Recognition: unknown
NeuroState-Bench: A Human-Calibrated Benchmark for Commitment Integrity in LLM Agent Profiles
Pith reviewed 2026-05-10 14:49 UTC · model grok-4.3
The pith
A benchmark for LLM agent profiles shows that task success and commitment integrity are distinct, with most profiles ranking differently under each measure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
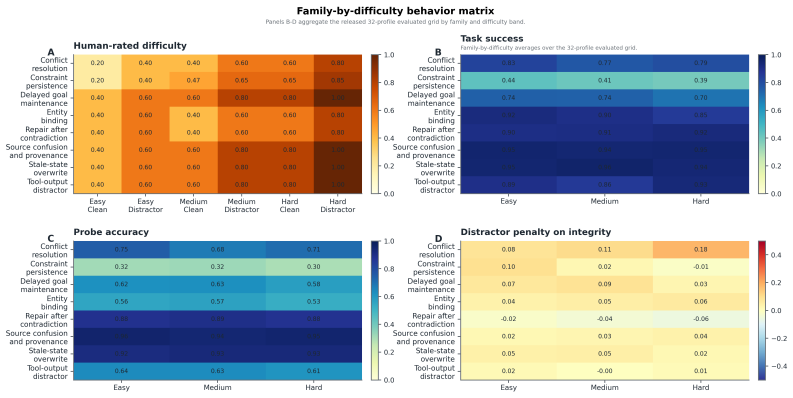
NeuroState-Bench supplies 144 tasks and 306 benchmark-defined side-query probes organized into eight cognitively motivated failure families, with paired clean and distractor versions across three difficulty levels. When applied to a fixed set of 32 agent profiles, the benchmark reveals that task success and commitment integrity diverge sharply: the profile with highest task success is not the one with highest integrity, 31 of the 32 profiles change rank under the switch, and integrity orderings remain more stable when distractors appear. Human calibration on a merged sample of tasks and annotations confirms high agreement, supporting the use of the probes as a direct diagnostic for terminal-
What carries the argument
NeuroState-Bench, a human-calibrated benchmark that measures commitment integrity through benchmark-defined side-query probes on LLM agent profiles.
If this is right
- Profiles that lead on task success can still produce commitment violations detectable by targeted probes, so success alone does not guarantee coherent multi-turn behavior.
- Integrity rankings resist perturbation from distractors more than success rankings do, indicating that the integrity measure isolates a more consistent property of the agent profile.
- The benchmark distinguishes profiles that reach terminal task failure after probes from those that do not, supplying a post-probe diagnostic axis beyond raw outcome.
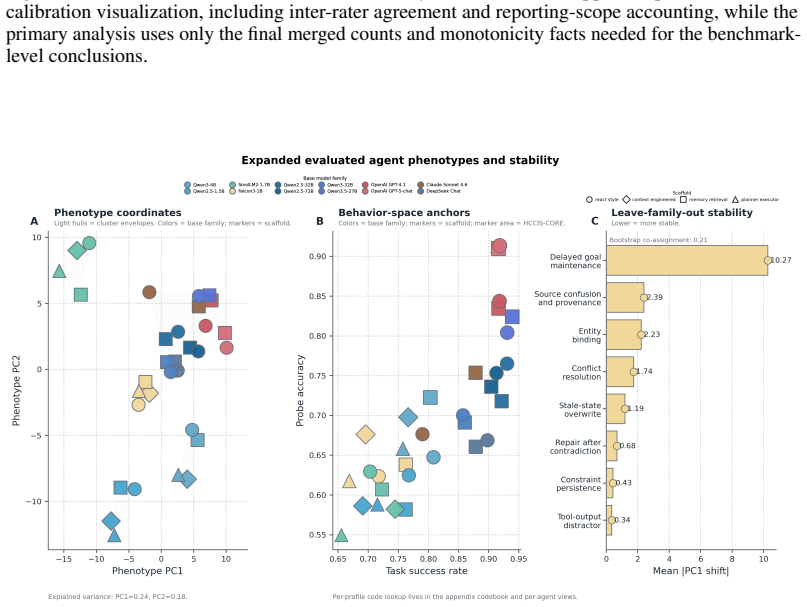
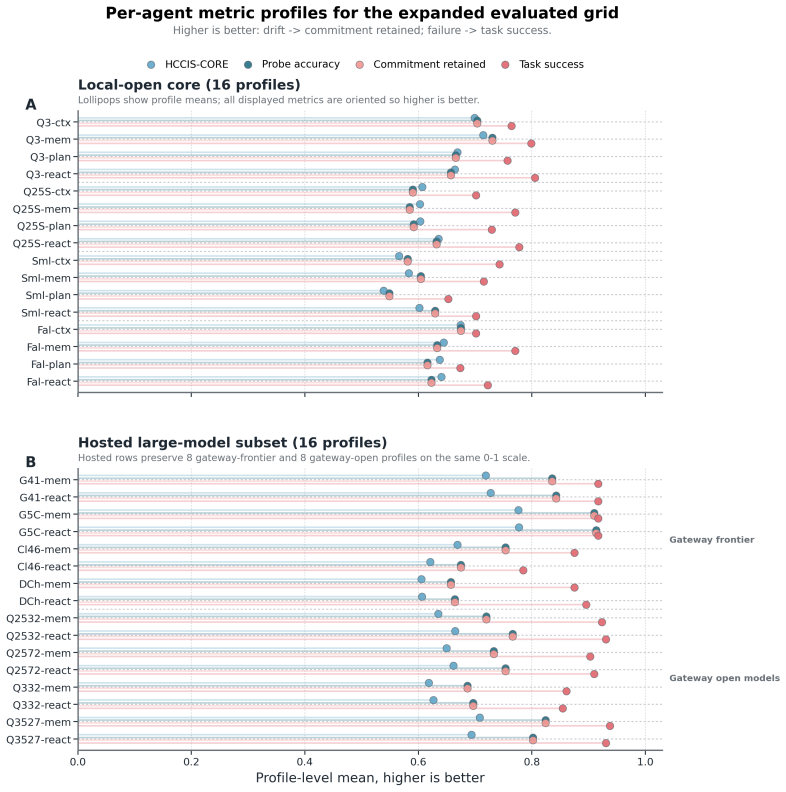
- The same pipeline applies equally to local and hosted large-model profiles, allowing direct comparison across a wider model grid than earlier local-only evaluations.
- Human-adjudicated annotations align closely with the probe-based scores, confirming that the operationalization tracks judgments of commitment preservation.
Where Pith is reading between the lines
- Leaderboards that optimize only for task success may systematically select agents unsuitable for applications requiring sustained commitment across turns.
- Training or fine-tuning loops could incorporate the side-query probes as an auxiliary objective to improve integrity without sacrificing success.
- The divergence raises the question of whether similar gaps appear in other agent evaluation settings that rely on outcome metrics alone, such as planning or tool-use benchmarks.
Load-bearing premise
The side-query probes fully and accurately capture the intended construct of commitment integrity without missing important failure modes or introducing artifacts from their design.
What would settle it
A new set of side-query probes, designed independently but targeting the same commitment failures, that produces substantially different rank orderings or loses the observed stability under distractors would falsify the claim that the current probes provide a reliable integrity axis.
Figures








read the original abstract
Outcome-only evaluation under-specifies whether an evaluated agent profile preserves the commitments required to solve a multi-turn task coherently. NeuroState-Bench is a human-calibrated benchmark that operationalizes commitment integrity through benchmark-defined side-query probes rather than inferred hidden activations. The released inventory contains 144 deterministic tasks and 306 benchmark-defined side-query probes spanning eight cognitively motivated failure families, paired clean and distractor variants, and three difficulty bands. The main 32-profile evaluation contains a fixed 16-profile local subset and a matched 16-profile hosted large-model subset evaluated through the same benchmark pipeline. Human calibration uses the final merged reporting scope: 104 sampled task units, 216 raw annotations, and 108 adjudicated task rows, with weighted kappa = 0.977 and ICC(2,1) = 0.977. Empirically, task success and commitment integrity diverge across this expanded grid: the success leader is not the integrity leader, 31 of 32 profiles change rank when integrity replaces task success, and integrity rankings are more stable under distractor perturbation. The primary confidence-free score HCCIS-CORE reaches 0.8469 AUC and 0.6992 PR-AUC for post-probe diagnostic discrimination of terminal task failure; the legacy full heuristic variant HCCIS-FULL reaches 0.7997 AUC and 0.6410 PR-AUC. Probe accuracy and state drift achieve slightly higher ROC-AUC, 0.8587, and better Brier/ECE, while HCCIS-CORE has substantially higher point-estimate PR-AUC and remains more closely tied to the benchmark's intended construct. The exploratory neural-augmented variant HCCIS+N is weaker overall, and a randomized subspace control approaches chance. NeuroState-Bench therefore contributes a calibrated evaluation axis for exposing commitment failures over a broader model grid than the original local-only subset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NeuroState-Bench, a benchmark operationalizing commitment integrity in LLM agent profiles via 144 deterministic tasks and 306 benchmark-defined side-query probes across eight cognitively motivated failure families, with clean/distractor variants and three difficulty bands. It evaluates a fixed 32-profile grid (16 local + 16 hosted large models) using the same pipeline, reports human calibration on 104 sampled task units yielding 108 adjudicated rows with weighted kappa = 0.977 and ICC(2,1) = 0.977, and finds that task success and commitment integrity diverge: the success leader is not the integrity leader, 31 of 32 profiles change rank under the switch, and integrity rankings are more stable under distractor perturbation. HCCIS-CORE achieves 0.8469 AUC for post-probe diagnostic discrimination of terminal task failure.
Significance. If the side-query probes validly capture the intended construct, the benchmark supplies a reproducible, human-calibrated axis that exposes divergences between task completion and commitment preservation, with direct implications for multi-turn agent reliability. The fixed pipeline, absence of post-hoc exclusions, and release of the full inventory are strengths that support empirical claims. High inter-rater agreement on adjudicated rows bolsters annotation reliability, and the reported AUC/PR-AUC values plus stability findings provide concrete, falsifiable outcomes.
major comments (1)
- [Human Calibration] Human Calibration section: The reported weighted kappa = 0.977 and ICC(2,1) = 0.977 on 108 adjudicated rows establish high rater consistency on the sampled task units, but this does not constitute independent validation that the 306 benchmark-defined side-query probes accurately measure commitment integrity without introducing artifacts (such as eliciting explicit restatements absent in unprobed multi-turn behavior) or omitting key failure modes. Because the headline divergence result (31 of 32 rank changes) and stability claims are computed solely from HCCIS-CORE scores derived from these probes, the absence of evidence addressing probe-induced artifacts or construct coverage is load-bearing for interpreting the empirical findings as genuine rather than instrument-specific.
minor comments (2)
- [Abstract] Abstract: The distinction between HCCIS-CORE (confidence-free) and HCCIS-FULL (legacy full heuristic) is introduced without a brief inline definition or pointer to the section deriving the scores; adding one sentence would improve readability for readers encountering the acronyms for the first time.
- [Results] Results reporting: The AUC and PR-AUC values for HCCIS-CORE, HCCIS-FULL, and the neural-augmented variant are given as point estimates without accompanying confidence intervals or details on the number of bootstrap resamples used; including these would strengthen the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for highlighting the benchmark's strengths in reproducibility, fixed pipeline, and annotation reliability. We address the single major comment below.
read point-by-point responses
-
Referee: Human Calibration section: The reported weighted kappa = 0.977 and ICC(2,1) = 0.977 on 108 adjudicated rows establish high rater consistency on the sampled task units, but this does not constitute independent validation that the 306 benchmark-defined side-query probes accurately measure commitment integrity without introducing artifacts (such as eliciting explicit restatements absent in unprobed multi-turn behavior) or omitting key failure modes. Because the headline divergence result (31 of 32 rank changes) and stability claims are computed solely from HCCIS-CORE scores derived from these probes, the absence of evidence addressing probe-induced artifacts or construct coverage is load-bearing for interpreting the empirical findings as genuine rather than instrument-specific.
Authors: We agree that the reported kappa and ICC values establish high inter-rater reliability for adjudicating the 108 sampled task units (which incorporate the side-query probes) but do not constitute independent construct validation of the probes themselves. The calibration confirms consistent application of the benchmark-defined scoring criteria across raters, with the 216 raw annotations merged into adjudicated rows. The probes are explicitly operationalized rather than inferred from hidden states, and the eight failure families are drawn from cognitive literature on commitment and state maintenance. However, we acknowledge that this does not empirically rule out probe-induced artifacts (such as eliciting restatements that might not arise in unprobed multi-turn settings) or demonstrate exhaustive coverage of all possible failure modes. The divergence results (including 31 of 32 rank changes) and stability findings are therefore presented as observations under this specific measurement approach. In revision we will expand the Human Calibration and Limitations sections to explicitly discuss these boundaries, note the potential for probe artifacts, and outline directions for future external validation studies. This will better frame the interpretive scope of the empirical claims while leaving the reported data and pipeline unchanged. revision: partial
Circularity Check
No significant circularity; results are direct empirical outputs from a fixed benchmark pipeline.
full rationale
The paper defines commitment integrity via a fixed set of 306 benchmark-defined side-query probes across failure families, runs a deterministic evaluation pipeline on 32 profiles (producing task success and HCCIS-CORE scores), and reports rank changes and stability metrics as direct computations from those outputs. Human calibration (kappa 0.977 on 108 rows) is an external consistency check on sampled annotations, not a fitted parameter or self-referential step. No equations, derivations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text; the chain is measurement followed by descriptive statistics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Glenn W. Brier. Verification of forecasts expressed in terms of probability.Monthly Weather Review, 78(1):1–3, 1950. 17 Table 10: Strict-schema side-query rerun over the completed 193-row primary matcher-audit subset. The subset is stratified and enriched for automatic matcher-audit decisions, so the match rate estimates schema robustness rather than full...
-
[2]
CheeseBench: Evaluating Large Language Models on Rodent Behavioral Neuroscience Paradigms
Zacharie Bugaud. Cheesebench: Evaluating large language models on rodent behav- ioral neuroscience paradigms, 2026. URL https://arxiv.org/abs/2604.10825. arXiv:2604.10825
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Weighted kappa: Nominal scale agreement with provision for scaled disagreement or partial credit.Psychological Bulletin, 70(4):213–220, 1968
Jacob Cohen. Weighted kappa: Nominal scale agreement with provision for scaled disagreement or partial credit.Psychological Bulletin, 70(4):213–220, 1968
1968
-
[4]
Cronbach and Paul E
Lee J. Cronbach and Paul E. Meehl. Construct validity in psychological tests.Psychological Bulletin, 52(4):281–302, 1955
1955
-
[5]
Crosse, Giovanni M
Michael J. Crosse, Giovanni M. Di Liberto, Adam Bednar, and Edmund C. Lalor. The multivari- ate temporal response function (mTRF) toolbox: A matlab toolbox for relating neural signals to continuous stimuli.Frontiers in Human Neuroscience, 10:604, 2016
2016
-
[6]
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. Workarena: How capable are web agents at solving common knowledge work tasks?, 2024. URLhttps://arxiv.org/abs/2403.07718. arXiv:2403.07718
-
[7]
An introduction to roc analysis.Pattern Recognition Letters, 27(8):861–874, 2006
Tom Fawcett. An introduction to roc analysis.Pattern Recognition Letters, 27(8):861–874, 2006
2006
-
[8]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InProceedings of the 34th International Conference on Machine Learning, pages 1321–1330, 2017
2017
-
[9]
Faiz Ghifari Haznitrama, Faeyza Rishad Ardi, and Alice Oh. A neuropsychologically grounded evaluation of llm cognitive abilities, 2026. URL https://arxiv.org/abs/2603. 02540. arXiv:2603.02540. 18 Table 12: Completed balanced follow-up matcher audit kept separate from the primary 193-row overall audit. The completed audit pairs the 128 hard-case automatic ...
-
[10]
Hoerl and Robert W
Arthur E. Hoerl and Robert W. Kennard. Ridge regression: Biased estimation for nonorthogonal problems.Technometrics, 12(1):55–67, 1970
1970
-
[11]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. Swe-bench: Can language models resolve real-world github issues?,
-
[12]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
URLhttps://arxiv.org/abs/2310.06770. arXiv:2310.06770
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Jolliffe.Principal Component Analysis
Ian T. Jolliffe.Principal Component Analysis. Springer, 2 edition, 2002
2002
-
[14]
Maurice G. Kendall. A new measure of rank correlation.Biometrika, 30(1/2):81–93, 1938
1938
-
[15]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Marta Garnelo, Evan Hubinger, Shan Carter, Scott Wang, Shaun Kravec, David Maxwell, Dylan Hadfield-Menell, and Jacob Steinhardt. Measuring faithfulness in chain-of-thought reasoning, 2023. URL https://arxiv.org/abs/2307.13702. arXiv:2307.13702
work page Pith review arXiv 2023
-
[16]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step, 2023. URL https://arxiv.org/abs/2305.20050. arXiv:2305.20050
work page internal anchor Pith review arXiv 2023
-
[17]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating llms as agents, 2023. URL https://arxiv.org/abs/ 2308.03688. arXiv:2...
work page internal anchor Pith review arXiv 2023
-
[18]
Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. Faithful chain-of-thought reasoning, 2023. URL https://arxiv. org/abs/2301.13379. arXiv:2301.13379. 19 Table 14: Compute resources for the expanded 32-profile experiment. The local rows describe the fixed 16-profile local subset; the gatew...
-
[19]
MacQueen
J. MacQueen. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, volume 1, pages 281–297, 1967
1967
-
[20]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: A benchmark for general ai assistants, 2023. URL https://arxiv.org/ abs/2311.12983. arXiv:2311.12983
work page internal anchor Pith review arXiv 2023
-
[21]
Kay, Shinji Nishimoto, and Jack L
Thomas Naselaris, Kendrick N. Kay, Shinji Nishimoto, and Jack L. Gallant. Encoding and decoding in fmri.NeuroImage, 56(2):400–410, 2011
2011
-
[22]
Claude E. Shannon. A mathematical theory of communication.Bell System Technical Journal, 27(3):379–423, 1948
1948
-
[23]
Shrout and Joseph L
Patrick E. Shrout and Joseph L. Fleiss. Intraclass correlations: Uses in assessing rater reliability. Psychological Bulletin, 86(2):420–428, 1979
1979
-
[24]
The proof and measurement of association between two things.The American Journal of Psychology, 15(1):72–101, 1904
Charles Spearman. The proof and measurement of association between two things.The American Journal of Psychology, 15(1):72–101, 1904
1904
-
[25]
arXiv preprint arXiv:2506.21605 , year=
Haoran Tan, Zeyu Zhang, Chen Ma, Xu Chen, Quanyu Dai, and Zhenhua Dong. Membench: Towards more comprehensive evaluation on the memory of llm-based agents, 2025. URL https://arxiv.org/abs/2506.21605. arXiv:2506.21605
-
[26]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory, 2024. URL https://arxiv.org/abs/2410.10813. arXiv:2410.10813. 20 Table 16: Paired two-way cluster bootstrap deltas for the main comparator pairs. Positive deltas favor HCCIS-CORE for AUC and PR-AUC; negative...
work page internal anchor Pith review arXiv 2024
-
[27]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024. URL https: //arxiv.org/abs/2...
work page internal anchor Pith review arXiv 2024
-
[28]
arXiv preprint arXiv:2406.04244 , year=
Cheng Xu, Shuhao Guan, Derek Greene, and M.-Tahar Kechadi. Benchmark data contamina- tion of large language models: A survey, 2024. URL https://arxiv.org/abs/2406. 04244. arXiv:2406.04244
-
[29]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024. URL https://arxiv.org/abs/ 2406.12045. arXiv:2406.12045
work page internal anchor Pith review arXiv 2024
-
[30]
Yujie Zhao, Boqin Yuan, Junbo Huang, Haocheng Yuan, Zhongming Yu, Haozhou Xu, Lanxiang Hu, Abhilash Shankarampeta, Zimeng Huang, Wentao Ni, Yuandong Tian, and Jishen Zhao. Ama-bench: Evaluating long-horizon memory for agentic applications, 2026. URL https: //arxiv.org/abs/2602.22769. arXiv:2602.22769
-
[31]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents, 2023. URL https://arxiv.org/abs/ 2307.13854. arXiv:2307.13854. 21 Table 18: Weight-sensitivity summary for the primary HCCIS-CORE...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.