Recognition: unknown
Khala: Scaling Acoustic Token Language Models Toward High-Fidelity Music Generation
Pith reviewed 2026-05-09 16:32 UTC · model grok-4.3
The pith
High-fidelity music can be generated by progressively modeling structure and detail together inside one 64-layer acoustic token hierarchy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
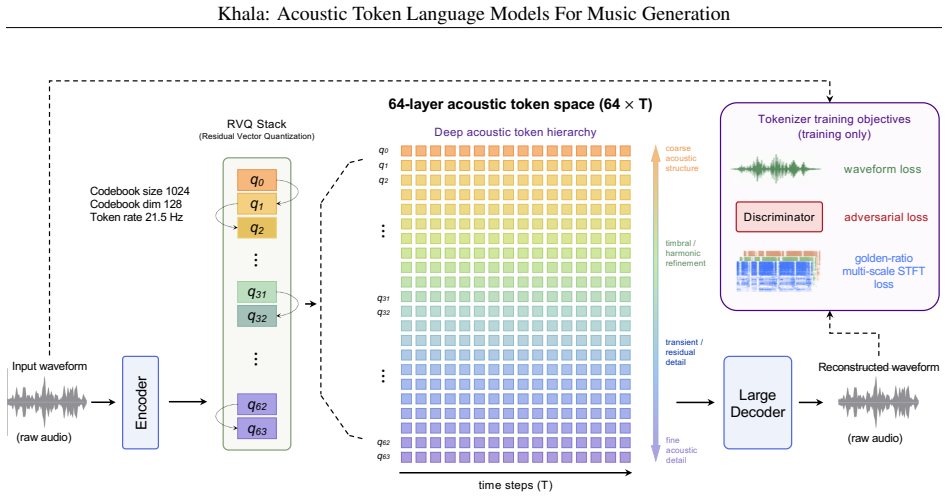
We build a 64-layer RVQ acoustic token space and a two-stage coarse-to-fine framework in which a backbone model generates the initial coarse tokens for the full track and a super-resolution model then completes finer tokens layer by layer while operating at full-track scale in parallel. Hybrid-attention training combines causal attention for alignment objectives with full attention for layer-wise refinement. Text-vocal alignment emerges naturally during pure acoustic-token language modeling, and initializing the super-resolution model from the backbone improves convergence and quality. These findings show that high-quality music generation can proceed without separating structure and fine-fd
What carries the argument
The 64-layer residual vector quantization (RVQ) acoustic token hierarchy, which encodes audio as stacked discrete tokens that progressively capture both coarse musical structure and fine sonic details within one unified space.
If this is right
- Music generation pipelines can be simplified by removing the need for a separate semantic token stage.
- A fixed 62-step inference schedule becomes possible because the super-resolution stage refines all finer layers in parallel over time.
- Initializing the super-resolution model from the already-trained backbone accelerates convergence and raises final quality.
- Lyric alignment can be obtained as an emergent property of acoustic-token language modeling alone.
Where Pith is reading between the lines
- The same unified hierarchy might be tested on other audio tasks such as sound-effect generation or multi-speaker speech synthesis.
- If the approach scales, future work could explore whether even deeper RVQ stacks or different quantization schedules further reduce the gap to real-world recordings.
- The fixed inference length opens a path to predictable latency in streaming or interactive music tools.
Load-bearing premise
A single 64-layer RVQ acoustic token space can contain enough information for both high-level musical structure and low-level audio fidelity without the information loss that would force the use of separate semantic tokens.
What would settle it
A controlled comparison in which the same training data and model scale are used to train both the unified 64-layer RVQ system and a conventional two-stage semantic-plus-acoustic pipeline, followed by blind listening tests and objective metrics on lyric alignment and perceptual quality.
Figures

read the original abstract
A common design pattern in high-quality music generation is to handle structure and fidelity in different representation spaces: a generator first models high-level structure, followed by diffusion-based or neural decoding stages that reconstruct fine details. In this work, we explore an alternative view: both may be progressively modeled within a single deep acoustic-token hierarchy. To study this, we build a 64-layer residual vector quantization (RVQ) acoustic representation and propose a two-stage coarse-to-fine generation framework. A backbone model first generates coarse acoustic tokens for the full track, and a super-resolution model then completes finer tokens within the same acoustic token space. The super-resolution stage works at full-track scale and refines tokens layer by layer while running in parallel over time, leading to a fixed 62-step inference process. To jointly improve lyric alignment and fine-detail reconstruction, we further introduce hybrid-attention training: the alignment objective uses causal attention, while layer-wise refinement uses full attention. A key finding is that text--vocal alignment can emerge within pure acoustic-token language modeling, without requiring a separate semantic token stage. Moreover, initializing the super-resolution model from the trained backbone significantly improves convergence and final quality. Taken together, our results suggest that high-quality music generation can be effectively pursued without separating structure and fidelity into heterogeneous representation spaces. Instead, both can be progressively modeled within a unified acoustic-token hierarchy, pointing toward a simpler and more unified path to high-quality music generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Khala, a two-stage coarse-to-fine framework for high-fidelity music generation that operates entirely within a single 64-layer residual vector quantization (RVQ) acoustic token hierarchy. A backbone language model first generates coarse acoustic tokens across the full track; a super-resolution model then refines the remaining layers in a fixed 62-step process that runs in parallel over time. Hybrid-attention training (causal for alignment, full for refinement) is introduced to jointly optimize lyric alignment and detail reconstruction. The central findings are that text-vocal alignment emerges from pure acoustic-token language modeling without a separate semantic stage, that initializing the super-resolution model from the backbone improves convergence, and that high-quality music generation can therefore be pursued without heterogeneous structure/fidelity representation spaces.
Significance. If the empirical claims are substantiated, the work offers a concrete alternative to the dominant semantic-then-acoustic pipeline, showing that a deep unified RVQ hierarchy plus layer-wise super-resolution can jointly capture long-range musical structure and fine acoustic fidelity. The fixed 62-step inference schedule and the hybrid-attention objective are practical engineering contributions that could be adopted more broadly. The observation of emergent alignment inside acoustic tokens is noteworthy and, if replicated, would reduce the need for multi-representation training regimes.
major comments (2)
- [Abstract and §4] Abstract and §4 (experimental results): The central claim that a single 64-layer RVQ hierarchy suffices for both high-level structure and fidelity rests on the untested assumption that lower RVQ layers preserve structural information (form, harmony, long-range dependencies) without irreversible loss. The manuscript reports emergent alignment and improved convergence but supplies no layer-wise information-preservation analysis (e.g., reconstruction fidelity or mutual information when conditioning only on coarser layers) nor direct comparisons against semantic+acoustic baselines on structural coherence metrics such as phrase-level alignment or harmonic consistency.
- [§3.1–3.2] §3.1–3.2 (model architecture and training): The 62-step inference process and the hybrid-attention schedule are presented as key enablers, yet no ablation is shown that isolates the contribution of backbone initialization versus random initialization of the super-resolution model, nor the effect of varying the number of RVQ layers on final quality. Without these controls, it is impossible to determine whether the reported gains are attributable to the unified acoustic hierarchy or to other training choices.
minor comments (2)
- [Abstract] The abstract states that the super-resolution stage “refines tokens layer by layer while running in parallel over time,” but the precise scheduling of which layers are generated at each of the 62 steps is not diagrammed; a small schematic would clarify the coarse-to-fine progression.
- [§3] Notation for the RVQ codebooks and the hybrid attention masks should be introduced once in §3 and used consistently; occasional shifts between “layer-wise” and “coarse-to-fine” phrasing obscure the exact scope of the attention masks.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. We address each major comment below with clarifications on our current results and commitments to strengthen the evidence in revision.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experimental results): The central claim that a single 64-layer RVQ hierarchy suffices for both high-level structure and fidelity rests on the untested assumption that lower RVQ layers preserve structural information (form, harmony, long-range dependencies) without irreversible loss. The manuscript reports emergent alignment and improved convergence but supplies no layer-wise information-preservation analysis (e.g., reconstruction fidelity or mutual information when conditioning only on coarser layers) nor direct comparisons against semantic+acoustic baselines on structural coherence metrics such as phrase-level alignment or harmonic consistency.
Authors: We acknowledge that the manuscript does not include explicit layer-wise information-preservation analyses (such as reconstruction fidelity or mutual information from coarser layers alone) or direct quantitative comparisons to semantic+acoustic baselines on structural metrics like phrase-level alignment or harmonic consistency. Our end-to-end results demonstrate that the two-stage framework on the 64-layer RVQ produces high-fidelity music with emergent lyric alignment, which indirectly supports that coarser layers retain sufficient structural information for the backbone model to generate coherent tracks. Nevertheless, we agree these additional analyses would provide stronger substantiation. In the revised manuscript we will add layer-wise ablation experiments measuring reconstruction quality when finer layers are withheld and, to the extent feasible with existing baselines, comparisons on harmonic consistency and alignment metrics. revision: yes
-
Referee: [§3.1–3.2] §3.1–3.2 (model architecture and training): The 62-step inference process and the hybrid-attention schedule are presented as key enablers, yet no ablation is shown that isolates the contribution of backbone initialization versus random initialization of the super-resolution model, nor the effect of varying the number of RVQ layers on final quality. Without these controls, it is impossible to determine whether the reported gains are attributable to the unified acoustic hierarchy or to other training choices.
Authors: We agree that formal ablations isolating backbone initialization from random initialization and examining the impact of RVQ layer count would strengthen the attribution of gains to the unified hierarchy. The manuscript reports that initializing the super-resolution model from the trained backbone improves convergence and final quality, based on observed training dynamics, but does not present controlled ablation tables for these factors or for varying the number of RVQ layers. In the revised version we will include these ablation studies, reporting metrics for backbone versus random initialization of the super-resolution stage and for different RVQ depths, to clarify the sources of the reported improvements. revision: yes
Circularity Check
No circularity: claims rest on architectural choices and empirical outcomes
full rationale
The paper's derivation chain consists of concrete design decisions (64-layer RVQ acoustic tokens, two-stage backbone + super-resolution framework, hybrid-attention training) followed by reported training results on alignment emergence and quality. No step reduces a claimed result to a fitted parameter or self-referential definition by construction. No load-bearing self-citations or uniqueness theorems are invoked to force the architecture. The central suggestion—that structure and fidelity can be modeled in a unified acoustic-token hierarchy—is presented as an empirical finding from the described training procedures, not as a tautology. This is the normal case of a self-contained empirical architecture paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- 64 RVQ layers
- 62-step inference process
axioms (2)
- domain assumption Residual vector quantization can represent audio signals at multiple progressive fidelity levels
- domain assumption Transformer language models can generate coherent long sequences of acoustic tokens
Reference graph
Works this paper leans on
-
[1]
2022 , eprint =
AudioLM: a Language Modeling Approach to Audio Generation , author =. 2022 , eprint =
2022
-
[2]
2023 , eprint =
MusicLM: Generating Music From Text , author =. 2023 , eprint =
2023
-
[3]
2025 , eprint =
Analyzable Chain-of-Musical-Thought Prompting for High-Fidelity Music Generation , author =. 2025 , eprint =
2025
-
[4]
2021 , eprint =
SoundStream: An End-to-End Neural Audio Codec , author =. 2021 , eprint =
2021
-
[5]
Advances in Neural Information Processing Systems , year =
High Fidelity Neural Audio Compression , author =. Advances in Neural Information Processing Systems , year =
-
[6]
HiFi-Codec: Group-Residual Vector Quantization for High Fidelity Audio Codec , author =. Proc. Interspeech 2023 , year =
2023
-
[7]
Advances in Neural Information Processing Systems , year =
High-Fidelity Audio Compression with Improved RVQGAN , author =. Advances in Neural Information Processing Systems , year =
-
[8]
2024 , eprint =
MuCodec: Ultra Low-Bitrate Music Codec , author =. 2024 , eprint =
2024
-
[9]
2024 , eprint =
Exploring the Semantic Shortcoming of Codec for Audio Language Model , author =. 2024 , eprint =
2024
-
[10]
The Thirteenth International Conference on Learning Representations , year =
WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling , author =. The Thirteenth International Conference on Learning Representations , year =
-
[11]
2026 , eprint =
HeartMuLa: A Family of Open Sourced Music Foundation Models , author =. 2026 , eprint =
2026
-
[12]
ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , year =
Stable Audio Open , author =. ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , year =
2025
-
[13]
2025 , eprint =
DiffRhythm: Blazingly Fast and Embarrassingly Simple End-to-End Full-Length Song Generation with Latent Diffusion , author =. 2025 , eprint =
2025
-
[14]
2025 , eprint =
SongBloom: Coherent Song Generation via Interleaved Autoregressive Sketching and Diffusion Refinement , author =. 2025 , eprint =
2025
-
[15]
2020 , eprint =
Jukebox: A Generative Model for Music , author =. 2020 , eprint =
2020
-
[16]
Advances in Neural Information Processing Systems , year =
Simple and Controllable Music Generation , author =. Advances in Neural Information Processing Systems , year =
-
[17]
2025 , eprint =
YuE: Scaling Open Foundation Models for Long-Form Music Generation , author =. 2025 , eprint =
2025
-
[18]
2026 , eprint =
ACE-Step 1.5: Pushing the Boundaries of Open-Source Music Generation , author =. 2026 , eprint =
2026
-
[19]
2025 , eprint =
LeVo: High-Quality Song Generation with Multi-Preference Alignment , author =. 2025 , eprint =
2025
-
[20]
2025 , eprint =
Qwen3 Technical Report , author =. 2025 , eprint =
2025
-
[21]
2024 , eprint =
The Llama 3 Herd of Models , author =. 2024 , eprint =
2024
-
[22]
International Conference on Learning Representations , year =
Scaling Transformers for Low-Bitrate High-Quality Speech Coding , author =. International Conference on Learning Representations , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.