corpora, five poisoning attack families, six target LLMs, and multiple passage- and character-level baselines, the paper claims RAGCharacter delivers the best overall trade-off between localization accuracy and low over-attribution.
Significance. If the empirical results hold under more comprehensive attack models, the work would advance RAG security from coarse passage-level suspicion to actionable character-level auditing, enabling targeted corpus remediation and improving forensic accountability in production retrieval-augmented systems.
major comments (1)
- Evaluation protocol (described in the abstract and implied §4–5): the reported localization fidelity rests on the assumption that a single contiguous poisoned span can be isolated via budgeted counterfactual masking. The protocol description gives no indication that multi-span or cross-evidence interaction cases (e.g., a trigger whose effect requires a prerequisite fact from another retrieved passage) were tested; if such cases exist in the five attack families, the central claim of best accuracy/over-attribution trade-off would be overstated.
Simulated Author's Rebuttal
We thank the referee for the detailed comment regarding the evaluation protocol and the scope of the tested attack families. We address the concern directly below and will make a partial revision to improve clarity.
read point-by-point responses
-
Referee: Evaluation protocol (described in the abstract and implied §4–5): the reported localization fidelity rests on the assumption that a single contiguous poisoned span can be isolated via budgeted counterfactual masking. The protocol description gives no indication that multi-span or cross-evidence interaction cases (e.g., a trigger whose effect requires a prerequisite fact from another retrieved passage) were tested; if such cases exist in the five attack families, the central claim of best accuracy/over-attribution trade-off would be overstated.
Authors: The five poisoning attack families (Section 4.2) are explicitly constructed as single contiguous poisoned spans within individual passages; none of the families involve multi-span payloads or cross-evidence prerequisite interactions. The evaluation protocol therefore measures localization fidelity under this single-span threat model, which aligns with the dominant attack patterns studied in the RAG poisoning literature. We agree that the manuscript does not explicitly state this scope in the protocol description, which could lead a reader to assume broader coverage. We will add a clarifying paragraph in Section 5 (Evaluation Protocol) and a short limitations note in the conclusion stating that (i) all tested attacks are single-span, (ii) the reported accuracy/over-attribution trade-off holds within this benchmark, and (iii) multi-span and cross-evidence cases remain open for future extension. This revision will ensure the claims are not overstated while preserving the contribution for the evaluated setting. revision: partial
Circularity Check
No circularity: empirical method evaluated against external baselines
full rationale
The paper describes a procedural two-pass forensic framework (Pass-0 logging, Pass-1 budgeted counterfactual masking) for localizing poisoned spans in RAG evidence. Performance claims rest on direct comparison to passage- and character-level baselines across fixed corpora, attack families, and LLMs, with no equations, fitted parameters renamed as predictions, or self-citation chains that reduce the reported accuracy/over-attribution trade-off to the method's own inputs by construction. The evaluation protocol is externally falsifiable and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RAG systems condition LLM outputs on retrieved evidence passages that may contain poisoned spans.
invented entities (1)
-
RAGCharacter two-pass forensic framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
In: Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security
Ben-Tov, M., Sharif, M.: Gasliteing the retrieval: Exploring vulnerabilities in dense embedding- based search. In: Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security. pp. 4364–4378 (2025)
2025
-
[3]
In: International conference on machine learning
Borgeaud, S., Mensch, A., Hoffmann, J., Cai, T., Rutherford, E., Millican, K., Van Den Driess- che, G.B., Lespiau, J.B., Damoc, B., Clark, A., et al.: Improving language models by retrieving from trillions of tokens. In: International conference on machine learning. pp. 2206–2240. PMLR (2022)
2022
-
[4]
One Shot Dominance: Knowledge Poisoning Attack on Retrieval-Augmented Generation Systems
Chang, Z., Li, M., Jia, X., Wang, J., Huang, Y ., Jiang, Z., Liu, Y ., Wang, Q.: One shot dominance: Knowledge poisoning attack on retrieval-augmented generation systems. arXiv preprint arXiv:2505.11548 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Beyond the Spelling Miracle: Investigating Substring Awareness in Character-Blind Language Models
Chang, Z., Li, M., Jia, X., Wang, J., Huang, Y ., Jiang, Z., Liu, Y ., Wang, Q.: One shot dominance: Knowledge poisoning attack on retrieval-augmented generation systems. In: Findings of the As- sociation for Computational Linguistics: EMNLP 2025. pp. 18811–18825. Association for Com- putational Linguistics, Suzhou, China (Nov 2025). https://doi.org/10.18...
-
[6]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Chaturvedi, S.S., Bagwe, G., Zhang, L.E., Yuan, X.: AIP: Subverting retrieval-augmented gener- ation via adversarial instructional prompt. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 15861–15878. Association for Computational Linguistics, Suzhou, China (Nov 2025). https://doi.org/10.18653/v1/2025.emnlp-m...
-
[7]
Phantom: General trigger attacks on retrieval augmented language generation,
Chaudhari, H., Severi, G., Abascal, J., Jagielski, M., Choquette-Choo, C.A., Nasr, M., Nita- Rotaru, C., Oprea, A.: Phantom: General trigger attacks on retrieval augmented language generation. arXiv preprint arXiv:2405.20485 (2024) 23
- [8]
-
[9]
Chen, Y ., Li, H., Zheng, Z., Wu, D., Song, Y ., Hooi, B.: Defense against prompt injection attack by leveraging attack techniques. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers). pp. 18331–18347. Association for Computational Linguistics, Vienna, Austria (Jul 2025). https://doi.org/10....
-
[10]
In: Proceedings of the 38th International Conference on Neural Information Processing Systems
Chen, Z., Xiang, Z., Xiao, C., Song, D., Li, B.: Agentpoison: red-teaming llm agents via poisoning memory or knowledge bases. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. NIPS ’24, Curran Associates Inc., Red Hook, NY , USA (2024)
2024
-
[11]
Cheng, P., Ding, Y ., Ju, T., Wu, Z., Du, W., Zhao, H., Yi, P., Zhang, Z., Liu, G.: TrojanRAG: Retrieval-augmented generation can be backdoor driver in large language models (2024), https://openreview.net/forum?id=RfYD6v829Y
2024
-
[12]
arXiv preprint arXiv:2510.25025 (2025)
Cheng, Z., Sun, J., Gao, A., Quan, Y ., Liu, Z., Hu, X., Fang, M.: Secure retrieval-augmented generation against poisoning attacks. arXiv preprint arXiv:2510.25025 (2025)
-
[13]
arXiv preprint arXiv:2404.13948 (2024)
Cho, S., Jeong, S., Seo, J., Hwang, T., Park, J.C.: Typos that broke the rag’s back: Genetic attack on rag pipeline by simulating documents in the wild via low-level perturbations. arXiv preprint arXiv:2404.13948 (2024)
-
[14]
In: Findings of the Association for Computa- tional Linguistics: EMNLP 2025
Choi, C., Kim, J., Cho, S., Jeong, S., Chang, B.: The ragparadox: A black-box attack exploiting unintentional vulnerabilities in retrieval-augme. In: Findings of the Association for Computa- tional Linguistics: EMNLP 2025. Association for Computational Linguistics, Suzhou, China (Nov 2025)
2025
-
[15]
arXiv preprint arXiv:2506.04390 (2025)
Choudhary, S., Palumbo, N., Hooda, A., Dvijotham, K.D., Jha, S.: Through the stealth lens: Rethinking attacks and defenses in rag. arXiv preprint arXiv:2506.04390 (2025)
-
[16]
arXiv preprint arXiv:2410.14479 , year=
Clop, C., Teglia, Y .: Backdoored retrievers for prompt injection attacks on retrieval augmented generation of large language models. arXiv preprint arXiv:2410.14479 (2024)
- [17]
-
[18]
In: Proceedings of the 58th annual meeting of the association for computational linguistics
DeYoung, J., Jain, S., Rajani, N.F., Lehman, E., Xiong, C., Socher, R., Wallace, B.C.: Eraser: A benchmark to evaluate rationalized nlp models. In: Proceedings of the 58th annual meeting of the association for computational linguistics. pp. 4443–4458 (2020)
2020
-
[19]
Flemings, J., Jiang, B., Zhang, W., Takhirov, Z., Annavaram, M.: Estimating privacy leak- age of augmented contextual knowledge in language models. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Pa- pers). pp. 25092–25108. Association for Computational Linguistics, Vienna, Austria (Jul 2025). h...
-
[20]
In: International conference on machine learning
Ghorbani, A., Zou, J.: Data shapley: Equitable valuation of data for machine learning. In: International conference on machine learning. pp. 2242–2251. PMLR (2019)
2019
-
[21]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
In: Proceedings of the 16th ACM workshop on artificial intelligence and security
Greshake, K., Abdelnabi, S., Mishra, S., Endres, C., Holz, T., Fritz, M.: Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. In: Proceedings of the 16th ACM workshop on artificial intelligence and security. pp. 79–90 (2023)
2023
-
[23]
In: International conference on machine learning
Guu, K., Lee, K., Tung, Z., Pasupat, P., Chang, M.: Retrieval augmented language model pre-training. In: International conference on machine learning. pp. 3929–3938. PMLR (2020)
2020
-
[24]
ACM Transactions on Information Systems43(2), 1–55 (2025) 24
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., et al.: A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems43(2), 1–55 (2025) 24
2025
-
[25]
In: Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume
Izacard, G., Grave, E.: Leveraging passage retrieval with generative models for open domain question answering. In: Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume. pp. 874–880 (2021)
2021
-
[26]
Jiao, Y ., Wang, X., Yang, K.: Pr-attack: Coordinated prompt-rag attacks on retrieval-augmented generation in large language models via bilevel optimization. In: Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. p. 656–667. SIGIR ’25, Association for Computing Machinery, New York, NY , USA (20...
-
[27]
In: EMNLP (1)
Karpukhin, V ., Oguz, B., Min, S., Lewis, P.S., Wu, L., Edunov, S., Chen, D., Yih, W.t.: Dense passage retrieval for open-domain question answering. In: EMNLP (1). pp. 6769–6781 (2020)
2020
-
[28]
In: Interna- tional conference on machine learning
Koh, P.W., Liang, P.: Understanding black-box predictions via influence functions. In: Interna- tional conference on machine learning. pp. 1885–1894. PMLR (2017)
2017
-
[29]
Transactions of the Association for Computational Linguistics7, 452–466 (2019)
Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., Toutanova, K., Jones, L., Kelcey, M., Chang, M.W., Dai, A.M., Uszkoreit, J., Le, Q., Petrov, S.: Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics7,...
2019
-
[30]
In: Proceedings of the 34th International Conference on Neural Information Processing Systems
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V ., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., Riedel, S., Kiela, D.: Retrieval-augmented generation for knowledge- intensive nlp tasks. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. NIPS ’20, Curran Associates Inc., Red Hook, NY...
2020
-
[31]
Advances in neural information processing systems33, 9459–9474 (2020)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V ., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33, 9459–9474 (2020)
2020
-
[32]
Li, H., Liu, X., Zhang, N., Xiao, C.: PIGuard: Prompt injection guardrail via mitigating overdefense for free. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers). pp. 30420–30437. Association for Compu- tational Linguistics, Vienna, Austria (Jul 2025). https://doi.org/10.18653/v1/2025.acl-l...
-
[33]
In: International Symposium on Information and Communication Technology
Nguyen, H.T., Nguyen, T.D., Nguyen, V .H.: Enhancing retrieval augmented generation with hierarchical text segmentation chunking. In: International Symposium on Information and Communication Technology. pp. 209–220. Springer (2024)
2024
-
[34]
Nguyen, T., Rosenberg, M., Song, X., Gao, J., Tiwary, S., Majumder, R., Deng, L.: MS MARCO: A human generated machine reading comprehension dataset. In: Proceedings of the Workshop on Cognitive Computation: Integrating neural and symbolic approaches 2016 co-located with the 30th Annual Conference on Neural Information Processing Systems (NIPS 2016), Barce...
2016
-
[35]
Ignore Previous Prompt: Attack Techniques For Language Models
Perez, F., Ribeiro, I.: Ignore previous prompt: Attack techniques for language models. arXiv preprint arXiv:2211.09527 (2022)
work page internal anchor Pith review arXiv 2022
-
[36]
Advances in Neural Information Processing Systems33, 19920–19930 (2020)
Pruthi, G., Liu, F., Kale, S., Sundararajan, M.: Estimating training data influence by tracing gradient descent. Advances in Neural Information Processing Systems33, 19920–19930 (2020)
2020
-
[37]
In: ICLR 2024 Workshop on Navigating and Addressing Data Problems for Foundation Models (2024), https://openreview.net/forum?id=el5wbHYKeS
Qi, Z., Zhang, H., Xing, E.P., Kakade, S.M., Lakkaraju, H.: Follow my instruction and spill the beans: Scalable data extraction from retrieval-augmented generation systems. In: ICLR 2024 Workshop on Navigating and Addressing Data Problems for Foundation Models (2024), https://openreview.net/forum?id=el5wbHYKeS
2024
-
[38]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Rawte, V ., Chakraborty, S., Pathak, A., Sarkar, A., Tonmoy, S.T.I., Chadha, A., Sheth, A., Das, A.: The troubling emergence of hallucination in large language models - an extensive definition, quantification, and prescriptive remediations. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 2541–2573 (Dec 2023)
2023
-
[39]
why should i trust you?
Ribeiro, M.T., Singh, S., Guestrin, C.: " why should i trust you?" explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. pp. 1135–1144 (2016)
2016
-
[40]
In: Proceedings on
Schwinn, L., Dobre, D., Günnemann, S., Gidel, G.: Adversarial attacks and defenses in large language models: Old and new threats. In: Proceedings on. pp. 103–117. PMLR (2023) 25
2023
-
[41]
In: 34th USENIX Security Symposium (USENIX Security 25)
Shafran, A., Schuster, R., Shmatikov, V .: Machine against the{RAG}: Jamming {Retrieval- Augmented} generation with blocker documents. In: 34th USENIX Security Symposium (USENIX Security 25). pp. 3787–3806 (2025)
2025
-
[42]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025), https://openreview.net/forum?id= D9JeNTs5Bu
Shen, Z., Imana, B.Y ., Wu, T., Xiang, C., Mittal, P., Korolova, A.: ReliabilityRAG: Effective and provably robust defense for RAG-based web-search. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025), https://openreview.net/forum?id= D9JeNTs5Bu
2025
-
[43]
arXiv preprint arXiv:2510.09710 (2025)
Si, X., Zhu, M., Qin, S., Yu, L., Zhang, L., Liu, S., Li, X., Duan, R., Liu, Y ., Jia, X.: Secon-rag: A two-stage semantic filtering and conflict-free framework for trustworthy rag. arXiv preprint arXiv:2510.09710 (2025)
-
[44]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025), https: //openreview.net/forum?id=tTwZhy8JqY
si, X., Zhu, M., Qin, S., Yu, L., Zhang, L., Liu, S., Li, X., Duan, R., Liu, Y ., Jia, X.: Secon- RAG: A two-stage semantic filtering and conflict-free framework for trustworthy RAG. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025), https: //openreview.net/forum?id=tTwZhy8JqY
2025
- [45]
-
[46]
In: International conference on machine learning
Sundararajan, M., Taly, A., Yan, Q.: Axiomatic attribution for deep networks. In: International conference on machine learning. pp. 3319–3328. PMLR (2017)
2017
-
[47]
Tan, X., Luan, H., Luo, M., Sun, X., Chen, P., Dai, J.: Revprag: Revealing poisoning attacks in retrieval-augmented generation through llm activation analysis. arXiv preprint arXiv:2411.18948 (2024)
-
[48]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Tan, Z., Zhao, C., Moraffah, R., Li, Y ., Wang, S., Li, J., Chen, T., Liu, H.: Glue pizza and eat rocks-exploiting vulnerabilities in retrieval-augmented generative models. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 1610–1626 (2024)
2024
-
[49]
Gemma: Open Models Based on Gemini Research and Technology
Team, G., Mesnard, T., Hardin, C., Dadashi, R., Bhupatiraju, S., Pathak, S., Sifre, L., Rivière, M., Kale, M.S., Love, J., et al.: Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295 (2024)
work page internal anchor Pith review arXiv 2024
-
[50]
FEVER: a large-scale dataset for Fact Extraction and VERification
Thorne, J., Vlachos, A., Christodoulopoulos, C., Mittal, A.: Fever: a large-scale dataset for fact extraction and verification. arXiv preprint arXiv:1803.05355 (2018)
work page internal anchor Pith review arXiv 2018
-
[51]
In: Findings of the Associa- tion for Computational Linguistics: EMNLP 2025
Wen, T., Wang, C., Yang, X., Tang, H., Xie, Y ., Lyu, L., Dou, Z., Wu, F.: Defend- ing against indirect prompt injection by instruction detection. In: Findings of the Associa- tion for Computational Linguistics: EMNLP 2025. p. 19472–19487. Association for Com- putational Linguistics (2025). https://doi.org/10.18653/v1/2025.findings-emnlp.1060, http: //dx....
-
[52]
arXiv preprint arXiv:2510.13842 (2025)
Wu, Y ., Liu, X., Li, Y ., Gao, Y ., Ding, Y ., Ding, J., Zheng, X., Ma, X.: Admit: Few-shot knowledge poisoning attacks on rag-based fact checking. arXiv preprint arXiv:2510.13842 (2025)
-
[53]
Xiang, C., Wu, T., Zhong, Z., Wagner, D., Chen, D., Mittal, P.: Certifiably robust rag against retrieval corruption (2024)
2024
-
[54]
Badrag: Identifying vulnerabilities in retrieval augmented generation of large language models,
Xue, J., Zheng, M., Hu, Y ., Liu, F., Chen, X., Lou, Q.: Badrag: Identifying vulnerabilities in retrieval augmented generation of large language models. arXiv preprint arXiv:2406.00083 (2024)
-
[55]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Xia, T., Ren, X., Ren, X., Fan, Y ., Su, Y ., Zhang, Y ., Wan, Y ., Liu, Y ....
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W., Salakhutdinov, R., Manning, C.D.: Hot- potQA: A dataset for diverse, explainable multi-hop question answering. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 2369–2380 (Oct-Nov 2018) 26
2018
-
[57]
Yi, J., Xie, Y ., Zhu, B., Kiciman, E., Sun, G., Xie, X., Wu, F.: Benchmarking and defending against indirect prompt injection attacks on large language models. In: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .1. p. 1809–1820. KDD ’25, Association for Computing Machinery, New York, NY , USA (2025),https://doi. or...
-
[58]
In: Findings of the Association for Computational Linguis- tics: ACL 2024
Zeng, S., Zhang, J., He, P., Liu, Y ., Xing, Y ., Xu, H., Ren, J., Chang, Y ., Wang, S., Yin, D., Tang, J.: The good and the bad: Exploring privacy issues in retrieval- augmented generation (RAG). In: Findings of the Association for Computational Linguis- tics: ACL 2024. pp. 4505–4524. Association for Computational Linguistics, Bangkok, Thai- land (Aug 20...
-
[59]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Zeng, S., Zhang, J., He, P., Ren, J., Zheng, T., Lu, H., Xu, H., Liu, H., Xing, Y ., Tang, J.: Mitigating the privacy issues in retrieval-augmented generation (RAG) via pure synthetic data. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 24527–24558. Association for Computational Linguistics, Suzhou, China (...
-
[60]
arXiv preprint arXiv:2509.13772 (2025)
Zhang, B., Xin, H., Chen, Y ., Liu, Z., Yi, B., Li, T., Nie, L., Liu, Z., Fang, M.: Who taught the lie? responsibility attribution for poisoned knowledge in retrieval-augmented generation. arXiv preprint arXiv:2509.13772 (2025)
-
[61]
In: Proceedings of the ACM on Web Conference 2025
Zhang, B., Xin, H., Fang, M., Liu, Z., Yi, B., Li, T., Liu, Z.: Traceback of poisoning attacks to retrieval-augmented generation. In: Proceedings of the ACM on Web Conference 2025. pp. 2085–2097 (2025)
2025
-
[62]
Benchmarking poisoning attacks against retrieval- augmented generation,
Zhang, B., Xin, H., Li, J., Zhang, D., Fang, M., Liu, Z., Nie, L., Liu, Z.: Benchmarking poisoning attacks against retrieval-augmented generation. arXiv preprint arXiv:2505.18543 (2025)
-
[63]
In: Forty-second International Conference on Machine Learning (2025), https://openreview.net/forum? id=6SIymOqJlc
Zhang, C., Zhang, X., Lou, J., Wu, K., Wang, Z., Chen, X.: Poisonedeye: Knowledge poisoning attack on retrieval-augmented generation based large vision-language models. In: Forty-second International Conference on Machine Learning (2025), https://openreview.net/forum? id=6SIymOqJlc
2025
-
[64]
arXiv preprint arXiv:2410.02163 (2024)
Zhang, C., Zhang, T., Shmatikov, V .: Adversarial decoding: Generating readable documents for adversarial objectives. arXiv preprint arXiv:2410.02163 (2024)
-
[65]
In: Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering
Zhang, Q., Zeng, B., Zhou, C., Go, G., Shi, H., Jiang, Y .: Human-imperceptible retrieval poisoning attacks in llm-powered applications. In: Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering. pp. 502–506 (2024)
2024
-
[66]
arXiv preprint arXiv:2310.19156 (2023)
Zhong, Z., Huang, Z., Wettig, A., Chen, D.: Poisoning retrieval corpora by injecting adversarial passages. arXiv preprint arXiv:2310.19156 (2023)
-
[67]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Zhu, H., Fiondella, L., Yuan, J., Zeng, K., Jiao, L.: Neurogenpoisoning: Neuron-guided attacks on retrieval-augmented generation of llm via genetic optimization of external knowledge. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[68]
In: 34th USENIX Security Symposium (USENIX Security 25)
Zou, W., Geng, R., Wang, B., Jia, J.: {PoisonedRAG}: Knowledge corruption attacks to {Retrieval-Augmented} generation of large language models. In: 34th USENIX Security Symposium (USENIX Security 25). pp. 3827–3844 (2025) 27 A Character-level Traceback performance data Table 8: Experimental results on the NQ dataset (Gemma). Method Metric AbvDecoding Corp...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.