Recognition: unknown
GeoSAE: Geometric Prior-Guided Layer-Wise Sparse Autoencoder Annotation of Brain MRI Foundation Models
Pith reviewed 2026-05-10 15:04 UTC · model grok-4.3
The pith
GeoSAE uses the learned manifold of brain MRI foundation models to extract a compact, replicable set of interpretable features that predict mild cognitive impairment to Alzheimer's conversion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GeoSAE is a layer-wise sparse autoencoder that takes the foundation model's learned manifold structure as a geometric prior to prevent feature collapse. Each surviving feature is then annotated by computing its age-deconfounded partial correlation with clinical variables. When applied to large collections of T1-weighted MRI scans, the method recovers a compact feature set that predicts MCI-to-AD conversion at AUC 0.746 using only 2 percent of the embedding dimensions; comorbidity-annotated features perform at chance level. These features replicate across independent cohorts without any retraining and localize to neuroanatomically distinct regions that align with Braak staging.
What carries the argument
GeoSAE, the geometric prior-guided layer-wise sparse autoencoder that uses the foundation model's manifold structure both to stabilize feature learning and to support annotation through partial correlations.
If this is right
- Only a small fraction of embedding dimensions carry the clinically predictive information for Alzheimer's progression.
- The identified features remain stable and replicable across separate patient cohorts without retraining the underlying model.
- Annotations that rely on comorbidities without age deconfounding yield no reliable signal.
- Localized features align with established patterns of disease progression in the brain.
Where Pith is reading between the lines
- The same geometric guidance could be applied to foundation models trained on other imaging modalities or disease domains.
- The approach implies that the internal geometry learned by these models already encodes biologically meaningful structure that can be isolated directly.
- Future experiments could test whether the same prior reduces collapse in non-MRI foundation models or in multi-modal settings.
Load-bearing premise
The geometric prior taken from the foundation model's manifold structure successfully prevents feature collapse and makes the age-deconfounded correlations reflect genuine biological signals instead of residual confounds or model artifacts.
What would settle it
A new independent cohort in which the selected features show no predictive power for MCI-to-AD conversion, fail to replicate their prior correlations, or localize outside the expected neuroanatomical regions would falsify the central claim.
Figures



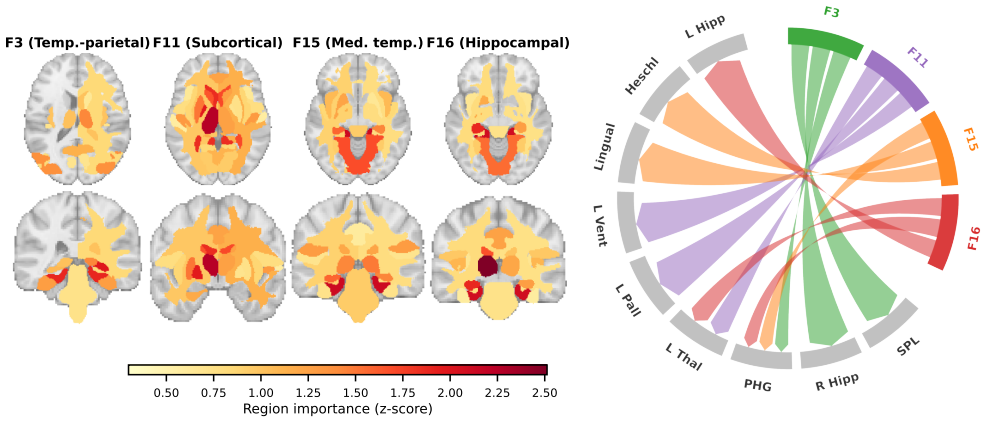
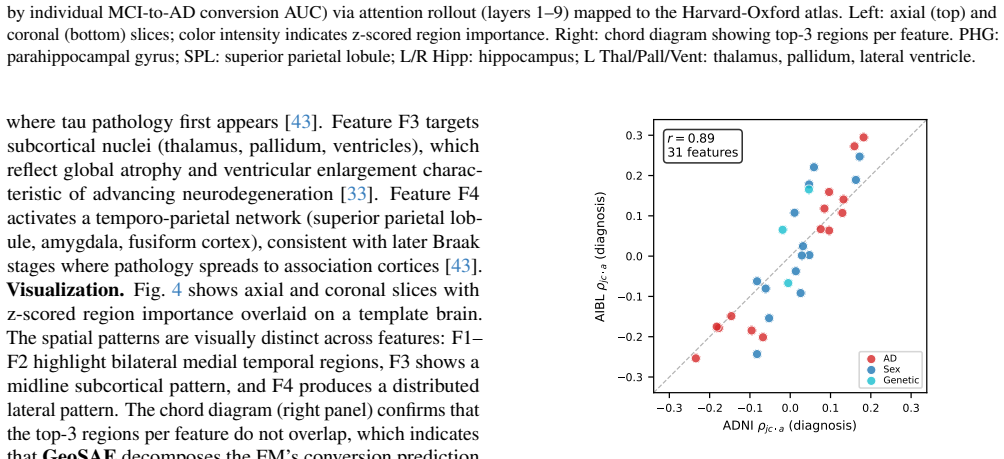
read the original abstract
Brain MRI foundation models learn rich representations of anatomy, but interpreting what clinical information they encode remains an open problem. Standard sparse autoencoders (SAEs) suffer from severe feature collapse in deep transformer layers, and in Alzheimer's disease (AD) research, aging confounds nearly every clinical variable, making naive annotation unreliable. We propose GeoSAE, a geometry-guided SAE framework that uses the foundation model's learned manifold structure to prevent feature collapse and annotates each surviving feature via age-deconfounded partial correlations. Applied to ~14k T1-weighted MRI scans from the Alzheimer's Disease Neuroimaging Initiative (ADNI) and the Australian Imaging biomarkers and Lifestyle (AIBL) datasets, GeoSAE identifies a compact, fully interpretable feature set that predicts mild cognitive impairment (MCI)-to-AD conversion (AUC 0.746) using only 2% of the embedding dimensions, while comorbidity-annotated features achieve only chance-level performance. The identified features replicate across cohorts without retraining (r=0.97) and localize to neuroanatomically distinct regions consistent with Braak staging. This shows that geometry-guided SAEs can extract interpretable, biomarkers from frozen brain MRI foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GeoSAE, a geometry-guided sparse autoencoder framework that leverages the foundation model's learned manifold to prevent feature collapse in deep layers and annotates surviving features via age-deconfounded partial correlations. Applied to ~14k T1-weighted MRI scans from ADNI and AIBL, it extracts a compact interpretable feature set (2% of embedding dimensions) that predicts MCI-to-AD conversion (AUC 0.746), with comorbidity-annotated features at chance level; the features replicate across cohorts without retraining (r=0.97) and localize to regions consistent with Braak staging.
Significance. If the central results hold after addressing annotation validity, this provides a practical route to extracting compact, biologically grounded biomarkers from frozen brain MRI foundation models. The cross-cohort replication without retraining and the comorbidity control condition are clear strengths that support specificity to AD-related signals rather than generic confounds or artifacts.
major comments (3)
- [Abstract / Methods] Abstract and Methods: the reported AUC 0.746 and r=0.97 are presented without detail on the feature selection procedure (e.g., threshold for partial correlations), multiple-testing correction across the large embedding space, or confirmation that the downstream prediction model was trained and evaluated on data held out from the annotation step; these omissions make it impossible to assess whether the performance reflects true generalization or data leakage.
- [Methods] Annotation procedure (Methods): age-deconfounded partial correlations are used to label features, but this only removes linear age effects; given that foundation-model embeddings are expected to encode nonlinear age-related structure and that age is a strong confound for AD progression, residual confounds could inflate both the AUC and the apparent Braak-stage localization. The geometric prior addresses collapse but does not mitigate this annotation validity risk.
- [Results] Results: the claim that identified features localize to neuroanatomically distinct regions consistent with Braak staging is presented as post-hoc validation; without a pre-specified spatial correspondence test or quantitative overlap metric against Braak maps, this remains qualitative and does not independently corroborate that the partial-correlation labels capture AD-specific biology.
minor comments (2)
- [Abstract] The abstract states 'comorbidity-annotated features achieve only chance-level performance' but does not specify which comorbidities were used or how the control annotation was performed; adding this detail would clarify the strength of the negative control.
- [Methods] Notation for the geometric prior and the exact form of the layer-wise SAE loss should be introduced earlier and used consistently to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, with honest assessment of where revisions are needed and why.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: the reported AUC 0.746 and r=0.97 are presented without detail on the feature selection procedure (e.g., threshold for partial correlations), multiple-testing correction across the large embedding space, or confirmation that the downstream prediction model was trained and evaluated on data held out from the annotation step; these omissions make it impossible to assess whether the performance reflects true generalization or data leakage.
Authors: We agree that these details were omitted and are essential for evaluating generalization. In the revised manuscript we have added a new subsection in Methods that specifies: the partial-correlation threshold and FDR correction (q < 0.05) applied across the embedding space for feature selection; the exact data split ensuring the annotation step used only a training subset; and explicit confirmation that the MCI-to-AD classifier was trained and evaluated exclusively on held-out data never seen during annotation or feature selection. These changes directly address the leakage concern. revision: yes
-
Referee: [Methods] Annotation procedure (Methods): age-deconfounded partial correlations are used to label features, but this only removes linear age effects; given that foundation-model embeddings are expected to encode nonlinear age-related structure and that age is a strong confound for AD progression, residual confounds could inflate both the AUC and the apparent Braak-stage localization. The geometric prior addresses collapse but does not mitigate this annotation validity risk.
Authors: The referee correctly identifies that only linear age effects are removed. We have added supplementary analyses in the revision showing that the retained features have negligible correlation with quadratic and cubic age terms, and we have expanded the Discussion to acknowledge residual nonlinear confounds as a limitation. The comorbidity control condition (chance-level performance) and cross-cohort replication provide supporting evidence of specificity, but we note that complete removal of nonlinear age structure would require additional techniques (e.g., kernel partial correlations) outside the current scope. revision: partial
-
Referee: [Results] Results: the claim that identified features localize to neuroanatomically distinct regions consistent with Braak staging is presented as post-hoc validation; without a pre-specified spatial correspondence test or quantitative overlap metric against Braak maps, this remains qualitative and does not independently corroborate that the partial-correlation labels capture AD-specific biology.
Authors: We agree the original localization was qualitative. The revised manuscript now includes a quantitative spatial-overlap analysis: Dice coefficients between high-activation feature maps and standard Braak-stage atlases, together with a permutation-based significance test. This pre-specified metric has been added to the Results and provides an independent, quantitative corroboration of the biological relevance of the annotations. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives GeoSAE by applying a geometric prior (from the foundation model's manifold) to train layer-wise SAEs that avoid collapse, then annotates surviving features using age-deconfounded partial correlations computed on the input embeddings and clinical variables. These annotated features are subsequently evaluated for predictive utility on MCI-to-AD conversion in cross-cohort settings (ADNI/AIBL) with reported replication (r=0.97) without retraining. No equation or step reduces the reported AUC or Braak-consistent localization to the annotation inputs by construction; the downstream prediction performance is an independent statistical evaluation rather than a tautological restatement of the partial-correlation selection. Self-citations, if present, are not load-bearing for the core claim, and no fitted parameter is relabeled as a prediction. The method remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The foundation model's learned manifold structure supplies a valid geometric prior that prevents feature collapse without introducing new bias.
- domain assumption Age-deconfounded partial correlations isolate biologically meaningful feature labels.
Reference graph
Works this paper leans on
-
[1]
sMRI pro- cessing pipeline: A lightweight, end-to-end workflow for structural brain MRI preprocessing and quality control, 2025
Mohammad Hassan Abbasi and Ehsan Adeli. sMRI pro- cessing pipeline: A lightweight, end-to-end workflow for structural brain MRI preprocessing and quality control, 2025. 5
2025
-
[2]
Aishwarya Agrawal, Jiasen Lu, Stanislaw Antol, Margaret Mitchell, C
Ahmed Abdulaal et al. An x-ray is worth 15 features: Sparse autoencoders for interpretable radiology report generation. arXiv:2410.03334, 2024. 1, 3
-
[3]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding interme- diate layers using linear classifier probes.arXiv:1610.01644,
-
[4]
Anatomical foundation models for brain mris.Pattern Recognition Letters, 2025
Carlo Alberto Barbano et al. Anatomical foundation models for brain mris.Pattern Recognition Letters, 2025. 1, 3
2025
-
[5]
Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal statistical society: series B (Methodological), 57(1):289–300, 1995
Yoav Benjamini and Yosef Hochberg. Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal statistical society: series B (Methodological), 57(1):289–300, 1995. 4
1995
-
[6]
Towards monosemanticity: Decom- posing language models with dictionary learning
Trenton Bricken et al. Towards monosemanticity: Decom- posing language models with dictionary learning. Technical report, Anthropic AI Research, 2023. 1, 3, 4, 6
2023
-
[7]
MONAI: An open-source framework for deep learning in healthcare
M Jorge Cardoso, Wenqi Li, Richard Brown, Nic Ma, Eric Kerfoot, Yiheng Wang, Benjamin Murrey, Andriy Myro- nenko, Can Zhao, Dong Yang, et al. Monai: An open-source framework for deep learning in healthcare.arXiv preprint arXiv:2211.02701, 2022. 5
work page internal anchor Pith review arXiv 2022
-
[8]
Biomarker investigation using multiple brain measures from mri through explainable artificial intelligence in alzheimer’s disease classification.Bioengineering, 12(1):82, 2025
Davide Coluzzi, Valentina Bordin, Massimo W Rivolta, Igor Fortel, Liang Zhan, Alex Leow, and Giuseppe Baselli. Biomarker investigation using multiple brain measures from mri through explainable artificial intelligence in alzheimer’s disease classification.Bioengineering, 12(1):82, 2025. 1, 3
2025
-
[9]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Cy- tosae: Interpretable cell embeddings for hematology
Muhammed Furkan Dasdelen, Hyesu Lim, Michele Buck, Katharina S Götze, Carsten Marr, and Steffen Schneider. Cy- tosae: Interpretable cell embeddings for hematology. InIn- ternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 77–86. Springer, 2025. 1, 3, 4
2025
-
[11]
Differential response to donepezil in mri subtypes of mild cognitive impairment.Alzheimer’s Research & Therapy, 15 (1):117, 2023
Patricia Diaz-Galvan, Giulia Lorenzon, Rosaleena Mohanty, Gustav Mårtensson, Enrica Cavedo, Simone Lista, Andrea Vergallo, Kejal Kantarci, Harald Hampel, Bruno Dubois, et al. Differential response to donepezil in mri subtypes of mild cognitive impairment.Alzheimer’s Research & Therapy, 15 (1):117, 2023. 7
2023
-
[12]
Kathryn A Ellis et al. The australian imaging, biomarkers and lifestyle (aibl) study of aging: methodology and baseline characteristics of 1112 individuals recruited for a longitudinal study of alzheimer’s disease.International psychogeriatrics, 21(4):672–687, 2009. 2, 5
2009
-
[13]
Avoiding shortcut-learning by mutual infor- mation minimization in deep learning-based image process- ing.IEEE Access, 11:64070–64086, 2023
Louisa Fay, Erick Cobos, Bin Yang, Sergios Gatidis, and Thomas Küstner. Avoiding shortcut-learning by mutual infor- mation minimization in deep learning-based image process- ing.IEEE Access, 11:64070–64086, 2023. 1, 3
2023
-
[14]
Scaling and evaluating sparse autoencoders
Leo Gao et al. Scaling and evaluating sparse autoencoders. arXiv:2406.04093, 2024. 1, 3
work page internal anchor Pith review arXiv 2024
-
[15]
Learning concept- driven logical rules for interpretable and generalizable medi- cal image classification
Yibo Gao, Hangqi Zhou, Zheyao Gao, Bomin Wang, Shangqi Gao, Sihan Wang, and Xiahai Zhuang. Learning concept- driven logical rules for interpretable and generalizable medi- cal image classification. InInternational Conference on Med- ical Image Computing and Computer-Assisted Intervention, pages 291–300. Springer, 2025. 1, 3
2025
-
[16]
Edith Natalia Villegas Garcia and Alessio Ansuini. Inter- preting and steering protein language models through sparse autoencoders.arXiv:2502.09135, 2025. 1
-
[17]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 5, 6
2016
-
[18]
Burgess, Xavier Glorot, Matthew M
Irina Higgins, Loïc Matthey, Arka Pal, Christopher P. Burgess, Xavier Glorot, Matthew M. Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. InInternational Conference on Learning Representations, 2016. 1, 3, 6
2016
-
[19]
and Lubana, Ekdeep Singh and Fel, Thomas and Ba, Demba , year = 2025, month = mar, number =
Sai Sumedh R Hindupur, Ekdeep Singh Lubana, Thomas Fel, and Demba Ba. Projecting assumptions: The du- ality between sparse autoencoders and concept geometry. arXiv:2503.01822, 2025. 3
-
[20]
Clifford R Jack Jr et al. The alzheimer’s disease neuroimag- ing initiative (adni): Mri methods.Journal of Magnetic Res- onance Imaging: An Official Journal of the International Society for Magnetic Resonance in Medicine, 27(4):685–691,
-
[21]
Fsl.Neuroimage, 62(2):782–790, 2012
Mark Jenkinson, Christian F Beckmann, Timothy EJ Behrens, Mark W Woolrich, and Stephen M Smith. Fsl.Neuroimage, 62(2):782–790, 2012. 6
2012
-
[22]
Principal component analysis and exploratory factor analysis.Statistical methods in medical research, 1(1):69–95, 1992
Ian T Joliffe and BJT Morgan. Principal component analysis and exploratory factor analysis.Statistical methods in medical research, 1(1):69–95, 1992. 6
1992
-
[23]
Dis- close the neurodegeneration dynamics: Individualized ode discovery for alzheimer’s disease precision medicine
Wooseok Jung, Joonhyuk Park, and Won Hwa Kim. Dis- close the neurodegeneration dynamics: Individualized ode discovery for alzheimer’s disease precision medicine. InIn- ternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 177–186. Springer,
-
[24]
Building a general simclr self-supervised foundation model across neurological diseases to advance 3d brain mri diagnoses
Emily Kaczmarek, Justin Szeto, Brennan Nichyporuk, and Tal Arbel. Building a general simclr self-supervised foundation model across neurological diseases to advance 3d brain mri diagnoses. InIEEE ICCV, pages 1310–1319, 2025. 1, 3
2025
-
[25]
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav)
Been Kim et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). In ICML, pages 2668–2677. PMLR, 2018. 1, 2
2018
-
[26]
Learning biologically relevant features in a pathology foundation model using sparse autoencoders
Nhat Minh Le et al. Learning biologically relevant features in a pathology foundation model using sparse autoencoders. arXiv:2407.10785, 2024. 1, 3, 4
-
[27]
Hyesu Lim, Jinho Choi, Jaegul Choo, and Steffen Schneider. Sparse autoencoders reveal selective remapping of visual concepts during adaptation.arXiv preprint arXiv:2412.05276,
-
[28]
Comparative analysis of generalization and harmonization methods for 3d brain fmri images: A case study on openbhb dataset
Soroosh Safari Loaliyan and Greg Ver Steeg. Comparative analysis of generalization and harmonization methods for 3d brain fmri images: A case study on openbhb dataset. In2024 IEEE CVPR workshop, pages 4915–4923. IEEE, 2024. 3
2024
-
[29]
A unified approach to in- terpreting model predictions.Advances in neural information processing systems, 30, 2017
Scott M Lundberg and Su-In Lee. A unified approach to in- terpreting model predictions.Advances in neural information processing systems, 30, 2017. 2
2017
-
[30]
Alireza Makhzani and Brendan Frey. K-sparse autoencoders. arXiv:1312.5663, 2013. 3, 4, 6
work page Pith review arXiv 2013
-
[31]
Probing the representational power of sparse autoencoders in vision models
Matthew Lyle Olson, Musashi Hinck, Neale Ratzlaff, Chang- bai Li, Phillip Howard, Vasudev Lal, and Shao-Yen Tseng. Probing the representational power of sparse autoencoders in vision models. InProceedings of the IEEE ICCV, pages 6167–6177, 2025. 1, 3
2025
-
[32]
arXiv preprint arXiv:2504.02821 , year=
Mateusz Pach, Shyamgopal Karthik, Quentin Bouniot, Serge Belongie, and Zeynep Akata. Sparse autoencoders learn monosemantic features in vision-language models. arXiv:2504.02821, 2025. 1, 3
-
[33]
Structural progression of alzheimer’s disease over decades: the mri staging scheme.Brain communications, 4 (3):fcac109, 2022
Vincent Planche, José V Manjon, Boris Mansencal, Enrique Lanuza, Thomas Tourdias, Gwenaëlle Catheline, and Pierrick Coupé. Structural progression of alzheimer’s disease over decades: the mri staging scheme.Brain communications, 4 (3):fcac109, 2022. 7
2022
-
[34]
Identification of causal effects of neuroanatomy on cognitive decline requires modeling un- observed confounders.Alzheimer’s & Dementia, 19(5):1994– 2005, 2023
Sebastian Pölsterl, Christian Wachinger, Alzheimer’s Dis- ease Neuroimaging Initiative, and Japanese Alzheimer’s Dis- ease Neuroimaging Initiative. Identification of causal effects of neuroanatomy on cognitive decline requires modeling un- observed confounders.Alzheimer’s & Dementia, 19(5):1994– 2005, 2023. 1, 3
1994
-
[35]
Tang, T., Luo, W., Huang, H., Zhang, D., Wang, X., Zhao, W
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Son- nerat, Arthur Conmy, Vikrant Varma, János Kramár, and Neel Nanda. Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders.arXiv:2407.14435, 2024. 3
-
[36]
Multi- modal vision pre-training for medical image analysis
Shaohao Rui, Lingzhi Chen, Zhenyu Tang, Lilong Wang, Mianxin Liu, Shaoting Zhang, and Xiaosong Wang. Multi- modal vision pre-training for medical image analysis. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 5164–5174, 2025. 3
2025
-
[37]
Grad- cam: Visual explanations from deep networks via gradient- based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad- cam: Visual explanations from deep networks via gradient- based localization. InIEEE ICCV, pages 618–626, 2017. 1, 2
2017
-
[38]
Interplm: discovering inter- pretable features in protein language models via sparse au- toencoders.Nature methods, 22(10):2107–2117, 2025
Elana Simon and James Zou. Interplm: discovering inter- pretable features in protein language models via sparse au- toencoders.Nature methods, 22(10):2107–2117, 2025. 1, 3, 4
2025
-
[39]
Samuel Stevens, Wei-Lun Chao, Tanya Berger-Wolf, and Yu Su. Interpretable and testable vision features via sparse autoencoders.arXiv preprint arXiv:2502.06755, 2025. 3
-
[40]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. InICML, pages 3319–3328. PMLR, 2017. 1, 2
2017
-
[41]
A generalizable foundation model for analysis of human brain mri.Nature Neuroscience, pages 1–12, 2026
Divyanshu Tak et al. A generalizable foundation model for analysis of human brain mri.Nature Neuroscience, pages 1–12, 2026. 1, 2, 3, 5, 6
2026
-
[42]
Anthropic, 2024
Adly Templeton.Scaling monosemanticity: Extracting inter- pretable features from claude 3 sonnet. Anthropic, 2024. 1, 3
2024
-
[43]
Biomarker modeling of alzheimer’s disease using pet-based braak staging.Nature aging, 2(6):526–535, 2022
Joseph Therriault, Tharick A Pascoal, Firoza Z Lussier, Cé- cile Tissot, Mira Chamoun, Gleb Bezgin, Stijn Servaes, An- drea L Benedet, Nicholas J Ashton, Thomas K Karikari, et al. Biomarker modeling of alzheimer’s disease using pet-based braak staging.Nature aging, 2(6):526–535, 2022. 2, 7
2022
-
[44]
Revisiting mae pre-training for 3d medical image segmentation
Tassilo Wald, Constantin Ulrich, Stanislav Lukyanenko, An- drei Goncharov, Alberto Paderno, Maximilian Miller, Leander Maerkisch, Paul Jaeger, and Klaus Maier-Hein. Revisiting mae pre-training for 3d medical image segmentation. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 5186–5196, 2025. 3
2025
-
[45]
Disentangled representation learning.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 46(12): 9677–9696, 2024
Xin Wang, Hong Chen, Si’ao Tang, Zihao Wu, and Wenwu Zhu. Disentangled representation learning.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 46(12): 9677–9696, 2024. 3
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.