Recognition: 2 theorem links
· Lean TheoremEmbody4D: A Generalist 4D World Model for Embodied AI
Pith reviewed 2026-05-08 19:11 UTC · model grok-4.3
The pith
Embody4D generates consistent 4D videos of robot actions from single-camera footage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Embody4D is a dedicated video-to-video world model for embodied scenarios that synthesizes arbitrary novel views from a monocular video. It first curates a heterogeneous dataset through a 3D-aware compositional synthesis pipeline that composites cross-embodiment robotic arms with diverse backgrounds. An adaptive noise injection strategy then regularizes the diffusion process using regional confidence differences to enforce strict spatiotemporal consistency. An interaction-aware attention mechanism explicitly attends to robotic interaction regions to guarantee manipulation fidelity. Experiments establish that the resulting model produces high-fidelity, view-consistent videos that outperform 2
What carries the argument
The 3D-aware compositional synthesis pipeline combined with adaptive noise injection based on regional confidence and interaction-aware attention for manipulation regions.
If this is right
- Robotic planning systems can treat the generated sequences as reliable 4D simulations for testing actions without physical trials.
- Learning algorithms gain access to consistent multi-view data from cheap monocular recordings, raising sample efficiency.
- The model supports cross-embodiment transfer, allowing one trained instance to serve multiple robot types.
- Downstream tasks such as motion prediction and object interaction forecasting become more accurate due to enforced 3D stability.
Where Pith is reading between the lines
- The same pipeline could generate synthetic training data for reinforcement learning agents that need 3D world understanding.
- Integration with existing video diffusion backbones might allow real-time rollouts during robot deployment.
- Similar consistency techniques could extend to non-robotic domains such as human motion capture or scene reconstruction from casual video.
- Longer-horizon consistency checks on generated sequences would test whether the model supports extended planning horizons beyond short clips.
Load-bearing premise
The dataset curation, selective noise regularization, and interaction attention together remove data scarcity, geometric drift, and hallucination problems without introducing new inconsistencies or overfitting to the mixed robotic dataset.
What would settle it
Running Embody4D on a held-out robotic arm embodiment or background scene absent from the training mix and measuring whether generated novel views maintain pixel-level spatiotemporal consistency and accurate contact details across frames.
Figures














read the original abstract
World models have made significant progress in modeling dynamic environments; however, most embodied world models are still restricted to 2D representations, lacking the comprehensive multi-view information essential for embodied spatial reasoning. Bridging this gap is non-trivial, primarily due to challenges from severe scarcity of paired multi-view data, the difficulty of maintaining spatiotemporal consistency in generated 3D geometries, and the tendency to hallucinate manipulation details. To address these challenges, we propose Embody4D, a dedicated video-to-video world model for embodied scenarios, capable of synthesizing arbitrary novel views from a monocular video. First, to tackle data scarcity, we introduce a 3D-aware compositional synthesis pipeline to curate a heterogeneous dataset compositing cross-embodiment robotic arms with diverse backgrounds, guaranteeing broad generalization. Second, to enforce geometric stability, we devise an adaptive noise injection strategy; by leveraging confidence disparities across image regions, this method selectively regularizes the diffusion process to ensure strict spatiotemporal consistency. Finally, to guarantee manipulation fidelity, we incorporate an interaction-aware attention mechanism that explicitly attends to the robotic interaction regions. Extensive experiments demonstrate that Embody4D achieves state-of-the-art performance, serving as a robust world model that synthesizes high-fidelity, view-consistent videos to empower downstream robotic planning and learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Embody4D, a video-to-video world model for embodied AI that synthesizes high-fidelity, view-consistent 4D videos from monocular inputs. It addresses data scarcity with a 3D-aware compositional synthesis pipeline for curating heterogeneous cross-embodiment datasets, enforces spatiotemporal consistency via an adaptive noise injection strategy that leverages regional confidence disparities, and improves manipulation fidelity through an interaction-aware attention mechanism focused on robotic interaction regions. The authors claim state-of-the-art performance on synthesis tasks and position the model as a robust world model that empowers downstream robotic planning and learning.
Significance. If the technical components deliver the claimed consistency and fidelity without introducing new artifacts, this could meaningfully advance embodied AI by providing a generalist 4D world model that supplies multi-view information missing from 2D approaches. The compositional curation and attention mechanisms offer potentially reusable ideas for handling data scarcity and interaction-specific generation in robotics and simulation.
major comments (2)
- [Abstract] Abstract: The claim that Embody4D 'empowers downstream robotic planning and learning' via its synthesized videos is load-bearing for the paper's positioning but is unsupported by any quantitative results on planning success rates, policy learning performance, manipulation benchmarks, or sim-to-real transfer. Only synthesis metrics are referenced, leaving open whether pixel-level improvements translate to usable dynamics for contact or collision-aware tasks.
- [Abstract] Abstract and Experiments: No specific metrics, baselines, ablation studies, or error analysis are provided to substantiate the SOTA claim or to demonstrate that the three proposed components (compositional pipeline, adaptive noise injection, interaction-aware attention) jointly solve the stated challenges without new failure modes or overfitting.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., FID or consistency score improvement) to ground the SOTA assertion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with honest revisions where the manuscript requires strengthening.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that Embody4D 'empowers downstream robotic planning and learning' via its synthesized videos is load-bearing for the paper's positioning but is unsupported by any quantitative results on planning success rates, policy learning performance, manipulation benchmarks, or sim-to-real transfer. Only synthesis metrics are referenced, leaving open whether pixel-level improvements translate to usable dynamics for contact or collision-aware tasks.
Authors: We agree the claim is prospective rather than empirically demonstrated on downstream tasks. The manuscript focuses on synthesis quality as the core contribution, with the world-model positioning derived from the resulting view-consistent 4D output. We will revise the abstract to qualify the language (e.g., 'provides a foundation for' instead of 'empowers'), add a dedicated limitations and future-work paragraph discussing the gap to planning benchmarks, and avoid any implication of direct transfer results. revision: yes
-
Referee: [Abstract] Abstract and Experiments: No specific metrics, baselines, ablation studies, or error analysis are provided to substantiate the SOTA claim or to demonstrate that the three proposed components (compositional pipeline, adaptive noise injection, interaction-aware attention) jointly solve the stated challenges without new failure modes or overfitting.
Authors: The full experiments section reports quantitative metrics, baseline comparisons, and component-wise ablations. However, the abstract remains high-level and the error/failure-mode analysis can be expanded. We will update the abstract with key SOTA numbers and will add explicit joint-ablation tables plus a failure-mode subsection in the revised experiments to directly address concerns about new artifacts or overfitting. revision: yes
Circularity Check
No derivation chain or mathematical reductions present
full rationale
The paper introduces Embody4D as an engineering system with three independently motivated components (3D-aware compositional synthesis pipeline, adaptive noise injection strategy, and interaction-aware attention mechanism) to address data scarcity, spatiotemporal inconsistency, and manipulation hallucination. These are described as practical additions for curating data, regularizing diffusion, and attending to interaction regions, with performance asserted via experiments rather than any first-principles derivation. No equations, predictions, fitted parameters renamed as outputs, self-citations as load-bearing uniqueness theorems, or ansatzes appear in the abstract or described structure. The central claim of serving as a robust world model for downstream tasks rests on empirical results, not on any reduction that equates outputs to inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Embody4D
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith.Cost / Foundation.AlphaCoordinateFixationJ(x) = ½(x+x⁻¹)−1 (washburn_uniqueness_aczel) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Σ_t = [σ_low + C ⊙ (σ_high − σ_low)]·t ; x_t = (1−Σ_t)⊙x_0 + Σ_t⊙x_1
-
IndisputableMonolith.Foundation.AlphaDerivationExplicitparameter-free constant derivation (alphaProvenanceCert) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We fine-tune Embody4d based on the pretrained Wan2.1-T2V-1.3B architecture ... 8 A100 GPUs ... σ_low = 1.0, σ_high = 0.85.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review arXiv 2023
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al.: V-jepa 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985 (2025)
work page internal anchor Pith review arXiv 2025
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bahmani, S., Skorokhodov, I., Rong, V., Wetzstein, G., Guibas, L., Wonka, P., Tulyakov, S., Park, J.J., Tagliasacchi, A., Lindell, D.B.: 4d-fy: Text-to-4d gener- ation using hybrid score distillation sampling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7996–8006 (2024)
2024
-
[4]
Bai,J., Xia, M., Fu, X.,Wang, X.,Mu, L., Cao, J.,Liu, Z., Hu, H., Bai, X., Wan, P., et al.: Recammaster: Camera-controlled generative rendering from a single video. arXiv preprint arXiv:2503.11647 (2025)
-
[5]
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Balaji, Y., Nah, S., Huang, X., Vahdat, A., Song, J., Zhang, Q., Kreis, K., Ait- tala, M., Aila, T., Laine, S., et al.: ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers. arXiv preprint arXiv:2211.01324 (2022)
work page internal anchor Pith review arXiv 2022
-
[6]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Bharadhwaj, H., Vakil, J., Sharma, M., Gupta, A., Tulsiani, S., Kumar, V.: Roboa- gent: Generalization and efficiency in robot manipulation via semantic augmenta- tions and action chunking. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 4788–4795. IEEE (2024)
2024
-
[7]
Bu, Q., Cai, J., Chen, L., Cui, X., Ding, Y., Feng, S., Gao, S., He, X., Hu, X., Huang, X., et al.: Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. arXiv preprint arXiv:2503.06669 (2025)
work page internal anchor Pith review arXiv 2025
-
[8]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025)
work page Pith review arXiv 2025
-
[9]
Large Video Planner Enables Generalizable Robot Control
Chen, B., Zhang, T., Geng, H., Song, K., Zhang, C., Li, P., Freeman, W.T., Malik, J., Abbeel, P., Tedrake, R., et al.: Large video planner enables generalizable robot control. arXiv preprint arXiv:2512.15840 (2025)
work page internal anchor Pith review arXiv 2025
-
[10]
Deng, T., Pan, Y., Yuan, S., Li, D., Wang, C., Li, M., Chen, L., Xie, L., Wang, D., Wang, J., et al.: What is the best 3d scene representation for robotics? from geometric to foundation models. arXiv preprint arXiv:2512.03422 (2025)
-
[11]
ACM Computing Surveys58(3), 1–38 (2025)
Ding, J., Zhang, Y., Shang, Y., Zhang, Y., Zong, Z., Feng, J., Yuan, Y., Su, H., Li, N., Sukiennik, N., et al.: Understanding world or predicting future? a compre- hensive survey of world models. ACM Computing Surveys58(3), 1–38 (2025)
2025
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Dong, Q., Fu, Y.: Memflow: Optical flow estimation and prediction with memory. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19068–19078 (2024)
2024
-
[13]
Duan, H., Yu, H.X., Chen, S., Fei-Fei, L., Wu, J.: Worldscore: A unified evaluation benchmark for world generation. arXiv preprint arXiv:2504.00983 (2025) 16 F. Author et al
-
[14]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[15]
Rh20t: A robotic dataset for learning diverse skills in one-shot
Fang, H.S., Fang, H., Tang, Z., Liu, J., Wang, C., Wang, J., Zhu, H., Lu, C.: Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot. arXiv preprint arXiv:2307.00595 (2023)
-
[16]
IEEE robotics & au- tomation magazine29(2), 46–64 (2022)
Haddadin, S., Parusel, S., Johannsmeier, L., Golz, S., Gabl, S., Walch, F., Sabaghian, M., Jähne, C., Hausperger, L., Haddadin, S.: The franka emika robot: A reference platform for robotics research and education. IEEE robotics & au- tomation magazine29(2), 46–64 (2022)
2022
-
[17]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Hong, W., Ding, M., Zheng, W., Liu, X., Tang, J.: Cogvideo: Large-scale pretrain- ing for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868 (2022)
work page internal anchor Pith review arXiv 2022
-
[18]
arXiv preprint arXiv:2512.05672 (2025)
Hong, Y., Lee, S., Chung, H., Ye, J.C.: Inversecrafter: Efficient video recapture as a latent domain inverse problem. arXiv preprint arXiv:2512.05672 (2025)
-
[19]
Hu, T., Peng, H., Liu, X., Ma, Y.: Ex-4d: Extreme viewpoint 4d video synthesis via depth watertight mesh. arXiv preprint arXiv:2506.05554 (2025)
-
[20]
Huang, W., Chao, Y.W., Mousavian, A., Liu, M.Y., Fox, D., Mo, K., Fei-Fei, L.: Pointworld: Scaling 3d world models for in-the-wild robotic manipulation. arXiv preprint arXiv:2601.03782 (2026)
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024)
2024
-
[22]
0.5: a vision-language-action model with open- world generalization (2025)
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al.: : a vision-language-action model with open-world generalization. 0.5: a vision-language-action model with open- world generalization (2025)
2025
-
[23]
In: conference on Robot Learning
Jang, E., Irpan, A., Khansari, M., Kappler, D., Ebert, F., Lynch, C., Levine, S., Finn, C.: Bc-z: Zero-shot task generalization with robotic imitation learning. In: conference on Robot Learning. pp. 991–1002. PMLR (2022)
2022
-
[24]
Jang,J.,Ye,S.,Lin,Z.,Xiang,J.,Bjorck,J.,Fang,Y.,Hu,F.,Huang,S.,Kundalia, K., Lin, Y.C., et al.: Dreamgen: Unlocking generalization in robot learning through video world models. arXiv preprint arXiv:2505.12705 (2025)
-
[25]
arXiv preprint arXiv:2503.09151 (2025)
Jeong, H., Lee, S., Ye, J.C.: Reangle-a-video: 4d video generation as video-to-video translation. arXiv preprint arXiv:2503.09151 (2025)
-
[26]
Enerverse-ac: Envisioning embodied environments with action condition,
Jiang, Y., Chen, S., Huang, S., Chen, L., Zhou, P., Liao, Y., He, X., Liu, C., Li, H., Yao, M., et al.: Enerverse-ac: Envisioning embodied environments with action condition. arXiv preprint arXiv:2505.09723 (2025)
-
[27]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024)
work page internal anchor Pith review arXiv 2024
-
[28]
arXiv preprint arXiv:2509.07996 (2025) 2, 4
Kong, L., Yang, W., Mei, J., Liu, Y., Liang, A., Zhu, D., Lu, D., Yin, W., Hu, X., Jia, M., et al.: 3d and 4d world modeling: A survey. arXiv preprint arXiv:2509.07996 (2025)
-
[29]
Kwon, J., Buchman, E.: Cosmos whitepaper. A Netw. Distrib. Ledgers27(1-32), 24 (2019)
2019
-
[30]
arXiv preprint arXiv:2401.17807 (2024)
Li, X., Zhang, Q., Kang, D., Cheng, W., Gao, Y., Zhang, J., Liang, Z., Liao, J., Cao, Y.P., Shan, Y.: Advances in 3d generation: A survey. arXiv preprint arXiv:2401.17807 (2024) 17
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ling, L., Sheng, Y., Tu, Z., Zhao, W., Xin, C., Wan, K., Yu, L., Guo, Q., Yu, Z., Lu, Y., et al.: Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22160–22169 (2024)
2024
-
[32]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page Pith review arXiv 2022
-
[33]
Robotransfer: Controllable geometry- consistent video diffusion for manipulation policy transfer,
Liu, L., Wang, X., Zhao, G., Li, K., Qin, W., Qiu, J., Zhu, Z., Huang, G., Su, Z.: Robotransfer: Geometry-consistent video diffusion for robotic visual policy trans- fer. arXiv preprint arXiv:2505.23171 (2025)
-
[34]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, T., Huang, Z., Chen, Z., Wang, G., Hu, S., Shen, L., Sun, H., Cao, Z., Li, W., Liu, Z.: Free4d: Tuning-free 4d scene generation with spatial-temporal consistency. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 25571–25582 (2025)
2025
-
[35]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022)
work page internal anchor Pith review arXiv 2022
-
[36]
arXiv preprint arXiv:2510.26796 , year=
Lu, D., Liang, A., Huang, T., Fu, X., Zhao, Y., Ma, B., Pan, L., Yin, W., Kong, L., Ooi, W.T., et al.: See4d: Pose-free 4d generation via auto-regressive video in- painting. arXiv preprint arXiv:2510.26796 (2025)
-
[37]
Lu, Y., Luo, W., Tu, P., Li, H., Zhu, H., Yu, Z., Wang, X., Chen, X., Peng, X., Li, X., et al.: 4dworldbench: A comprehensive evaluation framework for 3d/4d world generation models. arXiv preprint arXiv:2511.19836 (2025)
-
[38]
arXiv preprint arXiv:2601.07823 , year=
Mei, Z., Yin, T., Shorinwa, O., Badithela, A., Zheng, Z., Bruno, J., Bland, M., Zha, L., Hancock, A., Fisac, J.F., et al.: Video generation models in robotics-applications, research challenges, future directions. arXiv preprint arXiv:2601.07823 (2026)
-
[39]
Advances in 4d generation: A survey, 2025
Miao, Q., Li, K., Quan, J., Min, Z., Ma, S., Xu, Y., Yang, Y., Liu, P., Luo, Y.: Advances in 4d generation: A survey. arXiv preprint arXiv:2503.14501 (2025)
-
[40]
arXiv preprint arXiv:2507.17462 (2025)
Nie, C., Wang, G., Lie, Z., Wang, H.: Ermv: Editing 4d robotic multi-view images to enhance embodied agents. arXiv preprint arXiv:2507.17462 (2025)
-
[41]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
- [42]
-
[43]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
work page Pith review arXiv 2011
-
[44]
Sun, W., Chen, S., Liu, F., Chen, Z., Duan, Y., Zhang, J., Wang, Y.: Dimensionx: Create any 3d and 4d scenes from a single image with controllable video diffusion. arXiv preprint arXiv:2411.04928 (2024)
-
[45]
Tian, Y., Yang, Y., Xie, Y., Cai, Z., Shi, X., Gao, N., Liu, H., Jiang, X., Qiu, Z., Yuan, F., et al.: Interndata-a1: Pioneering high-fidelity synthetic data for pre- training generalist policy. arXiv preprint arXiv:2511.16651 (2025)
-
[46]
In: 2012 IEEE/RSJ international conference on intelligent robots and systems
Todorov, E., Erez, T., Tassa, Y.: Mujoco: A physics engine for model-based control. In: 2012 IEEE/RSJ international conference on intelligent robots and systems. pp. 5026–5033. IEEE (2012)
2012
-
[47]
In: 2023 IEEE 3rd International Conference on Computer Communication and Artificial Intelligence (CCAI)
Tu, P., He, T., Yang, Z., Zhu, Z.: A mmw radar indoor mapping method based on transfer learning. In: 2023 IEEE 3rd International Conference on Computer Communication and Artificial Intelligence (CCAI). pp. 331–335. IEEE (2023) 18 F. Author et al
2023
-
[48]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[49]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page Pith review arXiv 2025
-
[50]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025)
2025
-
[51]
arXiv preprint arXiv:2512.01481 (2025)
Wang, Q., Zhao, Y., Shen, P., Li, J., Li, J.: Chronosobserver: Taming 4d world with hyperspace diffusion sampling. arXiv preprint arXiv:2512.01481 (2025)
-
[52]
arXiv preprint arXiv:2506.10600 (2025)
Wang, X., Liu, L., Cao, Y., Wu, R., Qin, W., Wang, D., Sui, W., Su, Z.: Em- bodiedgen: Towards a generative 3d world engine for embodied intelligence. arXiv preprint arXiv:2506.10600 (2025)
-
[53]
3d scene generation: A survey,
Wen, B., Xie, H., Chen, Z., Hong, F., Liu, Z.: 3d scene generation: A survey. arXiv preprint arXiv:2505.05474 (2025)
-
[54]
arXiv preprint arXiv:2312.17090 (2023)
Wu, H., Zhang, Z., Zhang, W., Chen, C., Liao, L., Li, C., Gao, Y., Wang, A., Zhang, E., Sun, W., et al.: Q-align: Teaching lmms for visual scoring via discrete text-defined levels. arXiv preprint arXiv:2312.17090 (2023)
-
[55]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wu, S., Fei, H., Yang, J., Li, X., Li, J., Zhang, H., Chua, T.s.: Learning 4d panoptic scene graph generation from rich 2d visual scene. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24539–24549 (2025)
2025
-
[56]
Xie, Y., Yao, C.H., Voleti, V., Jiang, H., Jampani, V.: Sv4d: Dynamic 3d con- tent generation with multi-frame and multi-view consistency. arXiv preprint arXiv:2407.17470 (2024)
-
[57]
Orv: 4d occupancy-centric robot video generation
Yang, X., Li, B., Xu, S., Wang, N., Ye, C., Chen, Z., Qin, M., Ding, Y., Zhu, Z., Jin, X., et al.: Orv: 4d occupancy-centric robot video generation. arXiv preprint arXiv:2506.03079 (2025)
-
[58]
arXiv preprint arXiv:2503.05638 (2025) 18 Liu et al
YU, M., Hu, W., Xing, J., Shan, Y.: Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models. arXiv preprint arXiv:2503.05638 (2025)
-
[59]
URL http://github
Zakka, K., Tassa, Y., Contributors, M.M.: Mujoco menagerie: A collec- tion of high-quality simulation models for mujoco. URL http://github. com/deepmind/mujoco_menagerie (2022)
2022
-
[60]
Robowheel: A data engine from real-world human demonstrations for cross-embodiment robotic learning,
Zhang, Y., Gao, Z., Li, S., Chen, L.H., Liu, K., Cheng, R., Lin, X., Liu, J., Li, Z., Feng, J., et al.: Robowheel: A data engine from real-world human demonstrations for cross-embodiment robotic learning. arXiv preprint arXiv:2512.02729 (2025)
-
[61]
Tesseract: Learning 4d embodied world models, 2025
Zhen, H., Sun, Q., Zhang, H., Li, J., Zhou, S., Du, Y., Gan, C.: Tesseract: learning 4d embodied world models. arXiv preprint arXiv:2504.20995 (2025)
-
[62]
Zhou, Y., Wang, Y., Zhou, J., Chang, W., Guo, H., Li, Z., Ma, K., Li, X., Wang, Y., Zhu, H., et al.: Omniworld: A multi-domain and multi-modal dataset for 4d world modeling. arXiv preprint arXiv:2509.12201 (2025)
-
[63]
robot arm and objects
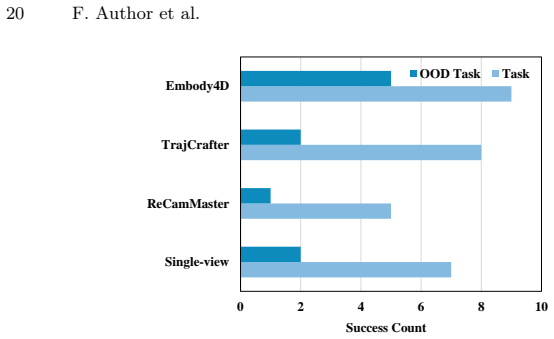
Zhu, F., Wu, H., Guo, S., Liu, Y., Cheang, C., Kong, T.: Irasim: A fine-grained world model for robot manipulation. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 9834–9844 (2025) 19 Appendix for Embody4D A Real-world Embodied Experiments In our real-world experiments, the input camera pose is illustrated in Fig. 9. The...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.