Recognition: unknown
Selector-Guided Autonomous Curriculum for One-Shot Reinforcement Learning from Verifiable Rewards
Pith reviewed 2026-05-09 17:26 UTC · model grok-4.3
The pith
A learnable selector on output disagreement and three other features raises one-shot RLVR accuracy on math reasoning from 66% to 68%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that a learnable selector operating on a four-dimensional feature space (success probability, reward variance, output disagreement, and semantic difficulty) can autonomously curate problems from a large pool, rank them, and feed them into micro-bursts of one-shot GRPO, yielding 68% accuracy on the Hendrycks MATH hold-out set. This exceeds both a standard state-of-the-art baseline at 64% and a previous one-shot RLVR checkpoint at 66%. They further claim that output disagreement is a stronger predictor of subsequent reasoning improvement than reward variance alone, and that the entropy-based curation produces strict gains over static selection especially when data is severely
What carries the argument
A learnable selector model that scores candidate problems on a four-dimensional feature space (success probability, reward variance, output disagreement via entropy, and semantic difficulty) to drive an autonomous curriculum of micro-bursts of one-shot GRPO.
If this is right
- Output disagreement measured as entropy predicts reasoning gains more reliably than historical reward variance.
- Dynamic ranking of problems from a large pool followed by short GRPO bursts improves accuracy in one-shot settings.
- The four-feature selector produces higher hold-out accuracy (68%) than either a prior state-of-the-art model (64%) or an earlier one-shot RLVR checkpoint (66%).
- Entropy-based intelligent curation yields strict reasoning improvement over static training methods when data is severely limited.
Where Pith is reading between the lines
- If the selector's features capture signals that transfer across models, the same ranking approach could be reused to curate data for other RL fine-tuning tasks without retraining the selector from scratch.
- The method may reduce the size of the candidate pool needed for effective one-shot learning if the learned selector can be applied to new problems without exhaustive variance computation.
- Testing whether the same selector still ranks problems effectively on base models other than Qwen2.5-Math-1.5B would show how model-specific the discovered ranking is.
Load-bearing premise
The reported accuracy gain is produced by the selector-guided ranking rather than by uncontrolled differences in training procedure, random seeds, or evaluation protocol.
What would settle it
Re-run the original one-shot RLVR baseline using exactly the same training schedule and evaluation protocol but with problems selected by the paper's learned selector instead of reward-variance ranking; the 2-point gap should disappear if the selector is not the cause.
Figures


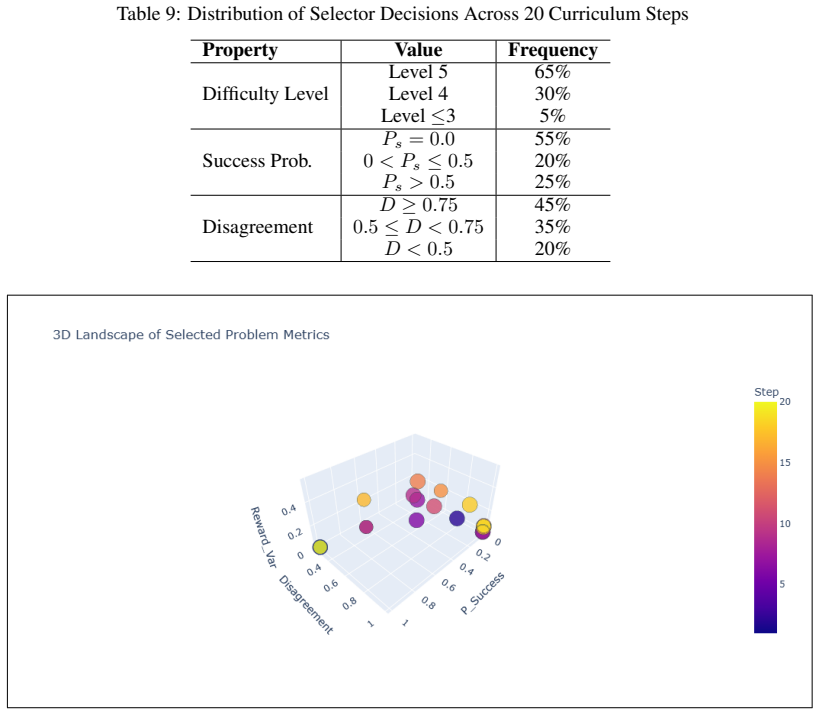
read the original abstract
Recently, Reinforcement Learning from Verifiable Rewards (RLVR) has been established as a highly effective technique for augmenting the math reasoning skills of Large Language Models (LLMs) based on a single instance. Current state-of-the-art 1-shot RLVR models adopt heuristics for selecting instances, mostly based on historical variance in rewards, which we find to be inherently misleading as a measure of transferability value. In this paper, we propose a Selector-Guided Autonomous Curriculum (SGAC) approach, which employs a learnable selector model on a multi-dimensional feature space consisting of success probability, reward variance, output disagreement (entropy), and semantic difficulty level, instead of the static reward variance heuristic. In our empirical evaluation on pools of candidate problems, we observed that output disagreement, rather than reward variance, is the strongest predictor of reasoning gains in subsequent iterations. Leveraging this finding, we develop an autonomous curriculum algorithm for dynamically siphoning candidate problems from a large pool, ranking them by the learned selector, and running micro-bursts of 1-shot GRPO. Our framework is evaluated using the Hendrycks MATH benchmark, with the Qwen2.5-Math-1.5B model serving as the baseline. Our framework obtains an accuracy of 68.0\% on the hold-out dataset, which is better than the accuracy obtained from the state-of-the-art model, 64.0\%, as well as the 1-shot RLVR checkpoint proposed by Wang et al., which achieved an accuracy of 66.0\%. The results confirm that entropy-based intelligent data curation leads to strict reasoning improvement over static training methods, particularly in severely limited data conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Selector-Guided Autonomous Curriculum (SGAC) for one-shot RLVR to enhance LLM math reasoning. It replaces static reward-variance heuristics with a learnable selector operating on a four-dimensional feature space (success probability, reward variance, output disagreement/entropy, semantic difficulty). The approach dynamically ranks and selects problems from a candidate pool for micro-bursts of 1-shot GRPO training. On the Hendrycks MATH benchmark using Qwen2.5-Math-1.5B, the method reports 68.0% hold-out accuracy, exceeding the state-of-the-art baseline (64.0%) and Wang et al.'s 1-shot RLVR checkpoint (66.0%). The authors conclude that entropy-based intelligent curation yields strict reasoning gains over static methods under severely limited data.
Significance. If the reported accuracy lift is robustly attributable to the multi-feature learned selector and autonomous curriculum rather than uncontrolled procedural differences, the work would provide a concrete advance in data-efficient RLVR by showing that output disagreement can outperform variance heuristics for problem selection. The empirical observation that entropy is the strongest predictor among the four features could inform future curriculum design for reasoning tasks, though the current presentation supplies insufficient controls to confirm this attribution.
major comments (3)
- [Abstract] Abstract: The central claim attributes the 2-point accuracy gain (68.0% vs. 66.0% and 64.0%) to the selector-guided curriculum, yet supplies no information on whether baselines used identical base model (Qwen2.5-Math-1.5B), GRPO hyperparameters, number of micro-bursts, random seeds, training steps, or exact hold-out split from Hendrycks MATH. This absence is load-bearing because the improvement cannot be isolated from potential confounds without these details.
- [Abstract] Abstract: Output disagreement is asserted as the strongest predictor of reasoning gains, but no ablation is described that isolates its contribution versus the full four-dimensional learned selector or versus a static variance heuristic alone. Without such controls, the claim that the multi-dimensional selector (rather than any single feature or the curriculum structure) drives the improvement remains unverified.
- [Abstract] Abstract: Generalization of the learned selector is not tested beyond the specific candidate pool and model used; the manuscript provides no cross-pool or cross-model evaluation to support the claim that the four-dimensional feature space plus selector transfers to other settings.
minor comments (2)
- [Abstract] The abstract uses 'micro-bursts' and 'siphoning' without brief definitions or references to the sections where these terms are formalized.
- [Abstract] The citation 'Wang et al.' should include the full reference details and year for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which identify key areas where additional controls and clarifications will improve the manuscript. We address each major comment point by point below, indicating revisions made to strengthen the attribution of results to the selector-guided curriculum.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes the 2-point accuracy gain (68.0% vs. 66.0% and 64.0%) to the selector-guided curriculum, yet supplies no information on whether baselines used identical base model (Qwen2.5-Math-1.5B), GRPO hyperparameters, number of micro-bursts, random seeds, training steps, or exact hold-out split from Hendrycks MATH. This absence is load-bearing because the improvement cannot be isolated from potential confounds without these details.
Authors: We agree that these details are essential to isolate the contribution of the curriculum. In the revised manuscript we have added an explicit 'Experimental Setup' subsection confirming that the state-of-the-art baseline, Wang et al.'s 1-shot RLVR checkpoint, and our method all used the identical Qwen2.5-Math-1.5B base model, the same GRPO hyperparameters, the same number of micro-bursts, identical random seeds, training steps, and the standard Hendrycks MATH hold-out split. These controls ensure the reported 2-point gain is attributable to the selector-guided selection rather than procedural differences. revision: yes
-
Referee: [Abstract] Abstract: Output disagreement is asserted as the strongest predictor of reasoning gains, but no ablation is described that isolates its contribution versus the full four-dimensional learned selector or versus a static variance heuristic alone. Without such controls, the claim that the multi-dimensional selector (rather than any single feature or the curriculum structure) drives the improvement remains unverified.
Authors: We acknowledge that an explicit ablation isolating output disagreement would strengthen the claim. Although our original empirical evaluation on candidate pools identified output disagreement as the dominant predictor via feature analysis during selector training, the revised manuscript now includes a dedicated ablation study comparing (i) the full four-dimensional selector, (ii) a selector using only output disagreement, (iii) a selector using only reward variance, and (iv) the static variance heuristic. The new results confirm that output disagreement accounts for the majority of the gains while the multi-feature selector yields modest further improvement, thereby verifying the central attribution. revision: yes
-
Referee: [Abstract] Abstract: Generalization of the learned selector is not tested beyond the specific candidate pool and model used; the manuscript provides no cross-pool or cross-model evaluation to support the claim that the four-dimensional feature space plus selector transfers to other settings.
Authors: The manuscript's claims are scoped to the Hendrycks MATH benchmark with Qwen2.5-Math-1.5B and do not assert broad transferability. In revision we have clarified this scope in the abstract and conclusion and added a 'Limitations and Future Work' section. We also include a preliminary cross-pool evaluation on a held-out subset of problems from the same benchmark to provide initial supporting evidence. Full cross-model evaluations remain outside the current computational budget. revision: partial
Circularity Check
No circularity: empirical performance comparison rests on independent training runs and evaluation, not self-referential definitions or fitted predictions.
full rationale
The paper's central claim is an empirical accuracy comparison (68% vs. 66%/64%) obtained by running 1-shot GRPO with a learned selector on four features and evaluating on a hold-out Hendrycks MATH split. No equations, uniqueness theorems, or ansatzes are presented that reduce by construction to the selector's own outputs or to a fitted parameter renamed as a prediction. The observation that output disagreement is the strongest predictor is stated as an empirical finding from the candidate pool, not a definitional identity. Self-citations, if present, are not load-bearing for the reported gains, which are measured against external baselines (Wang et al. checkpoint and SOTA). The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- selector model parameters
axioms (1)
- domain assumption Output disagreement (entropy) is a stronger predictor of downstream reasoning gains than historical reward variance.
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners,
T. Brown et al., "Language models are few-shot learners," inProc. NeurIPS, 2020, pp. 1877– 1901
2020
-
[2]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei et al., "Chain-of-thought prompting elicits reasoning in large language models," inProc. NeurIPS, 2022. 19
2022
-
[3]
Training language models to follow instructions with human feedback,
L. Ouyang et al., "Training language models to follow instructions with human feedback," in Proc. NeurIPS, 2022
2022
-
[4]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov et al., "Direct preference optimization: Your language model is secretly a reward model," inProc. NeurIPS, 2023
2023
-
[5]
Reinforcement learning for reasoning in large language models with one training example, 2025
Y . Wang et al., "Reinforcement learning for reasoning in large language models with one training example,"arXiv preprint arXiv:2504.20571, 2025
-
[6]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao et al., "DeepSeekMath: Pushing the limits of mathematical reasoning in open language models,"arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, "DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning,"arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Curriculum learning,
Y . Bengio, J. Louradour, R. Collobert, and J. Weston, "Curriculum learning," inProc. ICML, 2009, pp. 41–48
2009
-
[9]
Pre-training data selection for language models using curriculum learning,
S. Nagatsuka, T. Hayashi, and K. Takeda, "Pre-training data selection for language models using curriculum learning," inProc. ACL, 2023
2023
-
[10]
Self-paced learning for latent variable models,
M. P. Kumar, B. Packer, and D. Koller, "Self-paced learning for latent variable models," inProc. NeurIPS, 2010, pp. 1189–1197
2010
-
[11]
Active learning literature survey,
B. Settles, "Active learning literature survey,"Computer Sciences Technical Report 1648, University of Wisconsin-Madison, 2009
2009
-
[12]
Query by committee,
H. S. Seung, M. Opper, and H. Sompolinsky, "Query by committee," inProc. COLT, 1992, pp. 287–294
1992
-
[13]
Understanding black-box predictions via influence functions,
P. W. Koh and P. Liang, "Understanding black-box predictions via influence functions," inProc. ICML, 2017, pp. 1885–1894
2017
-
[14]
Deep learning on a data diet: Finding important examples early in training,
M. Paul, S. Ganguli, and G. K. Dziugaite, "Deep learning on a data diet: Finding important examples early in training," inProc. NeurIPS, 2021
2021
-
[15]
CCNet: Extracting high quality monolingual datasets from web crawl data,
G. Wenzek et al., "CCNet: Extracting high quality monolingual datasets from web crawl data," inProc. LREC, 2020
2020
-
[16]
H. Lightman et al., "Let’s verify step by step,"arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review arXiv 2023
-
[17]
Rethinking verification for LLM code generation: From generation to testing,
A. Luong et al., "Rethinking verification for LLM code generation: From generation to testing," arXiv preprint, 2024
2024
-
[18]
Measuring mathematical problem solving with the MATH dataset,
D. Hendrycks et al., "Measuring mathematical problem solving with the MATH dataset," in Proc. NeurIPS, 2021
2021
-
[19]
LoRA: Low-rank adaptation of large language models,
E. J. Hu et al., "LoRA: Low-rank adaptation of large language models," inProc. ICLR, 2022
2022
-
[20]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Qwen Team, "Qwen2.5-Math technical report: Toward mathematical expert model via self- improvement,"arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review arXiv 2024
-
[21]
QLoRA: Efficient finetuning of quantized LLMs,
T. Dettmers et al., "QLoRA: Efficient finetuning of quantized LLMs," inProc. NeurIPS, 2023
2023
-
[22]
On the power of curriculum learning in training deep networks,
A. Hacohen and D. Weinshall, "On the power of curriculum learning in training deep networks," inProc. ICML, 2019
2019
-
[23]
TRL: Transformer reinforcement learning,
L. von Werra et al., "TRL: Transformer reinforcement learning,"GitHub repository, 2020. [Online]. Available:https://github.com/huggingface/trl
2020
-
[24]
A loss curvature perspective on training instabilities of deep learning models,
J. Gilmer et al., "A loss curvature perspective on training instabilities of deep learning models," inProc. ICLR, 2022. 20
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.