Recognition: 4 theorem links
· Lean TheoremQuality-Aware Exploration Budget Allocation for Cooperative Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-08 19:32 UTC · model grok-4.3
The pith
A quality-aware exploration method using return-conditioned sigmoid scheduling and per-agent RSQ metrics achieves top-tier returns on seven cooperative MARL benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
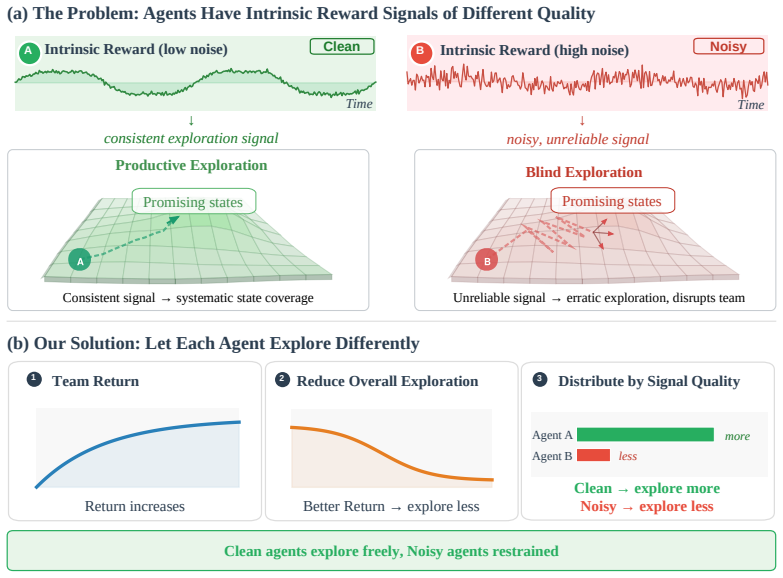
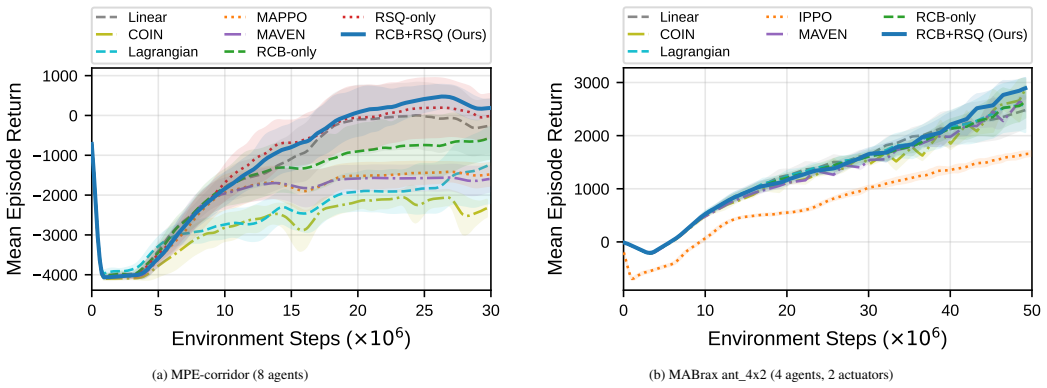
On seven cooperative benchmarks (MPE, SMAX, MABrax), our method achieves top-tier returns across all environments.
Load-bearing premise
That agents receiving noisy intrinsic rewards should explore less aggressively and that this allocation, determined from signal-to-noise statistics, will not prevent discovery of rare coordination configurations in the joint strategy space.
Figures





read the original abstract
Cooperative multi-agent reinforcement learning (MARL) requires agents to discover joint strategies in a combinatorially large state-action space, yet effective coordination configurations are exceedingly rare. Intrinsic motivation, which augments task rewards with novelty bonuses, is a popular approach for driving exploration, but its effectiveness hinges on the exploration intensity $\beta$, where too large a value overwhelms the task signal and causes coordination collapse, while too small a value prevents discovery of rare strategies. We address two complementary challenges: adapting $\beta$ globally over training, and allocating the exploration budget across agents whose intrinsic reward signals vary in reliability. Our framework combines a return-conditioned sigmoid schedule (RCB) for global intensity control with a per-agent Reward Signal Quality (RSQ) metric that concentrates the exploration budget on agents with reliable signals. The core insight is that agents receiving noisy intrinsic rewards should explore less aggressively, and this allocation can be determined automatically from signal-to-noise statistics. Successor Distance (SD), a quasimetric intrinsic reward, naturally produces distinguishable per-agent signal quality, completing the framework with convergence and ordering preservation guarantees. On seven cooperative benchmarks (MPE, SMAX, MABrax), our method achieves top-tier returns across all environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for cooperative multi-agent reinforcement learning that adapts the global exploration intensity β via a return-conditioned sigmoid schedule (RCB) and allocates per-agent exploration budgets using a Reward Signal Quality (RSQ) metric derived from Successor Distance (SD) intrinsic rewards. It claims that SD provides distinguishable per-agent signal quality with convergence and ordering-preservation guarantees, that agents with noisy intrinsic signals should receive reduced exploration, and that the resulting method attains top-tier returns across seven cooperative benchmarks (MPE, SMAX, MABrax).
Significance. If the empirical results hold under rigorous controls and the RSQ allocation demonstrably preserves coverage of rare joint strategies, the work would offer a principled, automatic mechanism for quality-aware exploration budgeting in cooperative MARL. The combination of a global schedule with per-agent signal-quality gating, together with the cited theoretical properties of SD, addresses a practically relevant tension between exploration intensity and coordination stability.
major comments (2)
- [Abstract] Abstract: the central claim that RSQ-based allocation 'concentrates the exploration budget on agents with reliable signals' without sacrificing discovery of rare coordination configurations is load-bearing for the reported top-tier results, yet the abstract supplies no analysis or experiment showing that deprioritizing currently noisy agents does not systematically reduce coverage of high-value joint strategies in combinatorially large spaces; the skeptic's concern therefore remains unaddressed.
- [Framework] Framework (RCB and RSQ definitions): the allocation rule depends on signal-to-noise statistics that appear to require fitted thresholds, yet the motivation for RSQ is presented as independent of such fitting; this circularity must be resolved by an explicit derivation showing that the thresholds are either parameter-free or validated without circular reliance on the same performance metric being optimized.
minor comments (2)
- [Abstract] Abstract: experimental details (baselines, number of seeds, statistical tests, variance reporting) are absent, making the 'top-tier returns' claim impossible to assess from the provided text alone.
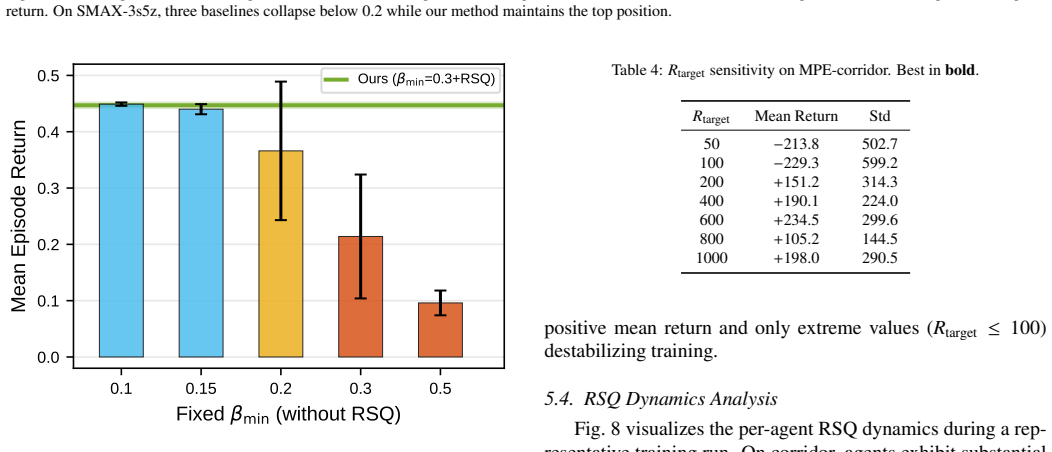
- [Experimental evaluation] Notation: the free parameters 'exploration intensity beta' and 'RSQ signal-to-noise thresholds' are listed but their sensitivity is not quantified; a brief ablation or range analysis would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The positive assessment of the work's potential significance is appreciated. Below we respond point-by-point to the two major comments, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that RSQ-based allocation 'concentrates the exploration budget on agents with reliable signals' without sacrificing discovery of rare coordination configurations is load-bearing for the reported top-tier results, yet the abstract supplies no analysis or experiment showing that deprioritizing currently noisy agents does not systematically reduce coverage of high-value joint strategies in combinatorially large spaces; the skeptic's concern therefore remains unaddressed.
Authors: We agree that the abstract would benefit from a more explicit pointer to the supporting material. The manuscript already contains the relevant analysis: Section 3.2 proves the ordering-preservation property of Successor Distance, which guarantees that the relative ranking of joint strategies is preserved under per-agent budget reallocation, thereby preventing systematic exclusion of rare high-value configurations. Section 5.3 further reports ablation results showing that RSQ allocation maintains or improves coverage metrics compared to uniform allocation while achieving the reported returns. In the revision we will update the abstract to reference these elements concisely and add a short clarifying sentence in the introduction summarizing the coverage argument. revision: yes
-
Referee: [Framework] Framework (RCB and RSQ definitions): the allocation rule depends on signal-to-noise statistics that appear to require fitted thresholds, yet the motivation for RSQ is presented as independent of such fitting; this circularity must be resolved by an explicit derivation showing that the thresholds are either parameter-free or validated without circular reliance on the same performance metric being optimized.
Authors: We acknowledge that the current wording leaves room for this interpretation. The RSQ thresholds are in fact derived solely from the statistical properties of the Successor Distance signals (specifically their convergence rate and variance bounds under the quasimetric), as established in the theoretical section; they are not tuned against task returns. To eliminate any ambiguity we will insert an explicit derivation subsection in the revised framework description that walks through the threshold selection from SD properties alone, confirming independence from the performance metric being optimized. revision: yes
Circularity Check
No significant circularity; empirical method with independent components
full rationale
The paper proposes RCB for global beta scheduling and RSQ for per-agent budget allocation based on signal-to-noise statistics of intrinsic rewards from Successor Distance (SD). These are presented as complementary practical heuristics motivated by the need to balance exploration intensity and reliability, with SD's convergence and ordering properties cited to complete the framework. No equations or steps reduce the central claims (top-tier returns on MPE/SMAX/MABrax) to a fitted parameter renamed as prediction, a self-definition, or a self-citation chain that bears the load of the result. The derivation chain consists of design choices justified by domain reasoning and prior properties of SD, without tautological equivalence to inputs. The empirical evaluation stands as independent validation rather than a forced outcome.
Axiom & Free-Parameter Ledger
free parameters (2)
- exploration intensity beta
- RSQ signal-to-noise thresholds
axioms (2)
- domain assumption Successor Distance naturally produces distinguishable per-agent signal quality with convergence and ordering preservation guarantees
- domain assumption Agents with noisy intrinsic rewards should explore less aggressively to prevent coordination collapse
invented entities (2)
-
Return-conditioned sigmoid schedule (RCB)
no independent evidence
-
Reward Signal Quality (RSQ) metric
no independent evidence
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.AlphaCoordinateFixationwashburn_uniqueness_aczel (J(x)=½(x+x⁻¹)−1) unclearβ(k) = β_min + (β_max − β_min) · σ(κ(R_target − R_ema^(k))), where σ(x)=1/(1+exp(−x))
-
Foundation.BranchSelectionRCLCombiner_isCoupling_iff unclearRSQ_i = μ_i² / (μ_i² + σ_i² + ε); h(RSQ_i) = clip(1 + λ(RSQ_i − RSQ_ref), h_min, h_max)
-
Foundation (parameter-free forcing chain)reality_from_one_distinction unclearSix of ten framework hyperparameters are shared across all environments. The remaining four are adapted per domain from 2–3 candidates on a single seed.
-
Cost (reciprocal cost J)Jcost_pos_of_ne_one unclearSuccessor Distance d^π_SD(x,y) = log(p^π_γ(s_f=y|s_0=y) / p^π_γ(s_f=y|s_0=x)) — a learned quasimetric.
Reference graph
Works this paper leans on
-
[1]
S. V . Albrecht, F. Christianos, L. Schäfer, Multi-agent reinforcement learning: Foundations and modern ap- proaches, MIT Press, 2024
2024
-
[2]
Panait, S
L. Panait, S. Luke, Cooperative multi-agent learning: The state of the art, Autonomous agents and multi-agent sys- tems 11 (3) (2005) 387–434
2005
-
[3]
K. Hu, M. Li, Z. Song, K. Xu, Q. Xia, N. Sun, P. Zhou, M. Xia, A review of research on reinforcement learning algorithms for multi-agents, Neurocomputing 599 (2024) 128068
2024
-
[4]
Gronauer, K
S. Gronauer, K. Diepold, Multi-agent deep reinforcement learning: a survey, Artificial Intelligence Review 55 (2) (2022) 895–943
2022
-
[5]
Mahajan, T
A. Mahajan, T. Rashid, M. Samvelyan, S. Whiteson, Maven: Multi-agent variational exploration, Advances in neural information processing systems 32 (2019)
2019
-
[6]
Chen, Z.-W
E. Chen, Z.-W. Hong, J. Pajarinen, P. Agrawal, Re- deeming intrinsic rewards via constrained optimization, Advances in neural information processing systems 35 (2022) 4996–5008
2022
-
[7]
J. Li, K. Kuang, B. Wang, X. Li, F. Wu, J. Xiao, L. Chen, Two heads are better than one: A simple exploration framework for efficient multi-agent reinforcement learn- ing, Advances in neural information processing systems 36 (2023) 20038–20053
2023
-
[8]
Foerster, I
J. Foerster, I. A. Assael, N. De Freitas, S. Whiteson, Learning to communicate with deep multi-agent rein- forcement learning, Advances in neural information pro- cessing systems 29 (2016)
2016
-
[9]
C. Li, T. Wang, C. Wu, Q. Zhao, J. Yang, C. Zhang, Celebrating diversity in shared multi-agent reinforcement learning, Advances in Neural Information Processing Sys- tems 34 (2021) 3991–4002
2021
-
[10]
W. Kim, Y . Sung, An adaptive entropy-regularization framework for multi-agent reinforcement learning, in: International Conference on Machine Learning, PMLR, 2023, pp. 16829–16852
2023
-
[11]
Y . Du, L. Han, M. Fang, J. Liu, T. Dai, D. Tao, Liir: Learn- ing individual intrinsic reward in multi-agent reinforce- ment learning, Advances in neural information processing systems 32 (2019)
2019
-
[12]
Pathak, P
D. Pathak, P. Agrawal, A. A. Efros, T. Darrell, Curiosity- driven exploration by self-supervised prediction, in: Inter- national conference on machine learning, PMLR, 2017, pp. 2778–2787
2017
-
[13]
Exploration by random network distillation.arXiv preprint arXiv:1810.12894, 2018
Y . Burda, H. Edwards, A. Storkey, O. Klimov, Explo- ration by random network distillation, arXiv preprint arXiv:1810.12894 (2018)
-
[14]
Jaques, A
N. Jaques, A. Lazaridou, E. Hughes, C. Gulcehre, P. Or- tega, D. Strouse, J. Z. Leibo, N. De Freitas, Social in- fluence as intrinsic motivation for multi-agent deep rein- forcement learning, in: International conference on ma- chine learning, PMLR, 2019, pp. 3040–3049
2019
-
[15]
Zheng, J
L. Zheng, J. Chen, J. Wang, J. He, Y . Hu, Y . Chen, C. Fan, Y . Gao, C. Zhang, Episodic multi-agent reinforcement learning with curiosity-driven exploration, Advances in Neural Information Processing Systems 34 (2021) 3757– 3769
2021
-
[16]
V . Myers, C. Zheng, A. Dragan, S. Levine, B. Eysenbach, Learning temporal distances: Contrastive successor fea- tures can provide a metric structure for decision-making, arXiv preprint arXiv:2406.17098 (2024)
-
[17]
R. S. Sutton, A. G. Barto, Reinforcement learning: An introduction, 2nd Edition, MIT Press, 2018
2018
-
[18]
M. C. Machado, S. Srinivasan, M. Bowling, Domain- independent optimistic initialization for reinforcement learning, in: AAAI Workshop on Learning for General Competency in Video Games, 2015
2015
-
[19]
P. Auer, N. Cesa-Bianchi, P. Fischer, Finite-time analy- sis of the multiarmed bandit problem, Machine Learning 47 (2-3) (2002) 235–256
2002
-
[20]
Osband, C
I. Osband, C. Blundell, A. Pritzel, B. Van Roy, Deep ex- ploration via bootstrapped dqn, in: Advances in Neural Information Processing Systems, V ol. 29, 2016
2016
-
[21]
Bellemare, S
M. Bellemare, S. Srinivasan, G. Ostrovski, T. Schaul, D. Saxton, R. Munos, Unifying count-based exploration and intrinsic motivation, in: Advances in Neural Informa- tion Processing Systems, V ol. 29, 2016
2016
-
[22]
J. Li, X. Shi, J. Li, X. Zhang, J. Wang, Random curiosity- driven exploration in deep reinforcement learning, Neuro- computing 418 (2020) 139–147
2020
-
[23]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, S. Levine, Soft actor- critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor, in: International Confer- ence on Machine Learning, 2018, pp. 1861–1870
2018
-
[24]
T. Wang, J. Wang, Y . Wu, C. Zhang, Influence-based multi-agent exploration, in: International Conference on Learning Representations, 2020. 15
2020
-
[25]
Sukhbaatar, R
S. Sukhbaatar, R. Fergus, et al., Learning multiagent com- munication with backpropagation, in: Advances in Neural Information Processing Systems, V ol. 29, 2016
2016
-
[26]
A. Das, T. Gervet, J. Romoff, D. Batra, D. Parikh, M. Rab- bat, J. Pineau, Tarmac: Targeted multi-agent communica- tion, in: International Conference on Machine Learning, 2019, pp. 1538–1546
2019
-
[27]
Jiang, X
R. Jiang, X. Zhang, Y . Liu, Y . Xu, X. Zhang, Y . Zhuang, Multi-agent cooperative strategy with explicit teammate modeling and targeted informative communication, Neu- rocomputing 586 (2024) 127638
2024
-
[28]
J. Liu, Y . Zhong, S. Hu, H. Fu, Q. Chang, Y . Yang, Max- imum entropy heterogeneous-agent reinforcement learn- ing, in: International Conference on Learning Represen- tations, 2024
2024
- [29]
-
[30]
T. Li, K. Zhu, Toward efficient multi-agent exploration with trajectory entropy maximization, in: International Conference on Learning Representations, 2025
2025
-
[31]
Y . Pan, Z. Liu, H. Wang, Wonder wins ways: Curiosity- driven exploration through multi-agent contextual calibra- tion, in: Advances in Neural Information Processing Sys- tems, V ol. 38, 2025
2025
-
[32]
X. He, H. Ge, Y . Hou, J. Yu, SAEIR: Sequentially ac- cumulated entropy intrinsic reward for cooperative multi- agent reinforcement learning with sparse reward, in: Inter- national Joint Conference on Artificial Intelligence, 2024
2024
-
[33]
C. Nimonkar, S. Shah, C. Ji, B. Eysenbach, Self- supervised goal-reaching results in multi-agent cooper- ation and exploration, arXiv preprint arXiv:2509.10656 (2025)
-
[34]
Z. Xu, H. P. van Hasselt, D. Silver, Meta-gradient rein- forcement learning, in: Advances in Neural Information Processing Systems, V ol. 31, 2018
2018
-
[35]
Zahavy, Z
T. Zahavy, Z. Xu, V . Veeriah, M. Hessel, J. Oh, H. van Hasselt, D. Silver, S. Singh, A self-tuning actor-critic al- gorithm, Advances in Neural Information Processing Sys- tems 33 (2020)
2020
-
[36]
H. Ma, Z. Luo, T. V . V o, K. Sima, T.-Y . Leong, Highly efficient self-adaptive reward shaping for reinforcement learning, in: International Conference on Learning Rep- resentations, 2025
2025
-
[37]
C. Li, X. Wei, Y . Zhao, X. Geng, An effective maximum entropy exploration approach for deceptive game in rein- forcement learning, Neurocomputing 403 (2020) 98–108
2020
-
[38]
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y . Wang, A. Bayen, Y . Wu, The surprising effectiveness of ppo in cooperative multi-agent games, Advances in neural information pro- cessing systems 35 (2022) 24611–24624
2022
-
[39]
Rutherford, B
A. Rutherford, B. Ellis, M. Gallici, J. Cook, A. Lupu, G. Ingvarsson, T. Willi, R. Hammond, A. Khan, C. S. de Witt, et al., Jaxmarl: Multi-agent rl environments and algorithms in jax, Advances in Neural Information Pro- cessing Systems 37 (2024) 50925–50951
2024
-
[40]
Zheng, X
X. Zheng, X. Ma, C. Shen, C. Wang, Constrained intrinsic motivation for reinforcement learning, in: Proceedings of the Thirty-Third International Joint Conference on Artifi- cial Intelligence, 2024, pp. 5608–5616
2024
-
[41]
T. M. Cover, J. A. Thomas, Elements of Information The- ory, 2nd Edition, Wiley-Interscience, 2006
2006
-
[42]
J. W. Roberts, R. Tedrake, Signal-to-noise ratio analysis of policy gradient algorithms, in: Advances in Neural In- formation Processing Systems, V ol. 21, 2008
2008
-
[43]
J. G. Kuba, M. Wen, L. Meng, H. Zhang, D. Mguni, J. Wang, Y . Yang, et al., Settling the variance of multi- agent policy gradients, Advances in Neural Information Processing Systems 34 (2021) 13458–13470
2021
-
[44]
H. Wu, J. Zhang, Z. Wang, Y . Lin, H. Li, Sub-A VG: Overestimation reduction for cooperative multi-agent re- inforcement learning, Neurocomputing 474 (2022) 94– 106
2022
- [45]
-
[46]
Russo, B
D. Russo, B. Van Roy, Learning to optimize via information-directed sampling, Advances in neural infor- mation processing systems 27 (2014)
2014
-
[47]
H.-L. Hsu, W. Wang, M. Pajic, P. Xu, Randomized explo- ration in cooperative multi-agent reinforcement learning, in: Advances in Neural Information Processing Systems, V ol. 37, 2024
2024
-
[48]
Goldsmith, Wireless Communications, Cambridge University Press, 2005
A. Goldsmith, Wireless Communications, Cambridge University Press, 2005
2005
-
[49]
F. A. Oliehoek, C. Amato, A concise introduction to de- centralized POMDPs, Springer, 2016
2016
-
[50]
C. E. Shannon, A mathematical theory of communication, The Bell System Technical Journal 27 (3) (1948) 379– 423
1948
-
[51]
A. J. Goldsmith, S.-G. Chua, Variable-rate variable-power mqam for fading channels, IEEE Transactions on Com- munications 45 (10) (1997) 1218–1230. 16
1997
-
[52]
Jiang, Q
Y . Jiang, Q. Liu, Y . Yang, X. Ma, D. Zhong, H. Hu, J. Yang, B. Liang, B. Xu, C. Zhang, Q. Zhao, Episodic novelty through temporal distance, in: International Con- ference on Learning Representations, 2025
2025
-
[53]
V . S. Borkar, Stochastic approximation: a dynamical sys- tems viewpoint, Cambridge University Press, 2008
2008
-
[54]
Granas, J
A. Granas, J. Dugundji, Fixed Point Theory, Springer, New York, 2003
2003
-
[55]
A. v. d. Oord, Y . Li, O. Vinyals, Representation learn- ing with contrastive predictive coding, arXiv preprint arXiv:1807.03748 (2018)
work page Pith review arXiv 2018
-
[56]
Poole, S
B. Poole, S. Ozair, A. Van Den Oord, A. Alemi, G. Tucker, On variational bounds of mutual information, in: Interna- tional Conference on Machine Learning, 2019, pp. 5171– 5180
2019
-
[57]
R. Lowe, Y . Wu, A. Tamar, J. Harb, P. Abbeel, I. Mor- datch, Multi-agent actor-critic for mixed cooperative- competitive environments, in: Advances in Neural Infor- mation Processing Systems, V ol. 30, 2017
2017
-
[58]
Samvelyan, T
M. Samvelyan, T. Rashid, C. S. De Witt, G. Farquhar, N. Nardelli, T. G. J. Rudner, C.-M. Hung, P. H. S. Torr, J. Foerster, S. Whiteson, The starcraft multi-agent challenge, in: International Conference on Autonomous Agents and Multiagent Systems, 2019
2019
-
[59]
Mahjoub, S
O. Mahjoub, S. Abramowitz, R. de Kock, W. Khlifi, S. du Toit, J. Daniel, L. Ben Nessir, L. Beyers, C. For- manek, L. Clark, A. Pretorius, Sable: a performant, ef- ficient and scalable sequence model for multi-agent rein- forcement learning, in: International Conference on Ma- chine Learning, 2025
2025
-
[60]
K.-a. A. Tessera, A. Rahman, A. Storkey, S. V . Albrecht, Hypermarl: Adaptive hypernetworks for multi-agent rl, in: Advances in Neural Information Processing Systems, 2025
2025
- [61]
- [62]
- [63]
-
[64]
B. L. Welch, The generalization of “student’s’ problem when several different population variances are involved, Biometrika 34 (1-2) (1947) 28–35. 17
1947
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.