Recognition: unknown
Spatiotemporal Hidden-State Dynamics as a Signature of Internal Reasoning in Large Language Models
Pith reviewed 2026-05-09 17:17 UTC · model grok-4.3
The pith
Spatiotemporal patterns in hidden states distinguish correct reasoning trajectories in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
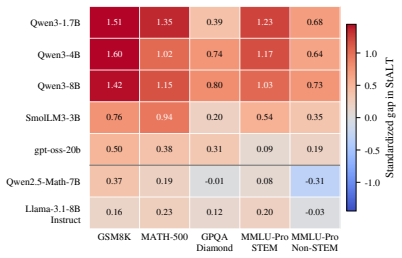
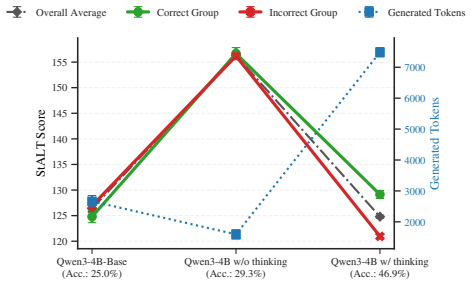
Successful reasoning trajectories exhibit broad temporal dynamics with localized layer-wise concentration in hidden states; this structure is weaker in non-reasoning models and knowledge-heavy domains. The authors formalize the pattern as Spatiotemporal Amplitude of Latent Transition (StALT), a training-free trajectory statistic that reliably separates correct from incorrect outputs in reasoning-intensive regimes and responds systematically to manipulations that alter internal reasoning demand.
What carries the argument
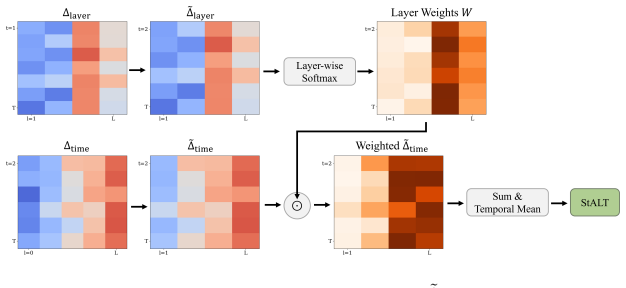
Spatiotemporal Amplitude of Latent Transition (StALT), a statistic that aggregates temporal changes between adjacent tokens weighted by within-token layer saliency to summarize hidden-state dynamics.
If this is right
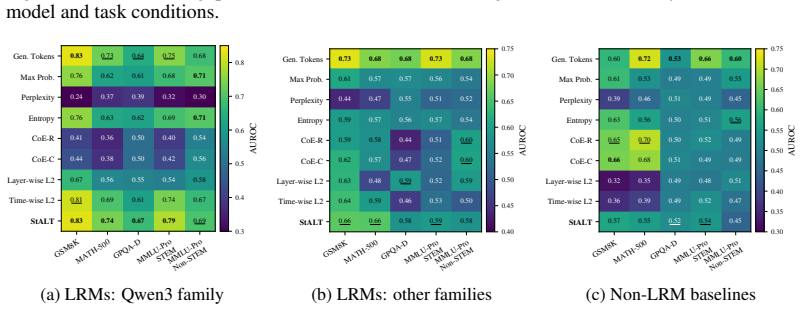
- StALT supplies a competitive label-free correctness signal that works alongside length-based and output-space baselines.
- The statistic changes in the expected direction under interventions that raise or lower the demand for internal reasoning.
- The same spatiotemporal signature is weaker in non-reasoning models and in knowledge-heavy domains.
- The findings supply direct empirical evidence that large reasoning models produce measurable hidden-state dynamics during extended generation.
Where Pith is reading between the lines
- If StALT genuinely indexes reasoning effort, it could be monitored in real time to decide when to stop or continue generation.
- The metric might help compare the internal computation profiles of models trained with different reasoning objectives or reinforcement schedules.
- Similar layer-and-time analyses could be applied to other sequential generation tasks where correctness is hard to verify from output alone.
Load-bearing premise
The measured spatiotemporal amplitude in hidden states tracks genuine internal reasoning computation rather than surface features such as output length or token distribution.
What would settle it
An experiment in which StALT loses its ability to separate correct from incorrect trajectories after matching or regressing out solution length and token-frequency statistics.
Figures








read the original abstract
Large reasoning models (LRMs) generate extended solutions, yet it remains unclear whether these traces reflect substantive internal computation or merely verbosity and overthinking. Although recent hidden-state analyses suggest that internal representations carry correctness-related signals, their coarse aggregations may obscure the token and layer structure underlying reasoning computation. We investigate hidden-state transitions across decoding steps and layers, and identify a distinct spatiotemporal pattern in LRMs: successful trajectories exhibit broad temporal dynamics with localized layer-wise concentration, while this structure is weaker in non-reasoning models and knowledge-heavy domains. We formalize this characteristic as Spatiotemporal Amplitude of Latent Transition (StALT), a training-free trajectory statistic that summarizes temporal changes between adjacent tokens weighted by within-token layer saliency. Across diverse models and benchmarks, StALT reliably separates correct from incorrect trajectories in reasoning-intensive regimes, providing a competitive label-free correctness signal alongside strong output-space and length-based baselines. Intervention analyses further show that this spatiotemporal amplitude responds systematically to manipulations that increase or reduce the demand for internal reasoning, supporting its association with latent reasoning dynamics in LRMs. These findings provide empirical evidence that LRMs exhibit measurable hidden-state dynamics and offer a practical probe for understanding internal computation beyond output-based evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that large reasoning models exhibit distinct spatiotemporal patterns in hidden-state transitions during decoding—successful trajectories show broad temporal dynamics with localized layer-wise concentration—while non-reasoning models and knowledge-heavy domains do not. It formalizes this as the training-free Spatiotemporal Amplitude of Latent Transition (StALT) statistic, which summarizes temporal changes between adjacent tokens weighted by within-token layer saliency. Across models and benchmarks, StALT separates correct from incorrect trajectories in reasoning-intensive regimes, remains competitive with length-based and output-space baselines, and responds systematically to interventions that increase or reduce reasoning demand.
Significance. If the central empirical claims hold after controls, the work supplies a practical, label-free probe for latent reasoning dynamics that goes beyond output evaluation. Credit is due for the training-free construction of StALT, the use of intervention analyses to test association with reasoning demand, and the cross-model/cross-benchmark consistency reported in the abstract.
major comments (2)
- [Abstract] Abstract: the claim of reliable separation across models and benchmarks rests on unexamined empirical robustness; no details are supplied on statistical controls, multiple-testing correction, or exact data-exclusion rules, which are load-bearing for the central correctness-signal claim.
- [Intervention analyses] The weakest assumption—that observed spatiotemporal amplitude directly indexes substantive internal reasoning rather than correlated surface features such as output length or token distribution—requires explicit ablations or controls; without them the intervention results cannot yet distinguish the two interpretations.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate the revisions that will be incorporated to strengthen the empirical claims and controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of reliable separation across models and benchmarks rests on unexamined empirical robustness; no details are supplied on statistical controls, multiple-testing correction, or exact data-exclusion rules, which are load-bearing for the central correctness-signal claim.
Authors: We agree that the abstract would be strengthened by explicit reference to the statistical procedures supporting the separation claims. In the revised manuscript we will update the abstract to note that separation is assessed via paired t-tests with Bonferroni correction for multiple comparisons across the 12 model-benchmark combinations, with exact data-exclusion rules (trajectories shorter than 8 tokens or containing NaN hidden states) stated in Section 3.2. These procedures are already detailed in the methods and supplementary results; the revision will simply surface them in the abstract for clarity. revision: yes
-
Referee: [Intervention analyses] The weakest assumption—that observed spatiotemporal amplitude directly indexes substantive internal reasoning rather than correlated surface features such as output length or token distribution—requires explicit ablations or controls; without them the intervention results cannot yet distinguish the two interpretations.
Authors: We acknowledge that stronger isolation from surface confounds is desirable. The existing intervention suite already includes length-matched prompt variants and shows that StALT changes track reasoning demand (CoT vs. direct answer) even when output length is statistically controlled via regression residuals. Nevertheless, we agree that additional explicit ablations are warranted. In the revision we will add (i) a length-matched subset analysis and (ii) a token-distribution control that permutes within-layer activations while preserving marginal token statistics. These will be reported in an expanded Section 4.3 and will allow readers to directly compare the reasoning-specific versus surface-feature accounts. revision: yes
Circularity Check
No significant circularity; StALT is an independent statistic
full rationale
The paper defines StALT explicitly as a training-free summary of temporal changes between adjacent tokens weighted by layer saliency, constructed solely from hidden-state observations. This definition precedes and does not reference correctness labels, output length, or any fitted parameters. The subsequent evaluation of StALT's separation power on correct versus incorrect trajectories is an external test rather than a definitional input, so the statistic does not reduce to its evaluation targets by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked to justify the core formulation. The derivation chain remains self-contained and falsifiable against independent benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, et al. Chain-of-thought prompting elicits reasoning in large language models, 2023. URLhttps://arxiv.org/abs/2201.11903
work page internal anchor Pith review arXiv 2023
-
[2]
Scaling llm test-time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[3]
s1: Simple test-time scaling
Niklas Muennighoff, Zitong Yang, Weijia Shi, et al. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286– 20332, 2025
2025
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Daya Guo, Dejian Yang, Haowei Zhang, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, September 2025. ISSN 1476-4687. doi: 10.1038/s41586-025-09422-z. URL http://dx.doi.org/10.1038/ s41586-025-09422-z
-
[6]
Trustllm: Trustworthiness in large language models.arXiv preprint arXiv:2401.05561,
Yue Huang, Lichao Sun, Haoran Wang, et al. Trustllm: Trustworthiness in large language models, 2024. URLhttps://arxiv.org/abs/2401.05561
-
[7]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, et al. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[8]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Yue Zhang, Yafu Li, Leyang Cui, et al. Siren’s song in the ai ocean: A survey on hallucination in large language models, 2025. URLhttps://arxiv.org/abs/2309.01219
work page internal anchor Pith review arXiv 2025
-
[9]
Teaching models to express their uncertainty in words
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words, 2022. URLhttps://arxiv.org/abs/2205.14334
-
[10]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empiri...
-
[11]
The unreasonable effectiveness of entropy minimization in LLM reasoning
Shivam Agarwal, Zimin Zhang, Lifan Yuan, Jiawei Han, and Hao Peng. The unreasonable effectiveness of entropy minimization in LLM reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum? id=UfFTBEsLgI
2025
-
[12]
Learning to reason without external rewards
Xuandong Zhao, Zhewei Kang, Aosong Feng, Sergey Levine, and Dawn Song. Learning to reason without external rewards. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=OU9nFEYR2M
2026
-
[13]
Pengyi Li, Matvey Skripkin, Alexander Zubrey, Andrey Kuznetsov, and Ivan Oseledets. Confidence is all you need: Few-shot rl fine-tuning of language models, 2025. URL https://arxiv.org/abs/2506.06395
-
[14]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms, 2024. URL https://arxiv.org/abs/2306.13063
work page internal anchor Pith review arXiv 2024
-
[15]
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Reasoning models know when they’re right: Probing hidden states for self-verification, 2025. URL https://arxiv.org/abs/2504.05419
-
[16]
Roy Eisenstadt, Itamar Zimerman, and Lior Wolf. Overclocking llm reasoning: Monitoring and controlling thinking path lengths in llms, 2025. URLhttps://arxiv.org/abs/2506.07240. 10
-
[17]
arXiv preprint arXiv:2502.07266 (2025)
Yuyang Wu, Yifei Wang, Ziyu Ye, Tianqi Du, Stefanie Jegelka, and Yisen Wang. When more is less: Understanding chain-of-thought length in llms, 2025. URL https://arxiv.org/abs/ 2502.07266
-
[18]
Think deep, not just long: Measuring llm reasoning effort via deep-thinking tokens, 2026
Wei-Lin Chen, Liqian Peng, Tian Tan, Chao Zhao, Blake JianHang Chen, Ziqian Lin, Alec Go, and Yu Meng. Think deep, not just long: Measuring llm reasoning effort via deep-thinking tokens, 2026. URLhttps://arxiv.org/abs/2602.13517
-
[19]
Wong, and Rui Wang
Yiming Wang, Pei Zhang, Baosong Yang, Derek F. Wong, and Rui Wang. Latent space chain-of-embedding enables output-free LLM self-evaluation. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=jxo70B9fQo
2025
-
[20]
Clue: Non-parametric verification from experience via hidden-state clustering, 2025
Zhenwen Liang, Ruosen Li, Yujun Zhou, Linfeng Song, Dian Yu, Xinya Du, Haitao Mi, and Dong Yu. Clue: Non-parametric verification from experience via hidden-state clustering, 2025. URLhttps://arxiv.org/abs/2510.01591
-
[21]
Amirhosein Ghasemabadi and Di Niu. Can llms predict their own failures? self-awareness via internal circuits, 2026. URLhttps://arxiv.org/abs/2512.20578
-
[22]
Vilas, Safoora Yousefi, Besmira Nushi, Eric Horvitz, and Vidhisha Balachandran
Martina G. Vilas, Safoora Yousefi, Besmira Nushi, Eric Horvitz, and Vidhisha Balachandran. Tracing the traces: Latent temporal signals for efficient and accurate reasoning, 2025. URL https://arxiv.org/abs/2510.10494
-
[23]
Decoupling knowledge and reasoning in llms: An exploration using cognitive dual-system theory
Mutian Yang, Jiandong Gao, and Ji Wu. Decoupling knowledge and reasoning in llms: An exploration using cognitive dual-system theory. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 34268–34276, 2026
2026
-
[24]
Knowledge or reasoning? a close look at how llms think across domains, 2025
Juncheng Wu, Sheng Liu, Haoqin Tu, Hang Yu, Xiaoke Huang, James Zou, Cihang Xie, and Yuyin Zhou. Knowledge or reasoning? a close look at how llms think across domains, 2025. URLhttps://arxiv.org/abs/2506.02126
-
[25]
An Yang, Anfeng Li, Baosong Yang, et al. Qwen3 technical report, 2025. URL https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The llama 3 herd of models, 2024. URLhttps://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Chong Wu, Jiawang Cao, Renjie Xu, Zhuoheng Ran, Maolin Che, Wenbo Zhu, and Hong Yan
Yubo Wang, Xueguang Ma, Ge Zhang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 95266–95290. Curran Associates, Inc., 2024. doi: 10.52202/079017-3018...
- [28]
-
[29]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, et al. Training verifiers to solve math word problems, 2021. URLhttps://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. In J. Vanschoren and S. Yeung, editors,Proceedings of the Neural Infor- mation Processing Systems Track on Datasets and Benchmarks, volume 1, 2021. URL https://datasets-benchmark...
2021
-
[31]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google- proof q&a benchmark. InFirst Conference on Language Modeling, 2024. URL https: //openreview.net/forum?id=Ti67584b98. 11
2024
-
[32]
SmolLM3: smol, multilingual, long- context reasoner.https://huggingface.co/blog/smollm3, 2025
Elie Bakouch, Loubna Ben Allal, Anton Lozhkov, et al. SmolLM3: smol, multilingual, long- context reasoner.https://huggingface.co/blog/smollm3, 2025
2025
-
[33]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, Sandhini Agarwal, Lama Ahmad, et al. gpt-oss-120b & gpt-oss-20b model card, 2025. URLhttps://arxiv.org/abs/2508.10925
work page internal anchor Pith review arXiv 2025
-
[34]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang, Beichen Zhang, Binyuan Hui, et al. Qwen2.5-math technical report: Toward mathemat- ical expert model via self-improvement, 2024. URL https://arxiv.org/abs/2409.12122
work page internal anchor Pith review arXiv 2024
-
[35]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. Curran Associates Inc. ISBN 9781713871088
2022
-
[36]
Jianhao Huang, Zixuan Wang, and Jason D. Lee. Transformers learn to implement multi-step gradient descent with chain of thought. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=r3DF5sOo5B
2025
-
[37]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=VD-AYtP0dve
2023
-
[38]
The internal state of an LLM knows when it ' s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Com- putational Linguistics: EMNLP 2023, pages 967–976, Singapore, December 2023. Asso- ciation for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.68. URL https://aclanthol...
-
[39]
Kevin Liu, Stephen Casper, Dylan Hadfield-Menell, and Jacob Andreas. Cognitive dissonance: Why do language model outputs disagree with internal representations of truthfulness? In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4791–4797, Singapore, December
2023
-
[40]
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.291. URLhttps://aclanthology.org/2023.emnlp-main.291/
-
[41]
Zhixiang Liang, Beichen Huang, Zheng Wang, and Minjia Zhang. Hidden states as early signals: Step-level trace evaluation and pruning for efficient test-time scaling, 2026. URL https://arxiv.org/abs/2601.09093
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Cot-kinetics: A theoretical modeling assessing lrm reasoning process
Jinhe Bi, Danqi Yan, Yifan Wang, et al. Cot-kinetics: A theoretical modeling assessing lrm reasoning process, 2025. URLhttps://arxiv.org/abs/2505.13408
-
[43]
Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[44]
Efficient memory management for large lan- guage model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, et al. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[45]
Transformers: State-of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, et al. Transformers: State-of-the-art natural language processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online, October 2020. Associ- ation for Computational Linguistics. URL https://www.aclweb.org/anthology/2020. emnlp-demos.6
2020
-
[46]
Leandro von Werra, Younes Belkada, Lewis Tunstall, et al. TRL: Transformers Reinforcement Learning, 2020. URLhttps://github.com/huggingface/trl. 12 Method / ModelQwen3-1.7B Qwen3-4B Qwen3-8B SmolLM3-3B gpt-oss-20bQwen2.5-Math-7B Llama-3.1-8B-Instruct MATH-500 (AUROC↑/ FPR95↓/ AUPR↑) Gen. Tokens0.78/0.60/0.910.71/0.64/0.920.70/0.65/0.920.74/0.63/0.910.63/0...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.