Recognition: unknown
TMD-Bench: A Multi-Level Evaluation Paradigm for Music-Dance Co-Generation
Pith reviewed 2026-05-09 16:07 UTC · model grok-4.3
The pith
TMD-Bench shows that current music-dance generators produce quality outputs but often lack consistent rhythmic coupling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
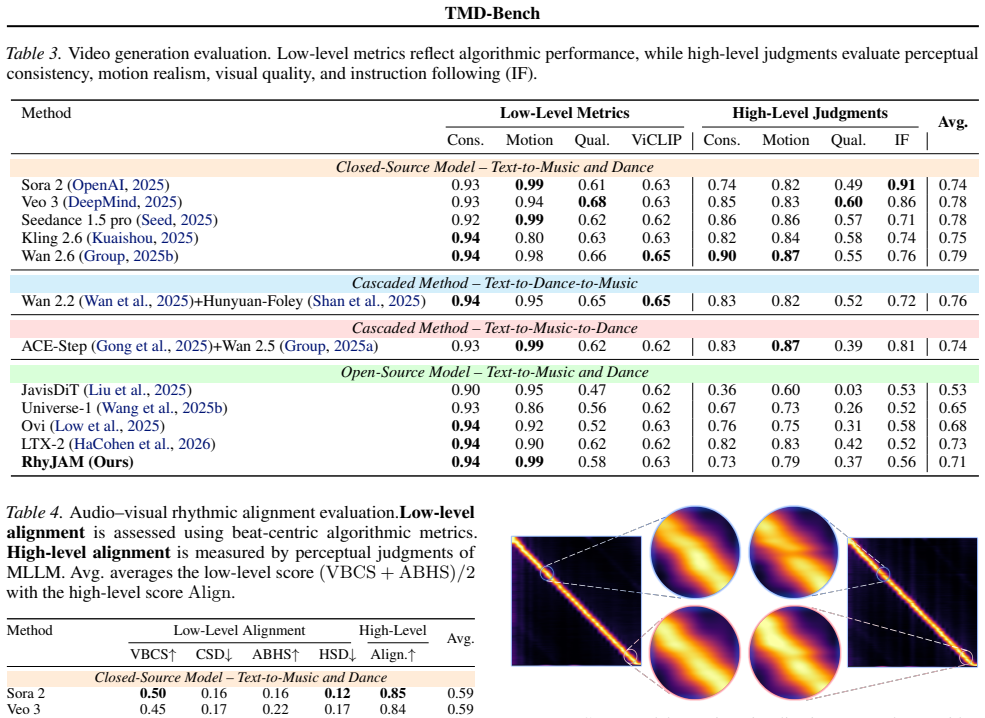
TMD-Bench evaluates music-dance co-generation systems across unimodal generation quality, instruction adherence, and cross-modal rhythmic alignment by combining computable physical metrics with perceptual multimodal judgments on a curated rhythm-aligned music-dance dataset supported by a fine-grained Music Captioner. It reveals that modern commercial audio-visual models such as Veo 3 and Sora 2 generate high-quality music and video while rhythmic coupling remains less consistently optimized. The unified baseline RhyJAM trained on rhythm-aligned data achieves competitive beat-level synchronization while maintaining competitive unimodal fidelity.
What carries the argument
TMD-Bench, the multi-level evaluation paradigm that integrates physical beat-synchronization metrics with perceptual judgments on a rhythm-aligned dataset and a structured Music Captioner.
If this is right
- Commercial models require additional optimization focused on rhythmic coupling between generated music and dance.
- Training on explicitly rhythm-aligned data enables models to reach competitive synchronization without loss of single-modality quality.
- Future music-dance systems should incorporate explicit objectives for rhythmic and kinetic coherence.
- Evaluation protocols for audio-visual generation need to combine objective metrics with human judgments to assess fine temporal alignment.
Where Pith is reading between the lines
- The same multi-level approach could be adapted to evaluate other paired generation tasks that require precise timing, such as speech-driven gesture or music-driven animation.
- Wider use of rhythm-aligned training sets may raise performance in broader audio-visual synthesis domains.
- Developers could incorporate TMD-Bench scores directly into model training loops to target synchronization improvements.
Load-bearing premise
The curated rhythm-aligned dataset together with the chosen physical metrics and perceptual judgments provide a reliable and unbiased measure of cross-modal rhythmic alignment.
What would settle it
An independent test in which models that score high on TMD-Bench rhythmic metrics receive low ratings from choreographers for actual music-dance synchronization, or vice versa, would show the benchmark does not capture the intended quality.
Figures












read the original abstract
Unified audio-visual generation is rapidly gaining industrial and creative relevance, enabling applications in virtual production and interactive media. However, when moving from general audio-video synthesis to music-dance co-generation, the task becomes substantially harder: musical rhythm, phrasing, and accents must drive choreographic motion at fine temporal resolution, and such rhythmic coupling is not captured by unimodal metrics or generic audiovisual consistency scores used in current evaluation practice. We introduce TMD-Bench, a benchmark for text-driven music-dance co-generation that assesses systems across unimodal generation quality, instruction adherence, and cross-modal rhythmic alignment. The benchmark integrates computable physical metrics with perceptual multimodal judgments, and is supported by a curated rhythm-aligned music-dance dataset and a fine-grained Music Captioner for structured music semantics. TMD-Bench further reveals that (i) modern commercial audio-visual models, such as Veo 3 and Sora 2, produce high-quality music and video, while rhythmic coupling remains less consistently optimized and leaves room for improvement, and (ii) our unified baseline RhyJAM trained on rhythm-aligned data achieves competitive beat-level synchronization while maintaining competitive unimodal fidelity. This presents prospects for building next-generation music-dance models that explicitly optimize rhythmic and kinetic coherence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TMD-Bench, a benchmark for text-driven music-dance co-generation that evaluates systems on unimodal generation quality, instruction adherence, and cross-modal rhythmic alignment. It integrates computable physical metrics with perceptual multimodal judgments, supported by a curated rhythm-aligned music-dance dataset and a fine-grained Music Captioner. Using this benchmark, the authors evaluate commercial models such as Veo 3 and Sora 2, finding high unimodal quality but inconsistent rhythmic coupling, and present a unified baseline RhyJAM trained on rhythm-aligned data that achieves competitive beat-level synchronization while maintaining unimodal fidelity.
Significance. If the benchmark's dataset, captioner, and metrics are shown to be robust and free of systematic bias, TMD-Bench would provide a valuable contribution by addressing the gap in fine-grained rhythmic evaluation for music-dance co-generation, which existing unimodal or generic audiovisual metrics do not capture. The curated dataset and RhyJAM baseline could serve as useful resources for the community, enabling more targeted progress on kinetic coherence.
major comments (3)
- [§3] §3 (Dataset Curation): The central claims about inconsistent rhythmic coupling in commercial models and the competitiveness of RhyJAM rest on the assumption that the curated rhythm-aligned music-dance dataset consists of genuinely aligned pairs without curation or genre bias. The manuscript must provide explicit details on verification of alignment (e.g., beat detection algorithms, manual annotation protocols) and genre/style distribution statistics; without these, the reported 'room for improvement' cannot be reliably interpreted.
- [§4.2] §4.2 (Metrics and Evaluation): The physical metrics for beat synchronization and perceptual judgments are claimed to assess cross-modal rhythmic alignment at fine temporal resolution. However, no ablation studies, sensitivity analysis, or correlation with human judgments on specific elements (phrasing, accents, kinetic coherence) are described to rule out confounding by unimodal quality or gaps in coverage; this directly undermines the load-bearing conclusion that commercial models leave room for improvement.
- [§5] §5 (Baseline RhyJAM): The claim that RhyJAM achieves competitive beat-level synchronization while maintaining unimodal fidelity depends on full transparency of its training procedure, architecture, and how rhythm-aligned data is leveraged. Missing details on these aspects (e.g., loss terms for alignment, data preprocessing) make it impossible to determine whether results are attributable to the benchmark design or the model itself.
minor comments (2)
- [Abstract] Abstract: The phrase 'fine temporal resolution' is used without specifying the exact temporal scales or beat granularity employed in the metrics; adding this would improve clarity.
- [Figures] Figure/Table captions: Ensure all figures comparing model outputs include explicit labels for rhythmic alignment scores and error bars where applicable.
Simulated Author's Rebuttal
We are grateful to the referee for the insightful comments that will help improve the clarity and robustness of our work on TMD-Bench. We address each of the major comments below and commit to making the suggested revisions to enhance the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Dataset Curation): The central claims about inconsistent rhythmic coupling in commercial models and the competitiveness of RhyJAM rest on the assumption that the curated rhythm-aligned music-dance dataset consists of genuinely aligned pairs without curation or genre bias. The manuscript must provide explicit details on verification of alignment (e.g., beat detection algorithms, manual annotation protocols) and genre/style distribution statistics; without these, the reported 'room for improvement' cannot be reliably interpreted.
Authors: We agree that providing more explicit details on the dataset curation is important for the community to interpret the benchmark results reliably. In the revised manuscript, we will expand Section 3 to include specific information on the alignment verification process, including the beat detection algorithms employed and the manual annotation protocols followed, as well as statistics on the genre and style distribution of the dataset. revision: yes
-
Referee: [§4.2] §4.2 (Metrics and Evaluation): The physical metrics for beat synchronization and perceptual judgments are claimed to assess cross-modal rhythmic alignment at fine temporal resolution. However, no ablation studies, sensitivity analysis, or correlation with human judgments on specific elements (phrasing, accents, kinetic coherence) are described to rule out confounding by unimodal quality or gaps in coverage; this directly undermines the load-bearing conclusion that commercial models leave room for improvement.
Authors: We thank the referee for highlighting this aspect. Our physical metrics are computed using independent feature extractors for audio beats and video motion onsets to minimize confounding with unimodal quality. To further strengthen the evaluation, we will incorporate a sensitivity analysis and report correlations with human judgments on rhythmic elements in the revised version of the paper. revision: partial
-
Referee: [§5] §5 (Baseline RhyJAM): The claim that RhyJAM achieves competitive beat-level synchronization while maintaining unimodal fidelity depends on full transparency of its training procedure, architecture, and how rhythm-aligned data is leveraged. Missing details on these aspects (e.g., loss terms for alignment, data preprocessing) make it impossible to determine whether results are attributable to the benchmark design or the model itself.
Authors: We acknowledge the need for greater transparency in describing the RhyJAM baseline. In the revised manuscript, we will provide comprehensive details on the model architecture, training procedure, loss functions including those for rhythmic alignment, and data preprocessing steps in Section 5 and the appendix. revision: yes
Circularity Check
No circularity: benchmark and dataset introduction with independent evaluation metrics
full rationale
The paper introduces TMD-Bench as a new multi-level evaluation framework for music-dance co-generation, supported by a curated rhythm-aligned dataset and a fine-grained Music Captioner. No equations, predictive derivations, or first-principles results are presented that reduce by construction to fitted parameters, self-citations, or the input data itself. Claims about commercial models (Veo 3, Sora 2) and the RhyJAM baseline are framed as empirical observations from applying the benchmark's physical metrics and perceptual judgments, which are defined independently rather than tautologically. The central contribution is the benchmark paradigm and supporting resources, not a closed-loop prediction or self-referential theorem. This is a standard non-circular benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rhythmic coupling in music-dance can be reliably measured by a combination of computable physical metrics and perceptual multimodal judgments.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Ace-step: A step towards music generation foundation model.arXiv preprint arXiv:2506.00045,
URLhttps://arxiv.org/abs/2506.00045. Group, A. T. Wan 2.5, 2025a. URL https://tongyi. aliyun.com/wan. Group, A. T. Wan 2.6, 2025b. URL https://tongyi. aliyun.com/wan. HaCohen, Y ., Brazowski, B., Chiprut, N., Bitterman, Y ., Kvochko, A., Berkowitz, A., Shalem, D., Lifschitz, D., Moshe, D., Porat, E., Richardson, E., Shiran, G., Chachy, I., Chetboun, J., F...
-
[4]
LTX-2: Efficient Joint Audio-Visual Foundation Model
URL https: //arxiv.org/abs/2601.03233. Hoi, S., Zhu, J., Yang, R., Gan, Q., and Xue, S. Omni- avatar: Efficient audio-driven avatar video generation with adaptive body animation,
-
[5]
URL https: //arxiv.org/abs/2506.18866. Hua, D., Wang, X., Zeng, B., Huang, X., Liang, H., Niu, J., Chen, X., Xu, Q., and Zhang, W. Vabench: A comprehen- sive benchmark for audio-video generation,
-
[6]
VABench: A Comprehensive Benchmark for Audio-Video Generation
URL https://arxiv.org/abs/2512.09299. Huang, Z., He, Y ., Yu, J., Zhang, F., Si, C., Jiang, Y ., Zhang, Y ., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y ., Chen, X., Wang, L., Lin, D., Qiao, Y ., and Liu, Z. Vbench: Com- prehensive benchmark suite for video generative mod- els,
work page internal anchor Pith review Pith/arXiv arXiv
- [7]
-
[8]
Li, R., Zhao, J., Zhang, Y ., Su, M., Ren, Z., Zhang, H., Tang, Y ., and Li, X
URL https://arxiv.org/abs/1911.02001. Li, R., Zhao, J., Zhang, Y ., Su, M., Ren, Z., Zhang, H., Tang, Y ., and Li, X. Finedance: A fine-grained choreography dataset for 3d full body dance generation,
-
[9]
Liang, Y ., Chen, Z., Ding, C., and Di, X
URL https://arxiv.org/abs/2212.03741. Liang, Y ., Chen, Z., Ding, C., and Di, X. Deepsound- v1: Start to think step-by-step in the audio generation from videos,
-
[10]
URL https://arxiv.org/ abs/2503.22208. Liu, K., Li, W., Chen, L., Wu, S., Zheng, Y ., Ji, J., Zhou, F., Jiang, R., Luo, J., Fei, H., and Chua, T.-S. Javisdit: Joint audio-video diffusion transformer with hierarchi- cal spatio-temporal prior synchronization,
-
[11]
URL https://arxiv.org/abs/2503.23377. Low, C., Wang, W., and Katyal, C. Ovi: Twin backbone cross-modal fusion for audio-video generation,
- [12]
-
[13]
URL https://openai.com/sora. Polyak, A., Zohar, A., Brown, A., Tjandra, A., Sinha, A., Lee, A., Vyas, A., Shi, B., Ma, C.-Y ., Chuang, C.-Y ., Yan, D., Choudhary, D., Wang, D., Sethi, G., Pang, G., Ma, H., Misra, I., Hou, J., Wang, J., ran Jagadeesh, K., Li, K., Zhang, L., Singh, M., Williamson, M., Le, M., Yu, M., Singh, M. K., Zhang, P., Vajda, P., Duva...
work page internal anchor Pith review arXiv
-
[14]
URL https: //arxiv.org/abs/2508.16930. Tjandra, A., Wu, Y .-C., Guo, B., Hoffman, J., Ellis, B., Vyas, A., Shi, B., Chen, S., Le, M., Zacharov, N., Wood, C., Lee, A., and Hsu, W.-N. Meta audiobox aesthetics: Unified automatic quality assessment for speech, music, and sound,
-
[15]
URL https://arxiv.org/abs/ 2502.05139. Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T....
-
[16]
Wan: Open and Advanced Large-Scale Video Generative Models
URL https: //arxiv.org/abs/2503.20314. Wang, C., Zhang, C., Chen, X., Chen, Z., Xu, H., Song, G., Xie, Y ., Luo, L., and Chang, D. X-dancer: Expressive music to human dance video generation, 2025a. URL https://arxiv.org/abs/2502.17414. Wang, D., Zuo, W., Li, A., Chen, L.-H., Liao, X., Zhou, D., Yin, Z., Dai, X., Jiang, D., and Yu, G. Universe-1: Unified a...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
URL https://arxiv.org/ abs/2307.06942. Wang, Z., Zhang, P., Qi, J., Xu, G. W. S., Zhang, B., and Bo, L. Omnitalker: Real-time text-driven talking head genera- tion with in-context audio-visual style replication, 2025c. URLhttps://arxiv.org/abs/2504.02433. Wu, Y ., Chen, K., Zhang, T., Hui, Y ., Nezhurina, M., Berg-Kirkpatrick, T., and Dubnov, S. Large-sca...
work page internal anchor Pith review arXiv
-
[18]
Large-scale con- trastive language-audio pretraining (clap),
URL https://arxiv.org/abs/2211.06687. Xu, J., Guo, Z., He, J., Hu, H., He, T., Bai, S., Chen, K., Wang, J., Fan, Y ., Dang, K., Zhang, B., Wang, X., Chu, Y ., and Lin, J. Qwen2.5-omni technical report,
-
[19]
URL https://arxiv.org/abs/2503.20215. You, F., Fang, M., Tang, L., Huang, R., Wang, Y ., and Zhao, Z. Momu-diffusion: On learning long-term motion- music synchronization and correspondence,
work page internal anchor Pith review arXiv
-
[20]
Zhang, G., Zhou, Z., Hu, T., Peng, Z., Zhang, Y ., Chen, Y ., Zhou, Y ., Lu, Q., and Wang, L
URL https://arxiv.org/abs/2411.01805. Zhang, G., Zhou, Z., Hu, T., Peng, Z., Zhang, Y ., Chen, Y ., Zhou, Y ., Lu, Q., and Wang, L. Uniavgen: Unified audio and video generation with asymmetric cross-modal in- teractions, 2025a. URL https://arxiv.org/abs/ 2511.03334. Zhang, R., Yu, B., Min, J., Xin, Y ., Wei, Z., Shi, J. N., Huang, M., Kong, X., Xin, N. L....
-
[21]
Raters were intentionally diverse, including five students with a computer-science background and five from non-CS majors. The 100 videos were selected to cover a wide range of dance styles, music genres, and scene contexts, and were sampled in a balanced manner with a similar number of clips from each baseline to avoid skew. To reduce potential informati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.